NLP论文解读:无需模板且高效的语言微调模型(上)
原创作者 | 苏菲
论文题目:
Prompt-free and Efficient Language Model Fine-Tuning
论文作者:
Rabeeh Karimi Mahabadi
论文地址:
https://openreview.net/pdf?id=6o5ZEtqP2g
提示学习(Prompt-learning)被誉为自然语言处理的“第 4 种范式”,它可以在少样本甚至零样本的条件下,通过将下游任务修改为语言生成任务来获得相对较好的模型。
但是,传统的提示学习需要针对下游任务手工设计模板,而且采用自回归的训练预测方法非常耗时。本文提出的PERFECT方法,无需手工设计特定模板,大大降低内存和存储消耗(分别降低了5个百分点和100个百分点)。
在12个NLP任务中,这种微调方法(PERFECT)在简单高效的同时,取得了与SOTA方法(如PET提示学习模型)相近甚至更高的结果。
论文的创新之处在于:
(1)使用特定任务适配器替代手工制作任务提示,提高了微调的采样效率且降低内存及存储消耗;
(2)使用不依赖于模型词汇集的多标记标签向量学习,替代手工编制的语言生成器,可以避免复杂的自回归解码过程。
01 背景介绍
论文作者首先介绍了少样本语言模型微调以及提示学习的问题定义、适配器、基于提示的微调、训练策略、预测策略等,然后再提出论文对这一问题和模型的改进方法。
图1所示的是一个情感分类器(提示学习模型),输入的提示模板为“x It was [MASK]”, 可以替换x为输入文本,通过语言生成器(Verbalizers)把词汇对应到极性标签(‘positive’或者‘negative’),从而获得整个文本的情感类别。
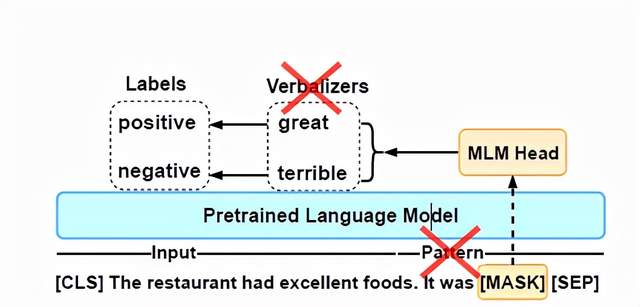
图1
现存的提示学习模型需要手工精心设计提示模板和语言生成器,以便将任务转化为掩码语言模型(MLM)和完形填空格式。这篇论文提出的PERFECT方法不需要任何手工构建工作,且可以去掉提示模板和语言生成器。
1.1问题的定义

论文作者进一步设定验证集与训练集的样本数相同(因为更大的验证集可能更有优势),因此论文作者使用的训练集有16个样本,即N=16,同时使用的验证集也有16个样本,总共是32个样本的少样本学习数据集。
1.2 适配层(Adapters)
在具有超大规模参数的预训练语言模型(PLMs)中,微调语言模型时可以通过加入一个小的特定任务层(称为适配层Adapters),那么在训练语言模型时只需要训练新加入的适配层和归一化层,而语言模型中的其它参数保持不变。
例如在Transformer模型中,其中的每一层主要由一个注意力block和一个前馈block构成,而这两个block后面都会接一个跳跃连接层;通常把适配层插在这些block之后且在跳跃连接层之前(如图2所示),那么在训练时仅仅需要优化图中绿色模块的参数。
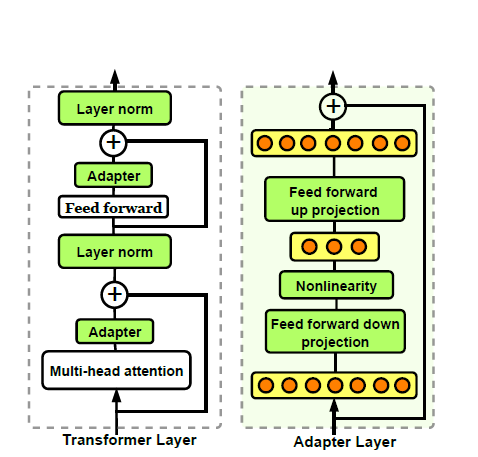
图2
1.3 基于提示的微调
标准的微调:标准的预训练语言模型微调方法是,首先将一个特殊符号[CLS]加入到输入x中,然后模型将其映射到隐藏层中的序列表示
