TSDB - VictoriaMetrics 技术原理浅析
版权说明: 本文章版权归本人及博客园共同所有,转载请在文章前标明原文出处( https://www.cnblogs.com/mikevictor07/p/17258452.html ),以下内容为个人理解,仅供参考。
一、前言
在监控领域,通常需要指标存储组件TSDB,目前开源的TSDB组件比较多,各个组件性能、高可用性、维护成本等等各有差异。本文不分析选型问题,重点讲解VictoriaMetrics(后面简称为vm)。
有兴趣的朋友建议结合源码进行分析,由于源码不断变更,此分析基于 v1.80.0,后续版本变化理论上不会很大。
二、架构与能力
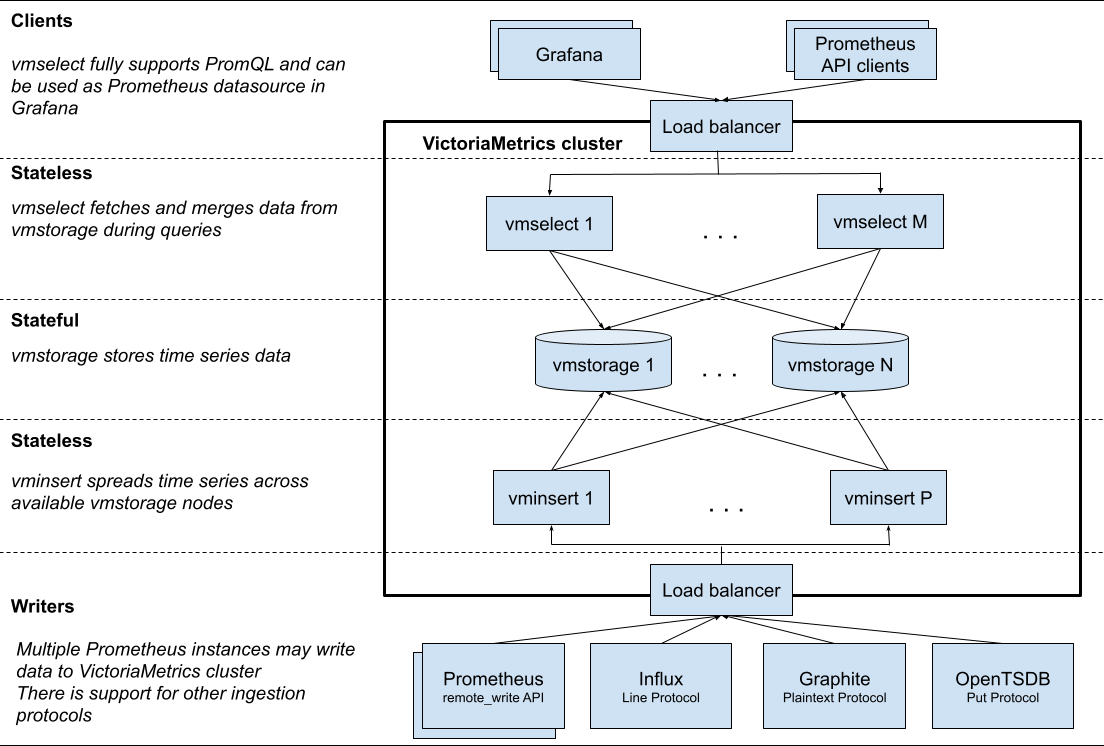
vm开源版本分为single-server(all in one)的单节点模式和cluster模式,单点模式合适本地调试或测试使用,生产使用的cluster模式分为vmselect、vminsert、vmstorage三个主要模块:
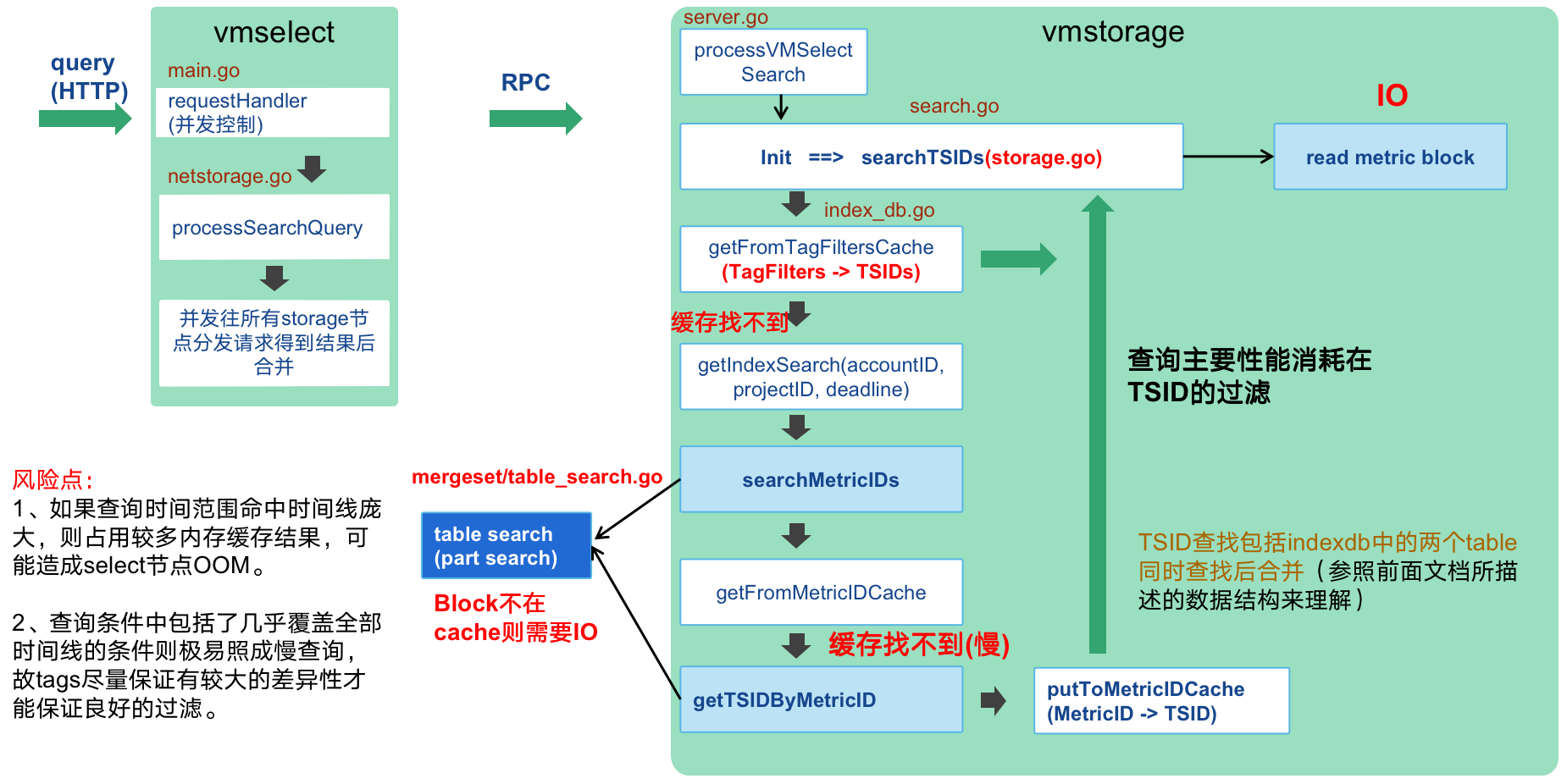
