Python并发编程03 /僵孤进程,孤儿进程、进程互斥锁,进程队列、进程之间的通信
Python并发编程03 /僵孤进程,孤儿进程、进程互斥锁,进程队列、进程之间的通信
1. 僵尸进程/孤儿进程
1. 僵尸进程
定义:僵尸进程是当子进程比父进程先结束,而父进程又没有利用wait/waitpid回收子进程、释放子进程占用的资源,此时子进程将成为一个僵尸进程
主进程与子进程之间的关系
基于unix环境(linux,macOS):主进程时刻监测子进程的运行状态,当子进程结束之后,一段时间之内,将子进程进行回收,主进程需要等待子进程结束之后,主进程才结束。
window环境:Windows没有僵尸进程这个概念。
为什么主进程不在子进程结束后马上对其回收,子进程为什么不在结束后马上释放内存资源
- 主进程与子进程是异步关系.主进程无法马上捕获子进程什么时候结束.
- 如果子进程结束之后马上在内存中释放资源,主进程就没有办法监测子进程的状态了
- unix针对于上面的问题,提供了一个机制:所有的子进程结束之后,立马会释放掉文件的操作链接,内存的大部分数据,但是会保留一些内容: 进程号,结束时间,运行状态,等待主进程监测,回收.
所有的子进程结束之后,在被主进程回收之前,都会进入僵尸进程状态.
僵尸进程有无危害
如果父进程不对僵尸进程进行回收(wait/waitpid),产生大量的僵尸进程,这样就会占用内存,占用进程pid号.
僵尸进程如何解决
父进程产生了大量子进程,但是不回收,这样就会形成大量的僵尸进程,解决方式就是直接杀死父进程,将所有的僵尸进程变成孤儿进程进程,由init进行回收.
2. 孤儿进程
- 定义:孤儿进程指的是在其父进程执行完成或被终止后仍继续运行的一类进程。这些孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
- 父进程由于某种原因结束了,但是子进程还在运行中,这样这些子进程就成了孤儿进程.父进程如果结束了,所有的孤儿进程就会被init进程的回收,init就变成了父进程,对其进行回收.
2. 进程互斥锁
互斥锁的应用
代码示例:三个同事同时用一个打印机打印内容,三个进程模拟三个同事, 输出平台模拟打印机
版本一:
from multiprocessing import Process
import time
import random
import os def task1():
print(f'{os.getpid()}开始打印了')
time.sleep(random.randint(1,3))
print(f'{os.getpid()}打印结束了') def task2():
print(f'{os.getpid()}开始打印了')
time.sleep(random.randint(1,3))
print(f'{os.getpid()}打印结束了') def task3():
print(f'{os.getpid()}开始打印了')
time.sleep(random.randint(1,3))
print(f'{os.getpid()}打印结束了') if __name__ == '__main__': p1 = Process(target=task1)
p2 = Process(target=task2)
p3 = Process(target=task3) p1.start()
p2.start()
p3.start() # 现在是所有的进程都并发的抢占打印机,造成了顺序的混乱
# 并发是以效率优先的,但是目前需求是: 顺序优先.
# 多个进程共强一个资源时, 要保证顺序优先: 串行,一个一个来,因此看版本二
版本二:
from multiprocessing import Process
import time
import random
import os def task1(p):
print(f'{p}开始打印了')
time.sleep(random.randint(1,3))
print(f'{p}打印结束了') def task2(p):
print(f'{p}开始打印了')
time.sleep(random.randint(1,3))
print(f'{p}打印结束了') def task3(p):
print(f'{p}开始打印了')
time.sleep(random.randint(1,3))
print(f'{p}打印结束了') if __name__ == '__main__': p1 = Process(target=task1,args=('p1',))
p2 = Process(target=task2,args=('p2',))
p3 = Process(target=task3,args=('p3',)) p2.start()
p2.join()
p1.start()
p1.join()
p3.start()
p3.join() # 利用join 解决串行的问题,保证了顺序优先,但是这个谁先谁后是固定的.
