MindSpore:基于本地差分隐私的 Bandit 算法
摘要:本文将先简单介绍Bandit 问题和本地差分隐私的相关背景,然后介绍基于本地差分隐私的 Bandit 算法,最后通过一个简单的电影推荐场景来验证 LDP LinUCB 算法。
Bandit问题是强化学习中一类重要的问题,由于它定义简洁且有大量的理论分析,因此被广泛应用于新闻推荐,医学试验等实际场景中。随着人类进入大数据时代,用户对自身数据的隐私性日益重视,这对机器学习算法的设计提出了新的挑战。为了在保护隐私的情况下解决 Bandit 这一经典问题,北京大学和华为诺亚方舟实验室联合提出了基于本地差分隐私的 Bandit 算法,论文已被 NeurIPS 2020 录用,代码已基于 MindSpore 开源首发。
本文将先简单介绍 Bandit 问题和本地差分隐私的相关背景,然后介绍基于本地差分隐私的 Bandit 算法,最后通过一个简单的电影推荐场景来验证 LDP LinUCB 算法。

大家都有过这样的经历,在我们刷微博或是读新闻的时候,经常会看到一些系统推荐的内容,这些推荐的内容是根据用户对过往推荐内容的点击情况以及阅读时长等反馈来产生的。在这个过程里,系统事先不知道用户对各种内容的偏好,通过不断地与用户进行交互(推荐内容 — 得到反馈),来慢慢学习到用户的偏好特征,不断提高推荐的精准性,从而最大化用户的价值,这就是一个典型的 Bandit 问题。
Bandit 问题有 context-free 和 contextual 两种常见的设定,下面给出它们具体的数学定义。
【Context-Free Bandit】

【Contextual Bandit】


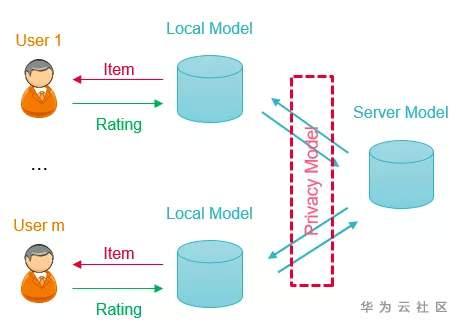
传统的差分隐私技术(Differential Privacy,DP)是将用户数据集中到一个可信的数据中心,在数据中心对用户数据进行匿名化使其符合隐私保护的要求后,再分发给下游使用,我们将其称之为中心化差分隐私。但是,一个绝对可信的数据中心很难找到,因此人们提出了本地差分隐私技术(Local Differential Privacy,LDP),它直接在客户端进行数据的隐私化处理后再提交给数据中心,彻底杜绝了数据中心泄露用户隐私的可能。


Context-Free Bandit


我们可以证明,上述算法有如下的性能:

根据上述定理,我们只需将任一非隐私保护的算法按照算法 1 进行改造,就立即可以得到对应的隐私保护版本的算法,且它的累积 regret 的理论上界和非隐私算法只相差一个

因子,因此算法 1 具有很强的通用性。我们将损失函数满足不同凸性和光滑性条件下的 regret 简单罗列如下:

上述算法和结论可以扩展到每一轮能观测多个动作损失值的情况,感兴趣的可以参见论文(https://arxiv.org/abs/2006.00701)。
Contextual Bandit


【定理】 依照至少为
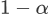
的概率,LDP LinUCB 算法的 regret 满足如

上述算法和结论可以扩展到 gg 不是恒等变换的情况,感兴趣的可以参见论文(https://arxiv.org/abs/2006.00701)。

MovieLens 是一个包含多个用户对多部电影评分的公开数据集,我们可以用它来模拟电影推荐。我们通过src/dataset.py 来构建环境:我们从数据集中抽取一部分有电影评分数据的用户,然后将评分矩阵通过 SVD 分解来补全评分数据,并将分数归一化到[−1,+1]。在每次交互的时候,系统随机抽取一个用户,推荐算法获得特征,并选择一部电影进行推荐,MovieLensEnv会在打分矩阵中查询该用户对电影对评分并返回,从而模拟用户给电影打分。
class MovieLensEnv: def observation(self): """random select a user and return its feature.""" sampled_user = random.randint(0, self._data_matrix.shape[0] - 1) self._current_user = sampled_user return Tensor(self._feature[sampled_user]) def current_rewards(self): """rewards for current user.""" return Tensor(self._approx_ratings_matrix[self._current_user])

import mindspore.nn as nn
class LinUCB(nn.Cell): def __init__(self, context_dim, epsilon=100, delta=0.1, alpha=0.1, T=1e5): ... # Parameters self._V = Tensor(np.zeros((context_dim, context_dim), dtype=np.float32)) self._u = Tensor(np.zeros((context_dim,), dtype=np.float32)) self._theta = Tensor(np.zeros((context_dim,), dtype=np.float32))
每来一个用户,LDP LinUCB 算法根据用户和电影的联合特征x基于当前的模型来选择最优的电影a_max做推荐,并传输带噪声的更新量:

import mindspore.nn as nn
class LinUCB(nn.Cell):... def construct(self, x, rewards): """compute the perturbed gradients for parameters.""" # Choose optimal action x_transpose = self.transpose(x, (1, 0)) scores_a = self.squeeze(self.matmul(x, self.expand_dims(self._theta, 1))) scores_b = x_transpose * self.matmul(self._Vc_inv, x_transpose) scores_b = self.reduce_sum(scores_b, 0) scores = scores_a + self._beta * scores_b max_a = self.argmax(scores) xa = x[max_a] xaxat = self.matmul(self.expand_dims(xa, -1), self.expand_dims(xa, 0)) y = rewards[max_a] y_max = self.reduce_max(rewards) y_diff = y_max - y self._current_regret = float(y_diff.asnumpy()) self._regret += self._current_regret
# Prepare noise B = np.random.normal(0, self._sigma, size=xaxat.shape) B = np.triu(B) B += B.transpose() - np.diag(B.diagonal()) B = Tensor(B.astype(np.float32)) Xi = np.random.normal(0, self._sigma, size=xa.shape) Xi = Tensor(Xi.astype(np.float32))
# Add noise and update parameters return xaxat + B, xa * y + Xi, max_a
系统收到更新量之后,更新模型参数如下:
import mindspore.nn as nn
class LinUCB(nn.Cell):... def server_update(self, xaxat, xay): """update parameters with perturbed gradients.""" self._V += xaxat self._u += xay self.inverse_matrix() theta = self.matmul(self._Vc_inv, self.expand_dims(self._u, 1)) self._theta = self.squeeze(theta)

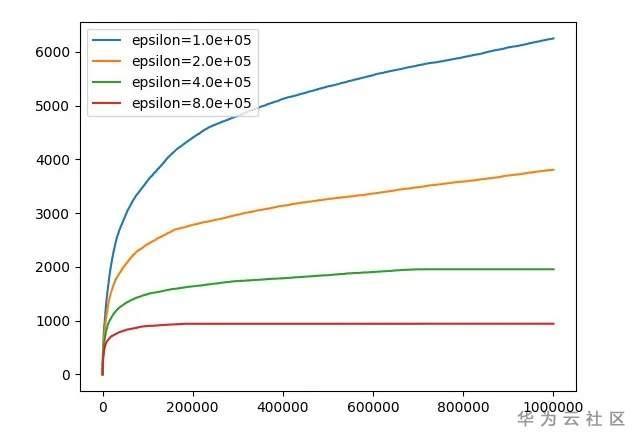
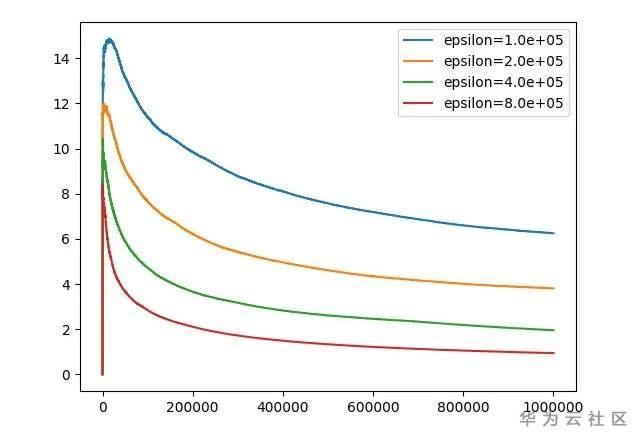
我们测试不同的 \varepsilonε 对累积 regret 对影响:
- x 轴:交互轮数
- y 轴:累积 regret