(1)vmselect:查询模块,可无状态部署,客户端发送请求到查询模块后,查询模块会把请求分发到所有storage模块(由于没有元数据中心节点,固数据存储在哪无法感知,类似clickhouse的设计模式),得到原始的block数据后在select模块进行合并,再得到一个总结果。
(2)vminsert:写入模块,可无状态部署,写入数据的请求发到此模块后,根据labels通过一定的hash计算出一个值,根据这个值确定此条数据发往哪个storage节点。因此相同的时间线会往同一个点节点发送,如果有某个时间线数据量特别大则会出现数据倾斜问题后某个storage写入和查询压力都会增大。在扩容货缩容后,由于节点的列表变更,固计算出的hash发往的storage节点也会变更。
(3)vmstorage:存储模块,有状态,存储模块的移除须先从select和insert的配置中移除才不会有异常,此模块压力最大,非常消耗内存和IO,固推荐使用SSD和比较大的内存,宁愿用大规格的机器也不用量多但规格较小的机器(缓存不命中则会造成较多的IO,性能下降严重)。
三、vmstorage 存储模块
本文重点讲难度最高的 storage 模块,也只是属于个人理解,如有错误或偏差,望指正。
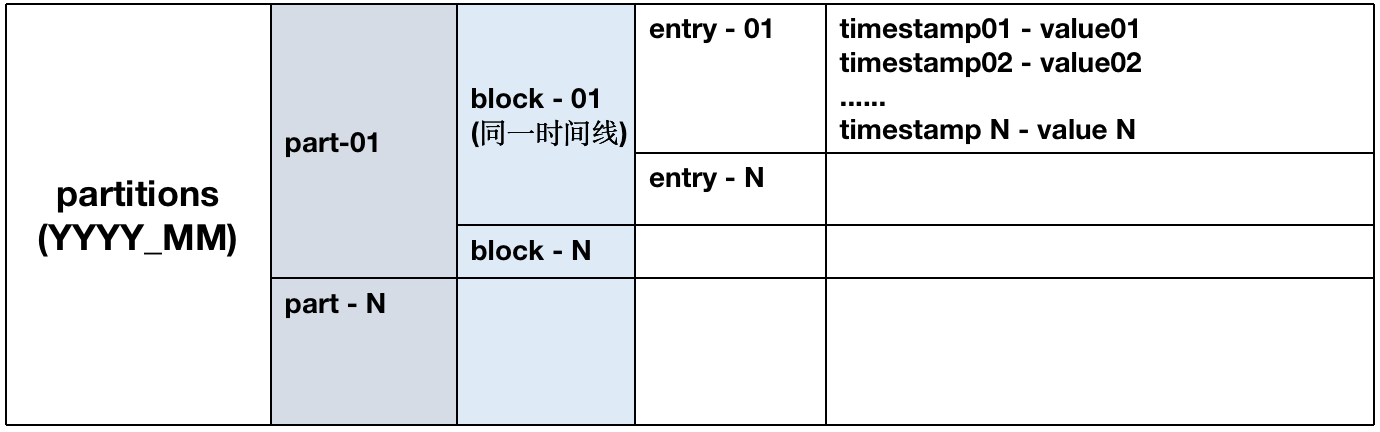
1、存储目录结构

/data 数据目录的逻辑结构如下:
(1)每个block只包括一个时间线,内部根据时间排序。
(2) 每个block最大容纳8000个sample,不同block可并发处理。
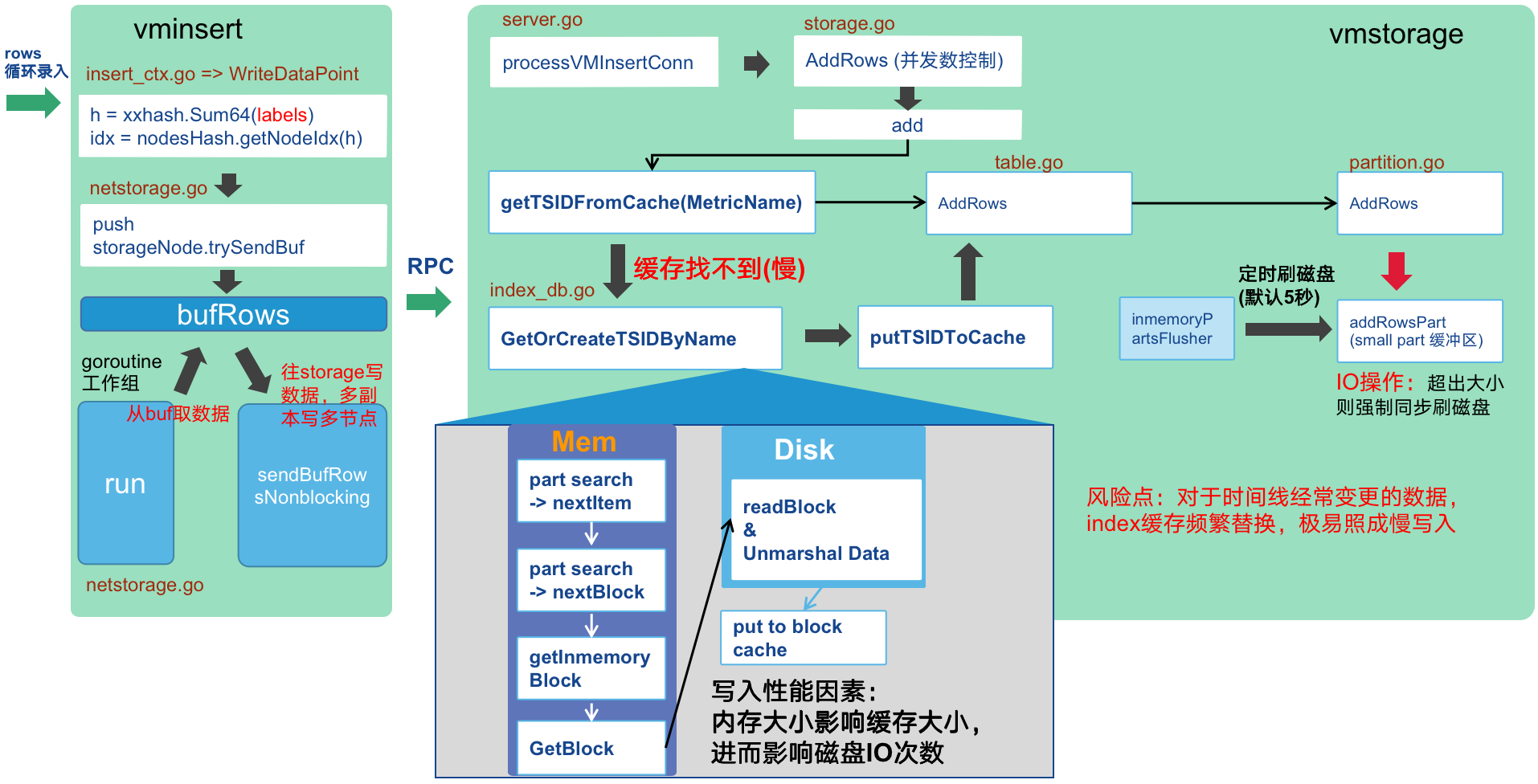
2、 写入流程与风险点
3、查询流程与风险点
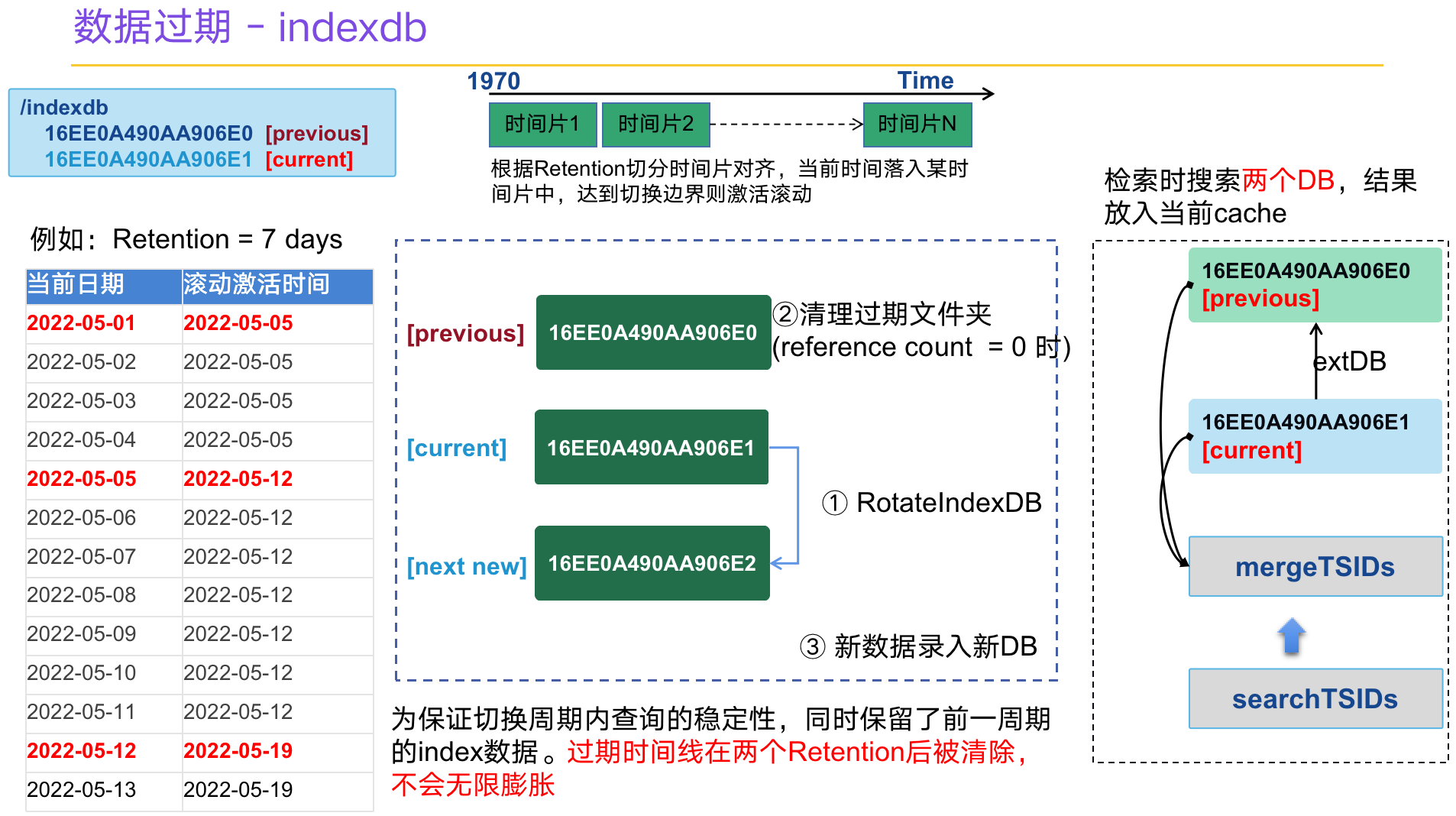
4、数据过期机制
开源的cluster版本只能针对租户使用全局的统一过期时间,收费的企业版才能支持租户单独设置过期时间。

5、数据安全性保障
(1)VictoriaMetrics 并未使用WAL,而是直接写入类似SSTable的内存结构中,定时刷写磁盘,这是此模块能表现出极高的写入性能的一个原因,如果是单副本则宕机时有可能照成最近的少量数据丢失,如果是数据安全性要求极高的场景,则建议开启双副本模式。
(2)双副本状态下,写入性能有一定的下降。即使在双副本模式下,不能同时下线两台主机,如果同时下掉两台主机则数据会丢失,为保证数据安全,建议对存储层配置RAID1、RAID5或RAID10保证数据安全性,迁移时将数据从data目录直接迁移走即可在另一主机运行。
四、运维&监控能力、Downsample
