数据标准化方法及其Python代码实现
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。目前数据标准化方法有多种,归结起来可以分为直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。不同的标准化方法,对系统的评价结果会产生不同的影响,然而不幸的是,在数据标准化方法的选择上,还没有通用的法则可以遵循。
常见的方法有:min-max标准化(Min-max normalization),log函数转换,atan函数转换,z-score标准化(zero-mena normalization,此方法最为常用),模糊量化法,均值归一化。本文只介绍min-max标准化、Z-score标准化方法、均值归一化、log函数转换、atan函数转换。
data = [1, 3, 4, 5, 2, 13, 23, 71, 11, 19, 9, 24, 38]
一、min-max标准化(Min-Max Normalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数如下:

from __future__ import print_function, division # min-max标准化方法
data0 = [(x - min(data))/(max(data) - min(data)) for x in data]
二、Z-score标准化方法
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:

from __future__ import print_function
import math # 均值
average = float(sum(data))/len(data) # 方差
total = 0
for value in data:
total += (value - average) ** 2 stddev = math.sqrt(total/len(data)) # z-score标准化方法
data1 = [(x-average)/stddev for x in data]
三、均值归一化
两种方式,以max为分母的归一化方法和以max-min为分母的归一化方法
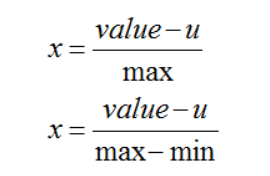
from __future__ import print_function # 均值
average = float(sum(data))/len(data) # 均值归一化方法
data2_1 = [(x - average )/max(data) for x in data] data2_2 = [(x - average )/(max(data) - min(data)) for x in data]
四、log函数转换方法
from __future__ import print_function import math # log2函数转换
data3_1 = [math.log2(x) for x in data] # log10函数转换
data3_2 = [math.log10(x) for x in data]
五、atan函数转换方法
from __future__ import print_function import math # atan函数转换方法
data4 = [math.atan(x) for x in data]
数据标准化方法及其Python代码实现的更多相关文章
- Z-Score数据标准化处理(python代码)
#/usr/bin/python def Z_Score(data): lenth = len(data) total = sum(data) ave = float(total)/lenth tem ...
- JQuery 获取json数据$.getJSON方法的实例代码
这篇文章介绍了JQuery 获取json数据$.getJSON方法的实例代码,有需要的朋友可以参考一下 前台: function SelectProject() { var a = new Array ...
- YoloV4当中的Mosaic数据增强方法(附代码详细讲解)码农的后花园
上一期中讲解了图像分类和目标检测中的数据增强的区别和联系,这期讲解数据增强的进阶版- yolov4中的Mosaic数据增强方法以及CutMix. 前言 Yolov4的mosaic数据增强参考了CutM ...
- 在代理中托管特殊方法的python代码实现
任务简单的介绍是: 在新风格对象模型中,Python操作其实是在类中查找特殊方法的(经典对象是在实例中进行操作的),现在需要将一些新风格的实例包装到代理中,,此代理可以选择将一些特殊的方法委托给内部的 ...
- 1.由于测试某个功能,需要生成500W条数据的txt,python代码如下
txt内容是手机号,数量500W,采用python代码生成,用时60S,本人技能有限,看官如果有更快的写法,欢迎留言交流. import random f = open("D:\\data. ...
- 优化Python代码的4种方法
介绍 作为数据科学家,编写优化的Python代码非常非常重要.杂乱,效率低下的代码即浪费你的时间甚至浪费你项目的钱.经验丰富的数据科学家和专业人员都知道,当我们与客户合作时,杂乱的代码是不可接受的. ...
- 用SVM处理XSS时,数据清洗打标数据标准化处理的方法和意义
def get_len(url): return len(url) def get_url_count(url): if re.search('(http://)|(https://)', url, ...
- 利用 pandas 进行数据的预处理——离散数据哑编码、连续数据标准化
数据的标准化 数据标准化就是将不同取值范围的数据,在保留各自数据相对大小顺序不变的情况下,整体映射到一个固定的区间中.根据具体的实现方法不同,有的时候会映射到 [ 0 ,1 ],有时映射到 0 附近的 ...
- 转:数据标准化/归一化normalization
转自:数据标准化/归一化normalization 这里主要讲连续型特征归一化的常用方法.离散参考[数据预处理:独热编码(One-Hot Encoding)]. 基础知识参考: [均值.方差与协方差矩 ...
随机推荐
- NETCore中RabbitMQ的使用
NET中RabbitMQ的使用 https://www.cnblogs.com/xibei666/p/5931267.html 概述 MQ全称为Message Queue, 消息队列(MQ)是一种应用 ...
- Spring3.x JSR-303
JSR303介绍 JSR303-Bean Validation描述:This JSR will define a meta-data model and API for JavaBeanTM vali ...
- Git 的 cherry-pick 功能
简而言之,cherry-pick就是从不同的分支中捡出一个单独的commit,并把它和你当前的分支合并.如果你以并行方式在处理两个或以上分支,你可能会发现一个在全部分支中都有的bug.如果你在一个分支 ...
- C++笔记之CopyFile和MoveFile的使用
1.函数定义 CopyFile(A, B, FALSE);表示将文件A拷贝到B,如果B已经存在则覆盖(第三参数为TRUE时表示不覆盖) MoveFile(A, B);表示将文件A移动到B 2.函数原型 ...
- vuecli3 运行报错
Microsoft Windows [版本 6.1.7601]版权所有 (c) 2009 Microsoft Corporation.保留所有权利. C:\Users\Administrator\De ...
- Xcode 打开playground文件的时候提示-Unable to find execution service for selected run destination
解决办法: step 1: 关闭Xcode (快捷键cmd + q) step 2:在terminal里面运行如下语句 rm -rf ~/Library/Developer/CoreSimulator ...
- 【转】使用Jmeter录制web脚本
1.web性能测试以及web http请求基本原理. 再介绍录制jmeter脚本之前,我们先谈一下web性能测试.web就是调用http/https接口, 其实没有是什么复杂度可言.只是我们必须清楚, ...
- 安卓端后台登录接口单元测试demo
package com.js.ai.modules.pointwall.interfac; import java.io.IOException; import java.io.Unsupported ...
- ansibel---tag模块
如果你有一个大的剧本,你可以在不运行整个剧本的情况下运行一个特定的部分. 由于这个原因,两个游戏和任务都支持一个“标记:”属性.您只能根据命令行中的标记(标记或- skip- tags)对任务进行筛 ...
- python's sixth day for me
---恢复内容开始--- # == 比较的是数值 a = 1000 b = 1000 print(a == b) #True # is 比较的是内存地址 >>> a = 100 ...