使用K-means进行聚类,用calinski_harabaz_score评价聚类效果
代码如下:
"""
下面的方法是用kmeans方法进行聚类,用calinski_harabaz_score方法评价聚类效果的好坏
大概是类间距除以类内距,因此这个值越大越好 """
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import KMeans
from sklearn import metrics
"""
下面是生成一些样本数据
X为样本特征,Y为样本簇类别, 共1000个样本,每个样本2个特征,共4个簇,簇中心在[-1,-1], [0,0],[1,1], [2,2],
簇方差分别为[0.4, 0.5, 0.2]
"""
X, y = make_blobs(n_samples=500, n_features=2, centers=[[2,3], [3,0], [1,1]], cluster_std=[0.4, 0.5, 0.2],
random_state =9)
"""
首先画出生成的样本数据的分布
"""
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
"""
下面看不同的k值下的聚类效果
"""
score_all=[]
list1=range(2,6)
#其中i不能为0,也不能为1
for i in range(2,6):
y_pred = KMeans(n_clusters=i, random_state=9).fit_predict(X)
#画出结果的散点图
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
score=metrics.calinski_harabaz_score(X, y_pred)
score_all.append(score)
print(score)
"""
画出不同k值对应的聚类效果
"""
plt.plt(list1,score_all)
plt.show()
原来的数据分布图为:
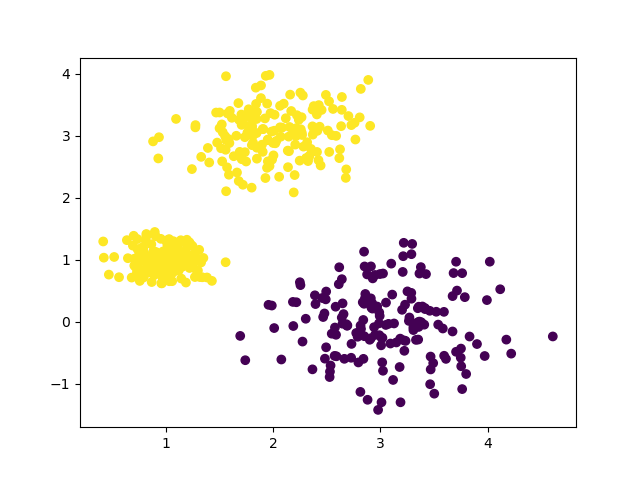
k=2时,聚类情况:
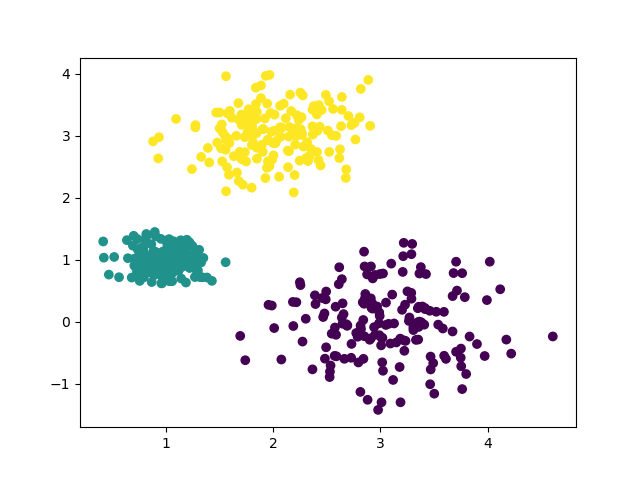
k=3时,聚类情况:
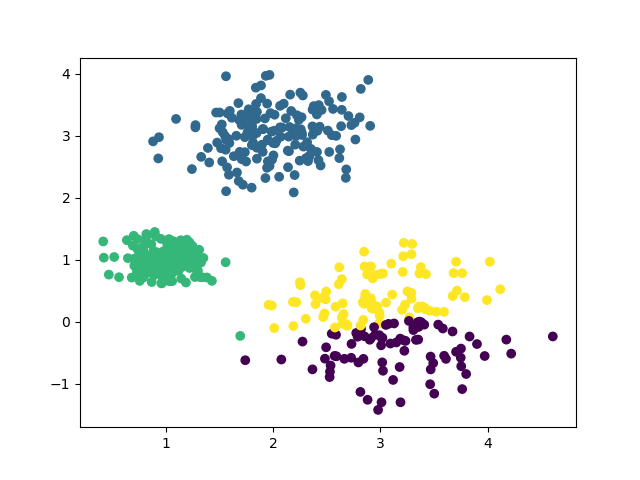
k=4时的聚类效果:
k=5时的聚类效果:

不同k值对应的聚类效果折线图:
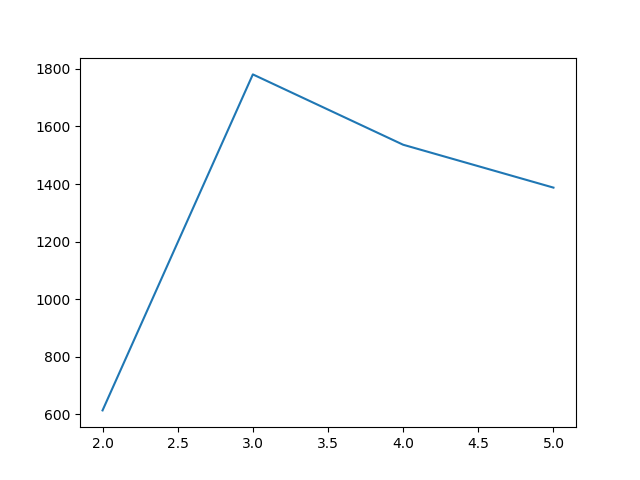
我们可以看到,k=3时,哪个值最大,效果最好。
使用K-means进行聚类,用calinski_harabaz_score评价聚类效果的更多相关文章
- 聚类 高维聚类 聚类评估标准 EM模型聚类
高维数据的聚类分析 高维聚类研究方向 高维数据聚类的难点在于: 1.适用于普通集合的聚类算法,在高维数据集合中效率极低 2.由于高维空间的稀疏性以及最近邻特性,高维的空间中基本不存在数据簇. 在高维聚 ...
