02.Flink的单机wordcount、集群安装
一、单机安装
1.准备安装包
将源码编译出的安装包拷贝出来(编译请参照上一篇01.Flink笔记-编译、部署)或者在Flink官网下载bin包
2.配置
前置:jdk1.8+
修改配置文件flink-conf.yaml
#Flink的默认WebUI端口号是8081,如果有冲突的服务,可更改
rest.port: 18081
其余项选择默认即可
3.启动
- Linux:
./bin/start-cluster.sh
- Win:
cd bin
start-cluster.bat
win本地启动如下(图片模糊可右击在新标签中打开)
二、单机WordCount
1.java版本
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* @author :qinglanmei
* @date :Created in 2019/4/10 11:10
* @description:flink的java版本window示例
*/
public class WindowWordCount {
public static void main(String[] args) throws Exception{
final String hostname;
final int port;
try {
final ParameterTool params = ParameterTool.fromArgs(args);
hostname = params.has("hostname") ? params.get("hostname") : "localhost";
port = params.has("port") ? params.getInt("port"):9999;
} catch (Exception e) {
System.err.println("No port specified. Please run 'SocketWindowWordCount " +
"--hostname <hostname> --port <port>', where hostname (localhost by default) " +
"and port is the address of the text server");
System.err.println("To start a simple text server, run 'netcat -l <port>' and " +
"type the input text into the command line");
return;
}
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String,Integer>> dataStream = env
.socketTextStream(hostname,port)
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5),Time.seconds(5))
.sum(1);
dataStream.print();
env.execute("WindowWordCount");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for(String word : sentence.split(" ")){
