(二). 细说Kalman滤波:The Kalman Filter
本文为原创文章,转载请注明出处,http://www.cnblogs.com/ycwang16/p/5999034.html
前面介绍了Bayes滤波方法,我们接下来详细说说Kalman滤波器。虽然Kalman滤波器已经被广泛使用,也有很多的教程,但我们在Bayes滤波器的框架上,来深入理解Kalman滤波器的设计,对理解采用Gaussian模型来近似状态分布的多高斯滤波器(Guassian Multi-Hyperthesis-Filter)等都有帮助。
一. 背景知识回顾
1.1 Bayes滤波
首先回顾一下Bayes滤波. Bayes滤波分为两步:1.状态预测;和 2.状态更新
1. 状态预测,基于状态转移模型:
$\overline {bel} ({x_t}) = \int {p({x_t}|{u_t},{x_{t - 1}})} \;bel({x_{t - 1}})\;d{x_{t - 1}}$
2. 状态更新,基于新的观测
$bel({x_t}) = \;\eta \,p({z_t}|{x_t})\,\overline {bel} ({x_t})$
我们可以看到,我们的目的是计算$x_t$的后验概率,如果$bel({x_t})$是任意分布,我们需要在$x_t$的所有可能取值点上,计算该取值的概率,这在计算上是难于实现的。这一计算问题可以有多种方法来近似,比如利用采样的方法,就是后面要讲的粒子滤波和无迹Kalman滤波。
这节要说的近似方法是,当假设$bel({x_t})$服从Gauss分布,那么我们只需要分布的均值和方差就可以完全描述$bel({x_t})$,而无需在$x_t$的每个可能取值点上进行概率计算。这也是用高斯分布来近似$bel({x_t})$的好处,因为我们在每一个时刻,只需要计算均值$\mu_t$和方差$\Sigma_t$这两个数值,就可以对$bel({x_t})$完全描述,所以我们就可以推导出这两个数值的递推公式,从而在每个时刻由这两个数值的递推公式完全获得状态估计,这就是The Kalman Filter的基本思想。
1.2 正态分布(Guassian Distribution)
然后我们再回顾一下正态分布的基础知识。正态分布是一种特殊的概率分布,分布的形态完全由二阶矩决定。一元高斯分布表述如下:
$$\begin{array}{l}
p(x)\sim N(\mu ,{\sigma ^2}):\\
p(x) = \frac{1}{{\sqrt {2\pi } \sigma }}{e^{ - \frac{1}{2}\frac{{{{(x - \mu )}^2}}}{{{\sigma ^2}}}}}
\end{array}$$
其中,一阶矩为均值$\mu$表示期望值,二阶矩为方差$\sigma$表示分布的不确定程度。
多元高斯分布的表达式为:
$$\begin{array}{l}
p({\bf{x}})\sim {\rm N}({\bf{\mu }},{\bf{\Sigma }}):\\
p({\bf{x}}) = \frac{1}{{{{(2\pi )}^{d/2}}{{\left| {\bf{\Sigma }} \right|}^{1/2}}}}{e^{ - \frac{1}{2}{{({\bf{x}} - {\bf{\mu }})}^t}{{\bf{\Sigma }}^{ - 1}}({\bf{x}} - {\bf{\mu }})}}
\end{array}$$
同样,一阶矩为$\bf{\mu}$表示各元变量的期望值,二阶矩为方差矩阵$\bf{\Sigma}$表示各元变量的不确定程度。
1.3 正态分布的特点
在线性变换下,一旦高斯,代代高斯。
首先,高斯变量线性变换后,仍为高斯分布,均值和方差如下:
$\left. {\begin{array}{*{20}{l}}
{X\sim N(\mu ,\Sigma )}\\
{Y = AX + B\quad \;}
\end{array}} \right\}\quad \Rightarrow \quad Y\sim N(A\mu + B,A\Sigma {A^T})$
然后,两个高斯变量线性组合,仍为高斯分布,均值和方差如下:
$\left. {\begin{array}{*{20}{c}}
{{X_1}\sim N({\mu _1},\sigma _1^2)}\\
