Hadoop之计数器与自定义计数器及Combiner的使用
1,计数器:
显示的计数器中分为四个组,分别为:File Output Format Counters、FileSystemCounters、File Input Format Counters和Map-Reduce Framkework。
分组File Input Format Counters包括一个计数器Bytes Read,表示job执行结束后输出文件的内容包括的字节数(空格、换行都是字符)
关于以上这段计数器日志中详细的说明请见下面的注释:

1 Counters: 19 // Counter表示计数器,19表示有19个计数器(下面一共4计数器组)
2 File Output Format Counters // 文件输出格式化计数器组
3 Bytes Written=19 // reduce输出到hdfs的字节数,一共19个字节
4 FileSystemCounters// 文件系统计数器组
5 FILE_BYTES_READ=481
6 HDFS_BYTES_READ=38
7 FILE_BYTES_WRITTEN=81316
8 HDFS_BYTES_WRITTEN=19
9 File Input Format Counters // 文件输入格式化计数器组
10 Bytes Read=19 // map从hdfs读取的字节数
11 Map-Reduce Framework // MapReduce框架
12 Map output materialized bytes=49
13 Map input records=2 // map读入的记录行数,读取两行记录,”hello you”,”hello me”
14 Reduce shuffle bytes=0 // 规约分区的字节数
15 Spilled Records=8
16 Map output bytes=35
17 Total committed heap usage (bytes)=266469376
18 SPLIT_RAW_BYTES=105
19 Combine input records=0 // 合并输入的记录数
20 Reduce input records=4 // reduce从map端接收的记录行数
21 Reduce input groups=3 // reduce函数接收的key数量,即归并后的k2数量
22 Combine output records=0 // 合并输出的记录数
23 Reduce output records=3 // reduce输出的记录行数。<helllo,{1,1}>,<you,{1}>,<me,{1}>
24 Map output records=4 // map输出的记录行数,输出4行记录
2,自定义计数器:
由于不同的场景有不同的计数器应用需求,我们可以自定义不同的计数器:
一:敏感词准备:
将文件中的hello设为敏感词,自定义计数器的目的是将文件中出现的计数器的次数给记录出来
二:代码部分:
仅需要修改之前博客中WordClass中的map的代码部分:
public class WordClass {
public static class MyMapper extends org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, LongWritable> {
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
//动态申明
Counter sensitiveCounter = context.getCounter("Sensitive Words", "hello");
String line = value.toString();
//假设hello是一个敏感词
if (line.contains("hello")){
sensitiveCounter.increment(1L);
}
String[] split = line.split("\t");
for (String word :
split) {
context.write(new Text(word), new LongWritable(1));
}
}
}
计数器声明
1.通过枚举声明 context.getCounter(Enum enum)
2.动态声明 context.getCounter(String groupName,String counterName)
计数器操作
counter.setValue(long value);//设置初始值
counter.increment(long incr);//增加计数
三:结果
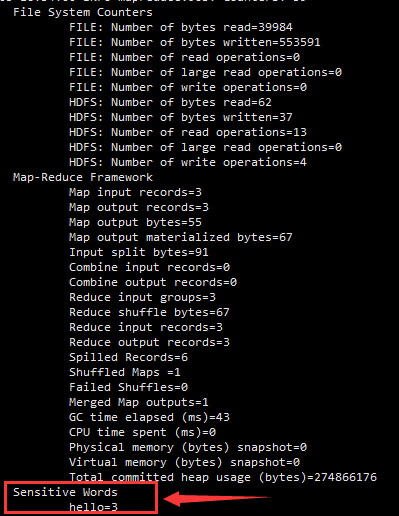
在日志信息中可以看到文件中的敏感词信息
3,Combiner的使用
Combiner的作用就是在map端对数据进行合并,从而提高网络的通讯速率,减少map到reduce的网络带宽
我们可以本地把Map的输出做一个合并计算,把具有相同key的数据做一个计算,然后再把此输出作为reduce的输入,这样传给reduce的数据就少了很多。Combiner是用reducer来定义的,多数的情况下Combiner和reduce处理的是同一种逻辑,所以job.setCombinerClass()的参数可以直接使用定义的reduce,括号中可以直接传入类似于MyReducer.Class,当然也可以单独去定义一个有别于reduce的Combiner,继承Reducer,写法基本上定义reduce一样。
----那么,既然Combiner这么有用为什么不能将它作为默认设置呢?
