《Python 机器学习》笔记(四)
数据预处理——构建好的训练数据集
机器学习算法最终学习结果的优劣取决于两个主要因素:数据的质量和数据中蕴含的有用信息的数量。
缺失数据的处理
在实际应用过程中,样本由于各种原因缺少一个或多个值得情况并不少见。其原因主要有:数据采集过程中出现了错误,常用得度量方法不适用于某些特征,或者在调查过程中某些数据未被填写等等。通常我们见到得缺失值是数据表中得空值,或者是类似于NaN的占位符。
如果我们忽略这些缺失值,将导致大部分的计算工具无法对原始数据进行处理,或者得到某些不可预知的结果。因此,在做更深入的分析之前,必须对这些缺失值进行处理。
将存在缺失值的特征或样本删除
处理缺失数据最简单的方法就是:将包含确定数据的特征(列)或者样本(行)从数据集中删除。可通过dropna方法来删除数据集中包含缺失值的行(这里dropna()函数是存在于dataframe数据结构中)
类似地,我们可以将axis参数设为1,以删除数据集中至少包含一个NaN值的列
dropna方法还支持其他参数,以应对各种缺失值的情况:
#only drop rows where all columns are NaN
df,dropna(how=’all’)
#drop rows that have not at least 4 non-NaN values
df.dropna(thresh=4)
#only drop rows where NaN appear in specific columns (here:’C’)
df.dropna(subset=[‘C’])
删除缺失数据看起来像是一种非常方便的方法,但也有一定的确定,如:我们可能会删除过多的样本,导致分析结果的可靠性不高。另一方面,如果删除了过多的特征列,有可能会面临丢失有价值信息的风险,而这些信息是分类器用来区分类别所必须的。
缺失数据填充
通常情况下,删除样本或者删除数据集中的震哥哥特征列是不可行的,因为这样可能会丢失过多有价值的数据。在此情况下,我们可以使用不同的插值技术,通过数据集中其他训练样本的数据来估计缺失值。最常用的插值技术之一就是均值插补,即使用相应的特征均值来替换缺失值。我们可使用scikit-learn中的Impute类方便地实现此方法
imr=Imputer(missing_value=’NaN’,strategy=’mean’,axis=0)
如果把参数axis=0改成axis=1,则用每行地均值来进行相应的替换。参数strategy的可选项还有median或者most_frequent,后者代表使用对应行或列中出现频次最高的值来替换缺失值,常用于填充类别特征值。
处理类别数据
到目前为止,我们仅学习了处理数值型数据的方法,然而,在真实数据集中,经常会出现一个或多个类别数据的特征列。我们在讨论类别数据时,又可以进一步将他们划分为标称特征和有序特征。可以将有序特征理解为类别的值是有序的或者是可以排序的。相反,标称数据则不具备排序的特性。
有序特征的映射
为了确保学习算法可以正确地使用有序特征,我们需要将类别字符串转换为整数。但是,没有一个适当的方法可以自动将尺寸特征转换为正确的顺序。由此,需要我们手工定义相应的映射。
size_mapping={‘XL’:3,’L’:2,’M’:1}
df[‘size’]=df[‘size’].map(size_mapping)#构建了映射
类标的编码
许多机器学习库要求类标以整数值的方式进行编码。虽然scikit-learn中大多数分类预估器都会在内部将类标转换为整数,但通过将类标转换为整数序列能够从技术角度避免某些问题的产生,在实践中这被认为是一个很好的做法。为了对类标进行编码,可以采用与前面讨论的有序特征映射相类似的方式。要清楚一点,类标并不是有序的,而且对于特定的字符串类标,赋予哪个整数值给它对我们来说并不重要。因此,我们可以简单地以枚举的方式从0开始设定类标。
标称特征上的one-hot编码
我们曾使用字典映射的方法将有序的尺寸特征转换为整数。由于scikit-learn的预估器将类标作为无序数据进行处理,可以使用scikit-learn中的LabelEncoder类将字符串类标转换为整数。同样,也可以用此方法处理数据集中标称数据格式的color列.