{{X_2}\sim N({\mu _2},\sigma _2^2)}
\end{array}} \right\} \Rightarrow p({X_1} + {X_2})\sim N\left( {{\mu _1} + {\mu _2},\sigma _1^2 + \sigma _2^2 + 2\rho {\sigma _1}{\sigma _2}} \right)$
最后,两个相互独立的高斯变量的乘积,仍然为高斯分布,均值和方差如下:
$\left. {\begin{array}{*{20}{c}}
{{X_1}\sim N({\mu _1},\sigma _1^2)}\\
{{X_2}\sim N({\mu _2},\sigma _2^2)}
\end{array}} \right\} \Rightarrow p({X_1}) \cdot p({X_2})\sim N\left( {\frac{{\sigma _2^2}}{{\sigma _1^2 + \sigma _2^2}}{\mu _1} + \frac{{\sigma _1^2}}{{\sigma _1^2 + \sigma _2^2}}{\mu _2},\quad \frac{{\sigma _1^2\sigma _2^2}}{{\sigma _1^2 + \sigma _2^2}}} \right)$
正因为高斯分布有这些特点,所以,在Bayes滤波公式中的随机变量的加法、乘法,可以用解析的公式计算均值和方差,这使得Bayes滤波的整个计算过程非常简便,即Kalman滤波器的迭代过程。
二. Kalman滤波
2.1 Kalman滤波的模型假设
Kalman滤波所解决的问题,是对一个动态变化的系统的状态跟踪的问题,基本的模型假设包括:1)系统的状态方程是线性的;2)观测方程是线性的;3)过程噪声符合零均值高斯分布;4)观测噪声符合零均值高斯分布;从而,一直在线性变化的空间中操作高斯分布,状态的概率密度符合高斯分布。
- 状态方程
${x_t} = {A_t}{x_{t - 1}} + {B_t}{u_t} + {\varepsilon _t}$ - 观测方程
${z_t} = {H_t}{x_t} + {\delta _t}$
其中过程噪声${\varepsilon _t}$假设符合零均值高斯分布;观测噪声${\delta _t}$假设符合零均值高斯分布。对于上述模型,我们可以用如下参数描述整个问题:
2.2 Kalman滤波器的模型
- $x_t$,$n$维向量,表示$t$时刻观测状态的均值。
- $P_t$,$n*n$方差矩阵,表示$t$时刻被观测的$n$个状态的方差。
- $u_t$,$l$维向量,表示$t$时刻的输入
- $z_t$,$m$维向量,表示$t$时刻的观测
- ${A_t}$,$n*n$矩阵,表示状态从$t-1$到$t$在没有输入影响时转移方式
- ${B_t}$,$n*n$矩阵,表示$u_t$如何影响$x_t$
- ${H_t}$,$m*n$矩阵,表示状态$x_t$如何被转换为观测$z_t$
- ${R_t}$,$n*n$矩阵,表示过程噪声${\varepsilon _t}$的方差矩阵
- $Q_t$,$m*m$矩阵,表示观测噪声${\delta _t}$的方差矩阵
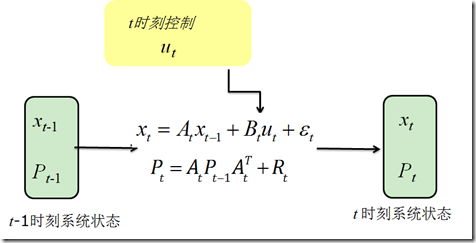
图1.在没有观测情况下,系统状态的从$t-1$到$t$的转移方式
{kind=link}
图1给出了在没有观测,仅有输入$u_t$时,状态变量的均值和方差从$t-1$到$t$的转移方式,可见均值和方差的计算,完全是基于高斯分布的线性变化的方法来算的。
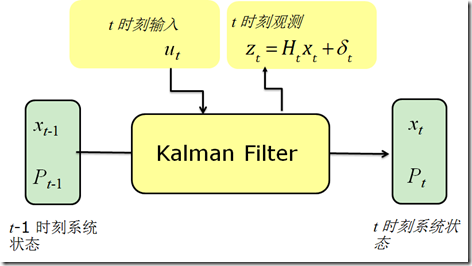
图2. Kalman 滤波解决在收到t时刻的输入$u_t$和观测$z_t$的情况下,更新状态$x_t$的问题
图2给出了Kalman滤波所解决的问题,即在获得t时刻的输入和观测的情况下,如何更新$x_t$的均值和方差的问题。当然$u_t$和$z_t$也并不是每一个时刻都需要同时获得,就像贝叶斯滤波一样,可以在获得$u_t$时就做一次状态预测,在获得$z_t$时做一次状态更新。
2.3 Kalman滤波算法
Kalman滤波整体算法如下:
|
Kalman Filter ($x_{t-1}, P_{t-1}, u_t, z_t$)
