懵了!女朋友突然问我MVCC实现原理
前言
都知道事务的可重复读级别实现原理是使用MVCC实现的,那么你对MVCC的底层实现原理知道多少呢?面试高频点,你值得拥有。
一、MVCC到底是什么?
MVCC即多版本控制器,其特点就是在同一时间,不同事务可以读取到不同版本的数据,从而去解决脏读和不可重复读的问题。

这样的解释你看了不下几十遍了吧!但是你真的理解什么是多版本控制器吗?
生活案例:搬家
最近小Q跟自己的女朋友搬到新家,由于出小区的时候需要支付当月的物业费。
于是小Q跟自己的女朋友同时登录了小区提供的物业缴费系统。
悲观并发控制
假设小Q正在查当月需要缴纳的费用是多少进行支付的时候,此时小Q查询的这条数据是已经被锁定的。
那么小Q女朋友是无法访问该数据的,直至小Q支付完成或者退出系统将悲观锁释放,小Q的女朋友才可以查询到数据。
悲观锁保证在同一时间只能有一个线程访问,默认数据在访问的时候会产生冲突,然后在整个过程都加上了锁。
这样的系统对于用户来说就是毫无体验感,如果多个人同时需要访问一条信息,只能在一台设备上看喽!
乐观并发控制
在小Q查看物业费欠费情况,并且支付的同时,小Q的女朋友也可以访问到该数据。
乐观锁认为即使在并发环境下,也不会产生冲突问题,所以不会去做加锁操作。
而是在数据提交的时候进行检测,如果发现有冲突则返回冲突信息。
小结
Innodb的MVCC机制就是乐观锁的一种体现,读不加锁,读写不冲突,在不加锁的情况下能让多个事务进行并发读写,并且解决读写冲突问题,极大的提高系统的并发性
二、悲观锁、乐观锁
锁按照粒度分为表锁、行锁、页锁。
按照使用方式分为共享锁、排它锁。
根据思想分为乐观锁、悲观锁。
无论是乐观锁、悲观锁都只是一种思想而已,并不是实际的锁机制,这点一定要清楚。
1. 悲观锁(悲观并发控制)
悲观锁实际为悲观并发控制,缩写PCC。
悲观锁持消极态度,认为每一次访问数据时,总是会发生冲突,因此,每次访问必须先锁住数据,完成访问后在释放锁。
保证在同一时间只有单个线程可以访问,实现数据的排它性。同时悲观锁使用数据库自身的锁机制实现,可以解决读-写,写-写的冲突。
那么在什么场景下可以使用悲观锁呢!
悲观锁适用于在写多读少的并发环境下使用,虽然并发效率不高,但是保证了数据的安全性。
2. 乐观锁(乐观并发控制)
跟悲观锁一样,乐观锁实际为乐观并发控制,缩写为OCC。
乐观锁相对于悲观锁而言,认为即使在并发环境下,外界对数据的操作不会产生冲突,所以不会去加锁,而是会在提交更新的时候才会正式的对数据冲突与否进行检测。
如果发现冲突,要么再重试一次,要么切换为悲观的策略。
乐观并发控制要解决的是数据库并发场景下的写-写冲突,指用无锁的方式去解决
三、MVCC解决了哪些问题
在事务并发的情况下会产生以下问题。
脏读:读取其它事务未提交的数据。 不可重复读:一个事务在读取一条数据时,由于另一个事务修改了这条数据并且提交事务,再次读取时导致数据不一致 幻读:一个事务读取了某个范围的数据,同时另一个事务新增了这个范围的数据,再次读取发现俩次得到的结果不一致。
MVCC在Innodb存储引擎的实现主要是为了提高数据库并发能力,用更好的方式去处理读--写冲突,同时做到不加锁、非阻塞并发读写。
mvcc可以解决脏读,不可重复读,mvcc使用快照读解决了部分幻读问题,但是在修改时还是使用当前读,所以还是存在幻读问题,幻读问题最终就是使用间隙锁解决。
四、当前读、快照读
在了解MVCC是如何解决事务并发带来的问题之前,需要先明白俩个概念,当前读、快照读。
1. 当前读
给读操作加上共享锁、排它锁,DML操作加上排它锁,这些操作就是当前读。
共享锁、排它锁也被称之为读锁、写锁。
共享锁与共享锁是共存的,但是要修改、添加、删除时,必须等到共享锁释放才可进行操作。
因为在Innodb存储引擎中,DML操作都会隐式添加排它锁。
所以说当前读所读取的记录就是最新的记录,读取数据时加上锁,保证其它事务不能修改当前记录。
2. 快照读
如果你看到这里就默认你对隔离级别有一定的了解哈!
