hadoop-1.2.1集群搭建
继续上一篇:http://www.cnblogs.com/CoolJayson/p/7430654.html
首先需要安装上台虚拟机, 分别为: master, salve1, slave2
1.复制CentOS_6.5, 分别重命名为-slave1和-slave2
2.用虚拟机打开slave1和slave2, 因为我们使用的是NAT模式, 此时三台虚拟机的ip是相同的需要进行修改.(关于如何修改请参考上一篇)
修改完成后重启网络服务, 查看ip和网卡(HWaddr)是否有相同的, 如果网卡相同的话, 进入到虚拟机设置, 移除原来的网络适配器,再重新添加一个网络适配器, 网卡就改变了.
完成后通过SecureCRT连接三台虚拟机, 测试是否能够连接网络.



3. 安装jdk
在虚拟机中设置共享文件夹(目录为jdk所在的目录)
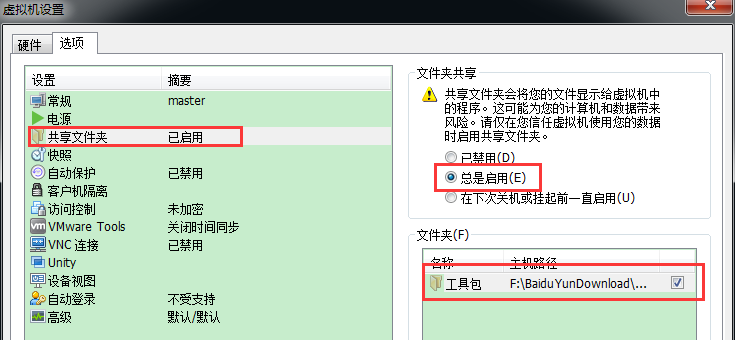
查看是否共享成功, 使用命令 cd /mnt/hgfs/ 下查看是否有共享的文件夹

共享成功后将jdk拷贝到 /usr/local/src/目录下

开始安装jdk

安装完成后添加环境变量: 编辑根目录下的.bashrc文件

添加完环境变量后按ESC, 使用命令 :wq 保存退出, 使用source ~/.bashrc是配置的环境变量生效(或者用命令bash)


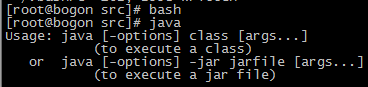
执行以下命令, 将jdk从master拷贝到salve2(拷贝到salve1也是相同操作), 然后重复上述操作在slave1和salve2中安装jdk并且配置环境变量.

>>>>>>>>>>>>>开始安装hadoop集群>>>>>>>>>>>>>
1.在共享文件夹中将hadoop压缩包拷贝到/usr/local/src/目录下, 同时进行解压

2.进入到hadoop解压的目录中,创建一个tmp文件夹用来存放临时文件

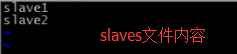
3.进入到conf目录下, 修改masters文件和slaves文件

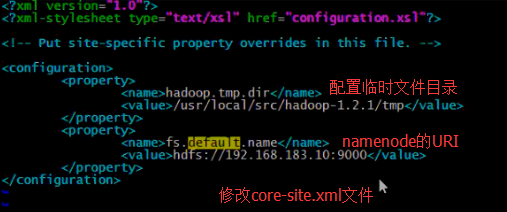
4.修改core-site.xml文件和mapred-site.xml文件

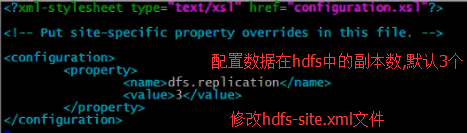
5.修改hdfs-site.xml文件和hadoop-env.sh文件

6.本地网络配置, 修改/etc/hosts文件, 配置后可以直接通过hostname(master/slave1/slave2)来访问虚拟机而不需要通过ip来访问

7.修改虚拟机的hostname, 如果要永久生效需要修改/etc/sysconfig/network文件


目前为止在master节点一共修改了以下8个文件:
hadoop的conf目录下的: masters, slaves, core-site.xml, mapred-site.xml, hdfs-site.xml, hadoop-env.sh
以及 /etc/hosts文件和 /etc/sysconfig/network文件.
8.将hadoop解压文件远程拷贝到slave1和slave2节点. 检查以下拷贝的文件是否有误.


