流式大数据计算实践(2)----Hadoop集群和Zookeeper
一、前言
1、上一文搭建好了Hadoop单机模式,这一文继续搭建Hadoop集群
二、搭建Hadoop集群
1、根据上文的流程得到两台单机模式的机器,并保证两台单机模式正常启动,记得第二台机器core-site.xml内的fs.defaultFS参数值要改成本机的来启动,启动完毕后再改回来
2、清空数据,首先把运行单机模式后生成的数据全部清理掉
rm -rf /work/hadoop/nn/current rm -rf /work/hadoop/dn/current hdfs namenode -format
3、启动集群
(1)storm1作为namenode节点,所以在这台机上面执行命令启动namenode
$HADOOP_PREFIX/sbin/hadoop-daemon.sh --script hdfs start namenode
(2)storm2作为datanode节点,所以在这台机上面执行命令启动datanode
$HADOOP_PREFIX/sbin/hadoop-daemon.sh --script hdfs start datanode
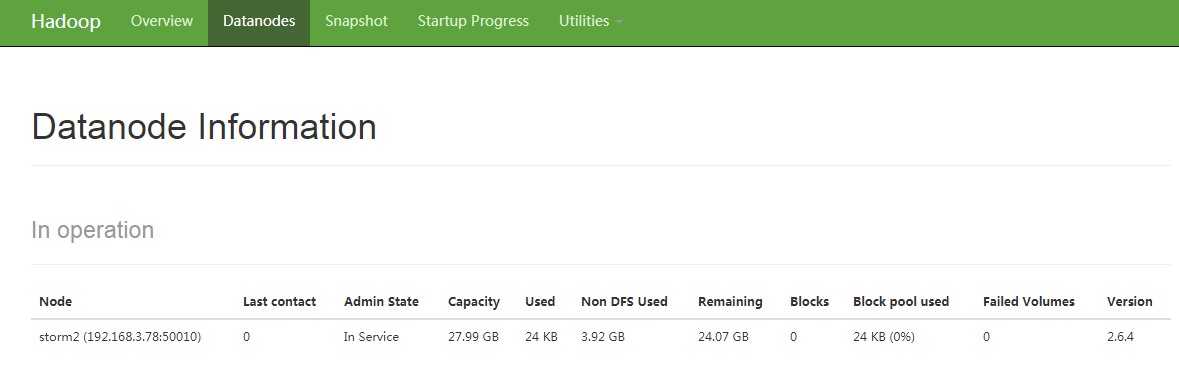
(3)通过jps命令可以看到对应的节点,然后通过50070的控制台可以看到storm2的datanode节点
三、ZooKeeper
1、Zookeeper是分布式框架经常要用到的应用协调服务,相当于让分布式内的每个组件同步起来
2、Zookeeper安装
(1)下载Zookeeper的tar.gz包,并解压
(2)配置环境变量
vim /etc/profile #set zookeeper env
export ZOOKEEPER_HOME=/work/soft/zookeeper-3.4.
export PATH=$PATH:$ZOOKEEPER_HOME/bin source /etc/profile
(3)配置ZooKeeper
①进入到Zookeeper目录的conf文件夹,可以看到里面有一个配置文件的模板zoo_sample.cfg,将模板复制一份到zoo.cfg
②然后编辑内容,只需要修改Zookeeper的存放数据的目录(记得创建对应文件夹)
vim /work/soft/zookeeper-3.4./conf/zoo.cfg dataDir=/work/zookeeper/data
③继续编辑bin目录下的zkEnv.sh文件来修改Zookeeper存放日志的目录(记得创建对应文件夹)
vim /work/soft/zookeeper-3.4./bin/zkEnv.sh ZOO_LOG_DIR=/work/zookeeper/logs
④进入到刚刚设定的数据目录,创建一个文件myid,并写入本台机器的Zookeeper Id,这个id的取值范围是1-255,我这里取得分别是1和2
vim /work/zookeeper/data/myid
(4)启动单机版Zookeeper
①首先启动Zookeeper
$ZOOKEEPER_HOME/bin/zkServer.sh start
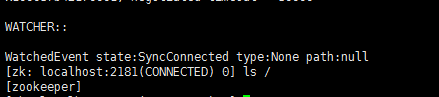
②进入到Zookeeper的控制台查看数据目录是否正常
$ZOOKEEPER_HOME/bin/zkCli.sh ls /
(5)启动集群版Zookeeper
①先停止单机版
$ZOOKEEPER_HOME/bin/zkServer.sh stop
②把刚刚单机版产生的数据删除,执行删除目录时,一定要小心不要输错,还有记得再把刚才的myid文件创建出来- -
rm -rf /work/zookeeper/data/*
rm -rf /work/zookeeper/logs/*
③进入Zookeeper的conf目录,编辑zoo.cfg,在文件末尾配置Zookeeper集群的节点信息
vim /work/soft/zookeeper-3.4./conf/zoo.cfg server.=storm1::
server.=storm2::
④在每台机器启动Zookeeper,然后通过jps命令查看进程是否存在
$ZOOKEEPER_HOME/bin/zkServer.sh start jps

⑤使用查看集群状态命令,在每台机器执行,可以发现一台是leader,另一台是follower,说明集群是OK的
$ZOOKEEPER_HOME/bin/zkServer.sh status


流式大数据计算实践(2)----Hadoop集群和Zookeeper的更多相关文章
- 流式大数据计算实践(1)----Hadoop单机模式
一.前言 1.从今天开始进行流式大数据计算的实践之路,需要完成一个车辆实时热力图 2.技术选型:HBase作为数据仓库,Storm作为流式计算框架,ECharts作为热力图的展示 3.计划使用两台虚拟 ...
