Hadoop MapReduce概念学习系列之mr程序组件全貌(二十)
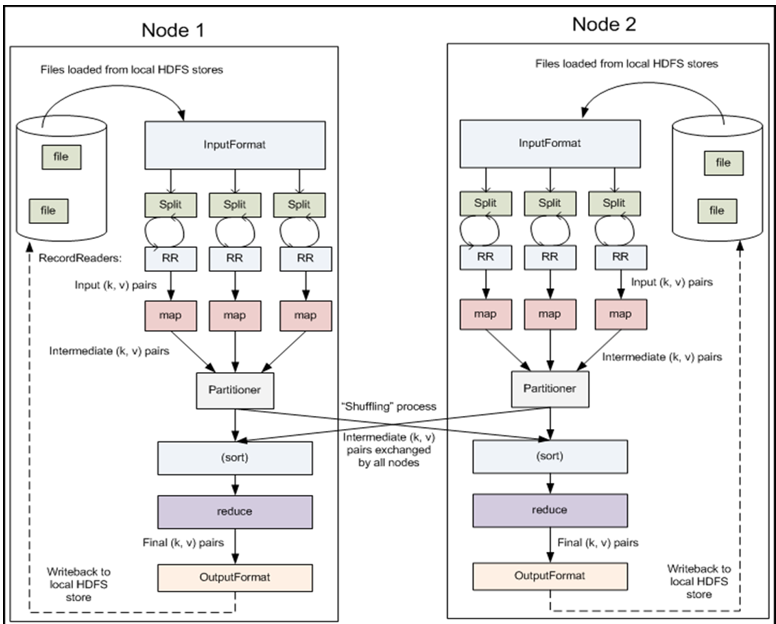
其实啊,spilt是,控制Apache Hadoop Mapreduce的map并发任务数,详细见http://www.cnblogs.com/zlslch/p/5713652.html
map,是mapper代码
partitioner,自定义分组,详细见http://www.cnblogs.com/zlslch/p/5713701.html
sort,自定义排序,详细见http://www.cnblogs.com/zlslch/p/5713701.html
reduce,是reducer代码
缓存,分组,排序,转发,这些都是mr的shuffle。 详细见http://www.cnblogs.com/zlslch/p/5713701.html
最重要的是,mr程序的组件InputFormat和OutputFormat啊!(重要的话,说三遍)
最重要的是,mr程序的组件InputFormat和OutputFormat啊!
最重要的是,mr程序的组件InputFormat和OutputFormat啊!

我们知道,在大数据里,数据源是非常之广,比如,hdfs(默认,而且还是TextInputFormat),数据库,文件,ftp,网页,网络端口.....
那么,对于用户来说,不需要具体去管,特推出mr程序的组件-------InputFormat

往数据库、HBase、ftp、hdfs(默认是往hdfs写,而且还是TextOutputFormat),文件,,,用户不用管,特推出mr程序的组件------OutputFormat
But,在生产环境,可是最重要的是具体业务...
注意:
比如,对于图片,视频,,,这些,InputFormat,就不能了。

