[TensorFlow]Tensor维度理解
http://wossoneri.github.io/2017/11/15/[Tensorflow]The-dimension-of-Tensor/
Tensor维度理解
Tensor在Tensorflow中是N维矩阵,所以涉及到Tensor的方法,也都是对矩阵的处理。由于是多维,在Tensorflow中Tensor的流动过程就涉及到升维降维,这篇就通过一些接口的使用,来体会Tensor的维度概念。以下是个人体会,有不准确的请指出。
tf.reduce_mean
reduce_mean(
input_tensor,
axis=None,
keep_dims=False,
name=None,
reduction_indices=None
)
计算Tensor各个维度元素的均值。这个方法根据输入参数axis的维度上减少输入input_tensor的维度。
举个例子:
x = tf.constant([[1., 1.], [2., 2.]])
tf.reduce_mean(x) # 1.5
tf.reduce_mean(x, 0) # [1.5, 1.5]
tf.reduce_mean(x, 1) # [1., 2.]
x是二维数组[[1.0,1.0],[2.0, 2.0]]
当axis参数取默认值时,计算整个数组的均值:(1.+1.+2.+2.)/4=1.5
当axis取0,意味着对列取均值:[1.5, 1.5]
当axis取1,意味着对行取均值:[1.0, 2.0]
再换一个3*3的矩阵:
sess = tf.Session()
x = tf.constant([[1., 2., 3.], [4., 5., 6.], [7., 8., 9.]])
print(sess.run(x))
print(sess.run(tf.reduce_mean(x)))
print(sess.run(tf.reduce_mean(x, 0)))
print(sess.run(tf.reduce_mean(x, 1)))
输出结果是
[[ 1. 2. 3.]
[ 4. 5. 6.]
[ 7. 8. 9.]]
5.0
[ 4. 5. 6.]
[ 2. 5. 8.]
如果我再加一维是怎么计算的?
sess = tf.Session()
x = tf.constant([[[1., 1.], [2., 2.]], [[3., 3.], [4., 4.]]])
print(sess.run(x))
print(sess.run(tf.reduce_mean(x)))
print(sess.run(tf.reduce_mean(x, 0)))
print(sess.run(tf.reduce_mean(x, 1)))
print(sess.run(tf.reduce_mean(x, 2)))
我给的输入Tensor是三维数组:
[[[ 1. 1.]
[ 2. 2.]]
[[ 3. 3.]
[ 4. 4.]]]
推测一下,前面二维的经过处理都变成一维的,也就是经历了一次降维,那么现在三维的或许应该变成二维。但现在多了一维,应该从哪个放向做计算呢?
看下结果:
2.5
[[ 2. 2.]
[ 3. 3.]]
[[ 1.5 1.5]
[ 3.5 3.5]]
[[ 1. 2.]
[ 3. 4.]]
发现,
当axis参数取默认值时,依然计算整个数组的均值:(float)(1+2+3+4+1+2+3+4)/8=2.5
当axis取0,计算方式是:
[[(1+3)/2, (1+3)/2],
[(2+4)/2, (2+4)/2]]
当axis取1,计算方式是:
[[(1+2)/2, (1+2)/2],
[(3+4)/2, (3+4)/2]]
当axis取2,计算方式是:
[[(1+1)/2, (2+2)/2],
[(3+3)/2, (4+4)/2]]
看到这里,能推断出怎么从四维降到三维吗?
有人总结了一下:
规律:
对于k维的,
tf.reduce_xyz(x, axis=k-1)的结果是对最里面一维所有元素进行求和。
tf.reduce_xyz(x, axis=k-2)是对倒数第二层里的向量对应的元素进行求和。
tf.reduce_xyz(x, axis=k-3)把倒数第三层的每个向量对应元素相加。
链接
拿上面的数组验证这个规律:
[[[ 1. 1.]
[ 2. 2.]]
[[ 3. 3.]
[ 4. 4.]]]
我们的k=3。小括号是一层,在一层内进行计算:
axis=3-1=2,做最内层计算,我们的最内层就是(1,1),(2,2),(3,3),(4,4),计算出来的就是
[[ 1. 2.]
