【转】RabbitMQ基础——和——持久化机制
这里原来有一句话,触犯啦天条,被阉割!!!!
首先不去讨论我的日志组件怎么样。因为有些日志需要走网络,有的又不需要走网路,也是有性能与业务场景的多般变化在其中,就把他抛开,我们只谈消息RabbitMQ。
那么什么是RabbitMQ,它是用来解决什么问题的,性能如何,又怎么用?我会在下面一一阐述,如有错误,不到之处,还望大家不吝赐教。
RabbitMQ简介
必须一提的是rabbitmq是由LShift提供的一个消息队列协议(AMQP)的开源实现,由以高性能、健壮以及可伸缩性出名的Erlang写成(因此也是继承了这些优点)。
百度百科对RabbitMQ阐述也非常明确,建议去看下,还有amqp协议。
RabbitMQ官网:http://www.rabbitmq.com/ 如果你要下载安装,那么必须先把Erlang语言装上。
RabbitMQ的.net客户端,可以在nuget中输入rabbitmq轻松获得。
RabbitMQ与其他消息队列的对比,早有仙人给写出来。 Message Queue Shootout
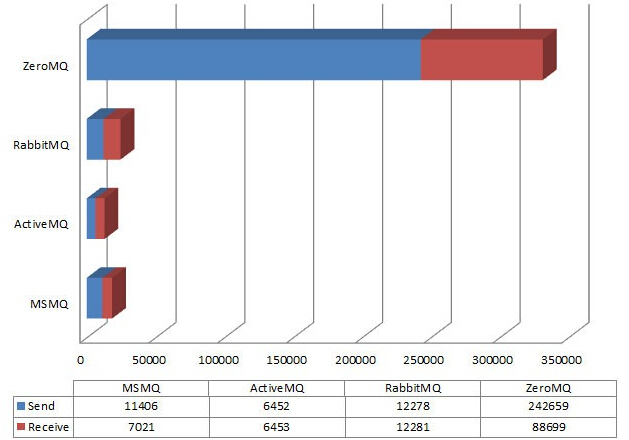
这篇文章中的测试案例为:1百万条1k的消息,每秒种的收发情况如下图。
如果你安装好啦,rabbitmq,他会提供一个操作监控页面,页面如下,他几乎提供啦,对rabbitmq的所有操作,与监控,所以,你装上后,自己多看看,多操作下。

RabbitMQ中的一些名词阐述与消息从投递到消费的整个过程
从上图的标题中可以看到一些陌生的英文单词,让我们感觉一无所知,更无从操作,那么我给大家弄啦一个图片大家可以看下,或许对您理解这些新鲜的单词有所帮助。

看过这些名词,之后,或许你还毫无头绪,那么我把消息从生产到消费的整个流程给大家说一下,或许会更深入一点,其中Exchange,与Queue都是可以设置相关属性,队列的持久化,交换器类型制定。

Note:首先这个过程走分三个部分,1、客户端(生产消息队列),2、RabbitMQ服务端(负责路由规则的绑定与消息的分发),3、客户端(消费消息队列中的消息)

Note:由图可以看出,一个消息可以走一次网络却被分发到不同的消息队列中,然后被多个的客户端消费,那么这个过程就是RabbitMQ的核心机制,RabbitMQ的路由类型与消费模式。
RabbitMQ中Exchange的类型
类型有4种,direct,fanout,topic,headers。其中headers不常用,本篇不做介绍,其他三种类型,会做详细介绍。
那么这些类型是什么意思呢?就是Exchange与队列进行绑定后,消息根据exchang的类型,按照不同的绑定规则分发消息到消息队列中,可以是一个消息被分发给多个消息队列,也可以是一个消息分发到一个消息队列。具体请看下文。
介绍之初还要说下RoutingKey,这是个什么玩意呢?他是exchange与消息队列绑定中的一个标识。有些路由类型会按照标识对应消息队列,有些路由类型忽略routingkey。具体看下文。
1、Exchange类型direct
他是根据交换器名称与routingkey来找队列的。

