Lambda表达式你会用吗?
函数式编程
在正式学习Lambda之前,我们先来了解一下什么是函数式编程
我们先看看什么是函数。函数是一种最基本的任务,一个大型程序就是一个顶层函数调用若干底层函数,这些被调用的函数又可以调用其他函数,即大任务被一层层拆解并执行。所以函数就是面向过程的程序设计的基本单元。
Java不支持单独定义函数,但可以把静态方法视为独立的函数,把实例方法视为自带this参数的函数。而函数式编程(请注意多了一个“式”字)——Functional Programming,虽然也可以归结到面向过程的程序设计,但其思想更接近数学计算。
我们首先要搞明白计算机(Computer)和计算(Compute)的概念。在计算机的层次上,CPU执行的是加减乘除的指令代码,以及各种条件判断和跳转指令,所以,汇编语言是最贴近计算机的语言。而计算则指数学意义上的计算,越是抽象的计算,离计算机硬件越远。对应到编程语言,就是越低级的语言,越贴近计算机,抽象程度低,执行效率高,比如C语言;越高级的语言,越贴近计算,抽象程度高,执行效率低,比如Lisp语言。
函数式编程就是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量,因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数我们称之为没有副作用。而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出,因此,这种函数是有副作用的。
函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数!
函数式编程最早是数学家阿隆佐·邱奇研究的一套函数变换逻辑,又称Lambda Calculus(λ-Calculus),所以也经常把函数式编程称为Lambda计算。
Java平台从Java 8开始,支持函数式编程。
Lambda初体验
先从一个例子开始,让我们来看一下Lambda可以用在什么地方。
例一:创建线程
常见创建线程的方法(JDK1.8以前)
//JDK1.7通过匿名内部类的方式创建线程
Thread thread = new Thread(new Runnable() {
@Override
public void run() { //实现run方法
System.out.println("Thread Run...");
}
});
thread.start();
通过匿名内部类的方式创建线程,省去了取名字的烦恼,但是还能不能再简化一些呢?
JDK1.8 Lambda表达式写法
Thread thread = new Thread(() -> System.out.println("Thread Run")); //一行搞定
thread.start();
我们可以看到Lambda一行代码就完成了线程的创建,简直不要太方便。(至于Lambda表达式的语法,我们下面章节再详细介绍)
如果你的逻辑不止一行代码,那么你还可以这么写
Thread thread = new Thread(() -> {
System.out.println("Thread Run");
System.out.println("Hello");
});
thread.start();
用{}将代码块包裹起来
例二:自定义比较器
我们先来看一下JDK1.7是如何实现自定义比较器的
List<String> list = Arrays.asList("Hi", "Life", "Hello~", "World");
Collections.sort(list, new Comparator<String>(){// 接口名
@Override
public int compare(String s1, String s2){// 方法名
if(s1 == null)
return -1;
if(s2 == null)
return 1;
return s1.length()-s2.length();
}
});
//输出排序好的List
for (String s : list) {
System.out.println(s);
}
这里的sort方法传入了两个参数,一个是待排序的list,一个是比较器(排序规则),这里也是通过匿名内部类的方式实现的比较器。
下面我们来看一下Lambda表达式如何实现比较器?
List<String> list = Arrays.asList("Hi", "Life", "Hello~", "World");
Collections.sort(list, (s1, s2) ->{// 省略了参数的类型,编译器会根据上下文信息自动推断出类型
if(s1 == null)
return -1;
if(s2 == null)
return 1;
return s1.length()-s2.length();
});
//输出排序好的List
for (String s : list) {
System.out.println(s);
}
我们可以看到,Lambda表达式和匿名内部类的作用相同,但是省略了很多代码,可以大大加快开发速度
Lambda表达式语法
Lambda 表达式,也可称为闭包,它是推动 Java 8 发布的最重要新特性。Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中)。
使用 Lambda 表达式可以使代码变的更加简洁紧凑。上一章节我们已经见识到了Lambda表达式的优点,那么Lambda表达式到底该怎么写呢?