[ 3. 4.]]
axis=3-2=1,做倒数第二层计算(参考二维计算):([1,1],[2,2])和([3, 3],[4, 4])
[[ 1.5 1.5]
[ 3.5 3.5]]
axis=3-3=1,做倒数第三层计算:([[1, 1], [2, 2]])([[3, 3], [4, 4]])
[[ 2. 2.]
[ 3. 3.]]
对于四维的,就贴段结果,自己可以尝试算一下,加深理解。
# input 4-D
[[[[ 1. 1.]
[ 2. 2.]]
[[ 3. 3.]
[ 4. 4.]]]
[[[ 5. 5.]
[ 6. 6.]]
[[ 7. 7.]
[ 8. 8.]]]]
# axis=none
4.5
# axis=0
[[[ 3. 3.]
[ 4. 4.]]
[[ 5. 5.]
[ 6. 6.]]]
# axis=1
[[[ 2. 2.]
[ 3. 3.]]
[[ 6. 6.]
[ 7. 7.]]]
在tensorflow 1.0版本中,
reduction_indices被改为了axis,在所有reduce_xxx系列操作中,都有reduction_indices这个参数,即沿某个方向,使用xxx方法,对input_tensor进行降维。
对于axis参数的作用,文档的解释是
the rank of the tensor is reduced by 1 for each entry in axis
即Tensor在axis的每一个分量上的秩减少1。如何理解矩阵的「秩」? - 马同学的回答 - 知乎
附一张reduction_indices的图
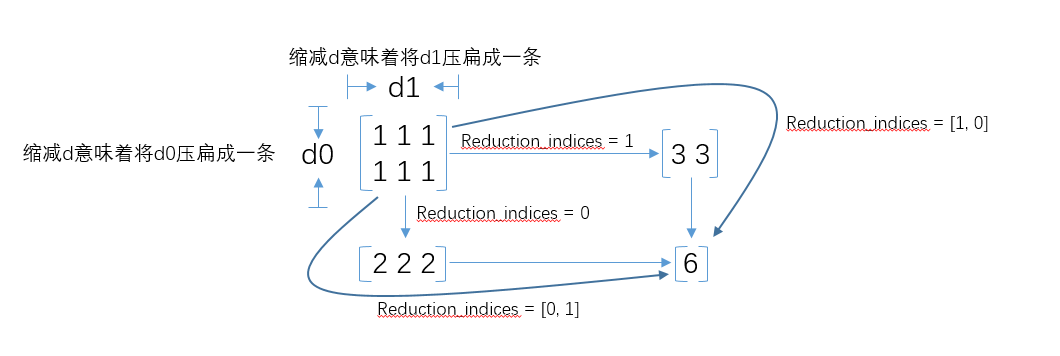
下面再看下第三个参数keep_dims,该参数缺省值是False,如果设置为True,那么减少的维度将被保留为长度为1。
回头看看最开始的例子:
# 2*2
[[ 1. 1.]
[ 2. 2.]]
# keep_dims=False
[ 1.5 1.5] # 1*2
[ 1. 2.] #1*2
# keep_dims=True
[[ 1.5 1.5]] #1*2
[[ 1.] #2*1
[ 2.]]
可以看到差别。关于这个参数,还没看到太多介绍,还需要了解。
[TensorFlow]Tensor维度理解的更多相关文章
- pytorch tensor 维度理解.md
torch.randn torch.randn(*sizes, out=None) → Tensor(张量) 返回一个张量,包含了从标准正态分布(均值为0,方差为 1)中抽取一组随机数,形状由可变参数 ...
- tensorflow中的函数获取Tensor维度的两种方法:
获取Tensor维度的两种方法: Tensor.get_shape() 返回TensorShape对象, 如果需要确定的数值而把TensorShape当作list使用,肯定是不行的. 需要调用Tens ...
- pytorch 中改变tensor维度的几种操作
具体示例如下,注意观察维度的变化 #coding=utf-8 import torch """改变tensor的形状的四种不同变化形式""" ...