快照读的前提是隔离级别不是串行级别,串行级别的快照读会退化成当前读。
快照读的出现旨在提高事务并发性,其实现基于本文的主角MVCC即多版本控制器。
MVCC可以认为是行锁的一个变种,但是它在很多情况下避免了加锁操作。
所以说快照读的数据有可能不是最新的,而是之前版本的数据。
为什么要提到快照读呢!因为read-view就是通过快照读生成的,为了防止后文概念模糊,所以在这里进行说明。
3. 如何区分当前读、快照读
不加锁的简单的select都属于快照读。
select id name user where id = 1;
与之对应的则是当前读,给select加上共享锁、排它锁。
select id name from user where id = 1 lock in share mode;
select id name from user where id = 1 for update;
五、MVCC实现三大要素
终于来到本文最重要的部分,前边的叙述都是为了给原理这一块做铺垫。
在这之前需要知道MVCC只在REPEATABLE READ(可重复读) 和 READ COMMITTED(已读提交)这俩种隔离级别下适用。
MVCC实现原理是由俩个隐式字段、undo日志、Read view来实现的。
1. 隐式字段
在Innodb存储引擎中,在有聚簇索引的情况下每一行记录中都会隐藏俩个字段,如果没有聚簇索引则还有一个6byte的隐藏主键。
这俩个隐藏列一个记录的是何时被创建的,一个记录的是什么时候被删除。
这里不要理解为是记录的是时间,存储的是事务ID。
俩个隐式字段为DB_TRX_ID,DB_ROLL_PTR,没有聚簇索引还会有DB_ROW_ID这个字段。
DB_TRX_ID:记录创建这条数据上次修改它的事务 ID DB_ROLL_PTR:回滚指针,指向这条记录的上一个版本
隐式字段实际还有一个delete flag字段,即记录被更新或删除,这里的删除并不代表真的删除,而是将这条记录的delete flag改为true(这里埋下一个伏笔,数据库的删除是真的删除吗?)
2. undo log(回滚日志)
之前对undo log的作用只提到了回滚操作实现原子性,现在需要知道的另一个作用就是实现MVCC多版本控制器。
undo log细分为俩种,insert时产生的undo log、update,delete时产生的undo log
