hadoop伪分布式集群的安装(不是单机版)
准备工作
三台虚拟机,关闭防火墙,关闭selinux
查看防火状态 systemctl status firewalld
暂时关闭防火墙 systemctl stop firewalld
永久关闭防火墙 systemctl disable firewalld
查看 selinux状态 getenforce
暂时关闭 selinux setenforce 0
永久关闭 selinux 在/etc/selinux/config文件中将SELINUX改为disabled
修改主机名称
三台主机
hostnamectl set-hostname master
hostnamectl set-hostname slave1
hostnamectl set-hostname slave2
使用bash命令刷新生效
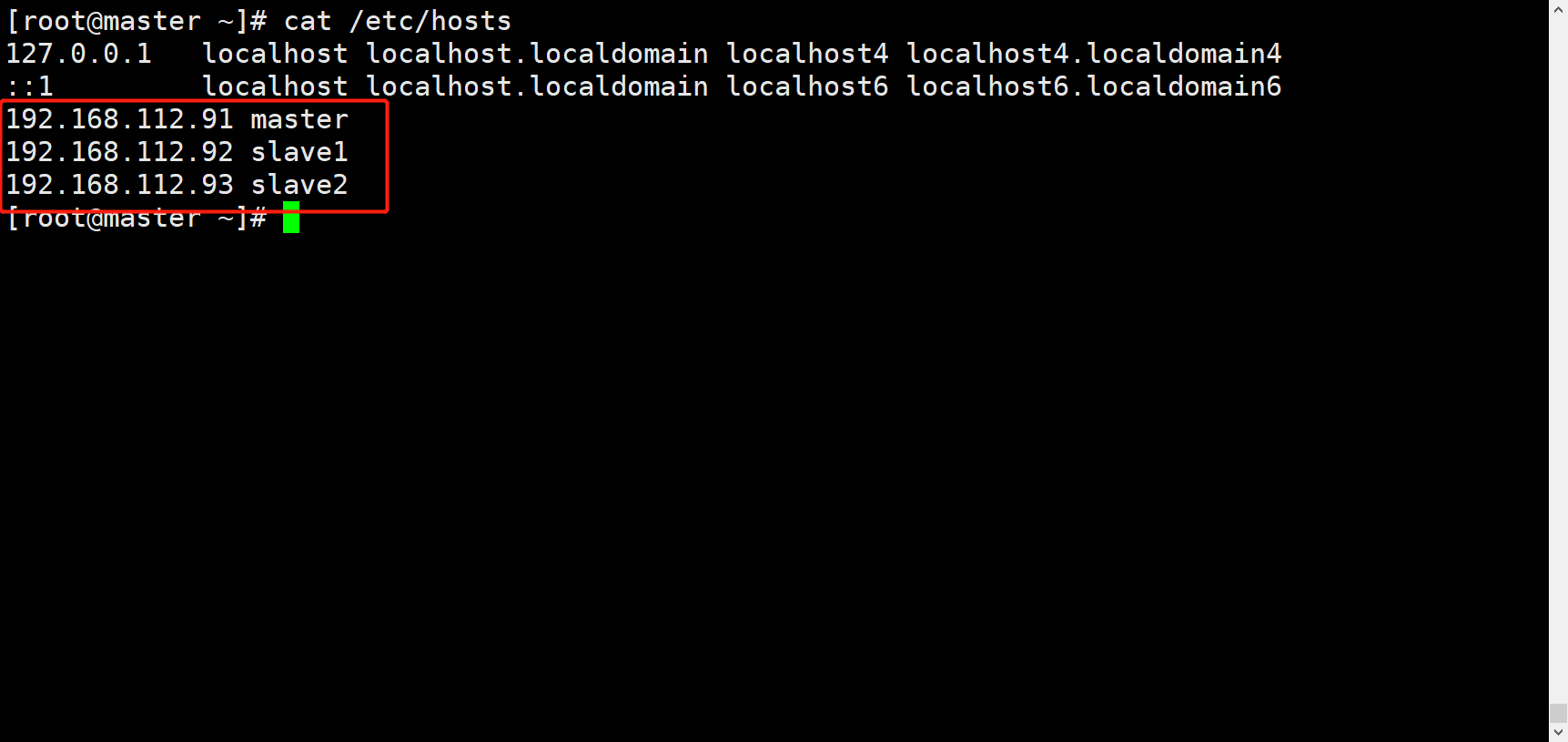
在/etc/hosts文件中添加ip映射
IP+主机名称
根据自己需求修改,这里给出模板
配置ssh免密登录
ssh-keygten -t rsa #生成密钥 ssh-copy-id master #分发给其他节点,分发给自己主要是为了之后群集集群不需要输入密码
ssh-copy-id slave1
ssh-copy-id slave2
安装JAVA和HADOOP
解压JAVA

解压HADOOP

修改名称为jdk与hadoop

配置环境变量
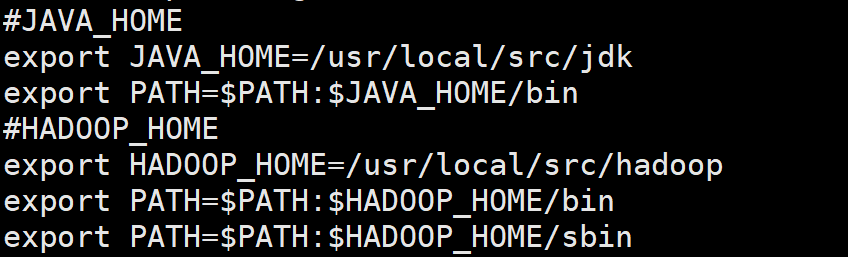
刷新环境变量,使生效
source /etc/profile
使用javac 与hadoop verison验证是否安装成功
配置hadoop文件
core-site.xml文件
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop-2.7.2/data/tmp</value>
</property>
hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop-2.6.0/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop-2.6.0/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
yarn.site.xml
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
在hadoop-env.sh yarn-env.sh mapred-env.sh中配置java环境
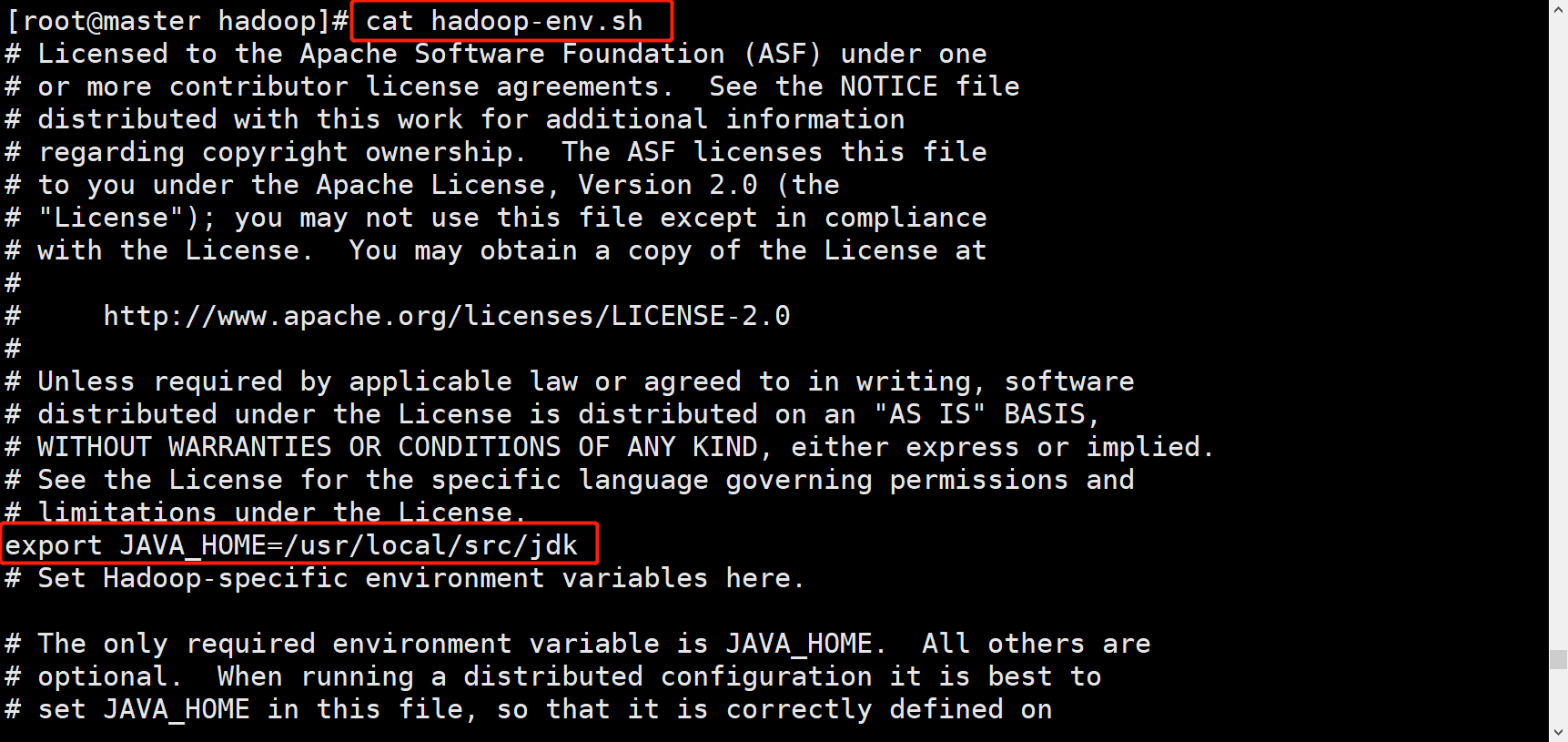
这里给出hadoop-env.sh 其他相同
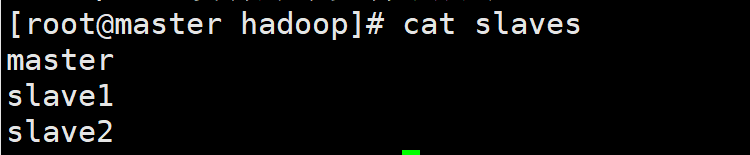
配置slave
写入三台主机的主机名
将配置好的hadoop分发给其他主机