# 这样不合理. 在争抢同一个资源的时候,应该是先到先得,保证公平,因此看版本三
版本三:
from multiprocessing import Process
from multiprocessing import Lock
import time
import random
import os def task1(p,lock):
'''
一把锁不能连续锁两次
lock.acquire()
lock.acquire()
lock.release()
lock.release()
'''
lock.acquire()
print(f'{p}开始打印了')
time.sleep(random.randint(1,3))
print(f'{p}打印结束了')
lock.release() def task2(p,lock):
lock.acquire()
print(f'{p}开始打印了')
time.sleep(random.randint(1,3))
print(f'{p}打印结束了')
lock.release() def task3(p,lock):
lock.acquire()
print(f'{p}开始打印了')
time.sleep(random.randint(1,3))
print(f'{p}打印结束了')
lock.release() if __name__ == '__main__': mutex = Lock()
p1 = Process(target=task1,args=('p1',mutex))
p2 = Process(target=task2,args=('p2',mutex))
p3 = Process(target=task3,args=('p3',mutex)) p2.start()
p1.start()
p3.start()
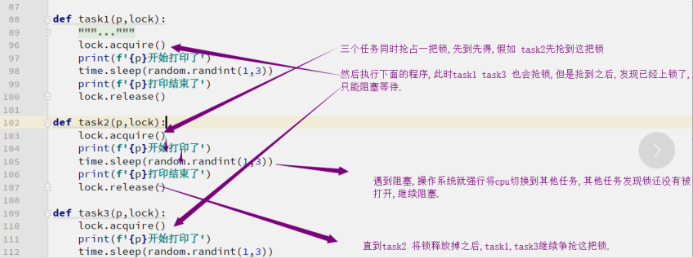
Lock与join的区别
共同点: 都可以把并发变成串行, 保证了顺序.
不同点: join人为设定顺序,lock让其争抢顺序,保证了公平性.
3. 进程队列
概念:
队列: 把队列理解成一个容器,这个容器可以承载一些数据
队列的特性: 先进先出永远保持这个数据. FIFO(first in first out).
存取操作:put() / get()
from multiprocessing import Queue q = Queue()
def func():
print('in func') q.put(1) # 整型
q.put('张三') # 字符串
q.put([1,2,3]) # 列表
q.put(func) # 函数 print(q.get())
print(q.get())
print(q.get())
f = q.get()
f()
当队列存满、空时
# 示例一:当队列满了时,在进行put数据就会阻塞.
from multiprocessing import Queue
q = Queue(3) q.put(1)
q.put('张三')
q.put([1,2,3])
q.put(5555) # 当队列满了时,在进行put数据就会阻塞.
q.get() # 示例二:当数据取完时,在进行get数据也会出现阻塞,直到某一个进行put数据.
from multiprocessing import Queue
q = Queue(3) q.put(1)
q.put('张三')
q.put([1,2,3])
print(q.get())
print(q.get())
print(q.get())
print(q.get()) # 当数据取完时,在进行get数据也会出现阻塞,直到某一个进行put数据.
队列queue的参数
from multiprocessing import Queue
q = Queue(3) # maxsize q.put(1)
q.put('张三')
q.put([1,2,3])
q.put(5555,block=False) print(q.get())
print(q.get())
print(q.get())
print(q.get(timeout=3)) # 阻塞3秒,3秒之后还阻塞直接报错.
print(q.get(block=False)) block=False # 只要遇到阻塞就会报错.
timeout=3 # 阻塞3秒,3秒之后还阻塞直接报错.
队列queue的方法
q.get(block=True/False) # 取值时只要遇到阻塞就会报错.
q.get(timeout=3) # 取值时,阻塞3秒,3秒之后还阻塞直接报错.
q.get_nowait() # 只要遇到阻塞就报错
q.empty() # 判断队列是否为空
q.full() # 判断队列是否已经存满
q.qsize() # 判断队列里边数据的多少
4. 进程之间的通信
进程在内存级别是隔离的
基于文件通信 / 模拟抢票系统
分析:
1. 先可以查票.查询余票数. 并发
2. 进行购买,向服务端发送请求,服务端接收请求,在后端将票数-1,返回到前端. 串行.