- 对Tensorflow中tensor的理解
Tensor即张量,在tensorflow中所有的数据都通过张量流来传输,在看代码的时候,对张量的概念很不解,很容易和矩阵弄混,今天晚上查了点资料,并深入了解了一下,简单总结一下什么是张量的阶,以及张 ...
- tensor维度变换
维度变换是tensorflow中的重要模块之一,前面mnist实战模块我们使用了图片数据的压平操作,它就是维度变换的应用之一. 在详解维度变换的方法之前,这里先介绍一下View(视图)的概念.所谓Vi ...
- tensor 维度 问题。
tf.argmax takes two arguments: input and dimension. example: tf.argmx(arr, dimension = 1). or tf.arg ...
- 关于类型为numpy,TensorFlow.tensor,torch.tensor的shape变化以及相互转化
https://blog.csdn.net/zz2230633069/article/details/82669546 2018年09月12日 22:56:50 一只tobey 阅读数:727 1 ...
- 从维度理解dp问题
对于dp,我目前的理解就是,干成题目中的那件事需要作出若干次决策,然后你要取其中最优的结果,我们可以用深搜来递归地找最优解,然后我们来观察一下这个递归树的形状,如果它能从底往上直接递推的话,就不用递归 ...
- tensorflow tensor Flatten 张量扁平化,多通道转单通道数据
slim.flatten(inputs,outputs_collections=None,scope=None) (注:import tensorflow.contrib.slim as slim) ...
随机推荐
- Python——爬虫进阶
课程内容 Python爬虫——反爬 Python加密与解密 Python模块——HashLib与base64 Python爬虫——selenium模块 Python——pytessercat识别 ...
- python应用-爬取猫眼电影top100
import requests import re import json import time from requests.exceptions import RequestException d ...
- mysql 开发进阶篇系列 22 磁盘I/O问题(从linux操作系统上优化)
1. 使用Symbolic Links分布I/O mysql的数据库名和表名是与文件系统的目录名和文件名对应的,默认情况下,创建的数据库和表都存放在参数datadir定义的目录下.如果不使用RAID或 ...
- [疑难杂症]__当你的Cortana搜索无法使用,显示纯白界面(ps:已解决).
前言 这个问题是在前不久解决关于我电脑点击屏幕上方快捷方式不久后出现的问题,之前并没有出现过这样的错误,但因为使用到的情况比较少,就一直没有去解决,但在一点时间后,发现没有Cortana搜索栏还是十分 ...
- shiro 返回json字符串 + 自定义filter
前言: 在前后端分离的项目中, 在使用shiro的时候, 我们绝大部分时候, 并不想让浏览器跳转到那个页面去, 而是告诉前端, 你没有登录, 或者没有访问权限. 那这时候, 我们就需要返回json字符 ...
- github代码clone加速
这阵子想看看开源项目 MyBatis 的源码,结果使用 git 的 clone 命令怎么也 clone 不下来,我以为是网速慢,上 Google 一搜,原来 Github 的域名被 DNS 污染了,我 ...
- leetcode — permutation-sequence
import java.util.ArrayList; import java.util.List; /** * Source : https://oj.leetcode.com/problems/p ...
- 日志切割工具logrotate解决Tomcat catalina.out日志过大的问题
一.介绍日志切割logrotate 对于Linux系统安全来说,日志文件是极其重要的工具.不知为何,我发现很多运维同学的服务器上都运行着一些诸如每天切分Nginx日志之类的CRON脚本,大家似乎遗忘了 ...
- 让Python代码更快运行的 5 种方法
不论什么语言,我们都需要注意性能优化问题,提高执行效率.选择了脚本语言就要忍受其速度,这句话在某种程度上说明了Python作为脚本语言的不足之处,那就是执行效率和性能不够亮.尽管Python从未如C和 ...
- Java并发(二)—— 并发编程的挑战 与 并发机制的底层原理
单核处理器也可以支持多线程,因为CPU是通过时间片分配算法来循环执行任务 多线程一定比单线程快么?不一定,因为线程创建和上下文切换都需要开销. 如何减少上下文切换 无锁并发编程 CAS算法 使用最少线 ...