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
} }
2.scala版本
本地安装scala
idea配置scala插件
scala的maven插件
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
代码详细
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.scala._ object SocketWindowCount { def main(args: Array[String]): Unit = {
val port = try{
ParameterTool.fromArgs(args).getInt("port")
}catch {
case e:Exception =>{
System.err.println("No port specified. Please run 'SocketWindowWordCount --port <port>'")
return
}
}
//1.获取env
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//2.通过socket连接获取输入数据 val text = env.socketTextStream("localhost",port,'\n')
//3.一系列操作
/**
* timeWindow(size,slide)
* size:窗口大小,slide:滑动间隔。分为以下三种情况:
* 1. 窗口大小等于滑动间隔:这个就是滚动窗口,数据不会重叠,也不会丢失数据。
* 2. 窗口大小大于滑动间隔:这个时候会有数据重叠,也即是数据会被重复处理。
* 3. 窗口大小小于滑动间隔:必然是会导致数据丢失,不可取。
*/
val windowCounts = text
.flatMap { w => w.split("\\s") }
.map {x:String => WordWithCount(x,1)}
.keyBy(0)
.timeWindow(Time.seconds(5),Time.seconds(5))
.sum(1)
//4.输出结果,打印
windowCounts.print().setParallelism(1)
//5.env执行
env.execute("Socket window WordCount") }
case class WordWithCount(value: String, i: Long)
}
3.win本地开发环境测试
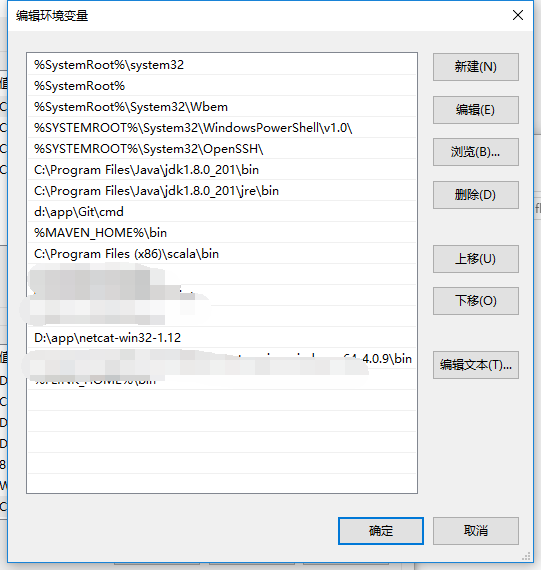
安装netcat
- 下载:https://eternallybored.org/misc/netcat/
- 配置环境变量
打开cmd启动nc端口号监听(win下需加-p)
nc -l -p
idea中配置输出参数
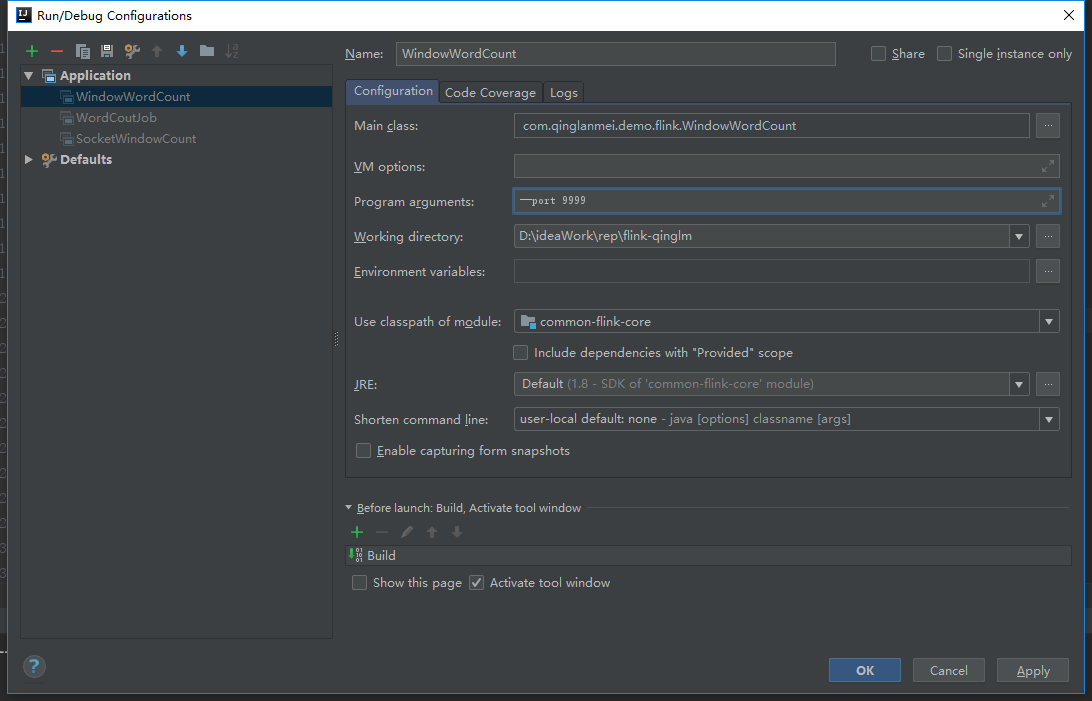
运行程序、在cmd命令窗口输入单词、按空格分隔、在idea本地即可输出结果

4.Flink单机提交(Linux)
Linux安装的是Flink1.8
- 本地maven打包
mvn clean package
- 上传jar包到Linux
- 启动Flink节点(单机)
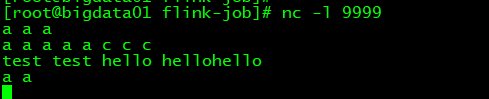