Note:消息从client发出,传送给交换器ChangeA,RoutingKey为routingkey.ZLH,那么不管你发送给Queue1,还是Queue2一个消息都会保存在Queue1,Queue2,Queue3,三个队列中。这就是交换器的direct类型的路由规则。只要找到路由器与routingkey绑定的队列,那么他有多少队列,他就分发给多少队列。
2、Exchange类型fanout
这个类型忽略Routingkey,他为广播模式。

Note:消息从客户端发出,只要queue与exchange有绑定,那么他不管你的Routingkey是什么他都会将消息分发给所有与该exchang绑定的队列中。
3、Exchange类型topic
这个类型的路由规则如果你掌握啦,那是相当的好用,与灵活。他是根据RoutingKey的设置,来做匹配的,其中这里还有两个通配符为:
*,代表任意的一个词。例如topic.zlh.*,他能够匹配到,topic.zlh.one ,topic.zlh.two ,topic.zlh.abc, ....
#,代表任意多个词。例如topic.#,他能够匹配到,topic.zlh.one ,topic.zlh.two ,topic.zlh.abc, ....

Note:这个图看上去很乱,但是他是根据匹配符做匹配的,这里我建议你自己做下消息队列的具体操作。
具体操作如下

public static void Producer(int value)
{
try
{
var qName = "lhtest1";
var exchangeName = "fanoutchange1";
var exchangeType = "fanout";//topic、fanout
var routingKey = "*";
var uri = new Uri("amqp://192.168.10.121:5672/");
var factory = new ConnectionFactory
{
UserName = "123",
Password = "123",
RequestedHeartbeat = 0,
Endpoint = new AmqpTcpEndpoint(uri)
};
using (var connection = factory.CreateConnection())
{
using (var channel = connection.CreateModel())
{
//设置交换器的类型
channel.ExchangeDeclare(exchangeName, exchangeType);
//声明一个队列,设置队列是否持久化,排他性,与自动删除
channel.QueueDeclare(qName, true, false, false, null);
//绑定消息队列,交换器,routingkey
channel.QueueBind(qName, exchangeName, routingKey);
var properties = channel.CreateBasicProperties();
//队列持久化
properties.Persistent = true;
var m = new QMessage(DateTime.Now, value+"");
var body = Encoding.UTF8.GetBytes(DoJson.ModelToJson<QMessage>(m));
//发送信息
channel.BasicPublish(exchangeName, routingKey, properties, body);
}
}
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
}
消息队列的消费与消息确认Ack
1、消息队列的消费