|
- 第一行基于转移矩阵和控制输入,预测$t$时刻的状态
- 第二行是预测方差矩阵
- 第三行计算Kalman增益,Kt
- 第四行基于观测的新息进行状态更新
- 第五行计算更新状态的方差矩阵。
可以看到算法的所有的精妙之处都在于第三行和第四行。我们可以这样来理解:
- $({H_t}{\overline P _t}H_t^T + {Q_t})$代表对状态进行观测时,观测的不确定程度,它与Kalman增益Kt成反比,表示观测的可能噪声越大的时候,Kalman增益Kt越小。
- 再看第四行,${x_t}$的更新是在$\overline x_t$上加一个 $K_t$ 乘以 $({z_t} - {H_t}{\overline x _t})$。$({z_t} - {H_t}{\overline x _t})$代表的是预测的值与观测之间的差异,这个差异当预测和观测都比较接近于真实值时比较小。当观测不准,或者预测不准时都会比较大。而前面的乘子Kt是在观测噪声大的时候比较小,所以整个${K_t}({z_t} - {H_t}{\overline x _t})$这个修正量,表示利用观测对预测结果的修正量。
- 当观测噪声比较小,预测误差比较大时修正幅度比较大
- 当观测噪声比较小预测误差比较小的时候,或者观测噪声比较大的时候,修正误差的幅度也比较小,从而起到了一种平滑的作用。
- 利用较准确的观测修正预测误差,不准确的观测修正量也较小,所以在误差较大的时候能快速修正,而在误差较小时能逐渐收敛。
2.4 Kalman滤波算法的推导
这里我们用Bayes公式,给出Kalman Filter是如何导出的。
1. 系统的初始状态是:
$bel({x_0}) = N\left( {{\mu _0},{P_0}} \right)$
2. 预测过程的推导
状态转移模型是线性函数
${x_t} = {A_t}{x_{t - 1}} + {B_t}{u_t} + {\varepsilon _t}$
所以,由$x_{t-1}$到$x_{t}$状态转移的条件概率为:
$p({x_t}|{u_t},{x_{t - 1}}) = N\left( {{A_t}{x_{t - 1}} + {B_t}{u_t},{R_t}} \right)$
回顾Bayes公式,计算预测状态的分布,需要考虑所有可能的$x_{t-1}$:
$\overline {bel} ({x_t}) = \int {p({x_t}|{u_t},{x_{t - 1}})} {\rm{ }}bel({x_{t - 1}})\;d{x_{t - 1}}$
这正是计算两个高斯分布的卷积的过程,参考文献[2]:
$\begin{array}{l}
\overline {bel} ({x_t}) = \int {p({x_t}|{u_t},{x_{t - 1}})} \quad \;\;\quad \quad \quad \quad bel({x_{t - 1}})\;d{x_{t - 1}}\\
\quad \quad \quad \quad \quad \quad \Downarrow \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \Downarrow \\
\quad \quad \quad \sim N\left( {{A_t}{\mu _{t - 1}} + {B_t}{u_t},{R_t}} \right)\quad \quad \sim N\left( {{\mu _{t - 1}},{P_{t - 1}}} \right)\\
\quad \quad \quad \quad \quad \quad \Downarrow \quad \quad \quad \quad \quad \quad \quad \\
\overline {bel} ({x_t}) = \eta \;\int {\exp \left\{ { - \frac{1}{2}{{({x_t} - {A_t}{x_{t - 1}} - {B_t}{u_t})}^T}R_t^{ - 1}({x_t} - {A_t}{x_{t - 1}} - {B_t}{u_t})} \right\}} \\
