PostgreSQL执行计划:Bitmap scan VS index only scan
之前了解过postgresql的Bitmap scan,只是粗略地了解到是通过标记数据页面来实现数据检索的,执行计划中的的Bitmap scan一些细节并不十分清楚。这里借助一个执行计划来分析bitmap scan以及index only scan,以及两者的一些区别。
这里有关于Bitmap scan的一些实现过程,https://dba.stackexchange.com/questions/119386/understanding-bitmap-heap-scan-and-bitmap-index-scan0. 构建测试环境
如下测试脚本,构建一个简单的测试表
create table my_test_table01
(
c1 serial not null primary key,
c2 varchar(100),
c3 timestamp
)
--c3字段上建索引
create index ix_c3 on my_test_table01(c3); truncate table my_test_table01; --写入300W行测试数据,c3列生成随机时间
insert into my_test_table01 (c2,c3)
select uuid_generate_v1(),NOW() - (random() * (NOW()+'1000 days' - NOW())) from generate_series(1,3000000);
1. Bitmap Scan的剖析
用最最容易理解的场景来测试Bitmap Index Scan,执行如下sql,来分析bitma scan这个执行计划的含义。
explain (analyze, buffers,verbose,timing)
select count(1) from my_test_table01 a
where a.c3 >'20220328' or a.c1 < 100;
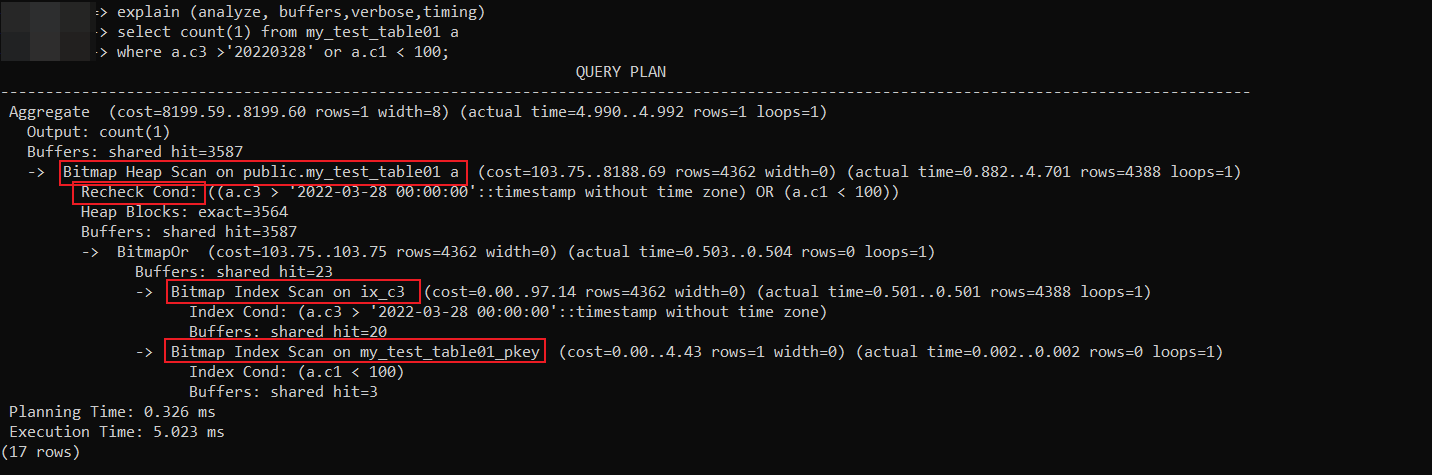
对以上的执行计划,有几个问题先弄清楚:
1,Bitmap Index Scan做了什么?
2,Bitmap Heap Scan做了什么?
3,Recheck Cond的目的是什么?
第一个问题:Bitmap Index Scan做了什么?