在Innodb中insert产生的undo log在提交事务之后就会被删除,因为新插入的数据没有历史版本,所以无需维护undo log。
update和delete操作产生的undo log都属于一种类型,在事务回滚时需要,而且在快照读时也需要,则需要维护多个版本信息。只有在快照读和事务回滚不涉及该日志时,对应的日志才会被purge线程统一删除。
purge线程会清理undo log的历史版本,同样也会清理del flag标记的记录。
undo log在mvcc中的作用
写到这里关于undo log在mvcc中的作用估计还是蒙圈的。
undo log保存的是一个版本链,也就是使用DB_ROLL_PTR这个字段来连接的。
当数据库执行一个select语句时会产生一致性视图read view。
那么这个read view是由查询时所有未提交事务ID组成的数组,数组中最小的事务ID为min_id和已创建的最大事务ID为max_id组成,查询的数据结果需要跟read-view做比较从而得到快照结果。
所以说undo log在mvcc中的作用就是为了根据存储的事务ID和一致性视图做对比,从而得到快照结果。
3. undo log底层实现
假设一开始的数据为下图
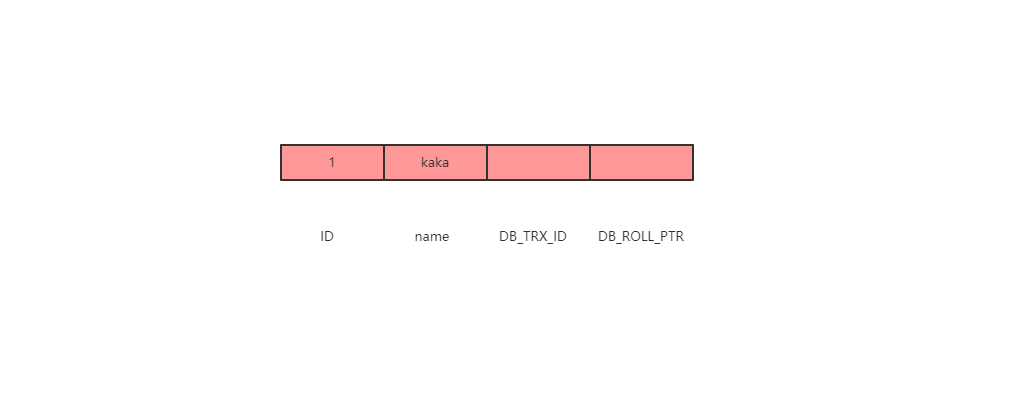
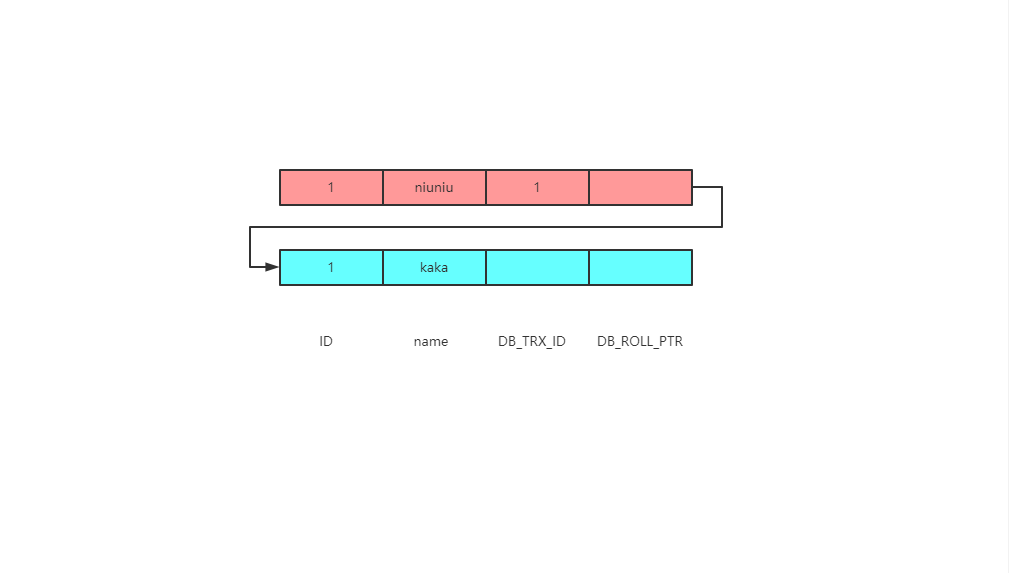
此时执行了一条更新的SQL语句update user set name = 'niuniu where id = 1',那么undo log的记录就会发生变化
也就是说当执行一条更新语句时会把之前的原有数据拷贝到undo log日志中。
同时你可以看见最新的一条记录在末尾处连接了一条线,也就是说DB_ROLL_PTR记录的就是存放在undo log日志的指针地址。
最终有可能需要通过指针来找到历史数据。
4. read-view
当执行SQL语句查询时会产生一致性视图,也就是read-view,它是由查询的那一时间所有未提交事务ID组成的数组,和已经创建的最大事务ID组成的。
在这个数组中最小的事务ID被称之为min_id,最大事务ID被称之为max_id,查询的数据结果要根据read-view做对比从而得到快照结果。
于是就产生了以下的对比规则,这个规则就是使用当前的记录的trx_id跟read-view进行对比,对比规则如下。
5. 版本链对比规则