语法
lambda 表达式的语法格式如下:
(parameters) -> expression //一行代码
或
(parameters) ->{ statements; } //多行代码
lambda表达式的重要特征:
- 可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。
- 可选的参数圆括号:一个参数无需定义圆括号,但多个参数需要定义圆括号。
- 可选的大括号:如果主体包含了一个语句,就不需要使用大括号。
- 可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指定明表达式返回了一个数值。
// 1. 不需要参数,返回值为 5
() -> 5
// 2. 接收一个参数(数字类型),返回其2倍的值
x -> 2 * x
// 3. 接受2个参数(数字),并返回他们的差值
(x, y) -> x – y
// 4. 接收2个int型整数,返回他们的和
(int x, int y) -> x + y
// 5. 接受一个 string 对象,并在控制台打印,不返回任何值(看起来像是返回void)
(String s) -> System.out.print(s)
函数接口
上面几个章节给大家介绍Lambda表达式的基本使用,那么是不是在任意地方都可以使用Lambda表达式呢?
其实Lambda表达式使用是有限制的。也许你已经想到了,能够使用Lambda的依据是必须有相应的函数接口。(函数接口,是指内部只有一个抽象方法的接口)
自定义函数接口
自定义函数接口很容易,只需要编写一个只有一个抽象方法的接口即可。
// 自定义函数接口
@FunctionalInterface
public interface PersonInterface<T>{
void accept(T t);
}
上面代码中的@FunctionalInterface是可选的,但加上该标注编译器会帮你检查接口是否符合函数接口规范。就像加入@Override标注会检查是否重载了函数一样。
那么根据上面的自定义函数式接口,我们就可以写出如下的Lambda表达式。
PersonInterface p = str -> System.out.println(str);
Lambda和匿名内部类
经过上面几部分的介绍,相信大家对Lambda表达式已经有了初步认识,学会了如何使用。但想必大家心中始终有一个疑问,Lambda表达式似乎只是为了简化匿名内部类的写法,其他也没啥区别了。这看起来仅仅通过语法糖在编译阶段把所有的Lambda表达式替换成匿名内部类就可以了,事实真的如此吗?
public class Main {
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Anonymous class");
}
}).start();
}
}
匿名内部类也是一个类,只不过我们不需要显示为他定义名称,但是编译器会自动为匿名内部类命名。Main编辑后的文件如下图
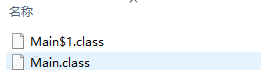
我们可以看到共有两个class文件,一个是Main.class,而另一个则是编辑器为我们命名的内部类。
下面我们来看一下Lambda表达式会产生几个class文件
public class Main {
public static void main(String[] args) {
new Thread(() -> System.out.println("Lambda")).start();
}
}
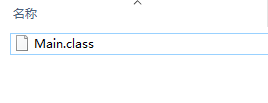
Lambda表达式通过invokedynamic指令实现,书写Lambda表达式不会产生新的类
Lambda在集合中的运用
既然Lambda表达式这么方便,那么哪些地方可以使用Lambda表达式呢?
我们先从最熟悉的Java集合框架(Java Collections Framework, JCF)开始说起。
为引入Lambda表达式,Java8新增了java.util.funcion包,里面包含常用的函数接口,这是Lambda表达式的基础,Java集合框架也新增部分接口,以便与Lambda表达式对接。
首先回顾一下Java集合框架的接口继承结构:

上图中绿色标注的接口类,表示在Java8中加入了新的接口方法,当然由于继承关系,他们相应的子类也都会继承这些新方法。下表详细列举了这些方法。
| 接口名 | Java8新加入的方法 |
|---|---|
| Collection | removeIf() spliterator() stream() parallelStream() forEach() |
| List | replaceAll() sort() |
| Map | getOrDefault() forEach() replaceAll() putIfAbsent() remove() replace() computeIfAbsent() computeIfPresent() compute() merge() |
这些新加入的方法大部分要用到java.util.function包下的接口,这意味着这些方法大部分都跟Lambda表达式相关。我们将逐一学习这些方法。
Collection中的新方法
如上所示,接口Collection和List新加入了一些方法,我们以是List的子类ArrayList为例来说明。了解Java7ArrayList实现原理,将有助于理解下文。
forEach()
该方法的签名为void forEach(Consumer<? super E> action),作用是对容器中的每个元素执行action指定的动作,其中Consumer是个函数接口,里面只有一个待实现方法void accept(T t)(后面我们会看到,这个方法叫什么根本不重要,你甚至不需要记忆它的名字)。
需求:假设有一个字符串列表,需要打印出其中所有长度大于3的字符串.