一个查询条件的Bitmap是一个bit数组,bit数组中的每一位映射到表中的一个数据页Id(One bit per heap page, in the same order as the heap)。
Bitmap Index Scan对于所有的查询条件,从扫描索引的所有页面,如果数据页面中有复合条件的数据,那么就将bit为标记为1,否则标记为0。
其他的查询条件依次创建一个一样的bit数组,同样扫描索引的所有页面,将符合条件的page的bit位标记为1。
最后多个条件生成的多个bit数组进行与(或)操作(取决于where多个条件是and组合或者or组合,上面截图中的BitmapOr),合并成一个最终的bit数组。
此时最终的bit数组标记的复合条件的数据页,而不是最终的数据行,所以最终还要去数据页中进行筛选。
bitmap index scan 内部优化机制:https://www.postgresql.org/message-id/12553.1135634231@sss.pgh.pa.us
第二个问题:Bitmap Heap Scan做了什么
而BitMap Index Scan一次性将满足条件的索引项全部取出,并在内存中进行排序, 然后根据取出的索引项访问表数据,也就是执行计划中的Bitmap Heap Scan。
第三个问题:Recheck Cond的目的是什么
BitMap Heap Scan指示找到符合条件的数据页面,而不是具体的记录,此时找到数据页后再用where条件进行筛选,也就是执行计划中的Recheck Cond。
https://stackoverflow.com/questions/50959814/what-does-recheck-cond-in-explain-result-mean
If the bitmap gets too large we convert it to "lossy" style, in which we only remember which pages contain matching tuples instead of remembering each tuple individually. When that happens, the table-visiting phase has to examine each tuple on the page and recheck the scan condition to see which tuples to return.
bitmap scan示例图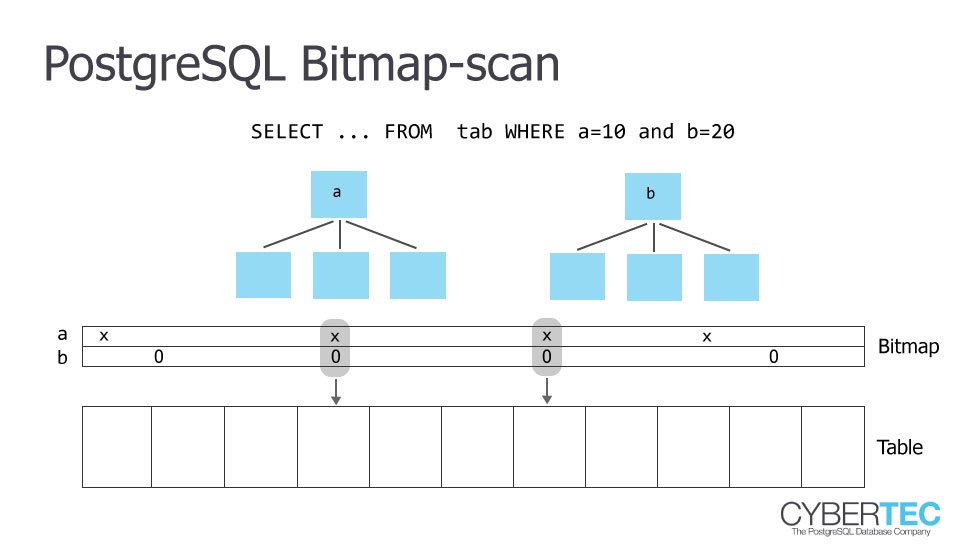
图片来源:https://www.cybertec-postgresql.com/en/postgresql-indexing-index-scan-vs-bitmap-scan-vs-sequential-scan-basics/bitmap index scan不仅仅发生在where条件中有多个筛选条件的场景(比如where c1 = m and c2 =n),其实对于一个条件的范围查询,也同样适用bitmap index scan,见下例。
2. 为什么执行计划走Bitmap Index Scan,而不是Index only Scan?