[root@master ~]# scp -r /usr/local/src/hadoop/ root@slave1:/usr/local/src/ [root@master ~]# scp -r /usr/local/src/hadoop/ root@slave2:/usr/local/src/
格式化namenode
hdfs namenode -format
启动dfs
start-dfs.sh
启动yarn
start-yarn.sh
使用jps查看
master节点:ResourceManager,DataNode,SecondaryNameNode,NameNode,NodeManager
slave1节点与slave2节点:NodeManager,DataNode
集群全部启动则为启动成功
进入web页面验证
namenode web页面 = IP+50070
yarn web页面 =IP 8088
hadoop伪分布式集群的安装(不是单机版)的更多相关文章
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- hadoop伪分布式集群的搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 linux系统环境:Centos6.5 创建普通用户 dummy 设置静态IP地址 Hadoop伪分布式集群搭建: 为普通用户添加su ...
- 基于Hadoop伪分布式集群搭建Spark
一.前置安装 1)JDK 2)Hadoop伪分布式集群 二.Scala安装 1)解压Scala安装包 2)环境变量 SCALA_HOME = C:\ProgramData\scala-2.10.6 P ...
- hadoop学习笔记(五)hadoop伪分布式集群的搭建
本文原创,如需转载,请注明作者和原文链接 1.集群搭建的前期准备 见 搭建分布式hadoop环境的前期准备---需要检查的几个点 2.解压tar.gz包 [root@node01 ~]# ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop伪分布式集群
一.HDFS伪分布式环境搭建 Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点.但同时, ...
- Hadoop学习笔记(一):ubuntu虚拟机下的hadoop伪分布式集群搭建
hadoop百度百科:https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin hadoop官网:http://hadoop.apache.org/ ...
- 大数据学习之hadoop伪分布式集群安装(一)公众号undefined110
hadoop的基本概念: Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速运算和存储. Hadoo ...
- Hadoop伪分布式集群搭建