9.修改slave1和slave2节点的/etc/hosts文件和/etc/sysconfig/network文件. slave1和slave2的/etc/hosts文件和master相同.



10.通过 hostname slave1和hostname slave2命令让hostname立即生效. /etc/sysconfig/network文件的修改要重启虚拟机后才能生效


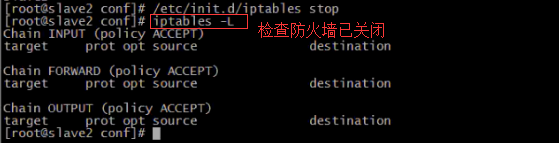
11.系统环境不同, 为了避免网络传输出现问题时难排查, 对防火墙和selinux进行关闭. 每台机器都要关闭防火墙和selinux. 通过iptables -L命令检查防火墙是否已关闭


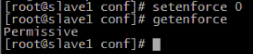
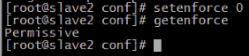
12.建立每台机器之间的互信机制(在远程访问每台机器的ip或hostname时不用再输入密码)
在master节点通过ssh-keygen生成密钥文件

进入~/.ssh/隐藏目录, 将id_rsa.pub公钥文件拷贝到authorized_keys文件, 并检查两个文件内容是否相同.

在slave1和slave2节点也通过ssh-keygen命令生成密钥, 并把它们的公钥拷贝到master节点的authorized_keys文件中
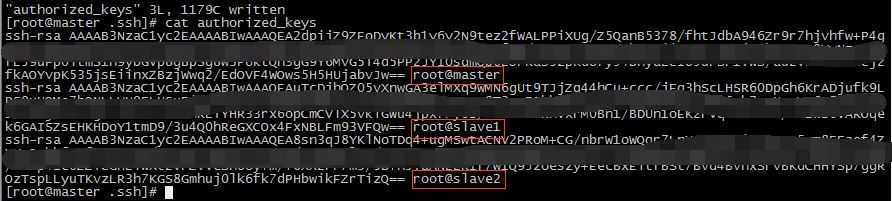
将authorized_keys文件拷贝到slave1和slave2节点中.
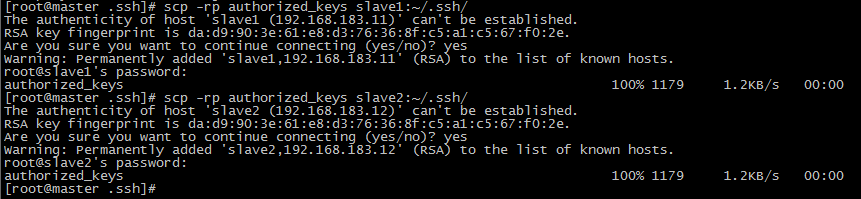
此时在master节点可以直接通过ssh slave1来访问slave1节点而不需要密码, 在slave1节点也可以通过ssh master直接访问master.