(1)vm配置有grafana的监控模板,安装即可观测各个模块的性能,需要结合代码才能比较深入的了解各个指标的作用含义(不过最前面部分的CPU/内存总量的计算貌似不正确,未深究,有兴趣可以看看什么问题)。
(2)vm写入由于没有WAL,如果出现大量缓存失效则容易出现慢写入,甚至大量超时,所以写入建议前置一个MQ(如kafka)缓解写入异常放大,写入模块做一定的异常限流防止查询也出现大量超时。
(3)vm很吃内存和磁盘,磁盘随机IO很多,建议配置SSD。
(4)vm开源版不支持存储层的downsample(企业版才支持),故会查询原始数据后通过promQL配置采样减少输出点,但总的来说不是存储层的downsample查询时间范围过大时会有很大的压力(比如一个月以上),建议上报的数据1分钟一个点位减少数据量。
五、性能见解与总结
官方写了一些英文博文对比influxdb的性能,vm的表现优异,但建议实测(官方提供的总有一些趋向性)。从个人的测试数据上看表现确实很不错,数据不方便公开,建议自测。
总之,此款基于golang的开源TSDB性能表现很好,要能驾驭这组件需要比较多的功力,不能单纯从表层去把它当做一个黑盒来运维,以免后续出现慢写入慢查询会变得手足无措。
源码层面的分析可以搜索下其他文章,在此就不再分析代码段。
TSDB - VictoriaMetrics 技术原理浅析的更多相关文章
- java数据库连接池技术原理(浅析)
在执行数据库SQL语句时,我们先要进行数据连接:而每次创建新的数据库的连接要消耗大量的资源,这样,大家就想出了数据库连接池技术.它的原理是,在运行过程中,同时打开着一定数量的数据库连接,形成数据连接池 ...
- 模拟实现 DBUtils 工具 , 技术原理浅析
申明:本文采用自己 C3P0 连接池工具进行测试 自定义的 JDBCUtils 可以获取 Connection: package com.test.utils; import java.sql.Con ...
- 沉淀,再出发:docker的原理浅析
沉淀,再出发:docker的原理浅析 一.前言 在我们使用docker的时候,很多情况下我们对于一些概念的理解是停留在名称和用法的地步,如果更进一步理解了docker的本质,我们的技术一定会有质的进步 ...
- 【Spark Core】TaskScheduler源代码与任务提交原理浅析2
引言 上一节<TaskScheduler源代码与任务提交原理浅析1>介绍了TaskScheduler的创建过程,在这一节中,我将承接<Stage生成和Stage源代码浅析>中的 ...