对于如下这个查询,表中有300W测试数据符合条件的数据比例很少,很明显,ix_c3上的索引扫描才是更优化的执行计划,为什么在默认情况下是Bitmap Index Scan?
select count(1) from my_test_table01 a
where a.c3 >'20220328' ;
从如下截图可以看到,vacuum是打开的,在造完测试数据后,默认情况下上述sql查询走了bitmap Index scan,因为c3上有索引,预期是走ix_c3上的索引。
原本以为vacuum是异步的,或者说有滞后性,但是这个case在测试数据构造完之后几个小时甚至几天,该查询都依旧走bitmap Index scan的方式。
当关闭enable_bitmapscan和enable_seqscan,强制优化器走ix_c3上的index only scan,代价明显更大,这就有点说不通了,原因下文会具体分析。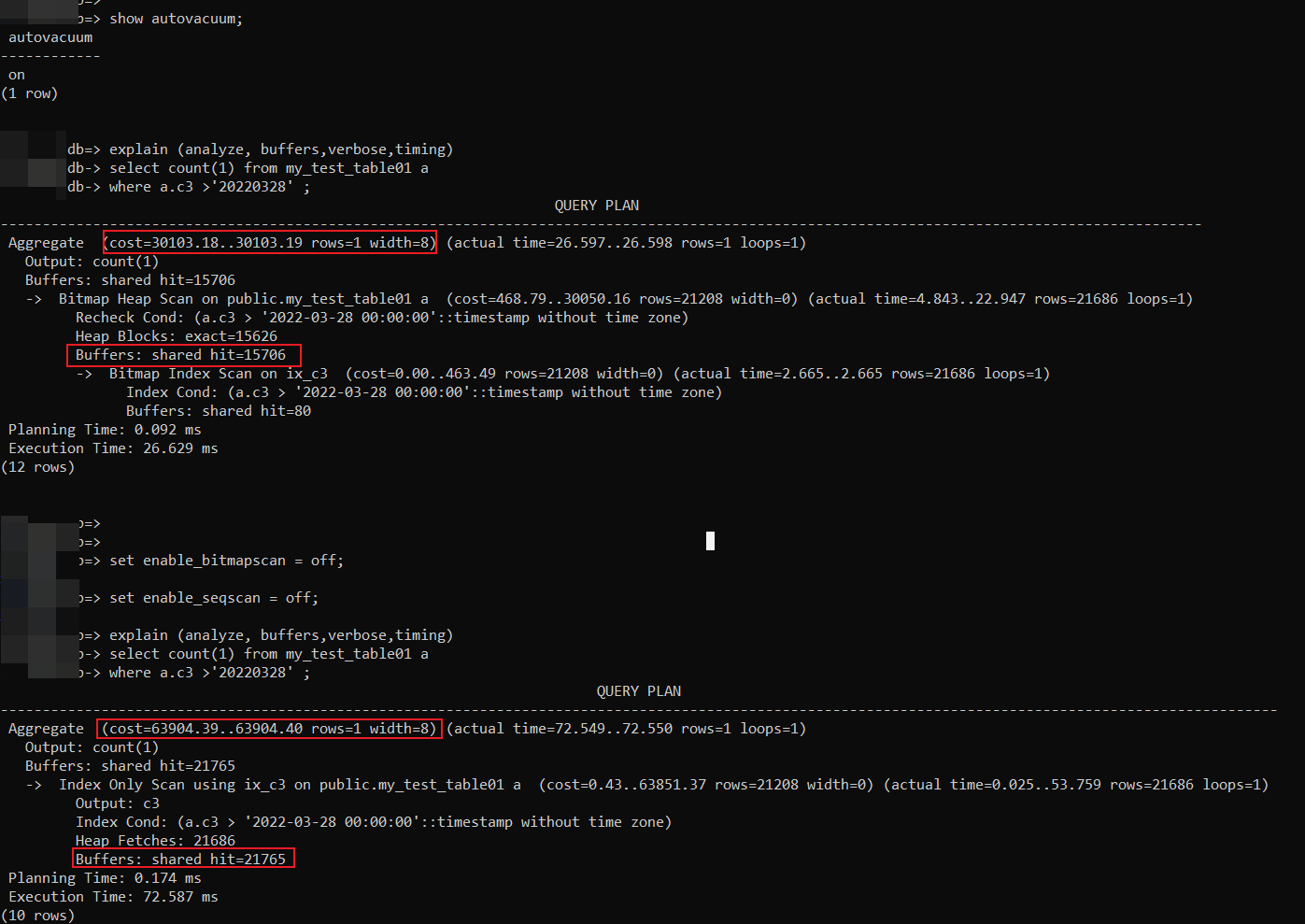
本人对该现象一开始也是百思不得其解,难道是bitmap scan有什么魔法?