如果落在trx_id<min_id,表示此版本是已经提交的事务生成的,由于事务已经提交所以数据是可见的
如果落在trx_id>max_id,表示此版本是由将来启动的事务生成的,是肯定不可见的
若在min_id<=trx_id<=max_id时
如果row的trx_id在数组中,表示此版本是由还没提交的事务生成的,不可见,但是当前自己的事务是可见的 如果row的trx_id不在数组中,表明是提交的事务生成了该版本,可见
在这里还有一个特殊情况那就是对于已经删除的数据,在之前的undo log日志讲述时说了update和delete是同一种类型的undo log,同样也可以认为delete就是update的特殊情况。
当删除一条数据时会将版本链上最新的数据复制一份,然后将trx_id修改为删除时的trx_id,同时在该记录的头信息中存在一个delete flag标记,将这个标记写上true,用来表示当前记录已经删除。
在查询时按照版本链的规则查询到对应的记录,如果delete flag标记位为true,意味着数据已经被删除,则不返回数据。
如果你对这里的read-view的生成和版本链对比规则不懂,不要着急,也不要在这里浪费时间,请继续往下看,咔咔会使用一个简单的案例和一个复杂的案例给大家重现上述的规则。
六、MVCC底层原理
案例一
下图是准备的素材,这里应该都理解select 返回的结果为niuniu,即事务102修改后的结果

从上图中可以看到有三个事务正在进行。
事务ID为100、101是修改的其它表,只有事务ID为102修改的需要查询的这张表。
接下来看看select这一列查询返回的结果是不是就是事务ID为102修改的结果。
此时生成的read-view为[100,101],102
那么现在就可以返回去看一下read-view规则,在这里事务ID100就是min_id,事务ID102就是max_id。
这个 select语句返回结果肯定是 niuniu。
那么接下来看一下在MVCC中是如何查找数据的。
当前版本链。
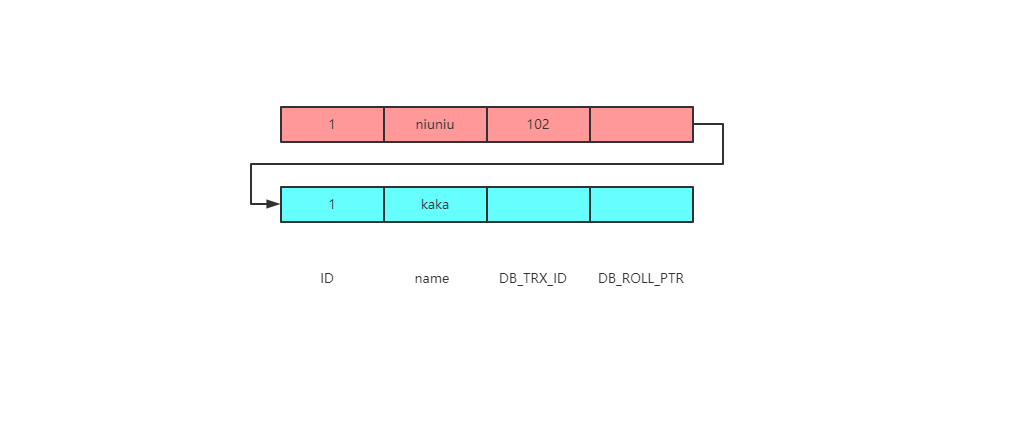
那么就会拿着trx_id 为102进行比对,会发现这个102就是max_id
然后你再看一下版本链的对比规则中第三种情况
如果落在min_id<=trx_id<=max_id会存在俩种情况
此时信息就已经非常明确了,事务ID102是没有在数组中的,所以表示这个版本是已经提交的事务生成的,那么就是可见的呗!