\quad \quad \quad \quad \;\quad \exp \left\{ { - \frac{1}{2}{{({x_{t - 1}} - {\mu _{t - 1}})}^T}P_{t - 1}^{ - 1}({x_{t - 1}} - {\mu _{t - 1}})} \right\}\;d{x_{t - 1}}\\
\overline {bel} ({x_t}) = \left\{ {\begin{array}{*{20}{c}}
{{{\bar \mu }_t} = {A_t}{\mu _{t - 1}} + {B_t}{u_t}}\\
{{{\overline P }_t} = {A_t}{P_{t - 1}}A_t^T + {R_t}}
\end{array}} \right.\quad \quad \quad \quad \quad \quad \quad
\end{array}$
所以Kalman滤波器的预测过程,正是基于两个高斯分布的卷积计算得到的解析表达式。
3. 观测更新过程的推导
观测方程也是线性方程,并且噪声是高斯噪声
${z_t} = {H_t}{x_t} + {\delta _t}$
所以$p({z_t}|{x_t}) $的条件概率是高斯分布的线性变换计算:
$p({z_t}|{x_t}) = N\left( {{H_t}{x_t},{Q_t}} \right)$
再考虑贝叶斯公式的状态更新步骤
$bel({x_t}) = \,\quad \eta \quad \,p({z_t}|{x_t})\overline {bel} ({x_t})$
这正是两个高斯分布的乘积的问题,参考文献[2]
$\begin{array}{l}
bel({x_t}) = \,\quad \eta \quad \,p({z_t}|{x_t})\quad \quad \quad \quad \quad \quad \overline {bel} ({x_t})\\
\quad \quad \quad \quad \quad \quad \quad \quad \Downarrow \quad \quad \quad \quad \quad \quad \quad \quad \Downarrow \\
\quad \quad \quad \quad \quad \sim N\left( {{z_t};{H_t}{x_t},{Q_t}} \right)\quad \quad \sim N\left( {{x_t};{{\overline \mu }_t},{{\overline P }_t}} \right)\\
\quad \quad \quad \quad \quad \quad \quad \quad \Downarrow \\
bel({x_t}) = \eta \;\exp \left\{ { - \frac{1}{2}{{({z_t} - {H_t}{x_t})}^T}Q_t^{ - 1}({z_t} - {H_t}{x_t})} \right\}\exp \left\{ { - \frac{1}{2}{{({x_t} - {{\bar \mu }_t})}^T}\bar P_t^{ - 1}({x_t} - {{\bar \mu }_t})} \right\}\\
\end{array}$
所以,基于求高斯变量乘积的分布的方法,可以导出结果仍然是高斯分布,用它的二阶矩表示:
$bel({x_t}) = \left\{ {\begin{array}{*{20}{c}}
{{\mu _t} = {{\bar \mu }_t} + {K_t}({z_t} - {H_t}{{\bar \mu }_t})}\\
{{P_t} = (I - {K_t}{H_t}){{\overline P }_t}}
\end{array}} \right.\quad \quad {\rm{with }}{K_t} = {\overline P _t}H_t^T{({H_t}{\overline P _t}H_t^T + {Q_t})^{ - 1}}$
所以状态更新中的Kalman增益,均值和方差的更新公式,都是这样导出的。
2.5 Kalman滤波算法的举例
图3和图4通过一维高斯分布的例子,给出在预测和更新过程中状态变量的概率密度分布是如何变化的。
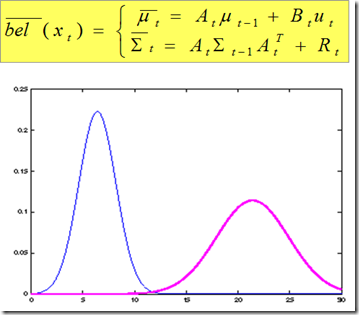
图3.预测过程的举例,蓝色曲线表示$x_{t-1}$的pdf,紫色曲线表示$\overline x_t$的pdf.