可以看到,DBInputFormat是去数据库里读,

可以看到,DBOutputFormat是往数据库里写,
其它更深以后会补上
Hadoop MapReduce概念学习系列之mr程序组件全貌(二十)的更多相关文章
- Hadoop MapReduce概念学习系列之mr程序详谈(二十三)
这个暂时,没写好. K1,v1 这是增强的for循环. for(Sting w : words) { } 迭代器里,前面,放的是什么类型,后面,迭代的是谁.
- Hadoop MapReduce概念学习系列之mr的Shuffle(二十二)
Shuffle是非常非常非常重要.搞mr,必须熟烂于心. 因为,分区,分组,排序,,,都是在Shuffle里完成.
- Hadoop HDFS概念学习系列之分布式文件管理系统(二十五)
数据量越来越多,在一个操作系统管辖的范围存在不了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来 管理多台机器上的文件,这就是分布式文件管理系统. 是一种允许文件 ...
- Hadoop MapReduce概念学习系列之shuffle大揭秘(十九)
shuffle是非常重要!一定要深入理解和多实践. 缓存,分组,排序,转发,这些都是mr的shuffle. Soga 我想得到按流量来排序,而且还是倒序,怎么达到实现呢?这就牵扯到排序的的问题 默认是 ...
- Hadoop MapReduce概念学习系列之map并发任务数和reduce并发任务数的原理和代码实现(十八)
首先,来说的是,reduce并发任务数,默认是1. 即,在jps后,出现一个yarnchild.之后又消失. 这里,我控制reduce并发任务数6 有多少个reduce的并发任务数可以控制,但有多少个 ...
- Hadoop MapReduce概念学习系列之JobTracker、ResourceManager、Task Tracker、NodeManager(二十一)
Tracker是跟踪者,跟踪器.JobTracker是项目经理.在hadoop2*的0.23版本之后,改叫RM了.ResourceManager.TaskTracker是小组长.它手下,还有具体搬砖的 ...
- Hadoop HBase概念学习系列之优秀行键设计(十六)
我们通过行键访问HBase.尽管使用扫描过滤器可以一次性指明大量的键,但是HBase仅仅能够根据行键识别出一行. 优秀的行键设计可以保证良好的HBase性能. 1.行键存在于HBase中的每一个单元格 ...
- Hadoop HBase概念学习系列之HBase里的HStore(十九)
Store在HBase里称为HStore.HStore包括MemStore和StoreFiles.
- Hadoop HBase概念学习系列之列、列簇(十二)
列在列簇中依照字典排序.例如,列簇是基础信息或公司域名或水果类.列是基础信息:面貌.基础信息:年龄.公司域名:org.公司域名:edu.水果类:苹果.水果类:香蕉. 列 = 列簇:列修饰符 ...
随机推荐
- hdu4003Find Metal Mineral(树形DP)
4003 思维啊 dp[i][j]表示当前I节点停留了j个机器人 那么它与父亲的关系就有了 那条边就走了j遍 dp[i][j] = min(dp[i][j],dp[child][g]+dp[i][j- ...
- c#开源Excel操作库--NPOI
前言 以前也用C#操作过excel,用的是OleDb或者offic的com组件,但是总是非常的麻烦,依赖限制较多,所以果断寻找开源方案,JAVA上面已经有非常成熟的POI,就这样,找到了移.Net的移 ...
- [ionic开源项目教程] - 第12讲 医疗模块的实现以及Service层loadMore和doRefresh的提取封装
关注微信订阅号:TongeBlog,可查看[ionic开源项目]全套教程. 这一讲主要实现tab2[医疗]模块,[医疗]模块跟tab1[健康]模块类似. [ionic开源项目教程] - 第12讲 医疗 ...
- request.getRequestDispatcher()和response.sendRedirect()
request.getRequestDispatcher("/homeMainAction_mainUI.do").forward(getRequest(), getRespons ...
- BZOJ 4551 树
线段树+标记永久化. #include<iostream> #include<cstdio> #include<cstring> #include<algor ...
- php多种实例理解无限极分类
- 修改Chrome默认搜索引擎为Google.com
在使用Chrome的时候,Google为增强本地化搜索,或将默认的Google搜索引擎转换为本地语言,如在中国会自动转到google.com.hk,日本会会自动转到google.co.jp,如果你是一 ...
- 【转】使用Python的IDE:Eclipse+PyDev
原文网址:http://www.crifan.com/try_with_python_ide_eclipse_pydev/ 之前已经介绍过了一些基本知识: [整理][多图详解]如何在Windows下开 ...
- Excel2007条件格式怎么用
Excel2007的条件格式功能十分的强大实用,较2003版改进十分的大,下面我们以经验记录为例做一简单的操作示范.注意前部分有二点技巧可借鉴,即不规则选取和不规则统一填充. 工具/原料 EXCEL2 ...
- hdu 4381(背包变形)
题意: 给定n个块,编号从1到n,以及m个操作,初始时n个块是白色. 操作有2种形式: 1 ai xi : 从[1,ai]选xi个块,将这些块涂白. 2 ai xi:从[ai,n]选xi个块,将这些块 ...