- 另起一窗口,打开nc -l 9999,输入单词,按空格分隔
- 运行jar包
flink run -c com.qinglanmei.demo.flink.SocketWindowCount ./common-flink-core-1.0.jar --port 9999
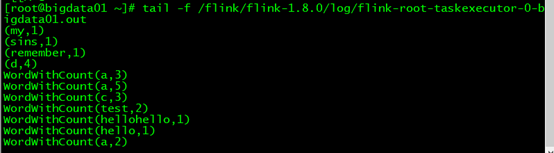
- 查看输出结果,Flink上运行的输出在log/flink-root-taskexecutor-0-bigdata01.out
tail -f /flink/flink-1.8.0/log/flink-root-taskexecutor-0-bigdata01.out
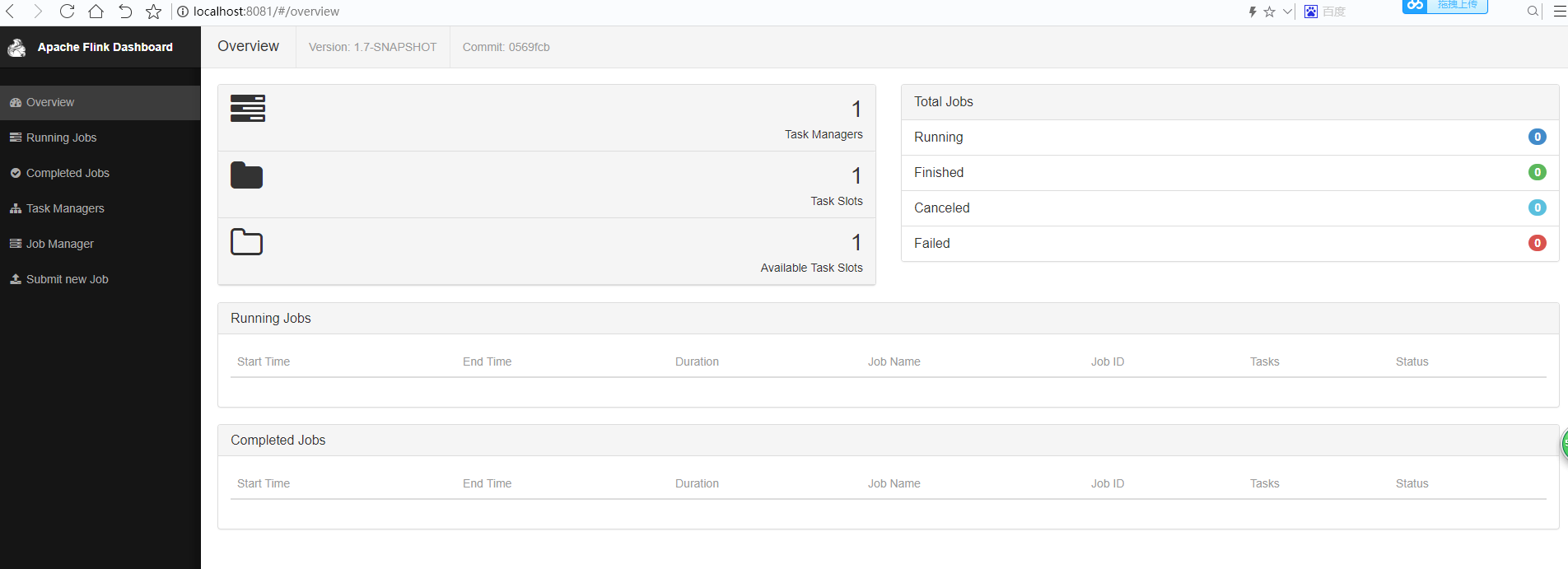
结果如下
观察Flink的Web界面
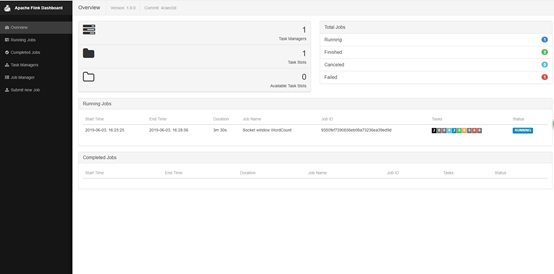
可以发现
- Total Jobs的Running=1
- Available Task Slots=0,说明单机的flink任务槽已经被占用了,因为每个槽运行一个并行管道
三、集群安装
1.standalone
环境配置:
- jdk1.8+
- ssh免密(具有相同的安装目录)
Flink设置
将源码编译出的安装包拷贝出来(编译请参照上一篇01.Flink笔记-编译、部署)或者在Flink官网下载bin包
节点分配:三个节点01-03分别是master、worker01.work02
flink-conf.yaml配置
# 主节点地址
jobmanager.rpc.address: bigdata01
# 任务槽数
taskmanager.numberOfTaskSlots: 2
# 端口号默认8081,因为与我的其他组建冲突,故改成18081
rest.port: 18081
可选配置:
- 每个JobManager(
jobmanager.heap.mb)的可用内存量, - 每个TaskManager(
taskmanager.heap.mb)的可用内存量, - 每台机器的可用CPU数量(
taskmanager.numberOfTaskSlots), - 集群中的CPU总数(
parallelism.default)和 - 临时目录(
taskmanager.tmp.dirs)
修改配置文件masters、slaves
[root@bigdata01 conf]# vim masters
bigdata01:18081
[root@bigdata01 conf]# vim slaves
bigdata02
bigdata03
拷贝01的目录到另外两台节点
scp -r flink-1.8.0/ bigdata02:/flink/
scp -r flink-1.8.0/ bigdata03:/flink/
配置环境变量(每个节点)
vim /etc/profile
#flink
export FLINK_HOME=/flink/flink-1.8.0
export PATH=$FLINK_HOME/bin:$PATH
使其生效source /etc/profile
启动Flink集群
start-cluster.sh
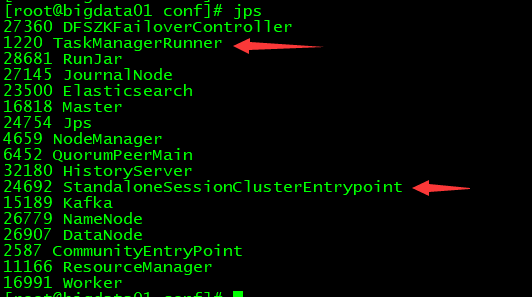
查看进程

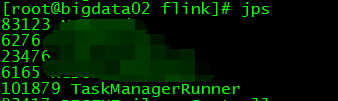

查看web

界面说明
Task Managers:等于worker数,即slaves文件中配置的节点数