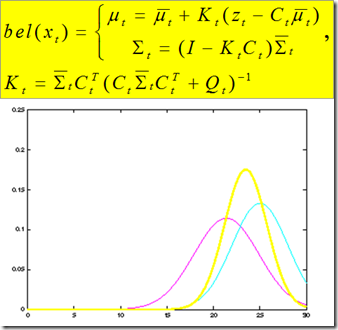
图4.更新过程举例,紫色为预测后的pdf, 黄色为更新后的pdf,青色为观测的结果
从这个例子中可以值得注意的是,在预测部分高斯分布的卷积一般会使状态估计的方差加大;在观测部分高斯分布的乘积一般会将估计的方差收窄。
2.6 Kalman滤波的代码实现
Kalman滤波算法可以非常方便的用矩阵计算方法实现,其迭代更新过程的Matlab实现的代码仅有如下几行:

2.7 Kalman滤波的效果示例
通过实现一个简单的Kalman滤波器,我们可以直观的看一下Kalman滤波器的提高跟踪准确性的效果。
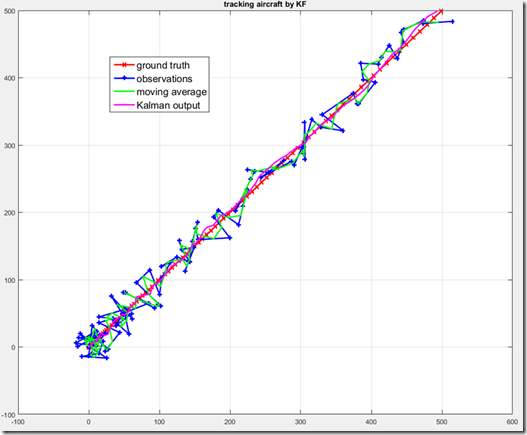
图5. Kalman滤波器的实验效果示例,其中红色实线是真值;蓝色点是观测;绿色线是滑动平均的结果;紫色曲线是Kalman滤波的结果。
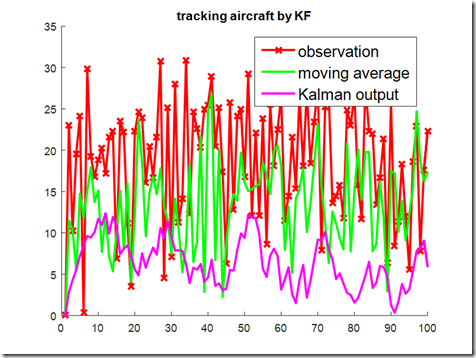
图6. 比较Kalman滤波的跟踪结果和滑动平均的跟踪结果
图6给出了直观的跟踪结果与真实值之间的最小二乘误差的比较,课件Kalman滤波算法相比滑动平均等,提供了更高的跟踪准确性。
2.8 Kalman滤波的算法特点
- Kalman滤波计算快速,计算复杂度为$O(m^{2.376} + n^2)$,其中$m$是观测的维数;$n$是状态的个数。
- 对于线性系统,零均值高斯噪声的系统,Kalman是理论上无偏的,最优滤波器。
- Kalman滤波在实际使用中,要注意参数$R$和$Q$的调节,这两者实际上是相对的,表示更相信观测还是更相信预测。具体使用时,$R$可以根据过程噪声的幅度决定,然后$Q$可以相对$R$来给定。当更相信观测时,把$Q$调小,不相信观测时,把$Q$调大。
- $Q$越大,表示越不相信观测,这是系统状态越容易收敛,对观测的变化响应越慢。$Q$越小,表示越相信观测,这时对观测的变化响应快,但是越不容易收敛。
参考文献
[1]. Sebastian Thrun, Wolfram Burgard, Dieter Fox, Probabilistic Robotics, 2002, The MIT Press.
[2]. P.A. Bromiley, Products and Convolutions of Gaussian Probability Density Functions, University of Manchester
(二). 细说Kalman滤波:The Kalman Filter的更多相关文章
- kalman滤波
kalman滤波原理(通俗易懂) 1. 在学习卡尔曼滤波器之前,首先看看为什么叫“卡尔曼”.跟其他著名的理论(例如傅立叶变换,泰勒级数等等)一样,卡尔曼也是一个人的名字,而跟他们不同的是,他是个现代人 ...
- 【滤波】标量Kalman滤波的过程分析和证明及C实现
摘要: 标量Kalman滤波的过程分析和证明及C实现,希望能够帮助入门的小白,同时得到各位高手的指教.并不涉及其他Kalman滤波方法. 本文主要参考自<A Introduction to th ...
- 理解Kalman滤波的使用
Kalman滤波简介 Kalman滤波是一种线性滤波与预测方法,原文为:A New Approach to Linear Filtering and Prediction Problems.文章推导很 ...
