hadoop-1.2.1集群搭建
继续上一篇:http://www.cnblogs.com/CoolJayson/p/7430654.html
首先需要安装上台虚拟机, 分别为: master, salve1, slave2
1.复制CentOS_6.5, 分别重命名为-slave1和-slave2
2.用虚拟机打开slave1和slave2, 因为我们使用的是NAT模式, 此时三台虚拟机的ip是相同的需要进行修改.(关于如何修改请参考上一篇)
修改完成后重启网络服务, 查看ip和网卡(HWaddr)是否有相同的, 如果网卡相同的话, 进入到虚拟机设置, 移除原来的网络适配器,再重新添加一个网络适配器, 网卡就改变了.
完成后通过SecureCRT连接三台虚拟机, 测试是否能够连接网络.



3. 安装jdk
在虚拟机中设置共享文件夹(目录为jdk所在的目录)
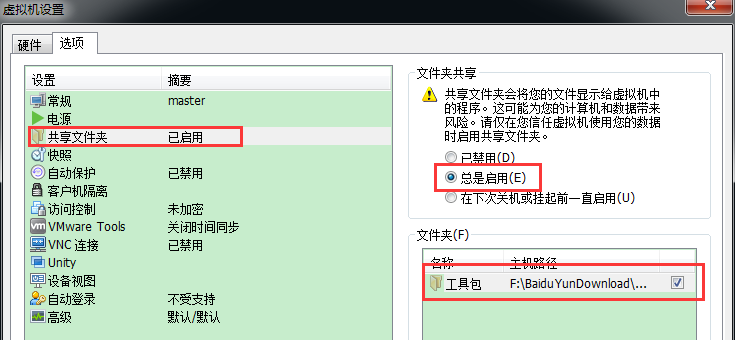
查看是否共享成功, 使用命令 cd /mnt/hgfs/ 下查看是否有共享的文件夹

共享成功后将jdk拷贝到 /usr/local/src/目录下

开始安装jdk

安装完成后添加环境变量: 编辑根目录下的.bashrc文件

添加完环境变量后按ESC, 使用命令 :wq 保存退出, 使用source ~/.bashrc是配置的环境变量生效(或者用命令bash)


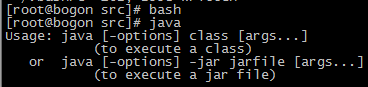
执行以下命令, 将jdk从master拷贝到salve2(拷贝到salve1也是相同操作), 然后重复上述操作在slave1和salve2中安装jdk并且配置环境变量.

>>>>>>>>>>>>>开始安装hadoop集群>>>>>>>>>>>>>
1.在共享文件夹中将hadoop压缩包拷贝到/usr/local/src/目录下, 同时进行解压

2.进入到hadoop解压的目录中,创建一个tmp文件夹用来存放临时文件

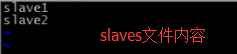
3.进入到conf目录下, 修改masters文件和slaves文件

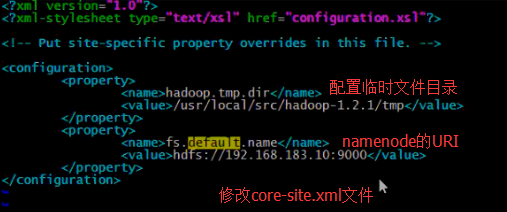
4.修改core-site.xml文件和mapred-site.xml文件

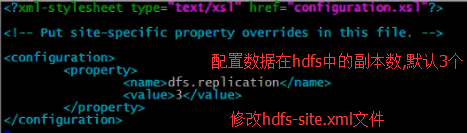
5.修改hdfs-site.xml文件和hadoop-env.sh文件

6.本地网络配置, 修改/etc/hosts文件, 配置后可以直接通过hostname(master/slave1/slave2)来访问虚拟机而不需要通过ip来访问

7.修改虚拟机的hostname, 如果要永久生效需要修改/etc/sysconfig/network文件


目前为止在master节点一共修改了以下8个文件:
hadoop的conf目录下的: masters, slaves, core-site.xml, mapred-site.xml, hdfs-site.xml, hadoop-env.sh
以及 /etc/hosts文件和 /etc/sysconfig/network文件.
8.将hadoop解压文件远程拷贝到slave1和slave2节点. 检查以下拷贝的文件是否有误.