Java7及以前我们可以用增强的for循环实现:
// 使用曾强for循环迭代
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
for(String str : list){
if(str.length()>3)
System.out.println(str);
}
现在使用forEach()方法结合匿名内部类,可以这样实现:
// 使用forEach()结合匿名内部类迭代
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.forEach(new Consumer<String>(){
@Override
public void accept(String str){
if(str.length()>3)
System.out.println(str);
}
});
上述代码调用forEach()方法,并使用匿名内部类实现Comsumer接口。到目前为止我们没看到这种设计有什么好处,但是不要忘记Lambda表达式,使用Lambda表达式实现如下:
// 使用forEach()结合Lambda表达式迭代
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.forEach( str -> {
if(str.length()>3)
System.out.println(str);
});
上述代码给forEach()方法传入一个Lambda表达式,我们不需要知道accept()方法,也不需要知道Consumer接口,类型推导帮我们做了一切。
removeIf()
该方法签名为boolean removeIf(Predicate<? super E> filter),作用是删除容器中所有满足filter指定条件的元素,其中Predicate是一个函数接口,里面只有一个待实现方法boolean test(T t),同样的这个方法的名字根本不重要,因为用的时候不需要书写这个名字。
需求:假设有一个字符串列表,需要删除其中所有长度大于3的字符串。
我们知道如果需要在迭代过程冲对容器进行删除操作必须使用迭代器,否则会抛出ConcurrentModificationException,所以上述任务传统的写法是:
// 使用迭代器删除列表元素
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
Iterator<String> it = list.iterator();
while(it.hasNext()){
if(it.next().length()>3) // 删除长度大于3的元素
it.remove();
}
现在使用removeIf()方法结合匿名内部类,我们可是这样实现:
// 使用removeIf()结合匿名名内部类实现
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.removeIf(new Predicate<String>(){ // 删除长度大于3的元素
@Override
public boolean test(String str){
return str.length()>3;
}
});
上述代码使用removeIf()方法,并使用匿名内部类实现Precicate接口。相信你已经想到用Lambda表达式该怎么写了:
// 使用removeIf()结合Lambda表达式实现
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.removeIf(str -> str.length()>3); // 删除长度大于3的元素
使用Lambda表达式不需要记忆Predicate接口名,也不需要记忆test()方法名,只需要知道此处需要一个返回布尔类型的Lambda表达式就行了。
replaceAll()
该方法签名为void replaceAll(UnaryOperator<E> operator),作用是对每个元素执行operator指定的操作,并用操作结果来替换原来的元素。其中UnaryOperator是一个函数接口,里面只有一个待实现函数T apply(T t)。
需求:假设有一个字符串列表,将其中所有长度大于3的元素转换成大写,其余元素不变。
Java7及之前似乎没有优雅的办法:
// 使用下标实现元素替换
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
for(int i=0; i<list.size(); i++){
String str = list.get(i);
if(str.length()>3)
list.set(i, str.toUpperCase());
}
使用replaceAll()方法结合匿名内部类可以实现如下:
// 使用匿名内部类实现
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.replaceAll(new UnaryOperator<String>(){
@Override
public String apply(String str){
if(str.length()>3)
return str.toUpperCase();
return str;
}
});
上述代码调用replaceAll()方法,并使用匿名内部类实现UnaryOperator接口。我们知道可以用更为简洁的Lambda表达式实现:
// 使用Lambda表达式实现
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.replaceAll(str -> {
if(str.length()>3)
return str.toUpperCase();
return str;
});
sort()
该方法定义在List接口中,方法签名为void sort(Comparator<? super E> c),该方法根据c指定的比较规则对容器元素进行排序。Comparator接口我们并不陌生,其中有一个方法int compare(T o1, T o2)需要实现,显然该接口是个函数接口。
需求:假设有一个字符串列表,按照字符串长度增序对元素排序。
由于Java7以及之前sort()方法在Collections工具类中,所以代码要这样写:
// Collections.sort()方法
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
Collections.sort(list, new Comparator<String>(){
@Override
public int compare(String str1, String str2){
return str1.length()-str2.length();
}
});
现在可以直接使用List.sort()方法,结合Lambda表达式,可以这样写:
// List.sort()方法结合Lambda表达式
ArrayList<String> list = new ArrayList<>(Arrays.asList("I", "love", "you", "too"));
list.sort((str1, str2) -> str1.length()-str2.length());
spliterator()
方法签名为Spliterator<E> spliterator(),该方法返回容器的可拆分迭代器。从名字来看该方法跟iterator()方法有点像,我们知道Iterator是用来迭代容器的,Spliterator也有类似作用,但二者有如下不同:
Spliterator既可以像Iterator那样逐个迭代,也可以批量迭代。批量迭代可以降低迭代的开销。Spliterator是可拆分的,一个Spliterator可以通过调用Spliterator<T> trySplit()方法来尝试分成两个。一个是this,另一个是新返回的那个,这两个迭代器代表的元素没有重叠。
可通过(多次)调用Spliterator.trySplit()方法来分解负载,以便多线程处理。
stream()和parallelStream()
stream()和parallelStream()分别返回该容器的Stream视图表示,不同之处在于parallelStream()返回并行的Stream。Stream是Java函数式编程的核心类,我们会在后面章节中学习。
Map中的新方法
相比Collection,Map中加入了更多的方法,我们以HashMap为例来逐一探秘。了解[Java7HashMap实现原理](https://github.com/CarpenterLee/JCFInternals/blob/master/markdown/6-HashSet and HashMap.md),将有助于理解下文。
forEach()
该方法签名为void forEach(BiConsumer<? super K,? super V> action),作用是对Map中的每个映射执行action指定的操作,其中BiConsumer是一个函数接口,里面有一个待实现方法void accept(T t, U u)。BinConsumer接口名字和accept()方法名字都不重要,请不要记忆他们。
需求:假设有一个数字到对应英文单词的Map,请输出Map中的所有映射关系.
Java7以及之前经典的代码如下:
// Java7以及之前迭代Map
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
for(Map.Entry<Integer, String> entry : map.entrySet()){
System.out.println(entry.getKey() + "=" + entry.getValue());
}
使用Map.forEach()方法,结合匿名内部类,代码如下:
// 使用forEach()结合匿名内部类迭代Map
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
map.forEach(new BiConsumer<Integer, String>(){
@Override
public void accept(Integer k, String v){
System.out.println(k + "=" + v);
}
});
上述代码调用forEach()方法,并使用匿名内部类实现BiConsumer接口。当然,实际场景中没人使用匿名内部类写法,因为有Lambda表达式:
// 使用forEach()结合Lambda表达式迭代Map
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
map.forEach((k, v) -> System.out.println(k + "=" + v));
}
getOrDefault()
该方法跟Lambda表达式没关系,但是很有用。方法签名为V getOrDefault(Object key, V defaultValue),作用是按照给定的key查询Map中对应的value,如果没有找到则返回defaultValue。使用该方法程序员可以省去查询指定键值是否存在的麻烦.
需求;假设有一个数字到对应英文单词的Map,输出4对应的英文单词,如果不存在则输出NoValue
// 查询Map中指定的值,不存在时使用默认值
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
// Java7以及之前做法
if(map.containsKey(4)){ // 1
System.out.println(map.get(4));
}else{
System.out.println("NoValue");
}
// Java8使用Map.getOrDefault()
System.out.println(map.getOrDefault(4, "NoValue")); // 2
putIfAbsent()
该方法跟Lambda表达式没关系,但是很有用。方法签名为V putIfAbsent(K key, V value),作用是只有在不存在key值的映射或映射值为null时,才将value指定的值放入到Map中,否则不对Map做更改.该方法将条件判断和赋值合二为一,使用起来更加方便.
remove()
我们都知道Map中有一个remove(Object key)方法,来根据指定key值删除Map中的映射关系;Java8新增了remove(Object key, Object value)方法,只有在当前Map中key正好映射到value时才删除该映射,否则什么也不做.
replace()
在Java7及以前,要想替换Map中的映射关系可通过put(K key, V value)方法实现,该方法总是会用新值替换原来的值.为了更精确的控制替换行为,Java8在Map中加入了两个replace()方法,分别如下:
replace(K key, V value),只有在当前Map中key的映射存在时才用value去替换原来的值,否则什么也不做.replace(K key, V oldValue, V newValue),只有在当前Map中key的映射存在且等于oldValue时才用newValue去替换原来的值,否则什么也不做.
replaceAll()
该方法签名为replaceAll(BiFunction<? super K,? super V,? extends V> function),作用是对Map中的每个映射执行function指定的操作,并用function的执行结果替换原来的value,其中BiFunction是一个函数接口,里面有一个待实现方法R apply(T t, U u).不要被如此多的函数接口吓到,因为使用的时候根本不需要知道他们的名字.
