用Python语言进行时间序列ARIMA模型分析
应用时间序列
时间序列分析是一种重要的数据分析方法,应用广泛。以下列举了几个时间序列分析的应用场景:
1.经济预测:时间序列分析可以用来分析经济数据,预测未来经济趋势和走向。例如,利用历史股市数据和经济指标进行时间序列分析,可以预测未来股市的走向。
2.交通拥堵预测:时间序列分析可以用来预测交通拥堵情况。例如,根据历史车流量和天气信息,可以建立一个时间序列模型来预测未来某个时间段的路况。
3.天气预测:时间序列分析可以用于天气预测,例如预测未来几天或几周的降雨量、温度等。这对于农业生产和水资源的管理非常重要。
4.财务规划:时间序列分析可以用来帮助企业进行财务规划。例如,通过分析历史销售数据,可以预测未来销售额,并制定相应的预算计划。
5.工业控制:时间序列分析可以用来优化工业生产过程。例如,根据机器运行状态和历史生产数据,可以建立一个时间序列模型来优化生产线的运行,提高生产效率。
源数据样例:

以下是数据的具体时间序列分析步骤:
注意:以下时间序列分析代码仅限一阶差分或者不使用差分进行的代码,以一阶差分为例。
一.导入数据
1 df=pd.read_excel('M17.xlsx')
2 print(df["水位"].head())
3
4 # 创建一个DatetimeIndex对象,指定时间范围为2021年1月1日到1月5日
5 dates = pd.date_range(start='1860-01-01', end='1955-12-31',freq='AS')
6 # 创建一个Series对象,将列表作为数据,DatetimeIndex对象作为索引
7 t_s = pd.Series(data=df["水位"].tolist(), index=dates)
8 t_s.index = t_s.index.strftime('%Y')
注:这里的数据df为dataframe数据,两列;t_s为时间序列数据,第二列,它内涵时间索引
二.绘制时序图
时序图是一种用于展示时间序列数据的图表,通常将时间作为X轴,将变量(如销售额、温度等)作为Y轴。时序图可以帮助我们观察和分析时间序列数据的趋势、季节性、周期性以及异常值等。
一个典型的时序图通常包括以下几个元素:
1-->X轴:表示时间轴,通常根据数据的时间粒度来设置刻度。例如,如果数据是按日收集的,则X轴可能显示日期;如果是按小时收集的,则X轴可能显示小时数。
2-->Y轴:表示变量的取值范围,通常根据数据的特性来设置刻度。例如,如果数据表示某个产品的销售额,则Y轴可能显示金额数值;如果数据表示温度,则Y轴可能显示摄氏度或华氏度。、
3-->数据线:表示时间序列数据的变化趋势,通常用一条连续的曲线或折线来表示。数据线的颜色和样式可以根据需要进行调整,以突出重点信息。
4-->标题和注释:用于说明时序图的含义、数据来源和相关信息。
将时间序列数据可视化成时序图,可以更加直观地观察和分析数据的变化趋势和规律,从而更好地理解数据。
首先可以绘制线图直接观察数据走势粗略判断平稳性,既无趋势也无周期
1 #时序图
2 plt.plot(df['年份'],df['水位'])
3 plt.xlabel("年份")
4 plt.ylabel("水位")
5 plt.show()

三.初步检验
3.1.纯随机性检验(白噪声检验)
3.1.1Ljung-Box 检验
Ljung-Box 检验是一种常用的时间序列分析方法,可以用于检测数据是否具有白噪声特征。白噪声指的是一种随机性非常强的信号,其中每个时间点的值都是独立且服从相同的分布。
Ljung-Box 检验是基于自相关和偏自相关函数计算的。在实际应用中,需要将时间序列数据转化为平稳序列,然后计算其自相关和偏自相关函数。Ljung-Box 检验会统计一组拉格朗日乘子(Lagrange Multiplier)值,从而判断序列数据是否具有白噪声特征。
通常情况下,如果 Ljung-Box 检验的统计值小于置信度水平对应的临界值,就可以认为时间序列数据具有白噪声特征。反之,如果统计值大于临界值,则可以认为时间序列数据不具有白噪声特征。
print("随机性检验:",'\n',lb_test(df["水位"], return_df=True,lags=5))