- 流式大数据计算实践(3)----高可用的Hadoop集群
一.前言 1.上文中我们已经搭建好了Hadoop和Zookeeper的集群,这一文来将Hadoop集群变得高可用 2.由于Hadoop集群是主从节点的模式,如果集群中的namenode主节点挂掉,那么 ...
- 流式大数据计算实践(4)----HBase安装
一.前言 1.前面我们搭建好了高可用的Hadoop集群,本文正式开始搭建HBase 2.HBase简介 (1)Master节点负责管理数据,类似Hadoop里面的namenode,但是他只负责建表改表 ...
- 流式大数据计算实践(6)----Storm简介&使用&安装
一.前言 1.这一文开始进入Storm流式计算框架的学习 二.Storm简介 1.Storm与Hadoop的区别就是,Hadoop是一个离线执行的作业,执行完毕就结束了,而Storm是可以源源不断的接 ...
- 流式大数据计算实践(5)----HBase使用&SpringBoot集成
一.前言 1.上文中我们搭建好了一套HBase集群环境,这一文我们学习一下HBase的基本操作和客户端API的使用 二.shell操作 先通过命令进入HBase的命令行操作 /work/soft/hb ...
- 流式大数据计算实践(7)----Hive安装
一.前言 1.这一文学习使用Hive 二.Hive介绍与安装 Hive介绍:Hive是基于Hadoop的一个数据仓库工具,可以通过HQL语句(类似SQL)来操作HDFS上面的数据,其原理就是将用户写的 ...
- 大数据运维尖刀班 | 集群_监控_CDH_Docker_K8S_两项目_腾讯云服务器
说明:大数据时代,传统运维向大数据运维升级换代很常见,也是个不错的机会.如果想系统学习大数据运维,个人比较推荐通信巨头运维大咖的分享课:https://url.cn/5HIqOOr,主要是实战强.含金 ...
- 本地日志数据实时接入到hadoop集群的数据接入方案
1. 概述 本手册主要介绍了,一个将传统数据接入到Hadoop集群的数据接入方案和实施方法.供数据接入和集群运维人员参考. 1.1. 整体方案 Flume作为日志收集工具,监控一个文件目录或者一个文 ...
- 大数据学习路线:Hadoop集群同步技术分享
今天给大家带来的技术分享是——Hadoop集群同步. 一.同步方式 选择一个机器,作为时间服务器(这里选择hadoop01),所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间. ...
随机推荐
- 移动端--用PX为单位+JS框架 实现页面布局
一:大家先下载metahandler.js 二:准备一个用px实现的移动页面(宽度固定死的页面),引入metahandler.js框架 1.视口设置 width=640,是根据psd图来设置,有多宽设 ...
- spring 3.1.1 mvc HanderMapping源码
https://my.oschina.net/zhangxufeng/blog/2177464 RequestMappingHandlerMapping getMappingForMethod /** ...
- Excel把数据存入共享字符串文件中并返回该字符串的下标
public static int InsertSharedStringItem(string text, pkg.SharedStringTablePart shareStringPart) { i ...
- 解决Eclipse中无法直接使用Base64Encoder的问题(转载)
资源出处:https://blog.csdn.net/u011514810/article/details/72725398 Base64的加密解密都是使用sun.misc包下的BASE64Encod ...
- jQuery-事件命名空间
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- datepart in ssis
"\\\\"+_"+ (DT_STR,4,1252)DATEPART( "yyyy" , @[System::StartTime] ) + RIGHT ...
- 使用MXNet的NDArray来处理数据
NDArray.ipynb NDArray介绍 机器学习处理的对象是数据,数据一般是由外部传感器(sensors)采集,经过数字化后存储在计算机中,可能是文本.声音,图片.视频等不同形式. 这些数字化 ...
- eclipse中如何自动生成构造函数
eclipse中如何自动生成构造函数 eclipse是一个非常好的IDE,我在写java程序的时候使用eclipse感觉开发效率很高.而且有很多的快捷和简便方式供大家使用,并且能直接生成class文件 ...
- 数据结构(二): 轻量级键值对 SparseArray
SparseArray是Android framework中提供的轻量级的键值对数据结构,我们知道空间和效率从来都是相悖的,SparseArray的实现正是以时间来换取空间效率,适合小规模数据的存储. ...
- Javascript高级编程学习笔记(23)—— 函数表达式(1)递归
前面的文章中,我在介绍JS中引用类型的时候提过,JS中函数有两种定义方式 第一种是声明函数,即使用function关键字来声明 第二种就是使用函数表达式,将函数以表达式的形式赋值给一个变量,这个变量就 ...