毫无疑问查询会返回niuniu这个值
先通过这个简单的案例让你对版本链有一个简单的理解,接下来将使用一个比较繁琐的案例再来跟大家演示一遍。
案例二
本例要求知道 select的第二个查询结果。深黑色字体。
同样是在kaka那一条记录的基础上。

当事务ID100两次更新后,版本链也会改变,现在的版本链如下图,红色部分为最新数据,蓝色数据为undo log的版本链数据。
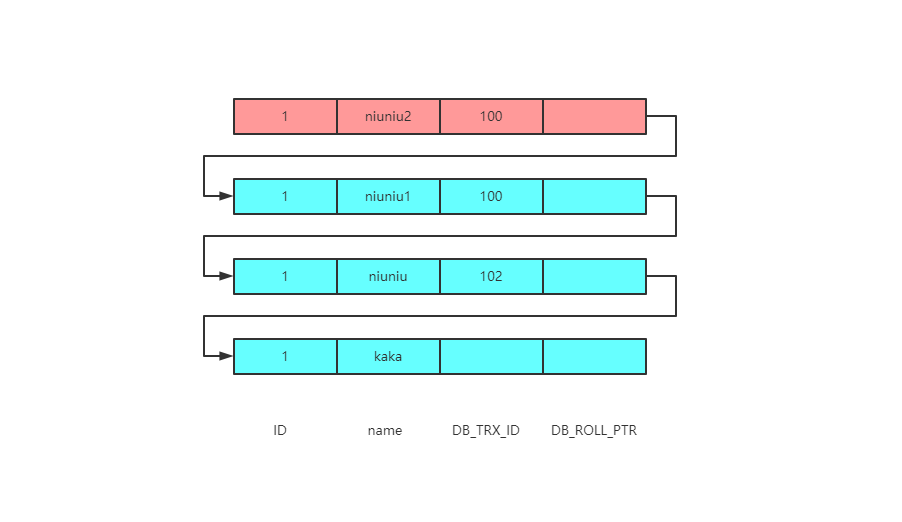
对于此时生成的read-view你会有什么疑问,在RR级别也就是可重复读的隔离级别下。
当在一个事务下执行查询时,所有的read-view都是沿用的第一条查询语句生成的。
那此时的read-view也就是[100,101],102
看一下底层查找步骤
目前数据的事务ID为100 根据规则会落在min_id<=trx_id<=max_id这个区间 并且当前行的事务ID100是在read-view的数组中的,表示此时事务还没有提交则不可见 继续在版本链中往下寻找,此时找到的事务ID还是100,跟上述流程一致 通过查找版本链,将发现事务 ID为102 102是read-view的max_id,同样也会落在min_id<=trx_id<=max_id这个区间,但是跟之前不同的是事务102是没有在数组中的,表示这个版本事务已经提交了所以是可见的 最后返回的是 niuniu
案例三
为了让大家体验一下可重复读级别生成的read-view是根据在同一事务中第一条快照读产生的,再来看一个案例
此时的事务ID101也再对数据更新两次,然后在进行查询看一下会返回什么值

经过案例一、案例二的熟悉现在对undo log的版本链和对比规则已经有了一定的了解了吧!