看到这里有一个提到这个问题:https://www.datadoghq.com/blog/postgresql-vacuum-monitoring/,里面相关的内容的是这么说的:
1. Large insert-only tables. Large insert-only tables are not automatically vacuumed (except for transaction-ID wraparound), because autovacuum is triggered by updates and deletes. This is generally a good thing, because it saves a great deal of not-very-useful work. However, it's problematic for index-only scans, because it also means the visibility map bits won't get set. I don't have a very clear idea what to do about this, but it's likely to need thought and work. For a first version of this feature, we'll likely have to rely on users to do a manual VACUUM in this case.
既然这种场景无法主从出发vacuum,那么这里就手动vacuum测试表,然后打开bitmap scan选项,继续观察此时的默认情况下,该查询是不是可以走index only scan,这一次终于是预期的ix_c3上的index only scan了。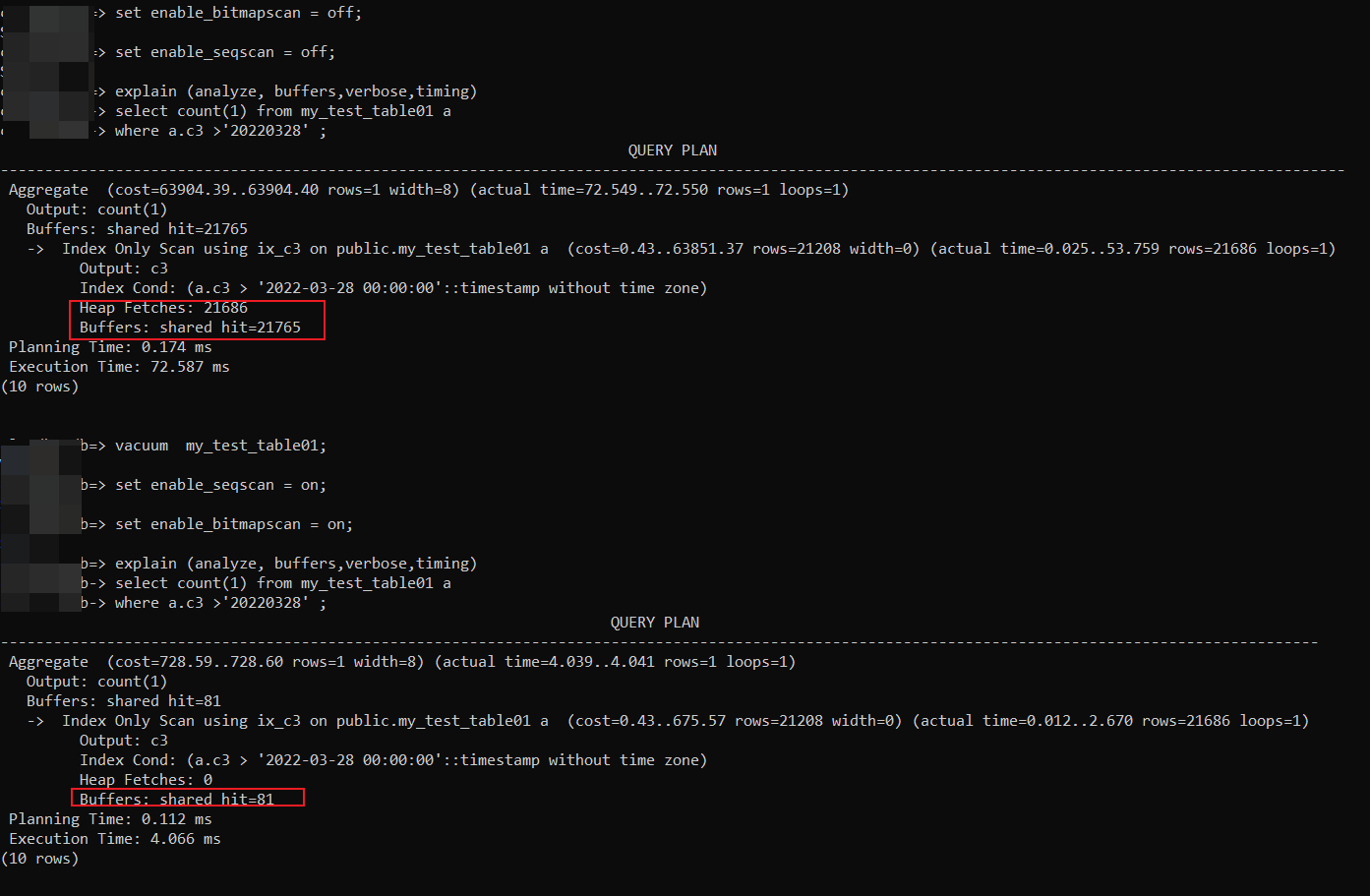
同时还有一个疑问:对表执行vacuum前后,index only scan的shared hit差别这么大?