9.修改slave1和slave2节点的/etc/hosts文件和/etc/sysconfig/network文件. slave1和slave2的/etc/hosts文件和master相同.



10.通过 hostname slave1和hostname slave2命令让hostname立即生效. /etc/sysconfig/network文件的修改要重启虚拟机后才能生效


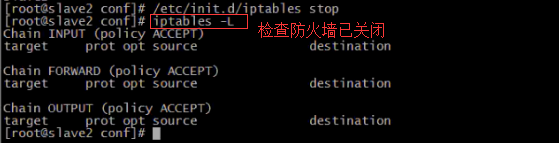
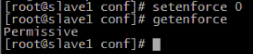
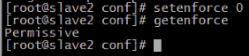
11.系统环境不同, 为了避免网络传输出现问题时难排查, 对防火墙和selinux进行关闭. 每台机器都要关闭防火墙和selinux. 通过iptables -L命令检查防火墙是否已关闭


12.建立每台机器之间的互信机制(在远程访问每台机器的ip或hostname时不用再输入密码)
在master节点通过ssh-keygen生成密钥文件

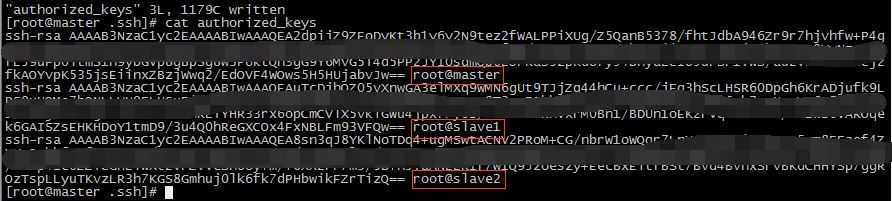
进入~/.ssh/隐藏目录, 将id_rsa.pub公钥文件拷贝到authorized_keys文件, 并检查两个文件内容是否相同.

在slave1和slave2节点也通过ssh-keygen命令生成密钥, 并把它们的公钥拷贝到master节点的authorized_keys文件中
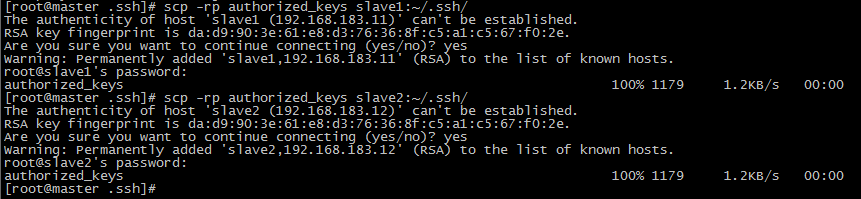
将authorized_keys文件拷贝到slave1和slave2节点中.
此时在master节点可以直接通过ssh slave1来访问slave1节点而不需要密码, 在slave1节点也可以通过ssh master直接访问master.