需求:假设有一个数字到对应英文单词的Map,请将原来映射关系中的单词都转换成大写.
Java7以及之前经典的代码如下:
// Java7以及之前替换所有Map中所有映射关系
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
for(Map.Entry<Integer, String> entry : map.entrySet()){
entry.setValue(entry.getValue().toUpperCase());
}
使用replaceAll()方法结合匿名内部类,实现如下:
// 使用replaceAll()结合匿名内部类实现
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
map.replaceAll(new BiFunction<Integer, String, String>(){
@Override
public String apply(Integer k, String v){
return v.toUpperCase();
}
});
上述代码调用replaceAll()方法,并使用匿名内部类实现BiFunction接口。更进一步的,使用Lambda表达式实现如下:
// 使用replaceAll()结合Lambda表达式实现
HashMap<Integer, String> map = new HashMap<>();
map.put(1, "one");
map.put(2, "two");
map.put(3, "three");
map.replaceAll((k, v) -> v.toUpperCase());
简洁到让人难以置信.
merge()
该方法签名为merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction),作用是:
- 如果
Map中key对应的映射不存在或者为null,则将value(不能是null)关联到key上; - 否则执行
remappingFunction,如果执行结果非null则用该结果跟key关联,否则在Map中删除key的映射.
参数中BiFunction函数接口前面已经介绍过,里面有一个待实现方法R apply(T t, U u).
merge()方法虽然语义有些复杂,但该方法的用方式很明确,一个比较常见的场景是将新的错误信息拼接到原来的信息上,比如:
map.merge(key, newMsg, (v1, v2) -> v1+v2);
compute()
该方法签名为compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction),作用是把remappingFunction的计算结果关联到key上,如果计算结果为null,则在Map中删除key的映射.
要实现上述merge()方法中错误信息拼接的例子,使用compute()代码如下:
map.compute(key, (k,v) -> v==null ? newMsg : v.concat(newMsg));
computeIfAbsent()
该方法签名为V computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction),作用是:只有在当前Map中不存在key值的映射或映射值为null时,才调用mappingFunction,并在mappingFunction执行结果非null时,将结果跟key关联.
Function是一个函数接口,里面有一个待实现方法R apply(T t).
computeIfAbsent()常用来对Map的某个key值建立初始化映射.比如我们要实现一个多值映射,Map的定义可能是Map<K,Set<V>>,要向Map中放入新值,可通过如下代码实现:
Map<Integer, Set<String>> map = new HashMap<>();
// Java7及以前的实现方式
if(map.containsKey(1)){
map.get(1).add("one");
}else{
Set<String> valueSet = new HashSet<String>();
valueSet.add("one");
map.put(1, valueSet);
}
// Java8的实现方式
map.computeIfAbsent(1, v -> new HashSet<String>()).add("yi");
使用computeIfAbsent()将条件判断和添加操作合二为一,使代码更加简洁.
computeIfPresent()
该方法签名为V computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction),作用跟computeIfAbsent()相反,即,只有在当前Map中存在key值的映射且非null时,才调用remappingFunction,如果remappingFunction执行结果为null,则删除key的映射,否则使用该结果替换key原来的映射.
这个函数的功能跟如下代码是等效的:
// Java7及以前跟computeIfPresent()等效的代码
if (map.get(key) != null) {
V oldValue = map.get(key);
V newValue = remappingFunction.apply(key, oldValue);
if (newValue != null)
map.put(key, newValue);
else
map.remove(key);
return newValue;
}
return null;
- Java8为容器新增一些有用的方法,这些方法有些是为完善原有功能,有些是为引入函数式编程,学习和使用这些方法有助于我们写出更加简洁有效的代码.
- 函数接口虽然很多,但绝大多数时候我们根本不需要知道它们的名字,书写Lambda表达式时类型推断帮我们做了一切.
参考:https://github.com/CarpenterLee/JavaLambdaInternals
Lambda表达式你会用吗?的更多相关文章
- 你知道C#中的Lambda表达式的演化过程吗?
那得从很久很久以前说起了,记得那个时候... 懵懂的记得从前有个叫委托的东西是那么的高深难懂. 委托的使用 例一: 什么是委托? 个人理解:用来传递方法的类型.(用来传递数字的类型有int.float ...
- Linq表达式、Lambda表达式你更喜欢哪个?