上述得知在large-insert的情况下,不会触发表上的vacuum,此时如果强制使用index only scan,因为索引上的没有数据行的可见性信息(Index Only Scan operation must visit the heap to check if the row is visible.)所以在vacuum之前,强制使用index only scan的过程中,对于任何一行数据都要回表进行可见性判断,因此会产生大量的shared hit。一旦vacuum之后,由于索引上更新了数据行的可见性,不需要回表判断,因此shared hit会大幅度地降低。
3. 主动触发vacuum.
Large insert-only tables are not automatically vacuumed,也就是大批量的插入无法主动发出vacuum,vacuum由update和delete产生,那么尝试对表执行一些update或者delete操作,会不会主动触发vacuum?
基于第一步的脚本,重新初始化测试表,在插入300W行数据后,删除其中一部分数据,目前是让delete操作触发vacuum,然后再通过执行计划,观察是否会想手动vacuum一样,走index only scan。
经过三次删除,完美触发vacuum,执行计划有一开始bitmap scan更新为index only scan。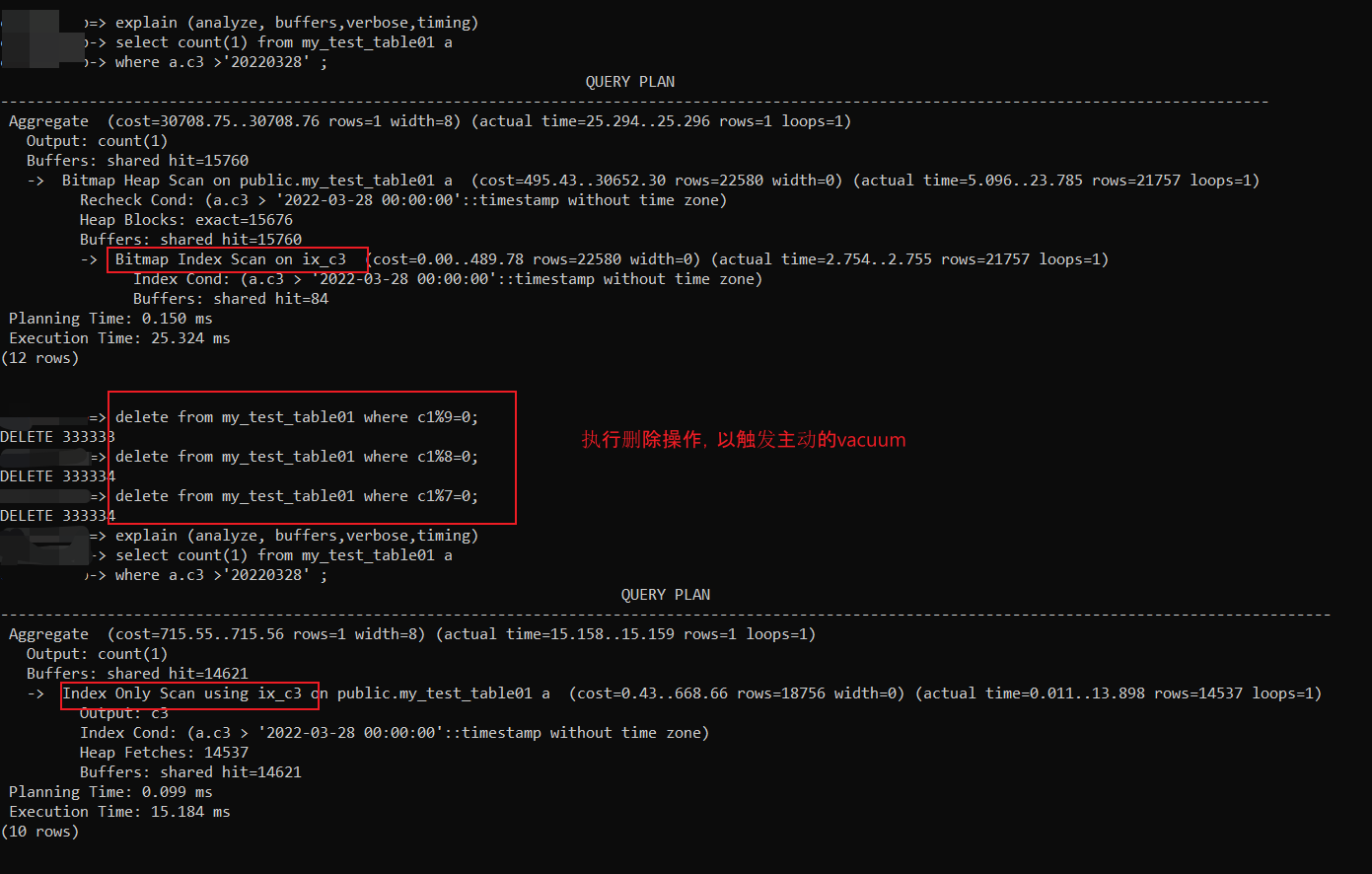
4. bitmp index scan VS index-only scan
参考这里https://www.cybertec-postgresql.com/en/killed-index-tuples/ 对 bitmap index scan 和 index-only scan的解释
PostgreSQL 8.1 introduced the “bitmp index scan”. This scan method first creates a list of heap blocks to visit and then scans them sequentially.