- 学习OpenCV——Kalman滤波
背景: 卡尔曼滤波是一种高效率的递归滤波器(自回归滤波器), 它能够从一系列的不完全及包含噪声的测量中,估计动态系统的状态.卡尔曼滤波的一个典型实例是从一组有限的,包含噪声的,对物体位置的观察序列(可 ...
- 透过表象看本质!?之三——Kalman滤波
数据拟合能够估计出数据变化的趋势,另外一个同等重要的应用是如何利用这一趋势,预测下一时刻数据可能的值.通俗点儿说,你观察苍蝇(蚊子,蜜蜂)飞了几秒,你也许会想“它下一个时刻可能在哪儿”,“呈现出什么样 ...
- 终于理解kalman滤波
2017拜拜啦,怎么过元旦呢?当然是果断呆实验室过... 应该是大二的时候首次听说kalman,一直到今天早上,我一看到其5条"黄金公式",就会找各种理由放弃,看不懂呀...但是研 ...
- 目标跟踪之卡尔曼滤波---理解Kalman滤波的使用预测
Kalman滤波简介 Kalman滤波是一种线性滤波与预测方法,原文为:A New Approach to Linear Filtering and Prediction Problems.文章推导很 ...
- kalman 滤波 演示与opencv代码
在机器视觉中追踪时常会用到预测算法,kalman是你一定知道的.它可以用来预测各种状态,比如说位置,速度等.关于它的理论有很多很好的文献可以参考.opencv给出了kalman filter的一个实现 ...
- 【转】kalman滤波
Kalman Filter是一个高效的递归滤波器,它可以实现从一系列的噪声测量中,估 计动态系统的状态.广泛应用于包含Radar.计算机视觉在内的等工程应用领域,在控制理论和控制系统工程中也是一个非常 ...
随机推荐
- bzoj1382: [Baltic2001]Mars Maps
Description 给出N个矩形,N<=10000.其坐标不超过10^9.求其面积并 Input 先给出一个数字N,代表有N个矩形. 接下来N行,每行四个数,代表矩形的坐标. Output ...
- NOIP第7场模拟赛题解
NOIP模拟赛第7场题解: 题解见:http://www.cqoi.net:2012/JudgeOnline/problemset.php?page=13 题号为2221-2224. 1.car 边界 ...
- SVN代码回滚命令之---merge的使用
一.改动还没被提交的情况(未commit) 这种情况下,见有的人的做法是删除work copy中文件,然后重新update,恩,这种做法达到了目的,但不优雅,因为这种事没必要麻烦服务端. 其实一个命令 ...
- 黄聪:wordpress如何添加自定义文章快速编辑按钮
When working with WordPress posts and you want to quickly change the status or date of one or more p ...
- ARM7+PROTEUS调试(转)
网上说ARM7调试产生的.axf文件不能直接放在PROTEUS中调试,方法:将.axf文件复制一份修改后缀名为.elf文件加载即可:hex文件删除倒数(用编辑器)第二行后保存即可加载
- ylbtech-Unitity-CS:Indexers
ylbtech-Unitity-CS:Indexers 1.A,效果图返回顶部 1.B,源代码返回顶部 1.B.1, // indexer.cs // 参数:indexer.txt using S ...
- 监控和管理Cassandra
了解Cassandra集群的性能特点有助于诊断和维护Cassandra.由于Cassandra使用JAVA开发的,所以它就提供了JMX环境下的一些管理工具来管理Cassandra,它们包括:Cassa ...
- iOS 审核加急通道使用--转载来源--有梦想的蜗牛
提交完成后进入加急审核页面. 链接:https://developer.apple.com/appstore/contact/appreviewteam/index.html 在i would lik ...
- js实现加减乘除
/** ** 除法函数,用来得到精确的除法结果 ** 说明:javascript的除法结果会有误差,在两个浮点数相除的时候会比较明显.这个函数返回较为精确的除法结果. ** 调用:accDiv(arg ...
- Perl中文/unicode/utf8/GB2312之间的转换
参考:http://daimajishu.iteye.com/blog/959239不过具测试,也有错误:原文如下: # author: jiangyujieuse utf8; ##在最后一个例子, ...