Task Slots:等于worker数*taskmanager.numberOfTaskSlots,taskmanager.numberOfTaskSlots即flink-conf.yaml中配置的参数
Available Task Slots:在没有job情况下等于Task Slots
2.HA
修改配置文件
修改flink-conf.yaml,高可用模式不需要指定jobmanager.rpc.address,在masters中添加jobmanager节点,由zookeeper做选举
#jobmanager.rpc.address: bigdata01
high-availability: zookeeper #指定高可用模式(必须)
high-availability.zookeeper.quorum: bigdata01:2181,bigdata02:2181,bigdata03:2181 #ZooKeeper仲裁是ZooKeeper服务器的复制组,它提供分布式协调服务(必须)
high-availability.storageDir:hdfs: ///flink/ha/ #JobManager元数据保存在文件系统storageDir中,只有指向此状态的指针存储在ZooKeeper中(必须)
high-availability.zookeeper.path.root: /flink #根ZooKeeper节点,在该节点下放置所有集群节点(推荐)
#自定义集群(推荐)
high-availability.cluster-id: /flinkCluster
state.backend: filesystem
state.checkpoints.dir: hdfs:///flink/checkpoints
state.savepoints.dir: hdfs:///flink/checkpoints
修改masters
[root@bigdata01 conf]# vim masters
bigdata01:18081
bigdata02:18081
修改slaves
[root@bigdata01 conf]# vim slaves
bigdata02
bigdata03
修改conf/zoo.cfg
# ZooKeeper quorum peers
server.1=bigdata01:2888:3888
server.2=bigdata02:2888:3888
server.3=bigdata03:2888:3888
其余节点同步配置文件
scp -r conf/ bigdata02:/flink/flink-1.8.0/
scp -r conf/ bigdata02:/flink/flink-1.8.0/
启动
先启动zookeeper集群、再启动hadoop、最后启动flink
02.Flink的单机wordcount、集群安装的更多相关文章
- hbase单机及集群安装配置,整合到hadoop
问题导读:1.配置的是谁的目录conf/hbase-site.xml,如何配置hbase.rootdir2.如何启动hbase?3.如何进入hbase shell?4.ssh如何达到互通?5.不安装N ...
- nacos单机,集群安装部署
nacos单机启动 准备 下载nacos安装包 下载地址 准备centos环境 (本次测试使用docker) PS C:\Users\Administrator> docker run -tid ...