This not only reduces the random I/O, but also avoids that the same block is visited several times during an index scan. PostgreSQL 9.2 introduced the “index-only scan”, which avoids fetching the heap tuple.
This requires that all the required columns are in the index and the “visibility map” shows that all tuples in the table block are visible to everybody.
bitmp index scan不仅可以避免随机的IO操作,而且可以避免同一个页面(在一个查询执行过程中)被重复读取(一个页面中可能存在多条满足查询条件的元组,其他方式可能会多次读取同一个页面)。
index-only scan避免了从堆中读取数据,但是他要求所有请求的字段都在索引中,并且“visibility map” 中显示表块中的所有元组对所有事物都是可见的,但是索引中并不包含元组的可见性。
本文通过一个看似不起眼的问题sql执行计划的分析,尝试分析bitmap scan 和index only scan的差异以及选择二者的原因,同时会涉index索引元组的可见性及vacuum没有触发的一些特殊场景。一个问题往往不是一个点,是一系列问题的合集,此事要躬行。
参考链接:
PostgreSQL执行计划:Bitmap scan VS index only scan的更多相关文章
- 深入理解Oracle索引(1):INDEX SKIP SCAN 和 INDEX RANGE SCAN
㈠ Index SKIP SCAN 当表有一个复合索引,而在查询中有除了索引中第一列的其他列作为条件,并且优化器模式为CBO,这时候查询计划就有可能使用到SS ...
- PostgreSQL 执行计划
简介 PostgreSQL是“世界上最先进的开源关系型数据库”.因为出现较晚,所以客户人群基数较MySQL少,但是发展势头很猛,最大优势是完全开源. MySQL是“世界上最流行的开源关系型数据库”.当 ...
- PostgreSQL执行计划的解析
一个顺序磁盘页面操作的cost值由系统参数seq_page_cost (floating point)参数指定的,由于这个参数默认为1.0,所以我们可以认为一次顺序磁盘页面操作的cost值为1.下面o ...