one-hot技术即创建一个新的虚拟特征,虚拟特征的每一类各代表标称数据的一个值。例如颜色用r,g,b三色标识。
当我们初始化onehotEncoder对象时,需要通过categorical_features参数来选定我们要转换的特征所在的位置。默认情况下,当我们调用onehotEncoder的transform方法时,它会返回一个稀疏矩阵。出于可视化的考虑,我们可以通过toarray方法将其转换为一个常规的Numpy数组。稀疏矩阵是存储大型数据集中的一个有效方法,被许多scikit-learn函数所支持,特别是在数据包含很多零值时非常有用。为了略过toarry的使用步骤,我们也可以通过在初始化阶段使用onehotEncoder(…,sparse=False)来返回一个常规的Numpy数组。
另外,我们可以通过pandas中的get_dummies方法,更加方便地实现onehot编码技术中的虚拟特征。当应用于DataFrame数据时,get_dummies方法只对字符串列进行转换,而其它的列保持不变
将数据集划分为训练数据集和测试数据集
交叉验证(cross validation)
from sklearn.cross_validation import train_test_split
将特征的值缩放到相同的区间
特征缩放是数据预处理过程中至关重要的一步,但却极易被人们忽略。
决策树和随机森林是机器学习算法中为数不多的不需要进行特征缩放的算法,然而,对大多数机器学习和优化算法而言,将特征的值缩放到相同的区间可以使其性能更佳。
目前,将不同的特征缩放到相同区间有两个常用的方法:归一化和标准化
归一化:
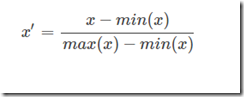
from sklearn.preprocessing import MinMaxScaler
标准化:
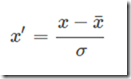
from sklearn.preprocessing import StandardScaler
选择有意义的特征
如果一个模型在训练数据集上的表现比在测试数据集上好很多,这意味着模型过拟合于训练数据。
而常用的降低泛化误差的方案有:
(1)收集更多的训练数据
(2)通过正则化引入罚项
(3)选择一个参数相对较少的简单模型
(4)降低数据的维度
序列特征选择算法
另外一种降低模型复杂度从而解决过拟合问题的方法是通过特征选择进行降维,该方法对未经正则化处理的模型特别有效。
降维技术主要分为两个大类:特征选择和特征提取。通过特征选择,我们可以选出原始特征的一个子集。而在特征提取中,通过对现有的特征信息进行推演,构造出一个新的特征子空间。在本节,我们将着眼于一些经典的特征选择算法。
序列特征选择算法系一种贪婪搜索法,用于将原始的d维特征空间压缩到一个k维特征子空间,k<d。使用特征选择算法处于以下考虑:能够剔除不相关特征或噪声,自动选出与问题最相关的特征子集,从而提高计算效率或是降低模型的泛化误差。这在模型不支持正则化时尤为有效。一个经典的序列特征选择算法是序列后向选择算法(SBS),其目的是在分类性能衰减最小的约束下,降低原始特征空间上的数据维度,以提高计算效率。在某些情况下,SBS甚至可以在模型面临过拟合问题时提高模型的预测能力。
《Python 机器学习》笔记(四)的更多相关文章
- Python机器学习笔记:使用Keras进行回归预测
Keras是一个深度学习库,包含高效的数字库Theano和TensorFlow.是一个高度模块化的神经网络库,支持CPU和GPU. 本文学习的目的是学习如何加载CSV文件并使其可供Keras使用,如何 ...
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
- Python机器学习笔记:不得不了解的机器学习面试知识点(1)
机器学习岗位的面试中通常会对一些常见的机器学习算法和思想进行提问,在平时的学习过程中可能对算法的理论,注意点,区别会有一定的认识,但是这些知识可能不系统,在回答的时候未必能在短时间内答出自己的认识,因 ...
- Python机器学习笔记:K-Means算法,DBSCAN算法
K-Means算法 K-Means 算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means 算法有大量的变体,本文就从最传统的K-Means算法学起,在其基础上学习 ...
- python机器学习笔记:EM算法
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域的基础,比如隐式马尔科夫算法(HMM),LDA主题模型的变分推断算法等等.本文对于E ...
- Python机器学习笔记:SVM(1)——SVM概述
前言 整理SVM(support vector machine)的笔记是一个非常麻烦的事情,一方面这个东西本来就不好理解,要深入学习需要花费大量的时间和精力,另一方面我本身也是个初学者,整理起来难免思 ...
- Python机器学习笔记:不得不了解的机器学习知识点(2)
之前一篇笔记: Python机器学习笔记:不得不了解的机器学习知识点(1) 1,什么样的资料集不适合用深度学习? 数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势. 数据集没有局 ...
- Python机器学习笔记 集成学习总结
集成学习(Ensemble learning)是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合,从而获得比单个学习器显著优越的泛化性能.它不是一种单独的机器学习算法啊,而更像是一种优 ...
- Python机器学习笔记:异常点检测算法——LOF(Local Outiler Factor)
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 在数据挖掘方面,经常需 ...
- Python机器学习笔记:奇异值分解(SVD)算法
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 奇异值分解(Singu ...
随机推荐
- Linux在本地使用yum安装软件
经常遇到有的linux服务器由于特殊原因,不能连接外网,但是经常需要安装一些软件,尤其是在编译一些包的时候经常由于没有安装一些依存包而报的各种各样的错误,当你找到依存的rpm包去安装的时候,又提示你有 ...
- javascript - Underscore 与 函数式编程
<Javascript函数式编程 PDF> # csdn下载地址http://download.csdn.net/detail/tssxm/9713727 Underscore # git ...
- C# 操作超时正常还是错
net(客户端)调用IIS(服务端)出现503后,就报操作超时错误 问题描述:服务端环境:IIS 客户端环境:windowsxp + iis + .net 调用时出现如下错误:System.Net.W ...
- HttpClient如何 关闭连接(转)
ava代码 HttpClient client = new HttpClient(); HttpMethod method = new GetMethod("http://www.apach ...
- 74. First Bad Version 【medium】
74. First Bad Version [medium] The code base version is an integer start from 1 to n. One day, someo ...
- CentOS 7 安装以及配置桌面环境
一.安装 GNOME 桌面 1.安装命令: yum groupinstall "GNOME Desktop" "X Window System" " ...
- jQuery导入代码片段并绑定事件
a.html <div> <button class="button" >点我达</button> </div> b.html &l ...
- ng file上传同域非同域
跨域 vm.uploadFiles = function (file, errFiles) { if (file) { file.upload = Upload.upload({ url: vm.up ...
- 放苹果(整数划分变形题 水)poj1664
问题:把M个相同的苹果放在N个相同的盘子里.同意有的盘子空着不放,问共同拥有多少种不同的分法?(用K表示)5,1,1和1,5,1 是同一种分法. 例子 : 1 7 3 ---------------8 ...
- 如何创建Windows定时任务
我们经常使用电脑,有没有那么一个瞬间想着要是电脑可以每隔一段时间,自动处理一件事情就好了呢? 其实Windows还真有这样的功能,很多软件检测更新就是通过这个方法实现的. 这次我们来做一个简易的喝水提 ...