其中 df["水位"] 是一个一维数组,表示时间序列数据;lags 参数指定计算自相关和偏自相关函数的滞后阶数。如果希望以一定的置信度进行 Ljung-Box 检验,可以根据自由度和置信度水平计算出对应的临界值,然后将其与 stat 进行比较。
注:当p值小于0.05时为显著非白噪声序列
3.1.2单位根检验:ADF检验
单位根检验,也称为增广迪基-福勒检验(Augmented Dickey-Fuller test,ADF test),是一种用于检验时间序列数据是否具有单位根(unit root)的方法。在时间序列分析中,单位根通常是假设时间序列数据中存在一种长期的趋势或非平稳性。
单位根检验旨在验证时间序列数据是否具有平稳性。如果时间序列数据具有单位根,则说明数据存在非平稳性,并且预测和分析可能会出现问题。因此,在进行时间序列分析之前,我们需要先进行单位根检验,以确保数据具有平稳性。
ADF检验是一种常用的单位根检验方法,它通过计算时间序列数据的ADF统计量来判断数据是否具有单位根。ADF统计量与t值类似,表示观测值与滞后版本之间的差异程度,同时考虑了其他因素的影响。如果ADF统计量小于对应的临界值,则拒绝原假设,即数据不存在单位根,表明数据具有平稳性。
除了ADF检验外,还有许多其他的单位根检验方法,例如Dickey-Fuller检验、KPSS检验等。不同的单位根检验方法具有不同的假设条件和适用范围,需要根据具体情况来选择合适的方法。
总之,单位根检验是一种重要的时间序列分析工具,用于验证数据是否具有平稳性。只有在数据具有平稳性的情况下,才能进行有效的预测和分析。
检验假设:H0:存在单位根 vs H1:不存在单位根
如果序列平稳,则不应存在单位根,所以我们希望能拒绝原假设
1 # 进行ADF检验
2 result = ts.adfuller(df['水位'])
3 # 输出ADF结果
4 print('-------------------------------------------')
5 print('ADF检验结果:')
6 print('ADF Statistic: %f' % result[0])
7 print('p-value: %f' % result[1])
8 print('Lags Used: %d' % result[2])
9 print('Observations Used: %d' % result[3])
10 print('Critical Values:')
11 for key, value in result[4].items():
12 print('\t%s: %.3f' % (key, value))

当p-value>0.05,则要进行差分运算!否之直接跳转到模型选择与定阶。
3.2差分运算
差分运算是时序数据预处理中的一个常见操作,它可以用来消除时间序列数据中的趋势和季节性变化,从而使得数据更加平稳。在时间序列分析和建模中,平稳序列通常比非平稳序列更容易建模,并且能够提供更精确的预测结果。
差分运算可以通过计算序列中相邻数据之间的差值得到。一阶差分是指将每个数值与其前一个数值相减,得到一个新的序列;二阶差分是指对一阶差分后的序列再进行一次差分运算,以此类推。
1 ##### 差分运算
2 def diff(timeseries):
3 new_df=timeseries.diff(periods=1).dropna()#dropna删除NaN
4 new_df.plot(color='orange',title='diff1')
5 return new_df
6
7 #进行一阶差分
8 ndf=diff(df['水位'])

或者如下方式也可以进行差分
ndf = pd.Series(np.diff(df['水位'], n=1))
注:n=1表示1阶差分
3.3再次进行ADF检验
1 #再次进行ADF检验
2 result2 = ts.adfuller(ndf)
3 # 输出ADF结果
4 print('-------------------------------------------')
5 print('差分后序列的ADF检验结果:')
6 print('ADF Statistic: %f' % result2[0])
7 print('p-value: %f' % result2[1])
8 print('Lags Used: %d' % result2[2])
9 print('Observations Used: %d' % result2[3])
10 print('Critical Values:')
11 for key, value in result2[4].items():
12 print('\t%s: %.3f' % (key, value))

如果p-value<0.05则进行下一步定阶;如p-value仍然>0.05,则继续进行差分,再进行ADF检验,直到检验结果的p-value<0.05则进行下一步定阶。
四.模型选择与定阶
4.1自相关图和偏自相关图人工定阶
自相关图和偏自相关图是时序数据分析中常用的工具,可以帮助我们理解时间序列数据中的自相关性和互相关性。自相关函数(ACF)和偏自相关函数(PACF)是计算自相关图和偏自相关图的数学概念。
自相关图展示了时间序列数据在不同滞后阶数下的自相关系数,即前一时间点与后面所有时间点之间的相关性。自相关图有助于判断时间序列数据是否存在季节性或周期性变化,并且可以用来选择合适的时间序列模型。如果一个时间序列数据存在季节性变化,则其自相关图通常会呈现出明显的周期性模式。
偏自相关图展示了在滞后阶数为 n 时,在其他阶数的影响已被削减的情况下,上一时间点与当前时间点之间的相关性。偏自相关图可以帮助我们确定时间序列数据中的短期相关性,从而选择合适的时间序列模型。如果一个时间序列数据存在短期相关性,则其偏自相关图通常会显示出急速衰减的模式。
模型定阶就是根据自相关图和偏自相关图来确定时间序列模型的阶数。一般建议先使用自相关图和偏自相关图来判断时间序列数据的性质和模型类型,然后根据其结果选择适当的时间序列模型及其阶数。常用的时间序列模型包括 AR、MA、ARMA 和 ARIMA 等。