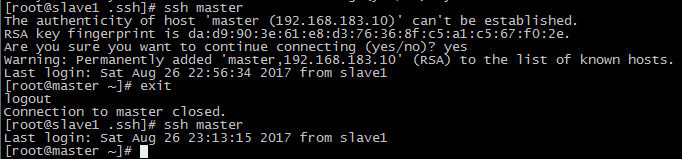
13.进入到hadoop目录下的bin目录, 先进行格式化
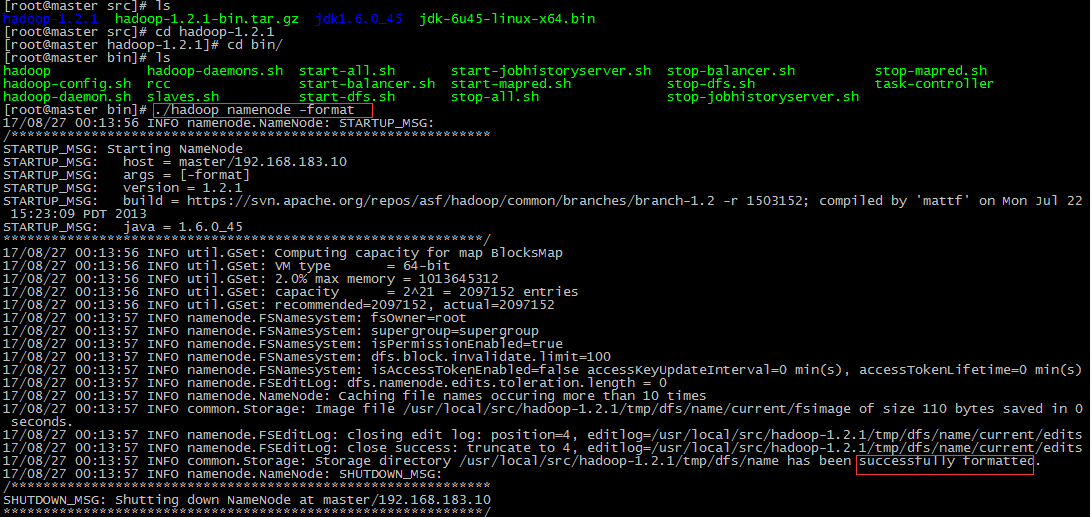
14.通过 ./start-all.sh 命令把整个集群启动起来, 通过jps查看每个节点的进程.


15.通过 ./hadoop fs -ls / 命令查看hdfs文件系统
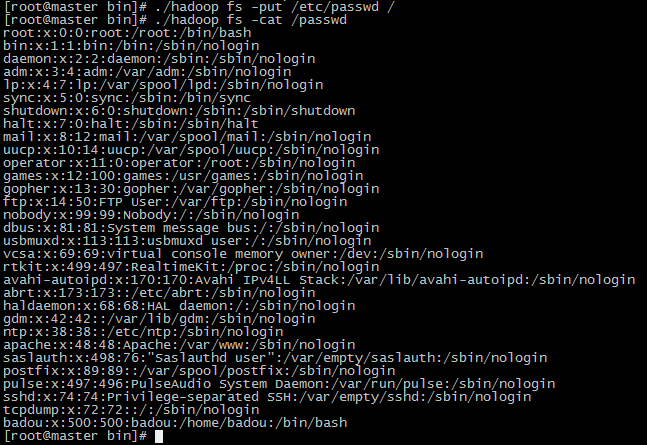
16.通过 ./hadoop fs -put /etc/passwd / 命令将passwd文件拷贝到hdfs文件系统中, 如果没有报错就说明成功了.