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 1.下载Hadoop压缩包 wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop- ...
随机推荐
- openvas漏洞扫描:使用openvas时扫描漏洞时,报告中显示的数据与数据库数据不同
使用openvas设备进行漏洞扫描时,报告中的漏洞数量与readis数据库中查找到的漏洞数量不同 原因是,openvas的代码中默认在报告中显示的最小质量检测为70%.如图: 上图详细链接为:http ...
- 【PostgreSql】more than one owned sequence found
do --check seq not in sync $$ declare _r record; _i bigint; _m bigint; begin for _r in ( Select DIST ...
- 一起学JAVA:做一个简单的API项目吧(一)
由于一些特殊原因,最近想要去学习JAVA,了解JAVA ,然后在此之前对JAVA只停留在能读懂代码,但是写不懂的状态,那么最近又很闲,所以打算重新进行一波自己的学习计划,又因为是三分钟的热情,所以特意 ...
- 重写antd组件样式
:global { .ant-select-selection-placeholder { color: #FFF; font-size: 14px; } .ant-select-selection- ...
- Microsoft.CppCommon.targets(138,5): error MSB3073
我生成 Zlib 库的某个项目的时候,出现了这些error,原来是项目属性---->生成后事件--->命令行 错误的内容就是命令行内容.这些命令行的具体作用我还不知道,但是把他们删除后就成 ...
- ASP.NET WEBAPI 获取微信ticket
public static string GetTicket(string AccessToken) { //类型 string Type = "jsapi"; string st ...
- 查看shell 用户连接数
w | grep pts |wc -l
- Windows10远程桌面连接CentOS7图形化桌面
Step1:在Centos7上检查是否安装了epel库 执行命令:rpm -qa|grep epel 示例: [root@master ~]# rpm -qa|grep epel[root@maste ...
- Redis学习(黑马篇)
1.redis是一个键值型数据库即在Redis内存的数据都是键值对的格式,如: 2.NOSQL非关系型数据库与MySQL关系型数据库对比: 非结构化类型分为:键值类型(Redis)(value支持多种 ...
- VUE+.NET应用系统的国际化-多语言词条服务
上篇文章我们介绍了 VUE+.NET应用系统的国际化-整体设计思路 系统国际化改造整体设计思路如下: 提供一个工具,识别前后端代码中的中文,形成多语言词条,按语言.界面.模块统一管理多有的多语言词条 ...