Note:如果一个消息队列中有大量消息等待操作时,我们可以用多个客户端来处理消息,这里的分发机制是采用负载均衡算法中的轮询。第一个消息给A,下一个消息给B,下下一个消息给A,下下下一个消息给B......以此类推。
2、为啦保证消息的安全性,保证此消息被正确处理后才能在服务端的消息队列中删除。那么rabbitmq提供啦ack应答机制,来实现这一功能。
ack应答有两种方式:1、自动应答,2、手动应答。具体实现如下。
public static void Consumer()
{
try
{
var qName = "lhtest1";
var exchangeName = "fanoutchange1";
var exchangeType = "fanout";//topic、fanout
var routingKey = "*";
var uri = new Uri("amqp://192.168.10.121:5672/");
var factory = new ConnectionFactory
{
UserName = "123",
Password = "123",
RequestedHeartbeat = 0,
Endpoint = new AmqpTcpEndpoint(uri)
};
using (var connection = factory.CreateConnection())
{
using (var channel = connection.CreateModel())
{
channel.ExchangeDeclare(exchangeName, exchangeType);
channel.QueueDeclare(qName, true, false, false, null);
channel.QueueBind(qName, exchangeName, routingKey);
//定义这个队列的消费者
QueueingBasicConsumer consumer = new QueueingBasicConsumer(channel);
//false为手动应答,true为自动应答
channel.BasicConsume(qName, false, consumer);
while (true)
{
BasicDeliverEventArgs ea = (BasicDeliverEventArgs)consumer.Queue.Dequeue();
byte[] bytes = ea.Body;
var messageStr = Encoding.UTF8.GetString(bytes);
var message = DoJson.JsonToModel<QMessage>(messageStr);
Console.WriteLine("Receive a Message, DateTime:" + message.DateTime.ToString("yyyy-MM-dd HH:mm:ss") + " Title:" + message.Title);
//如果是自动应答,下下面这句代码不用写啦。
if ((Convert.ToInt32(message.Title) % 2) == 1)
{
channel.BasicAck(ea.DeliveryTag, false);
}
}
}
}
}
RabbitMQ持久化机制
核心代码:
channel.queueDeclare(queue_name, durable, false, false, null); //声明消息队列,且为可持久化的
String message="Hello world"+Math.random();
//将队列设置为持久化之后,还需要将消息也设为可持久化的,MessageProperties.PERSISTENT_TEXT_PLAIN
channel.basicPublish("", queue_name, MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());
消息什么时候需要持久化?
根据 官方博文 的介绍,RabbitMQ在两种情况下会将消息写入磁盘:
- 消息本身在publish的时候就要求消息写入磁盘;
- 内存紧张,需要将部分内存中的消息转移到磁盘;
消息什么时候会刷到磁盘?
- 写入文件前会有一个Buffer,大小为1M(1048576),数据在写入文件时,首先会写入到这个Buffer,如果Buffer已满,则会将Buffer写入到文件(未必刷到磁盘);
- 有个固定的刷盘时间:25ms,也就是不管Buffer满不满,每隔25ms,Buffer里的数据及未刷新到磁盘的文件内容必定会刷到磁盘;
- 每次消息写入后,如果没有后续写入请求,则会直接将已写入的消息刷到磁盘:使用Erlang的receive x after 0来实现,只要进程的信箱里没有消息,则产生一个timeout消息,而timeout会触发刷盘操作。
消息在磁盘文件中的格式
消息保存于$MNESIA/msg_store_persistent/x.rdq文件中,其中x为数字编号,从1开始,每个文件最大为16M(16777216),超过这个大小会生成新的文件,文件编号加1。消息以以下格式存在于文件中:
<<Size:64, MsgId:16/binary, MsgBody>>
MsgId为RabbitMQ通过rabbit_guid:gen()每一个消息生成的GUID,MsgBody会包含消息对应的exchange,routing_keys,消息的内容,消息对应的协议版本,消息内容格式(二进制还是其它)等等。
文件何时删除?
当所有文件中的垃圾消息(已经被删除的消息)比例大于阈值(GARBAGE_FRACTION = 0.5)时,会触发文件合并操作(至少有三个文件存在的情况下),以提高磁盘利用率。
publish消息时写入内容,ack消息时删除内容(更新该文件的有用数据大小),当一个文件的有用数据等于0时,删除该文件。
消息索引什么时候需要持久化?
索引的持久化与消息的持久化类似,也是在两种情况下需要写入到磁盘中:要么本身需要持久化,要么因为内存紧张,需要释放部分内存。
消息索引什么时候会刷到磁盘?
- 有个固定的刷盘时间:25ms,索引文件内容必定会刷到磁盘;