- RabbitMQ3 单机及集群安装配置及优化
一.操作系统需求及配置 # 1.1.操作系统推荐配置 4C*8G*40G磁盘 # 1.2.内核参数优化 # 系统参数需要留有swap空间,rabbitmq 启动进程用户打开文件数至少需要5万,yum安 ...
- 第06讲:Flink 集群安装部署和 HA 配置
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 第04讲:Flin ...
- Greenplum源码编译安装(单机及集群模式)完全攻略
公司有个项目需要安装greenplum数据库,让我这个gp小白很是受伤,在网上各种搜,结果找到的都是TMD坑货帖子,但是经过4日苦战,总算是把greenplum的安装弄了个明白,单机及集群模式都部署成 ...
- hbase单机环境的搭建和完全分布式Hbase集群安装配置
HBase 是一个开源的非关系(NoSQL)的可伸缩性分布式数据库.它是面向列的,并适合于存储超大型松散数据.HBase适合于实时,随机对Big数据进行读写操作的业务环境. @hbase单机环境的搭建 ...
- ZooKeeper 的安装和配置---单机和集群
如题本文介绍的是ZooKeeper 的安装和配置过程,此过程非常简单,关键是如何应用(将放在下节及相关节中介绍). 单机安装.配置: 安装非常简单,只要获取到 Zookeeper 的压缩包并解压到某个 ...
- flink部署操作-flink standalone集群安装部署
flink集群安装部署 standalone集群模式 必须依赖 必须的软件 JAVA_HOME配置 flink安装 配置flink 启动flink 添加Jobmanager/taskmanager 实 ...
- Redis学习笔记之Redis单机,伪集群,Sentinel主从复制的安装和配置
0x00 Redis简介 Redis是一款开源的.高性能的键-值存储(key-value store).它常被称作是一款数据结构服务器(data structure server). Redis的键值 ...
随机推荐
- html标签知识(无表单、表格)
<meta> : 定义在head中 <hgroup></hgroup> : 标题分组标签 <br>: 换行标签 ! : 空行 <p>< ...
- 打开桌面的Eclipse闪退,打不开
参考了网上说的方法: .在C:/WINDOWS/system32 系统文件夹中ctrl+F 然后搜索java.exe,如果存在java.exe, javaw.exe etc.全部删除. 2.内存不足, ...
- 微信号可以改了?我用 Python 发现了隐藏的 6 大秘密.
“听说,微信可以改微信号了! ” 不知道谁扯了一嗓子,让办公室变成了欢乐的海洋 张姐流下了激动的泪水:“太好了!姐的年龄终于不用暴露在微信号了!” 很多人学习python,不知道从何学起.很多人学习p ...
- Java日志框架(二)
最流行的日志框架解决方案 按笔者理解,现在最流的日志框架解决方案莫过于SLF4J + LogBack.其有以下几个优点: LogBack 自身实现了 SLF4J 的日志接口,不需要 SLF4J 去做进 ...
- JavaScript promise基础示例
const { info } = console // cooking function cook() { info('[COOKING] start cooking.') const p = new ...
- 将阿里矢量图添加到element-ui
在阿里矢量图的操作 选择需要的图标添加至购物车 选择图标 将购物车中的图标, 添加至项目 添加至项目 会自动跳转到我的项目 项目页面 在 更多操作 中选择 编辑项目 更多操作 将 Fo ...
- windows服务器下,mysql运行一段时间之后忽然无法连接,但是mysql服务启动正常
出现这种情况以前都是重启服务器可以解决,但是治标不治本,一段时间之后仍然会出现此问题. 此问题不是mysql应用程序的问题而是windows server system 的配置问题.因此需要修改win ...
- unity探索者之iOS微信登录、分享
版权声明:本文为原创文章,转载请声明http://www.cnblogs.com/unityExplorer/p/8405700.html iOS接入微信的SDK相对于安卓要麻烦一点,除了核心功能代码 ...
- SQL获取多个字段中最大小值
1.语法最大值: GREATEST(expr_1, expr_2, ...expr_n)最小值: LEAST(expr_1, expr_2, ...expr_n) 2.说明GREATEST(expr_ ...
- Magento 2 Factory Objects
In object oriented programming, a factory method is a method that’s used to instantiate an object. F ...