案例三就不在那么详细的说明了。
此时的版本链如下
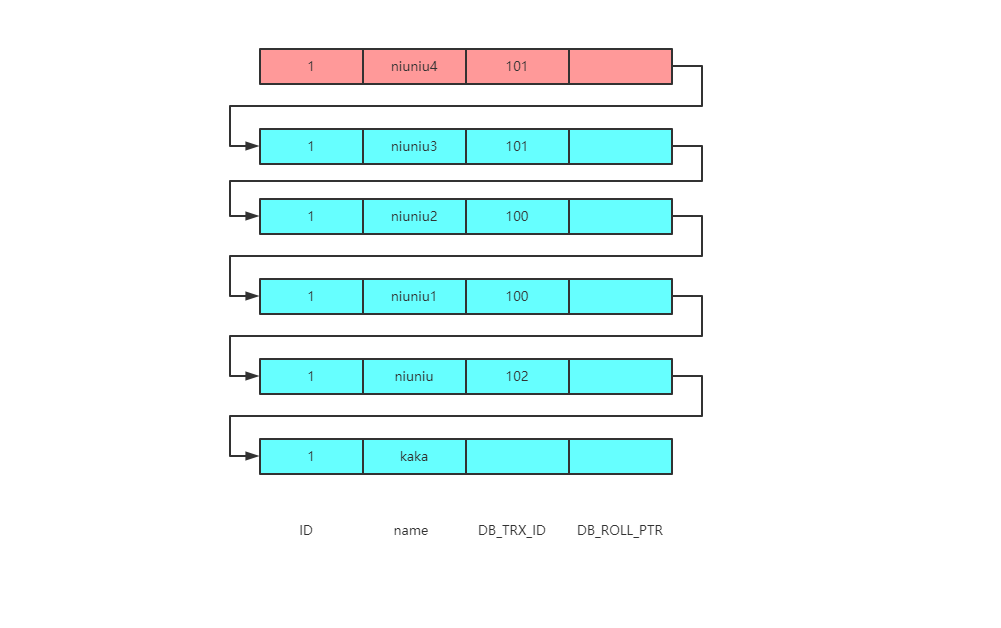
此时的read-view依然为[100,101],102。
那么首先会根据事务101去版本链对比,事务101和事务100都会落在min_id<=trx_id<=max_id这个区间,并且还都在数组中,所以数据是不可见的。
那么继续往版本链中寻找就会遇到事务102,这个是最大的事务ID并且不在数组中,所以是可见的。
于是最终的返回结果还是niuniu。
案例四
可以看到个案例三的图不同的是新增了一个查询语句,那么假设这俩条语句执行的时间都是一致的,它们返回的结果会相同吗?
案例三查询到的值为niuniu

其实现在版本链跟案例三也是一致的
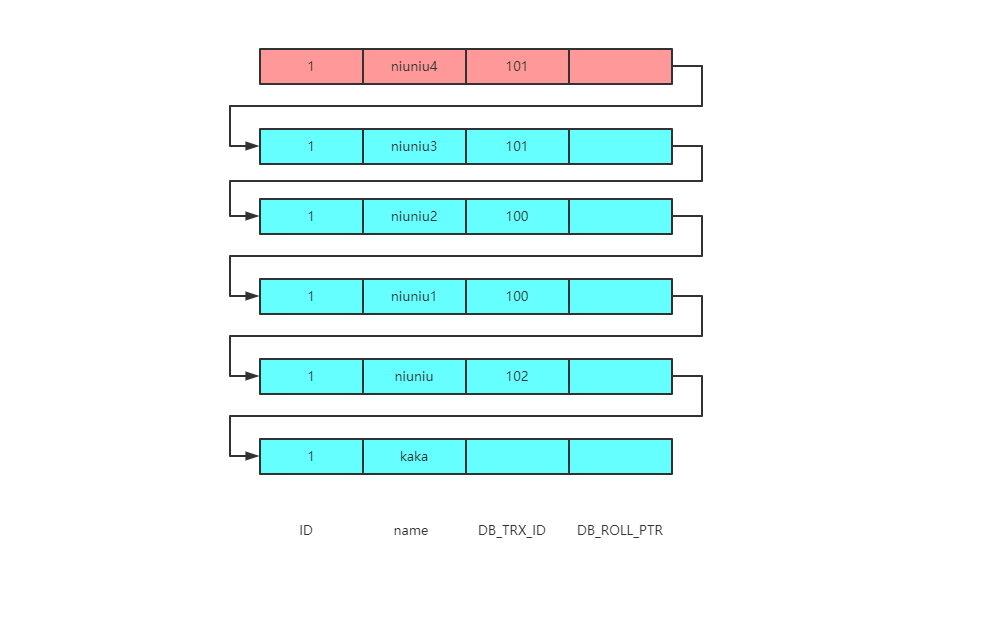
那么来梳理一下寻找过程
首先这里的read-view发生了变化,此时的read-view为 [101],102拿着当前的事务ID101跟版本链规则进行对比,落盘在min_id<=trx_id<=max_id,并且在数组中,则数据不可见 然后进入版本链,找到下一个数据的事务 ID,还是101,与上一个一致 接下来是事务ID100 事务ID100是落在trx_id<min_id,表示此版本是已经提交的事务生成的,由于事务已经提交所以数据是可见的 所以最终返回结果为 niuniu2
小结
在同一个事务中进行查询,会沿用第一次查询语句生成的read-view(前提是隔离级别是在可重复读)
通过以上的四个案例,在版本链寻找过程中,可以总结出一个小技巧
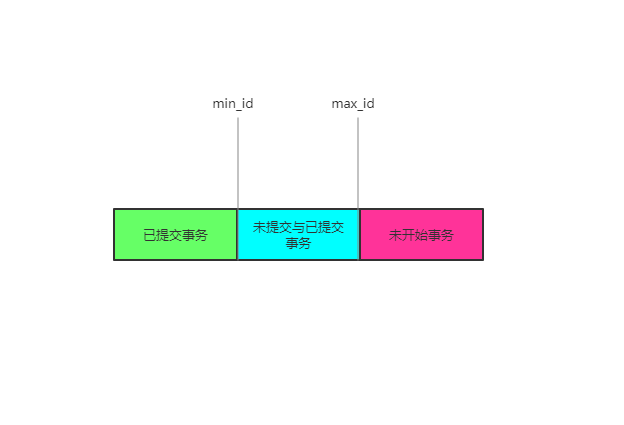
根据这个小技巧你可以很快的得知此版本是否可见。