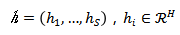

这种标准微调的主要缺点在于预训练和微调之间可能存在不一致,因为预训练时已经使用一个掩码语言模型进行了训练(用于预测被掩蔽的tokens),而微调时也进行了同样的训练。
基于提示的微调:为了解决这种不一致,基于提示的微调把任务转换为完型填空的形式。例如,图1所示的情感分类任务中,输入被转换为下面的提示形式:
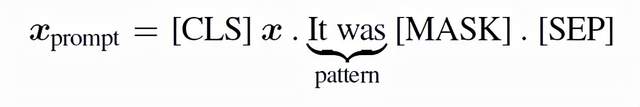

训练的策略:设是下游任务的标签,使用语言生成器(Verbalizers)可以将一个标签映射到预训练语言模型词库中的一个词语。那么,利用提示模板中的MASK,分类任务被转换到预测一个掩码的目标词语,预测标签y的概率为:
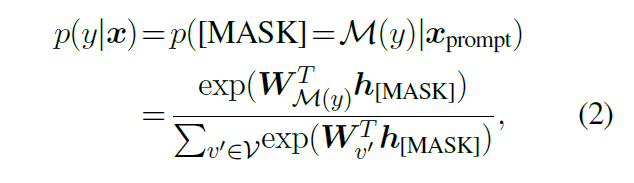

预测的策略:在预测阶段,这种基于提示的微调模型需要在给定上下文环境中选择使用哪一个Verbalizer,一般采取自回归的方式进行选择。首先把掩码token的数目从M修剪到每一个候选Verbalizer的token长度,并计算每一个掩码token概率。
然后,用概率最大的Verbalizer中的token替代相应的掩码token,再重新计算剩下的掩码token概率。重复这种自回归解码方式,直到所有要预测的掩码token都被计算完毕。
这种预测策略速度很慢,因为模型中前向路径传递的数目会随着类别数目、Verbalizer的token数目的增加而增长。
总的看来,基于提示的微调方法的成功严重依赖于手工工程的patterns和verbalizers,而寻找合适的verbalizers和patters也是困难的。
此外,手工定制的verbalizers会带来以下的效率方面的问题:
a)由于需要更新预训练语言模型的embedding层,所以会引起大量内存超负荷;
b)由于需要很小的学习率(通常是10-5),这会大大减慢verbalizers的微调速度;
c)把verbalizers作为预训练语言模型的一个token会影响输入在微调时的表示学习;
d)verbalizers的token长度是变化的,这使得其向量化会变得复杂,也是提高微调效率的一个挑战。为了解决上述困难和挑战,论文作者提出了下面的无需verbalizer和patterns的少样本学习微调方法(PERFECT)。
论文解读上篇先到这里,下篇将为大家继续分享作者独到的创新之处。
NLP论文解读:无需模板且高效的语言微调模型(上)的更多相关文章
- NLP论文解读:无需模板且高效的语言微调模型(下)
原创作者 | 苏菲 论文题目: Prompt-free and Efficient Language Model Fine-Tuning 论文作者: Rabeeh Karimi Mahabadi 论文 ...
- 医学AI论文解读 |Circulation|2018| 超声心动图的全自动检测在临床上的应用
文章来自微信公众号:机器学习炼丹术.号主炼丹兄WX:cyx645016617.文章有问题或者想交流的话欢迎- 参考目录: @ 目录 0 论文 1 概述 2 pipeline 3 技术细节 3.1 预处 ...