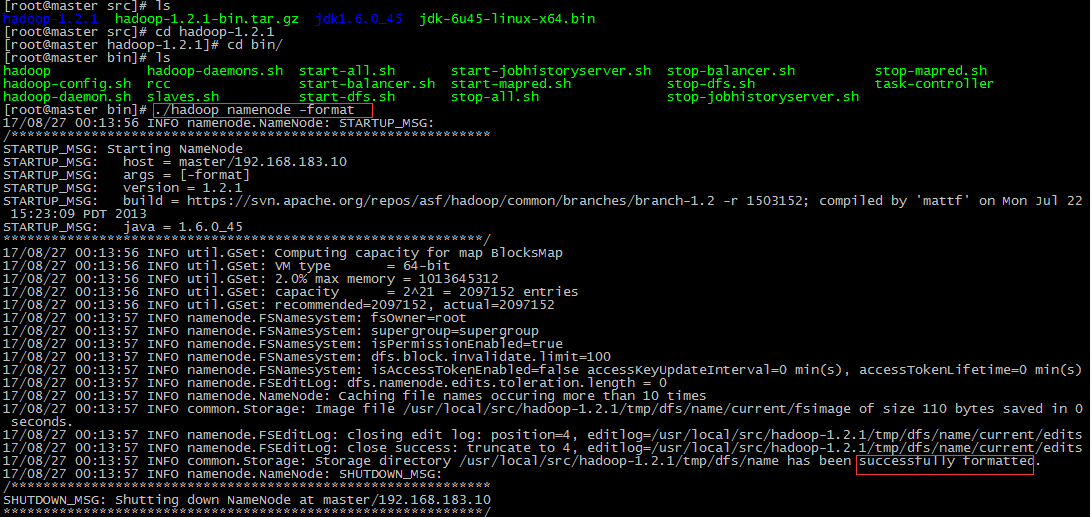
13.进入到hadoop目录下的bin目录, 先进行格式化
14.通过 ./start-all.sh 命令把整个集群启动起来, 通过jps查看每个节点的进程.


15.通过 ./hadoop fs -ls / 命令查看hdfs文件系统
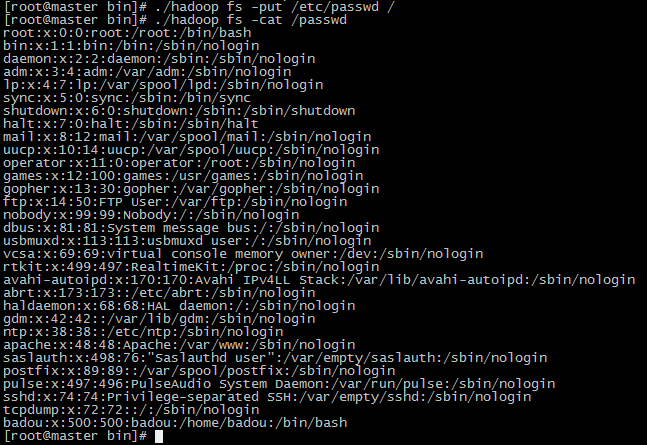
16.通过 ./hadoop fs -put /etc/passwd / 命令将passwd文件拷贝到hdfs文件系统中, 如果没有报错就说明成功了.