- postgreSQL执行计划
" class="wiz-editor-body wiz-readonly" contenteditable="false"> explain命 ...
- INDEX FAST FULL SCAN和INDEX FULL SCAN
INDEX FULL SCAN 索引全扫描.单块读 .它扫描的结果是有序的,因为索引是有序的.它通常发生在 下面几种情况(注意:即使SQL满足以下情况 不一定会走索引全扫描) 1. SQL语句有ord ...
- index unique scan 与index range scan等的区别
存取Oracle当中扫描数据的方法(一) Oracle 是一个面向Internet计算环境的数据库.它是在数据库领域一直处于领先地位的甲骨文公司的产品.可以说Oracle关系数据库系统是目前世界上流行 ...
- oralce索引中INDEX SKIP SCAN 和 INDEX RANGE SCAN区别
INDEX SKIP SCAN 当表中建立有复合索引的时候,查询时,除复合索引第一列外,别的列作为条件时,且优化器模式为CBO,这个时候查询可能会用到INDEX SKIP SCAN skip scan ...
- [20180316]为什么不使用INDEX FULL SCAN (MIN/MAX).txt
[20180316]为什么不使用INDEX FULL SCAN (MIN/MAX).txt --//链接:http://www.itpub.net/thread-2100456-1-1.html.自己 ...
- PostgreSQL 与 Oracle 访问分区表执行计划差异
熟悉Oracle 的DBA都知道,Oracle 访问分区表时,对于没有提供分区条件的,也就是在无法使用分区剪枝情况下,优化器会根据全局的统计信息制定执行计划,该执行计划针对所有分区适用.在分析利弊之前 ...
随机推荐
- laravel 终端命令
创建模块及控制器
- nginx配置负载均衡分发服务器笔记
记录学习搭建nginx负载均衡分发服务器的过程笔记 1.服务器IP:192.168.31.202(当前需要搭建nginx负载均衡分发的服务器)安装好nginx 2.在服务器IP:192.168.31. ...
- Applied Social Network Analysis in Python 相关笔记3
如果是option2的话,答案选A. 这里节点s,从左边的选择,节点t从右边选择. 这里计算还是用以前的值,不用更新过的值.
- js 中的值类型和引用类型
javascript中值类型(基本类型):number,string,bool,undefined,null(这5种基本数据类型是按值访问的,因为可以操作保存在变量中的实际的值) 引用类型:对象(Ob ...
- 5月14日 python学习总结 视图、触发器、事务、存储过程、函数、流程控制、索引
一.视图 1.什么是视图 视图就是通过查询得到一张虚拟表,然后保存下来,下次用的直接使用即可 2.为什么要用视图 如果要频繁使用一张虚拟表,可以不用重复查询 3.如何用视图 create view t ...
- 5月10日 python学习总结 单表查询 和 多表连接查询
一. 单表查询 一 语法 select distinct 查询字段1,查询字段2,... from 表名 where 分组之前的过滤条件 group by 分组依据 having 分组之后的过滤条件 ...
- PCIe Tandem PROM 方法
PCIe Tandem PROM 方法 什么是Tandem PROM? 简单总结:市面多数的FPGA都是SRAM型,需要在上电时从外部存储器件完成代码的加载,对于具有PCIe功能的SRAM FPGA而 ...
- protocol 协议语言介绍
Protocol Buffer是Google提供的一种数据序列化协议,是一种轻便高效的结构化数据存储格式,可以用于结构化数据序列化,很适合做数据存储或 RPC 数据交换格式.它可用于通讯协议.数据存储 ...
- TTL、RS232、RS485、UART、串口的关系和常见半双工、全双工协议
串口(UART口).COM口.USB口.DB9.DB25是指的物理接口形式(硬件) TTL.RS-232.RS-485是指的电平标准(电平信号) 我们单片机嵌入式常用的串口有三种(TTL/RS-2 ...
- 如果你的Serializable类包含一个不可序列化的成员,会发生什么?你是如何解决的?
任何序列化该类的尝试都会因NotSerializableException而失败,但这可以通过在 Java中 为 static 设置瞬态(trancient)变量来轻松解决. Java 序列化相关的常 ...