- 每次消息(及索引)写入后,如果没有后续写入请求,则会直接将已写入的索引刷到磁盘,实现上与消息的timeout刷盘一致。
RabbitMQ(二)队列与消息的持久化
当有多个消费者同时收取消息,且每个消费者在接收消息的同时,还要做其它的事情,且会消耗很长的时间,在此过程中可能会出现一些意外,比如消息接收到一半的时候,一个消费者宕掉了,这时候就要使用消息接收确认机制,可以让其它的消费者再次执行刚才宕掉的消费者没有完成的事情。另外,在默认情况下,我们创建的消息队列以及存放在队列里面的消息,都是非持久化的,也就是说当RabbitMQ宕掉了或者是重启了,创建的消息队列以及消息都不会保存,为了解决这种情况,保证消息传输的可靠性,我们可以使用RabbitMQ提供的消息队列的持久化机制。
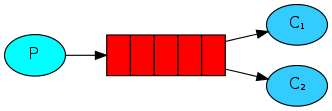
生产者:
2 import com.rabbitmq.client.Connection;
3 import com.rabbitmq.client.Channel;
4 import com.rabbitmq.client.MessageProperties;
5 public class ClientSend1 {
6 public static final String queue_name="my_queue";
7 public static final boolean durable=true; //消息队列持久化
8 public static void main(String[] args)
9 throws java.io.IOException{
10 ConnectionFactory factory=new ConnectionFactory(); //创建连接工厂
11 factory.setHost("localhost");
12 factory.setVirtualHost("my_mq");
13 factory.setUsername("zhxia");
14 factory.setPassword("123456");
15 Connection connection=factory.newConnection(); //创建连接
16 Channel channel=connection.createChannel();//创建信道
17 channel.queueDeclare(queue_name, durable, false, false, null); //声明消息队列,且为可持久化的
18 String message="Hello world"+Math.random();
19 //将队列设置为持久化之后,还需要将消息也设为可持久化的,MessageProperties.PERSISTENT_TEXT_PLAIN
20 channel.basicPublish("", queue_name, MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());
21 System.out.println("Send message:"+message);
22 channel.close();
23 connection.close();
24 }
25
26 }
说明:
行17 和行20 需要同时设置,也就是将队列设置为持久化之后,还需要将发送的消息也要设置为持久化才能保证队列和消息一直存在
消费者:
2 import com.rabbitmq.client.Connection;
3 import com.rabbitmq.client.Channel;
4 import com.rabbitmq.client.QueueingConsumer;
5 public class ClientReceive1 {
6 public static final String queue_name="my_queue";
7 public static final boolean autoAck=false;
8 public static final boolean durable=true;
9 public static void main(String[] args)
10 throws java.io.IOException,java.lang.InterruptedException{
11 ConnectionFactory factory=new ConnectionFactory();
12 factory.setHost("localhost");
13 factory.setVirtualHost("my_mq");
14 factory.setUsername("zhxia");
15 factory.setPassword("123456");
16 Connection connection=factory.newConnection();
17 Channel channel=connection.createChannel();
18 channel.queueDeclare(queue_name, durable, false, false, null);
19 System.out.println("Wait for message");
20 channel.basicQos(1); //消息分发处理
21 QueueingConsumer consumer=new QueueingConsumer(channel);
22 channel.basicConsume(queue_name, autoAck, consumer);
23 while(true){
24 Thread.sleep(500);
25 QueueingConsumer.Delivery deliver=consumer.nextDelivery();
26 String message=new String(deliver.getBody());
27 System.out.println("Message received:"+message);
28 channel.basicAck(deliver.getEnvelope().getDeliveryTag(), false);
29 }