如果当前的事务ID在绿色部分,是已经提交事务,则数据可见 如果当前的事务ID在蓝色部分,会有俩种情况,如果当前事务ID在read-view数组内,是没有提交的事务不可见,如果不在数组内数据可见 如果落在红色部分,则不考虑,对于未来的事情不去想即可。
七、总结
阅读本文后,在面试过程中极大可能会遇到的问题就是聊聊你对mvcc的认识。
本文内容从浅到深,从什么是mvcc到mvcc的底层实现,一步一步地陈述了mvcc的实现原理。
本文简单总结
mvcc在不加锁的情况下解决了脏读、不可重复读和快照读下的幻读问题,一定不要认为幻读完全是mvcc解决的 对当前读、快照读理解,简单点说加锁就是当前读,不加锁的就是快照读。 mvcc实现的三大要素俩个隐式字段、回滚日志、read-view 俩个隐式字段:DB_TRX_ID:记录创建这条记录最后一次修改该记录的事务ID,DB_ROLL_PTR:回滚指针,指向这条记录的上一个版本 undo log在更新数据时会产生版本链,是read-view获取数据的前提 read-view当SQL执行查询语句时产生的,是由为提交的事务ID组成的数组和创建的最大事务ID组成的 版本链规则看第六节的小结即可
“
坚持学习、坚持写作、坚持分享是咔咔从业以来一直所秉持的信念。希望在偌大互联网中咔咔的文章能带给你一丝丝帮助。我是咔咔,下期见。
”
懵了!女朋友突然问我MVCC实现原理的更多相关文章
- 女朋友突然问我DNS是个啥....
女朋友突然问我DNS是个啥.... 今天晚上我正在床上躺着刷手机,然后我女朋友突然说她的电脑坏了.说连着WIFi上不了网,让我给她看一下.(这就是有个程序员男朋友的好处) 然后我拿到电脑看了一下发现访 ...
- [ZZ]如果有人问你数据库的原理,叫他看这篇文章
如果有人问你数据库的原理,叫他看这篇文章 http://blog.jobbole.com/100349/ 文章把知识链都给串起来,对数据库做一个概述. 合并排序 阵列.树和哈希表 B+树索引概述 数据 ...