相关模型代码已上线 MindSpore Model Zoo:https://gitee.com/mindspore/mindspore/tree/master/model_zoo感兴趣的可自行体验。
1. Kai Zheng, Tianle Cai, Weiran Huang, Zhenguo Li, Liwei Wang. "Locally Differentially Private (Contextual) Bandits Learning." Advances in Neural Information Processing Systems. 2020.
2. LDP LinUCB 代码:
https://gitee.com/mindspore/mindspore/tree/master/model_zoo/research/rl/ldp_linucb
本文分享自华为云社区《MindSpore 首发:隐私保护的 Bandit 算法,实现电影推荐》,原文作者:chengxiaoli。
MindSpore:基于本地差分隐私的 Bandit 算法的更多相关文章
- 差分隐私(Differential Privacy)定义及其理解
1 前置知识 本部分只对相关概念做服务于差分隐私介绍的简单介绍,并非细致全面的介绍. 1.1 随机化算法 随机化算法指,对于特定输入,该算法的输出不是固定值,而是服从某一分布. 单纯形(simplex ...
- 每天进步一点点------Sobel算子(3)基于彩色图像边缘差分的运动目标检测算法
摘 要: 针对目前常用的运动目标提取易受到噪声影响.易出现阴影和误检漏检等情况,提出了一种基于Sobel算子的彩色边缘图像检测和帧差分相结合的检测方法.首先用Sobel算子提取视频流中连续4帧图像的 ...
- MindArmour差分隐私
MindArmour差分隐私 总体设计 MindArmour的Differential-Privacy模块,实现了差分隐私训练的能力.模型的训练主要由构建训练数据集.计算损失.计算梯度以及更新模型参数 ...
- 基于DFA敏感词查询的算法简析
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景 项目中需要对敏感词做一个过滤,首先有几个方案可以选择: a.直 ...
- 基于SNMP的路由拓扑发现算法收集
一.三层(网络层)发现 算法来源:王娟娟.基于SNMP的网络拓扑发现算法研究.武汉科技大学硕士学位论文,2008 数据结构: 待检路由设备网关链表:存放指定深度内待检路由设备的网关信息,处理后删除. ...
- 一个好用的多方隐私求交算法库JasonCeng/MultipartyPSI-Pro
Github链接传送:JasonCeng/MultipartyPSI-Pro 大家好,我是阿创,这是我的第29篇原创文章. 今天是一篇纯技术性文章,希望对工程狮们有所帮助. 向大家推荐一个我最近改造的 ...
- 基于本地存储的kvm虚拟机在线迁移
基于本地存储的kvm虚拟机在线迁移 kvm虚拟机迁移分为4种(1)热迁移基于共享存储(2)热迁移基于本地存储(3)冷迁移基于共享存储(4)冷迁移基于本地存储 这里介绍的是基于本地存储的热迁移 动态块迁 ...
- <<一种基于δ函数的图象边缘检测算法>>一文算法的实现。
原始论文下载: 一种基于δ函数的图象边缘检测算法. 这篇论文读起来感觉不像现在的很多论文,废话一大堆,而是直入主题,反倒使人觉得文章的前后跳跃有点大,不过算法的原理已经讲的清晰了. 一.原理 ...
- SVD++:推荐系统的基于矩阵分解的协同过滤算法的提高
1.背景知识 在讲SVD++之前,我还是想先回到基于物品相似的协同过滤算法.这个算法基本思想是找出一个用户有过正反馈的物品的相似的物品来给其作为推荐.其公式为:
随机推荐
- 主席树 【权值线段树】 && 例题K-th Number POJ - 2104
一.主席树与权值线段树区别 主席树是由许多权值线段树构成,单独的权值线段树只能解决寻找整个区间第k大/小值问题(什么叫整个区间,比如你对区间[1,8]建立一颗对应权值线段树,那么你不能询问区间[2,5 ...
- 在.NET中体验GraphQL
前言 以前需要提供Web服务接口的时候,除了标准的WEBAPI形式,还考虑了OData.GraphQL等形式,虽然实现思路上有很大的区别,但对使用方来说,都是将查询的主动权让渡给了前端,让调用方能够更 ...
- OpenStack Train版-8.安装neutron网络服务(控制节点)
安装neutron网络服务(controller控制节点192.168.0.10) 创建neutron数据库 mysql -uroot CREATE DATABASE neutron; GRANT A ...
- 超详细 DNS 协议解析
尽人事,听天命.博主东南大学研究生在读,热爱健身和篮球,正在为两年后的秋招准备中,乐于分享技术相关的所见所得,关注公众号 @ 飞天小牛肉,第一时间获取文章更新,成长的路上我们一起进步 本文已收录于 C ...
- HDU 4649 Professor Tian(概率DP)题解
题意:一个表达式,n + 1个数,n个操作,每个操作Oi和数Ai+1对应,给出每个操作Oi和数Ai+1消失的概率,给出最后表达式值得期望.只有| , ^,&三个位操作 思路:显然位操作只对当前 ...
- freeRTOS V10.0.1移植到STM32F407标准库 - 环境Keil5
最近因为工作需要用到FreeRTOS,其实开始本人内心是拒绝的因为自己只学习过UCOSIII还没实际上过什么大又复杂的工程,但是谁让FreeRTOS他是Free的呢公司成本考虑肯定是不会选择USOS的 ...
- DLL & Dynamic-link library
DLL & Dynamic-link library 动态链接库 .dll 动态链接库(英语:Dynamic-link library,缩写为 DLL)是微软公司在微软视窗操作系统中实现共享函 ...
- The Best One iOS Contacts App
The Best One iOS Contacts App iPhone Contacts App SwiftUI Awesome iOS Contacts App 一款高度还原华为通讯录 iOS A ...
- bash for mac
bash for mac https://sourabhbajaj.com/mac-setup/iTerm/ https://sourabhbajaj.com/mac-setup/iTerm/zsh. ...
- YAML & .yml
YAML & .yml YAML: YAML Ain't Markup Language https://yaml.org/ https://github.com/yaml/www.yaml. ...