30 }
31 }
说明:
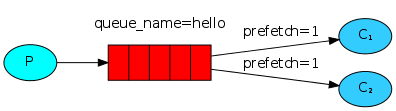
行22: 设置RabbitMQ调度分发消息的方式,也就是告诉RabbitMQ每次只给消费者处理一条消息,也就是等待消费者处理完并且已经对刚才处理的消息进行确认之后, 才发送下一条消息,防止消费者太过于忙碌。如下图所示:
【转】RabbitMQ基础——和——持久化机制的更多相关文章
- RabbitMQ的持久化机制
一.问题的引出 RabbitMQ的一大特色是消息的可靠性,那么它是如何保证消息可靠性的呢?——消息持久化.为了保证RabbitMQ在退出,服务重启或者crash等异常情况下,也不会丢失消息,我们可以将 ...
- 消息中间件-RabbitMQ持久化机制、内存磁盘控制
RabbitMQ持久化机制 RabbitMQ内存控制 RabbitMQ磁盘控制 RabbitMQ持久化机制 重启之后没有持久化的消息会丢失 package com.study.rabbitmq.a13 ...
- RabbitMQ 发布订阅持久化
RabbitMQ是一种重要的消息队列中间件,在生产环境中,稳定是第一考虑.RabbitMQ厂家也深知开发者的声音,稳定.可靠是第一考虑,为了消息传输的可靠性传输,RabbitMQ提供了多种途径的消息持 ...
- Rabbit MQ 消息确认和持久化机制
一:确认种类 RabbitMQ的消息确认有两种.一种是消息发送确认,用来确认生产者将消息发送给交换器,交换器传递给队列的过程中消息是否成功投递.发送确认分为两步,一是确认是否到达交换器,二是确认是否到 ...
- RabbitMQ基础知识详解
什么是MQ? MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法.MQ是消费-生产者模型的一个典型的代表,一端往消息队列中不断写入消息,而另一端则可以读取队列中 ...
- RabbitMQ,Apache的ActiveMQ,阿里RocketMQ,Kafka,ZeroMQ,MetaMQ,Redis也可实现消息队列,RabbitMQ的应用场景以及基本原理介绍,RabbitMQ基础知识详解,RabbitMQ布曙
消息队列及常见消息队列介绍 2017-10-10 09:35操作系统/客户端/人脸识别 一.消息队列(MQ)概述 消息队列(Message Queue),是分布式系统中重要的组件,其通用的使用场景可以 ...
- SpringCloudStream学习(一)RabbitMQ基础
应公司大佬要求,学习一下SpringCloudStream,作为技术储备.这几天也看了这方面的资料,现在写一篇笔记,以做总结.文章会从RabbitMQ基础讲起,到SpringCloudStream结束 ...
- RabbitMQ 基础概念进阶
上一篇 RabbitMQ 入门之基础概念 介绍了 RabbitMQ 的一些基础概念,本文再来介绍其中的一些细节和其它的进阶的概念. 一.消息生产者发送的消息不可达时如何处理 RabbitMQ 提供了消 ...
- Redis提供的持久化机制(RDB和AOF)
Redis提供的持久化机制 Redis是一种面向"key-value"类型数据的分布式NoSQL数据库系统,具有高性能.持久存储.适应高并发应用场景等优势.它虽然起步较晚,但发展却 ...
随机推荐
- Spring Boot 集成 logback日志
application.properties 配置logback.xml 路径注:如果logback.xml在默认的 src/main/resources 目录下则不需要配置application.p ...
- Kafka connect in practice(3): distributed mode mysql binlog ->kafka->hive
In the previous post Kafka connect in practice(1): standalone, I have introduced about the basics of ...
- 注解 - Excel 校验工具
注解类: @Retention(RetentionPolicy.RUNTIME) public @interface ExcelValidate { public boolean ignoreBlan ...
- [STM31F103]独立看门狗
独立看门狗步骤: l 取消寄存器写保护: n IWDG_WriteAccessCmd(); l 设置独立看门狗的预分频系数,确定时钟: n IWDG_SetPrescaler(); l 设置看门狗重装 ...
- 数据库索引的数据结构b+树
b+树的查找过程:如上图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针, ...
- 《机器学习实战》之一:knn(python代码)
数据 标称型和数值型 算法 归一化处理:防止数值较大的特征对距离产生较大影响 计算欧式距离:测试样本与训练集 排序:选取前k个距离,统计频数(出现次数)最多的类别 def classify0(inX, ...
- java 连接SQL Server
1.确认服务器的连通性,并且使用账户密码模式登陆有效. 1).登陆服务器 2).查看安全性 2.新建数据库用于测试 3.下载jdbc安装并配置 进入微软官网主页--> 搜索JDBC-->找 ...
- Spring boot 自定义拦截器
1.新建一个类实现HandlerInterceptor接口,重写接口的方法 package com.zpark.interceptor; import com.zpark.tools.Constant ...
- DOM编程艺术章12:一个简单的Ajax例子
大概入了JavaScript的门,现在要回过头恶补Ajax和json了,随手翻到dom编程艺术发现有一个适合回忆的例子,先抄录下来,引入对Ajax作用的大概印象,再去掰开了研究. <!DOCTY ...
- CI、CD相关概念
1.CI:持续集成(CONTINUOUS INTEGRATION) 基本概念 CI的全称是Continuous Integration,表示持续集成. 在CI环境中,开发人员将会频繁地向主干提交代码. ...