- (转)InnoDB存储引擎MVCC实现原理
InnoDB存储引擎MVCC实现原理 原文:https://liuzhengyang.github.io/2017/04/18/innodb-mvcc/ 简单背景介绍 MySQL MySQL是现在最流 ...
- 「MySQL高级篇」MySQL之MVCC实现原理&&事务隔离级别的实现
大家好,我是melo,一名大三后台练习生,死去的MVCC突然开始拷打我! 引言 MVCC,非常顺口的一个词,翻译起来却不是特别顺口:多版本并发控制. 其中多版本是指什么呢?一条记录的多个版本. 并发控 ...
- 昨晚12点,女朋友突然问我:你会RabbitMQ吗?我竟然愣住了。
01为什么要用消息队列? 1.1 同步调用和异步调用 在说起消息队列之前,必须要先说一下同步调用和异步调用. 同步调用:A服务去调用B服务,需要一直等着B服务,直到B服务执行完毕并把执行结果返回给A之 ...
- MySQL数据库InnoDB存储引擎多版本控制(MVCC)实现原理分析
文/何登成 导读: 来自网易研究院的MySQL内核技术研究人何登成,把MySQL数据库InnoDB存储引擎的多版本控制(简称:MVCC)实现原理,做了深入的研究与详细的文字图表分析,方便大家理解I ...
- InnoDB的MVCC实现原理
InnoDB的MVCC,是通过在每行记录后面保存两个隐藏的列来实现的. 这两个列,一个保存了行的创建时间,一个保存了行的过期时间(删除时间).当然存储的并不是实际时间,而是系统版本号(sytem ve ...
- mysql MVCC 实现原理
MVCC( Multi-Version Concurrency Controll) 每一行都存储了事件发生时的系统版本号(System Version Number),用来替代事件实际发生的时间.每一 ...
- 面试官再问你 HashMap 底层原理,就把这篇文章甩给他看
前言 HashMap 源码和底层原理在现在面试中是必问的.因此,我们非常有必要搞清楚它的底层实现和思想,才能在面试中对答如流,跟面试官大战三百回合.文章较长,介绍了很多原理性的问题,希望对你有所帮助~ ...
随机推荐
- CI / CD in Action
CI / CD in Action Continuous Integration (CI) & Continuous Delivery (CD) https://github.com/mark ...
- flex & flex-wrap
flex & flex-wrap https://css-tricks.com/almanac/properties/f/flex-wrap/ https://developer.mozill ...
- vscode & peacock extension
vscode & peacock extension https://marketplace.visualstudio.com/items?itemName=johnpapa.vscode-p ...
- SSR & 轮询登录 & Token
SSR & 轮询登录 & Token https://yuchengkai.cn/docs/frontend 扫码登录原理 https://www.cnblogs.com/xgqfrm ...
- 12.scikit-learn中的Scaler
import numpy as np from sklearn import datasets iris = datasets.load_iris() X = iris.data y = iris.t ...
- IDEA总结
1. 什么是idea? idea是Java开发软件 2. IDEA下载 https://www.jetbrains.com/idea/download/download-thanks.html?pla ...
- oracle ora-01114 IO error writing block to file 207 (block # )
oracle ORA-01114 IO error writing block to file 207 (block # ) Reference: https://stackoverflow.com/ ...
- RabbitMQ(一)安装篇
1. RabbitMQ 的介绍➢ 什么是 MQ?MQ 全称为 Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法.➢ 要解决什么样的问题?在项目中,将一些无需即时返回且耗 ...
- AVR单片机教程——第三期导语
背景(一) 寒假里做了一个灯带控制器: 理想情况下我应该在一个星期内完成这个项目,但实际上它耗费了我几乎一整个寒假,因为涉及到很多未曾尝试的方案.在这种不是很赶时间的.可以自定目标.自由发挥的项目中, ...
- C++类的友元机制说明
下面给出C++类的友元机制说明(对类private.protected成员访问),需要注意的是,友元机制尽量不用或者少用,虽然它会提供某种程度的效率,但会带来数据安全性的问题. 类的友元 友元是C++ ...