什么是Linq表达式?什么是Lambda表达式? 如图: 由此可见Linq表达式和Lambda表达式并没有什么可比性. 那与Lambda表达式相关的整条语句称作什么呢?在微软并没有给出官方的命名,在& ...
- 背后的故事之 - 快乐的Lambda表达式(一)
快乐的Lambda表达式(二) 自从Lambda随.NET Framework3.5出现在.NET开发者眼前以来,它已经给我们带来了太多的欣喜.它优雅,对开发者更友好,能提高开发效率,天啊!它还有可能 ...
- Kotlin的Lambda表达式以及它们怎样简化Android开发(KAD 07)
作者:Antonio Leiva 时间:Jan 5, 2017 原文链接:https://antonioleiva.com/lambdas-kotlin/ 由于Lambda表达式允许更简单的方式建模式 ...
- java8中lambda表达式的应用,以及一些泛型相关
语法部分就不写了,我们直接抛出一个实际问题,看看java8的这些新特性究竟能给我们带来哪些便利 顺带用到一些泛型编程,一切都是为了简化代码 场景: 一个数据类,用于记录职工信息 public clas ...
- 背后的故事之 - 快乐的Lambda表达式(二)
快乐的Lambda表达式 上一篇 背后的故事之 - 快乐的Lambda表达式(一)我们由浅入深的分析了一下Lambda表达式.知道了它和委托以及普通方法的区别,并且通过测试对比他们之间的性能,然后我们 ...
- CRL快速开发框架系列教程二(基于Lambda表达式查询)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- Lambda 表达式递归用法实例
注意: 使用Lambda表达式会增加额外开销,但却有时候又蛮方便的. Windows下查找子孙窗口实例: HWND FindDescendantWindows(HWND hWndParent, LPC ...
- Spark中Lambda表达式的变量作用域
通常,我们希望能够在lambda表达式的闭合方法或类中访问其他的变量,例如: package java8test; public class T1 { public static void main( ...
- 释放Android的函数式能量(I):Kotlin语言的Lambda表达式
原文标题:Unleash functional power on Android (I): Kotlin lambdas 原文链接:http://antonioleiva.com/operator-o ...
随机推荐
- Jmeter(6)命令行执行
Jmeter执行方式有2种:GUI和非GUI模式 GUI:在Windows电脑上运行,图形化界面,可直接查看测试结果,但是消耗压力机资源较高 非GUI:通过命令行执行,无图形化界面,不方便查看测试结果 ...
- 一、less命令查看日志
查看日志时,一般用less满足大部分的需求. 使用命令格式: less [要查看的文件名] 例如:less LOG.20201211 中间加参数命令格式 less 参数 [要查看的文件名] 例如:查看 ...
- curl使用技巧汇总
1,curl 忽略证书安全验证 curl https://192.168.1.5:8443-insecure -I
- 网络知识扫盲——DNS
参考文章链接 : https://baijiahao.baidu.com/s?id=1668393227924896391&wfr=spider&for=pc 一.DNS 是什么? ...
- 关于ABAP和JSON互相转换
关于ABAP数据结构和JSON格式转换,需要用到标准的类/UI2/CL_JSON一下两个方法, DESERIALIZE是把JSON格式转换成ABAP数据结构,SERIALIZE是把ABAP数据结构转换 ...
- Centos上配置nginx+uwsgi+负载均衡配置
负载均衡在服务端开发中算是一个比较重要的特性.因为Nginx除了作为常规的Web服务器外,还会被大规模的用于反向代理后端,Nginx的异步框架可以处理很大的并发请求,把这些并发请求hold住之后就可以 ...
- Core3.0中Swagger使用JWT
前言 学习ASP.NETCore,原链接 https://www.cnblogs.com/laozhang-is-phi/p/9511869.html 原教程是Core2.2,后期也升级到了Core3 ...
- [.NET] - EventSource类的使用
EventSource类: 这个类是在.NET 4.5新推出的一个类,用来提供创建事件用于 Windows 事件跟踪的功能 (ETW).在之前如果要配置一个Event Tracing for Wind ...
- 基于Redis的消息队列使用:spring boot2.0整合redis
一 . 引入依赖 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="ht ...
- sql去除重复的几种方法
所以用这样一句SQL就可以去掉重复项了: select * from msg group by terminal_id; SQL中distinct的用法(四种示例分析) 示例1 select dist ...