代码实现:
# 错误示例:造成了数据的不安全
from multiprocessing import Process
import json
import time
import os
import random def search():
time.sleep(random.randint(1,3)) # 模拟网络延迟(查询环节)
with open('ticket.json',encoding='utf-8') as f1:
dic = json.load(f1)
print(f'{os.getpid()} 查看了票数,剩余{dic["count"]}')
def paid():
with open('ticket.json', encoding='utf-8') as f1:
dic = json.load(f1)
if dic['count'] > 0:
dic['count'] -= 1
time.sleep(random.randint(1,3)) # 模拟网络延迟(购买环节)
with open('ticket.json', encoding='utf-8',mode='w') as f1:
json.dump(dic,f1)
print(f'{os.getpid()} 购买成功')
def task():
search()
paid() if __name__ == '__main__':
for i in range(6):
p = Process(target=task)
p.start() # 当多个进程共强一个数据时,如果要保证数据的安全,必须要串行.
# 要想让购买环节进行串行,我们必须要加锁处理.因此看正确示例 # 正确示例:加锁保证数据的不安全
from multiprocessing import Process
from multiprocessing import Lock
import json
import time
import os
import random def search():
time.sleep(random.randint(1,3)) # 模拟网络延迟(查询环节)
with open('ticket.json',encoding='utf-8') as f1:
dic = json.load(f1)
print(f'{os.getpid()} 查看了票数,剩余{dic["count"]}')
def paid():
with open('ticket.json', encoding='utf-8') as f1:
dic = json.load(f1)
if dic['count'] > 0:
dic['count'] -= 1
time.sleep(random.randint(1,3)) # 模拟网络延迟(购买环节)
with open('ticket.json', encoding='utf-8',mode='w') as f1:
json.dump(dic,f1)
print(f'{os.getpid()} 购买成功')
def task(lock):
search()
lock.acquire()
paid()
lock.release() if __name__ == '__main__':
mutex = Lock()
for i in range(6):
p = Process(target=task,args=(mutex,))
p.start() # 当很多进程抢一个资源(数据)时, 你要保证顺序(数据的安全),一定要串行.
# 互斥锁: 可以公平性的保证顺序以及数据的安全. # 基于文件的进程之间的通信:
# 效率低.
# 自己加锁麻烦而且很容易出现死锁.
基于队列通信
代码示例:
from multiprocessing import Process
from multiprocessing import Queue
import time
import random
import os
def search(count):
time.sleep(random.randint(1,2))
print(f'{os.getpid()} 查看了票数,剩余{count}张')
def pay(q):
dic = q.get()
time.sleep(random.randint(1,2))
if dic["count"] > 0:
print(f'{os.getpid()} 购买成功')
dic["count"] -= 1
q.put(dic)
else:
q.put(dic)
print(f'{os.getpid()} 购买失败') def task(q,count):
search(count)
pay(q) if __name__ == '__main__':
count = 3
q = Queue()
dic = {"count":count}
q.put(dic)
for i in range(5):
p = Process(target=task,args=(q,dic["count"]))
p.start()
Python并发编程03 /僵孤进程,孤儿进程、进程互斥锁,进程队列、进程之间的通信的更多相关文章
- 【漫画】JAVA并发编程 J.U.C Lock包之ReentrantLock互斥锁
在如何解决原子性问题的最后,我们卖了个关子,互斥锁不仅仅只有synchronized关键字,还可以用什么来实现呢? J.U.C包中还提供了一个叫做Locks的包,我好歹英语过了四级,听名字我就能马上大 ...
- java并发编程的艺术——第五章总结(Lock锁与队列同步器)
Lock锁 锁是用来控制多个线程访问共享资源的方式. 一般来说一个锁可以防止多个线程同时访问共享资源(但有些锁可以允许多个线程访问共享资源,如读写锁). 在Lock接口出现前,java使用synchr ...
- python并发编程——多线程
编程的乐趣在于让程序越来越快,这里将给大家介绍一个种加快程序运行的的编程方式--多线程 1 著名的全局解释锁(GIL) 说起python并发编程,就不得不说著名的全局解释锁(GIL)了.有兴趣的同 ...
- Python(并发编程进程)
并发编程 二.多进程 要让Python程序实现多进程(multiprocessing),我们先了解操作系统的相关知识. Unix/Linux操作系统提供了一个fork()系统调用,它非常特殊.普通的函 ...