----因为当有类似于求平均数的任务时,在map端执行Combiner会影响最终的结果,所以有些操作并不适合用Combiner,在工作使用中我们应该先选取小部分的数据进行测试,如果结果无误的话,则可以使用Combiner进行map端的数据合并
Hadoop之计数器与自定义计数器及Combiner的使用的更多相关文章
- Hadoop学习笔记—7.计数器与自定义计数器
一.Hadoop中的计数器 计数器:计数器是用来记录job的执行进度和状态的.它的作用可以理解为日志.我们通常可以在程序的某个位置插入计数器,用来记录数据或者进度的变化情况,它比日志更便利进行分析. ...
- 9.1hadoop 内置计数器、自定义枚举计数器、Streaming计数器
1.1 计数器 计数器的作用是用来统计数量的,用于记录特定事件的次数,分为内置计数器.自定义java枚举计数器.自定义Stream计数器三大类.用于质量分析,或应用级统计.分析计数器的值比分析一堆日 ...
- ionic3.x angular4.x ng4.x 自定义组件component双向绑定之自定义计数器
本文主要示例在ionic3.x环境下实现一个自定义计数器,实现后最终效果如图: 1.使用命令创建一个component ionic g component CounterInput 类似的命令还有: ...
- CSS计数器(自定义列表)
概念 CSS3计数器(CSS Counters)可以允许我们使用css对页面中的任意元素进行计数,实现类似于有序列表的功能(自定义有序列表) 与有序列表相比,它的突出特性在于可以对任意元素计数,同时实 ...
- CSS计数器(自定义列表)Demo
html <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <ti ...
- Hadoop学习笔记—5.自定义类型处理手机上网日志
转载自http://www.cnblogs.com/edisonchou/p/4288737.html Hadoop学习笔记—5.自定义类型处理手机上网日志 一.测试数据:手机上网日志 1.1 关于这 ...
- Hadoop生态圈-hive编写自定义函数
Hadoop生态圈-hive编写自定义函数 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Hive的自定义函数之UDTF(User-Defined Table-Generating Functions)
Hadoop生态圈-Hive的自定义函数之UDTF(User-Defined Table-Generating Functions) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Hive的自定义函数之UDAF(User-Defined Aggregation Function)
Hadoop生态圈-Hive的自定义函数之UDAF(User-Defined Aggregation Function) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
随机推荐
- innodb_index_stats
mysql> select * from mysql.innodb_index_stats WHERE database_name='test' and table_name='recordsI ...
- Python request 简单使用
Requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库.它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTT ...
- 第三十三篇 Python中关于OOP(面向对象)的常用术语
面向对象的优点 从编程进化论可知,面向对象是一种更高等级的结构化编程方式,它的好处主要有两点: 1. 通过封装明确了内外,你做为类的缔造者,你就是女娲,女娲造物的逻辑别人无需知道,女娲想让你知道,你才 ...
- 1098 Insertion or Heap Sort (25 分)(堆)
这里的第二序列相当于是排序还没拍好的序列 对于第二个样例的第二个序列其实已经是大顶堆了 然后才进行的堆排序 知道这个就好做了 #include<bits/stdc++.h> using n ...
- GraphSAGE 代码解析(二) - layers.py
原创文章-转载请注明出处哦.其他部分内容参见以下链接- GraphSAGE 代码解析(一) - unsupervised_train.py GraphSAGE 代码解析(三) - aggregator ...
- linux备忘录-系统服务daemon
服务(daemon)及其分类 Linux中的服务被称为daemon(daemon是守护神,恶鬼的意思哦).这些daemon会常驻在内存当中,从而对我们的系统和任务等进行一些辅助性的工作.实际上,dae ...
- BZOJ 2597 剪刀石头布(最小费用最大流)(WC2007)
Description 在一些一对一游戏的比赛(如下棋.乒乓球和羽毛球的单打)中,我们经常会遇到A胜过B,B胜过C而C又胜过A的有趣情况,不妨形象的称之为剪刀石头布情况.有的时候,无聊的人们会津津乐道 ...
- lintcode-74-第一个错误的代码版本
74-第一个错误的代码版本 代码库的版本号是从 1 到 n 的整数.某一天,有人提交了错误版本的代码,因此造成自身及之后版本的代码在单元测试中均出错.请找出第一个错误的版本号. 你可以通过 isBad ...
- Java循环控制语句-switch
Java循环控制语句之一switch 不同于其他循环控制语句的特性: switch的英文解释为开关,正如它的解释一样,switch循环的特点就像开关一样,跳到哪一个条件即会出现某一种结果. 写法: s ...
- [剑指Offer] 25.复杂链表的复制
/* struct RandomListNode { int label; struct RandomListNode *next, *random; RandomListNode(int x) : ...