- 人工智能论文解读精选 | PRGC:一种新的联合关系抽取模型
NLP论文解读 原创•作者 | 小欣 论文标题:PRGC: Potential Relation and Global Correspondence Based Joint Relational ...
- 从单一图像中提取文档图像:ICCV2019论文解读
从单一图像中提取文档图像:ICCV2019论文解读 DewarpNet: Single-Image Document Unwarping With Stacked 3D and 2D Regressi ...
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- zz扔掉anchor!真正的CenterNet——Objects as Points论文解读
首发于深度学习那些事 已关注写文章 扔掉anchor!真正的CenterNet——Objects as Points论文解读 OLDPAN 不明觉厉的人工智障程序员 关注他 JustDoIT 等 ...
- 注意力论文解读(1) | Non-local Neural Network | CVPR2018 | 已复现
文章转自微信公众号:[机器学习炼丹术] 参考目录: 目录 0 概述 1 主要内容 1.1 Non local的优势 1.2 pytorch复现 1.3 代码解读 1.4 论文解读 2 总结 论文名称: ...
- 论文解读丨基于局部特征保留的图卷积神经网络架构(LPD-GCN)
摘要:本文提出一种基于局部特征保留的图卷积网络架构,与最新的对比算法相比,该方法在多个数据集上的图分类性能得到大幅度提升,泛化性能也得到了改善. 本文分享自华为云社区<论文解读:基于局部特征保留 ...
随机推荐
- java多线程中同步的问题?
一.通过模拟网络延迟,解决同步的问题. package com.zxf.demo; public class G01 implements Runnable{ private int num=10; ...
- SpringBoot集成AOP
AOP简介 面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术,AOP是OOP的延续.简单的说它就是把我们程序重复的代码抽取出来,在需要执行的时候,使用动态代理技术,在不修改 ...
- RabbitMQ简介及安装
AMQP简介 AMQP AMQP(Advanced Message Queuing Protocol,高级消息队列协议)是进程之间传递异步消息的网络协议. AMQP工作过程 发布者(Publisher ...
- Jackson 的 基本用法
Jackson 是当前用的比较广泛的,用来序列化和反序列化 json 的 Java 的开源框架.Jackson 社 区相对比较活跃,更新速度也比较快, 从 Github 中的统计来看,Jackson ...
- Swift逻辑分支
一. 分支的介绍 分支即if/switch/三目运算符等判断语句 通过分支语句可以控制程序的执行流程 二. if分支语句 和OC中if语句有一定的区别 判断句可以不加() 在Swift的判断句中必须有 ...
- vi/vim 设置.vimrc(/etc/vim | $HOME)
转载请注明来源:https://www.cnblogs.com/hookjc/ "====================================================== ...
- shell——wait与多进程并发
在脚本里用&后台打开多个子进程,用wait命令可以使这些子进程并行执行. 例1: fun1(){ while true do echo 1 sleep 1 done } fun2(){ whi ...
- Solution -「CF 1392H」ZS Shuffles Cards
\(\mathcal{Description}\) Link. 打乱的 \(n\) 张编号 \(1\sim n\) 的数字排和 \(m\) 张鬼牌.随机抽牌,若抽到数字,将数字加入集合 \(S ...
- 016 Linux 卧槽,看懂进程信息也不难嘛?top、ps
目录 1 扒开看看 top 命令参数详情 第一行,[top - ]任务队列信息 第二行,[Tasks] 任务(进程) 第三行,[Cpu(s)]状态信息 第四行,[Mem]内存状态 第五行,[Swap] ...
- tip2:Linux系统相关命令使用
好记忆不如烂笔头,很多东西不常用突然要用就是记得相关的命令但是具体就不确定了,本文记录个人不常用同时偶尔用到但不确定或者记不住的内容. 一.用户管理 这组个人使用频率不高,知道同时记不住具体涉及的系统 ...