- 《转载》Python并发编程之线程池/进程池--concurrent.futures模块
本文转载自Python并发编程之线程池/进程池--concurrent.futures模块 一.关于concurrent.futures模块 Python标准库为我们提供了threading和mult ...
- python并发编程之进程、线程、协程的调度原理(六)
进程.线程和协程的调度和运行原理总结. 系列文章 python并发编程之threading线程(一) python并发编程之multiprocessing进程(二) python并发编程之asynci ...
- Python进阶(4)_进程与线程 (python并发编程之多进程)
一.python并发编程之多进程 1.1 multiprocessing模块介绍 由于GIL的存在,python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大 ...
- Python并发编程05 /死锁现象、递归锁、信号量、GIL锁、计算密集型/IO密集型效率验证、进程池/线程池
Python并发编程05 /死锁现象.递归锁.信号量.GIL锁.计算密集型/IO密集型效率验证.进程池/线程池 目录 Python并发编程05 /死锁现象.递归锁.信号量.GIL锁.计算密集型/IO密 ...
- Python并发编程04 /多线程、生产消费者模型、线程进程对比、线程的方法、线程join、守护线程、线程互斥锁
Python并发编程04 /多线程.生产消费者模型.线程进程对比.线程的方法.线程join.守护线程.线程互斥锁 目录 Python并发编程04 /多线程.生产消费者模型.线程进程对比.线程的方法.线 ...
随机推荐
- python + selenium登陆并点击百度平台
from PIL import Imagefrom selenium.webdriver import DesiredCapabilitiesfrom selenium import webdrive ...
- PuTTY通过SSH连接上Ubuntu20.04
在PuTTY中连接到Ubuntu20.04大致需要几个步骤(不一定对应文本中的序号):1) 安装opensh-server (Ubuntu安装好之后 ,一般openssh-client自动已经安装好) ...
- SQL2008R2安装碰到问题的解决方法(iso文件用对应的工具)
SQL2008R2安装碰到问题的解决方法 安装谁不会啊,这么简单,是啊,可是匹配包时就不是那么顺利啊.就像以前的Ruby还专挑匹配版本的包一样,不像现在的Py自动为我们找,这是Mar 7贴在Q ...
- delphi 控件查询
//老古董,以前这些东西太多了,收藏的没过来,只好粘贴至此,当然不是本人整理的. delphi 控件查询:http://www.torry.net/ http://www.jrsoftware.org ...
- Excel怎样根据出生日期,快速计算出其年龄呢?
问题:怎样根据出生日期,快速计算出其年龄呢? 方法:DATEDIF函数 Step1:在编辑栏中输入公式:=DATEDIF(E2,TODAY(),”Y”),按回车键. Step2:用鼠标向下拖拽复制公式 ...
- Charles抓包2-Charles抓包https请求
目录 1.开启SSL代理 2.安装证书 3.导出证书 4.浏览器安装证书 1.开启SSL代理 菜单,代理-->SSL代理设置 勾选启用SSL代理 在包括选项,添加主机:*,端口:443 确定保存 ...
- (三)Maven命令列表
mvn –version 显示版本信息 mvn clean 清理项目生产的临时文件,一般是模块下的target目录 mvn compile 编译源代码,一般编译模块下的src/main/java目录, ...
- 资料共享-源代码-视频教程-PLC-OpenCV-C++-MFC
资料共享-源代码-视频教程-PLC-OpenCV-C++-MFC 资料共享-源代码-视频教程 资料共享-源代码-视频教程-PLC-OpenCV-C++-MFC
- 面试问Redis集群,被虐的不行了......
哨兵主要针对单节点故障无法自动恢复的解决方案,集群主要针对单节点容量.并发问题.线性可扩展性的解决方案.本文使用官方提供的redis cluster.文末有你们想要的设置ssh背景哦! 本文主要围绕如 ...
- selenium(5)-解读强制等待,隐式等待,显式等待的区别
背景 为什么要设置元素等待 因为,目前大多数Web应用程序都是使用Ajax和Javascript开发的:每次加载一个网页,就会加载各种HTML标签.JS文件 但是,加载肯定有加载顺序,大型网站很难说一 ...