- 大数据相关技术原理资料整理(hdfs, spark, hbase, kafka, zookeeper, redis, hive, flink, k8s, OpenTSDB, InfluxDB, yarn)
hdfs: hdfs官方文档 深入理解HDFS的架构和原理 https://blog.csdn.net/kezhong_wxl/article/details/76573901 HDFS原理解析(总体 ...
- 消息队列——ActiveMQ使用及原理浅析
文章目录 引言 正文 一.ActiveMQ是如何产生的? 产生背景 JMS规范 基本概念 JMS体系结构 二.如何使用? 基本功能 消息传递 P2P pub/sub 持久订阅 消息传递的可靠性 事务型 ...
- MyBatis 原理浅析——基本原理
前言 MyBatis 是一个被广泛应用的持久化框架.一个简单的使用示例如下所示,先创建会话工厂,然后从会话工厂中打开会话,通过 class 类型和配置生成 Mapper 接口的代理实现,最后使用 Ma ...
- 老生常谈系列之Aop--Spring Aop原理浅析
老生常谈系列之Aop--Spring Aop原理浅析 概述 上一篇介绍了AspectJ的编译时织入(Complier Time Weaver),其实AspectJ也支持Load Time Weaver ...
- Netty构建分布式消息队列实现原理浅析
在本人的上一篇博客文章:Netty构建分布式消息队列(AvatarMQ)设计指南之架构篇 中,重点向大家介绍了AvatarMQ主要构成模块以及目前存在的优缺点.最后以一个生产者.消费者传递消息的例子, ...
- Atitit.ide技术原理与实践attilax总结
Atitit.ide技术原理与实践attilax总结 1.1. 语法着色1 1.2. 智能提示1 1.3. 类成员outline..func list1 1.4. 类型推导(type inferenc ...
随机推荐
- 选择 podman 的理由, 以及它和 Kubernetes , Docker 的区别
转载自https://zhuanlan.zhihu.com/p/506265757 前言 大家好,我是 Liangdi, podman 4.x 版本已经发布了, 我也从 docker 开始向 podm ...
- 【已解决】robotframework 连接oracle数据库返回结果中文显示乱码
问题描述:查询数据库返回信息有中文的时候会显示unicode的样式,如图: 环境:robotframework 3.0.x 解决方法: 找到Python安装目录下的\Lib\site-packages ...
- 在mysql中正常查询的句子,在C#中出错,原因是定义了变量。
在C#中 查询一样. 运行报错 Fatal error encountered during command execution." 命令执行过程中碰到的致命错误." MySqlE ...
- Jndi结合DynamicDataSource实现多数据源配置
首先注意本框架是SSM,配置主要在两个地方.第一个是applicationContext.xml,第二个文件是Tomcat下面的context.xml里面 1.context.xml文件配置的代码如下 ...
- java流程控制;
一.基础阶段: 1.用户交互Scanner Scanner对象: 之前我们学的基本语法中我们并没有实现程序和人的交互,但是Java给我们提供了这样一个工具类,我们可以获取用户的输入. java.uti ...
- 荔枝派Licheepi nano裸机移植ZLG_GUI和3D旋转立方体
一:前言 以前申请到了荔枝派zero,在发了两个开箱贴后就放在一边吃灰了.后来又购买了荔枝派nano,刷了几个教程中的系统之后又放到一边吃灰了.虽然有屯板子的习惯,却没有使用板子的能力. 后来,经过断 ...
- new一个实例的原理及过程
前提,要明白new出来的实例是什么,包含了哪些内容? 请看一下举例代码↓↓↓↓ function Person(name,age){ this.name = name; this.age = age; ...
- Docker 容器与镜像
列出所有容器ID :docker ps -aq 查看所有运行或者不运行容器:docker ps -a 停止所有的container(容器),这样才能够删除其中的images:docker stop $ ...
- FIRE2023:殁亡漫谈
FIRE2023:殁亡漫谈 读书的时候,想到殁亡,脑海涌出一则喜欢的遗言: 钱花完了,我走了.签名 如果可能牵涉到旁人(比如殁在旅馆里),就再立一则: 我的殁与店家无关. 签名 然后放下Kindle, ...
- Python第七章实验报告
一.实验名称:<零基础学Python>第7章 面向对象程序设计 二.实验环境:IDLE Shell 3.9.7 三.实验内容:5道实例.4道实战 四.实验过程: 实例01 创建大雁类并定义 ...