- 【聚类算法】谱聚类(Spectral Clustering)
目录: 1.问题描述 2.问题转化 3.划分准则 4.总结 1.问题描述 谱聚类(Spectral Clustering, SC)是一种基于图论的聚类方法——将带权无向图划分为两个或两个以上的最优子图 ...
- SparkMLlib聚类学习之KMeans聚类
SparkMLlib聚类学习之KMeans聚类 (一),KMeans聚类 k均值算法的计算过程非常直观: 1.从D中随机取k个元素,作为k个簇的各自的中心. 2.分别计算剩下的元素到k个簇中心的相异度 ...
- 100天搞定机器学习|day54 聚类系列:层次聚类原理及案例
几张GIF理解K-均值聚类原理 k均值聚类数学推导与python实现 前文说了k均值聚类,他是基于中心的聚类方法,通过迭代将样本分到k个类中,使每个样本与其所属类的中心或均值最近. 今天我们看一下无监 ...
- <第一周> city中国城市聚类 testdata学生上网聚类 例子
中国城市聚类 # -*- coding: utf-8 -*- kmeans算法 """ Created on Thu May 18 22:55:45 2017 @auth ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 【机器学习】聚类算法:层次聚类、K-means聚类
聚类算法实践(一)--层次聚类.K-means聚类 摘要: 所谓聚类,就是将相似的事物聚集在一 起,而将不相似的事物划分到不同的类别的过程,是数据分析之中十分重要的一种手段.比如古典生物学之中,人们通 ...
- 使用K近邻算法改进约会网站的配对效果
1 定义数据集导入函数 import numpy as np """ 函数说明:打开并解析文件,对数据进行分类:1 代表不喜欢,2 代表魅力一般,3 代表极具魅力 Par ...
随机推荐
- Java并发编程75道面试题及答案
1.在java中守护线程和本地线程区别? java中的线程分为两种:守护线程(Daemon)和用户线程(User). 任何线程都可以设置为守护线程和用户线程,通过方法Thread.setDaemon( ...
- python rabbitMQ持久化队列消息
import pika connection = pika.BlockingConnection( pika.ConnectionParameters('localhost'))#建立一个最基本的so ...
- vue页面绑定数据,渲染页面时会出现页面闪烁
<style type="text/css"> [v-cloak] { display: none; } </style> <div id=" ...
- bugku 密码学一些题的wp
---恢复内容开始--- 1.滴答滴 摩斯密码,http://tool.bugku.com/mosi/ 2.聪明的小羊 从提示猜是栅栏密码,http://tool.bugku.com/jiemi/ 3 ...
- Sql 无法解决 equal to 运算中 "Chinese_PRC_CI_AS" 和 "Chinese_PRC_90_CI_AI" 之间的排序规则冲突
导致问题原因为创建时,表所使用的排序规则不一致 解决办法: 在对比条件后增加 collate Chinese_PRC_90_CI_AI 的转义即可 如: where test1.FieldName = ...
- consul & registrator & consul-template 使用
consul & registrator & consul-template 使用 参考这里的文章: https://www.jianshu.com/p/a4c04a3eeb57 do ...
- Python基础测试题
1,执行Python脚本的两种方式 答:一种是 交互式,命令行shell启动Python,输入相应代码得出结果,无保存,另一种是 脚本式,例如:python 脚本文件.py,脚本文件一直存在,可编辑, ...
- Git自动化合并多个Commit
目录 git rebase逻辑 git editor的修改 处理git-rebase-todo文件 Python实现 当我们有多个commit或者从开源处拿到多个commit时,想合成一个commit ...
- 18.17 U-Boot+内核移植
18.17.1 移植U-Boot-2012.04.08 1.下载.建立source insight工程.编译.烧写.如果无运行分析原因. $ .tar.bz2 $ cd u-boot- $ make ...
- 安装owncloud出现:Error while trying to create admin user: An exception occurred while executing
安装owncloud出现:Error while trying to create admin user: An exception occurred while executing 1.安装ownc ...