17.通过 ./hadoop fs -cat /passwd 命令来读取passwd文件.
---------------- 到这里hadoop集群就配置成功了!!!------------------
hadoop-1.2.1集群搭建的更多相关文章
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Ubuntu 12.04下Hadoop 2.2.0 集群搭建(原创)
现在大家可以跟我一起来实现Ubuntu 12.04下Hadoop 2.2.0 集群搭建,在这里我使用了两台服务器,一台作为master即namenode主机,另一台作为slave即datanode主机 ...
- 高可用Hadoop平台-HBase集群搭建
1.概述 今天补充一篇HBase集群的搭建,这个是高可用系列遗漏的一篇博客,今天抽时间补上,今天给大家介绍的主要内容目录如下所示: 基础软件的准备 HBase介绍 HBase集群搭建 单点问题验证 截 ...
- Hadoop初期学习和集群搭建
留给我学习hadoop的时间不多了,要提高效率,用上以前学的东西.hadoop要注重实战,把概念和原理弄清楚,之前看过一些spark,感觉都是一些小细节,对于理解hadoop没什么帮助.多看看资料,把 ...
- Hadoop HA高可用集群搭建(2.7.2)
1.集群规划: 主机名 IP 安装的软件 执行的进程 drguo1 192.168.80.149 j ...
- Zookeeper(四)Hadoop HA高可用集群搭建
一.高可就集群搭建 1.集群规划 2.集群服务器准备 (1) 修改主机名(2) 修改 IP 地址(3) 添加主机名和 IP 映射(4) 同步服务器时间(5) 关闭防火墙(6) 配置免密登录(7) 安装 ...
- hadoop HA+kerberos HA集群搭建
IP.主机名规划 hadoop集群规划: hostname IP hadoop 备注 hadoop1 110.185.225.158 NameNode,ResourceManager,DFSZKFai ...
- 第3章 Hadoop 2.x分布式集群搭建
目录 3.1 配置各节点SSH无密钥登录 1.将各节点的秘钥加入到同一个授权文件中 2.拷贝授权文件到各个节点 3.测试无秘钥登录 3.2 搭建Hadoop集群 1.上传Hadoop并解压 2.配置H ...
- 3.环境搭建-Hadoop(CDH)集群搭建
目录 目录 实验环境 安装 Hadoop 配置文件 在另外两台虚拟机上搭建hadoop 启动hdfs集群 启动yarn集群 本文主要是在上节CentOS集群基础上搭建Hadoop集群. 实验环境 Ha ...
- Hadoop HA 高可用集群搭建
一.首先配置集群信息 vi /etc/hosts 二.安装zookeeper 1.解压至/usr/hadoop/下 .tar.gz -C /usr/hadoop/ 2.进入/usr/hadoop/zo ...
随机推荐
- c3p0配置文件(c3p0.properties.xml)解读
package cn.lijun.demo; import com.mchange.v2.c3p0.ComboPooledDataSource; import javax.sql.DataSource ...
- 新建体(1):新建type
类似数组的类型: TYPE TAB_TYPE_MCHNO IS TABLE OF t_r_terminal.rt_merchno%type; tMchNo TAB_TYPE_MCHNO; )集合赋值: ...
- day12-(jsp&el&jstl)
回顾: jsp: cookie: 浏览器端会话技术 由服务器产生,生成key=value形式,通过响应头(set-cookie)返回给浏览器,保存在浏览器端 下次访问的时候根据一定的规则携带cooki ...
- 给笔记本更换SSD硬盘
给笔记本更换SSD硬盘... ---------- 给笔记本更换SSD硬盘 带活动字样的一个新的系统盘,一个之前的主分区的系统盘 ----------------------------
- HTTP常用头部信息
下面用例子的形式来记录下常用的一些Http头部信息 Request Header: GET /sample.Jsp HTTP/1.1 //请求行 Host: www.uuid.online/ // ...
- MyBatis-获取 xxxMapper
Main 方法,mybatis 版本为 3.5.0 使用 MapperProxyFactory 创建一个 MapperProxy 的代理对象 代理对象里面包含了 DefaultSqlSession(E ...
- JAVA核心技术I---JAVA基础知识(映射Map)
一:映射Map分类 二:Hashtable(同步,慢,数据量小) –K-V对,K和V都不允许为null –同步,多线程安全 –无序的 –适合小数据量 –主要方法:clear, contains/con ...
- JAVA核心技术I---JAVA基础知识(集合set)
一:集合了解 (一)确定性,互异性,无序性 确定性:对任意对象都能判定其是否属于某一个集合 互异性:集合内每个元素都是无差异的,注意是内容差异 无序性:集合内的顺序无关 (二)集合接口HashSet, ...
- mysql 用户及权限管理 小结
MySQL 默认有个root用户,但是这个用户权限太大,一般只在管理数据库时候才用.如果在项目中要连接 MySQL 数据库,则建议新建一个权限较小的用户来连接. 在 MySQL 命令行模式下输入如下命 ...
- Nginx 之六: Nginx服务器的正向及反向代理功能
一:Nginx作为正向代理服务器: 1.正向代理:代理(proxy)服务也可以称为是正向代理,指的是将服务器部署在公司的网关,代理公司内部员工上外网的请求,可以起到一定的安全作用和管理限制作用,正向代 ...