17.通过 ./hadoop fs -cat /passwd 命令来读取passwd文件.
---------------- 到这里hadoop集群就配置成功了!!!------------------
hadoop-1.2.1集群搭建的更多相关文章
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Ubuntu 12.04下Hadoop 2.2.0 集群搭建(原创)
现在大家可以跟我一起来实现Ubuntu 12.04下Hadoop 2.2.0 集群搭建,在这里我使用了两台服务器,一台作为master即namenode主机,另一台作为slave即datanode主机 ...
- 高可用Hadoop平台-HBase集群搭建
1.概述 今天补充一篇HBase集群的搭建,这个是高可用系列遗漏的一篇博客,今天抽时间补上,今天给大家介绍的主要内容目录如下所示: 基础软件的准备 HBase介绍 HBase集群搭建 单点问题验证 截 ...
- Hadoop初期学习和集群搭建
留给我学习hadoop的时间不多了,要提高效率,用上以前学的东西.hadoop要注重实战,把概念和原理弄清楚,之前看过一些spark,感觉都是一些小细节,对于理解hadoop没什么帮助.多看看资料,把 ...
- Hadoop HA高可用集群搭建(2.7.2)
1.集群规划: 主机名 IP 安装的软件 执行的进程 drguo1 192.168.80.149 j ...
- Zookeeper(四)Hadoop HA高可用集群搭建
一.高可就集群搭建 1.集群规划 2.集群服务器准备 (1) 修改主机名(2) 修改 IP 地址(3) 添加主机名和 IP 映射(4) 同步服务器时间(5) 关闭防火墙(6) 配置免密登录(7) 安装 ...
- hadoop HA+kerberos HA集群搭建
IP.主机名规划 hadoop集群规划: hostname IP hadoop 备注 hadoop1 110.185.225.158 NameNode,ResourceManager,DFSZKFai ...
- 第3章 Hadoop 2.x分布式集群搭建
目录 3.1 配置各节点SSH无密钥登录 1.将各节点的秘钥加入到同一个授权文件中 2.拷贝授权文件到各个节点 3.测试无秘钥登录 3.2 搭建Hadoop集群 1.上传Hadoop并解压 2.配置H ...
- 3.环境搭建-Hadoop(CDH)集群搭建
目录 目录 实验环境 安装 Hadoop 配置文件 在另外两台虚拟机上搭建hadoop 启动hdfs集群 启动yarn集群 本文主要是在上节CentOS集群基础上搭建Hadoop集群. 实验环境 Ha ...
- Hadoop HA 高可用集群搭建
一.首先配置集群信息 vi /etc/hosts 二.安装zookeeper 1.解压至/usr/hadoop/下 .tar.gz -C /usr/hadoop/ 2.进入/usr/hadoop/zo ...
随机推荐
- 网络I/O模型总结
把网络IO模型整理了一下,如下图
- 异常处理和Throwable中的几个方法
package cn.lijun.demo; /* * try { //需要被检测的语句. } catch(异常类 变量) { //参数. //异常的处理语句. } finally { //一定会被执 ...
- Shiro进行简单的身份验证(二)
一个Realm数据源: shiro.ini: [users] wp=123456 main方法执行认证: package com.wp.shiro; import org.apache.shiro.S ...
- python自动化开发-[第十四天]-javascript(续)
今日概要: 1.数据类型 2.函数function 3.BOM 4.DOM 1.运算符 算术运算符: + - * / % ++ -- 比较运算符: > >= < <= != = ...
- grovvy生成随机汉字名字
StringBuilder sb = new StringBuilder(); for(int i = 0 ;i < 3; i++){ sb.append((char) (0x4e00 + (i ...
- NoClassDefFoundError com/google/inject/Injector
一个maven项目莫名其妙的遇上了NoClassDefFoundError com/google/inject/Injector,在maven-surefire-plugin插件中配置 了<fo ...
- android 与html交互java调js与js调java操作
1.首先在项目下建一个assets目录(右击app->New->Folder->Assets Flolder),直接放在项目根目录下和res目录同级别(把所html,js,图片,cs ...
- redis使用问题一:Cannot get Jedis connection; nested exception is redis.clients.jedis.exceptions.JedisException: Could not get a resource from the pool] with root cause
本文使用的是spring-data-redis 首先说下redis最简单得使用,除去配置. 需要在你要使用得缓存得地方,例如mybatis在mapper.xml中加入: <cache evict ...
- Springboot中Feign的使用总结
Feign是Webservice服务的客户端,创建接口+注解就可完成,实现简单 客户端通过@EnableFeignClients开启Feign的支持功能 @SpringBootApplication ...
- C#中的特性(Attributes)
约定: 1.”attribute”和”attributes”均不翻译 2.”property”译为“属性” 3.msdn中的原句不翻译 4.”program entity”译为”语言元素” Attri ...