1 #模型选择:绘制ACF与PACF,即自相关图和偏自相关图
2 #### 绘制ACF与PACF的图像
3 def plot_acf_pacf(timeseries): #利用ACF和PACF判断模型阶数
4 plot_acf(timeseries,lags=timeseries.shape[0]%2) #延迟数
5 plot_pacf(timeseries,lags=timeseries.shape[0]%2)
6 plt.show()
7 plot_acf_pacf(ndf)


4.2利用AIC与BIC准则进行迭代调优
AIC(Akaike Information Criterion)和 BIC(Bayesian Information Criterion)是常用的模型选择准则,可以用来评估不同模型在拟合数据时的复杂度和优劣程度。一般来说,AIC 和 BIC 的值越小,表示模型对数据的解释能力越强,预测结果也更加可信。
利用 AIC 和 BIC 进行迭代调优的基本思路如下:
1-->根据需要拟合的时间序列数据,选择一个初始模型,并计算其 AIC 和 BIC 值。
2-->对模型进行迭代调优。例如,可以逐步增加 AR 或 MA 的阶数,或者使用其他方法来改进模型的性能。每次更新模型后,重新计算 AIC 和 BIC 值,并与之前的值进行比较。
3-->如果新的 AIC 或 BIC 值更小,则接受新的模型;否则,保留原始模型。重复上述过程,直到找到最小的 AIC 和 BIC 值,并确定最佳的时间序列模型及其参数。
需要注意的是,AIC 和 BIC 只是一种近似的模型评价指标。在实际应用中,还需要考虑其他因素,例如模型的可解释性、预测误差等。因此,在选择时间序列模型时,需要综合考虑多个因素,以选择最合适的模型。
1 #迭代调优
2 print('-------------------------------------------')
3 #AIC
4 timeseries=ndf
5 AIC=sm.tsa.stattools.arma_order_select_ic(timeseries,max_ar=4,max_ma=4,ic='aic')['aic_min_order']
6 #BIC
7 BIC=sm.tsa.stattools.arma_order_select_ic(timeseries,max_ar=4,max_ma=4,ic='bic')['bic_min_order']
8 print('the AIC is{}\nthe BIC is{}\n'.format(AIC,BIC))

五.模型构建
ARIMA 模型是一种常用的时间序列分析模型,可以用来预测未来一段时间内的数据趋势。ARIMA 的全称是 Autoregressive Integrated Moving Average,其中 Autoregressive 表示自回归模型,Integrated 表示差分操作,Moving Average 表示滑动平均模型。
ARIMA 模型的一般形式为 ARIMA(p, d, q),其中 p、d 和 q 分别表示 AR 模型、差分阶数和 MA 模型的阶数。当d=0时,即差分阶数为零时为ARMA模型。具体来说:
·AR 模型是指基于前期观测值的线性组合,来预测当前观测值的模型。AR 模型的阶数 p 表示使用前 p 个时刻的观测值来预测当前时刻的值。
·差分操作是对原始数据进行差分运算(即相邻两个时间点之间的差值),以消除数据中的趋势和季节性变化。
·MA 模型是指基于前期观测值的随机误差的线性组合,来预测当前观测值的模型。MA 模型的阶数 q 表示使用前 q 个时刻的随机误差来预测当前时刻的值。
1 #模型构建
2 print('-------------------------------------------')
3 model= ARIMA(ndf, order=(1, 1, 2)).fit()
4 print(model.params)
5 print(model.summary())


六.模型后检验
6.1残差检验
残差检验是在统计学中经常用于检测线性回归模型是否符合假设的方法之一。在进行线性回归时,我们基于数据拟合一个模型,并观察模型的残差(实际值与模型预测值之间的差异)是否具有某些特定的性质。
通常情况下,如果残差服从正态分布、均值为零、方差相等,则说明模型拟合良好。而如果残差不满足上述条件,则表明模型可能存在问题,需要进一步调整或改进。
在进行残差检验时,常用的方法包括:
1-->绘制残差图:将样本数据的残差绘制成散点图,观察其是否随着自变量的增加而呈现出某种规律,比如呈现出线性或非线性关系。如果残差呈现出某种规律,则表明模型存在问题。
2-->绘制Q-Q图:将残差按照大小排序,并将其对应于标准正态分布的分位数,然后绘制出散点图。如果散点图近似于一条直线,则表明残差服从正态分布。
3-->进行统计检验:利用统计学方法检验残差是否服从正态分布。常用的检验方法包括Kolmogorov-Smirnov检验、Shapiro-Wilk检验等。
总之,残差检验是一种判断线性回归模型拟合效果的重要方法,可以帮助我们发现和解决模型存在的问题。
残差图:
1 #残差图
2 model.resid.plot(figsize=(10,3))
3 plt.show()

6.2Jarque-Bera检验
Jarque-Bera检验是一种用于检验样本数据是否符合正态分布的方法。它基于统计学中的JB检验,可以检验样本数据的偏度和峰度是否符合正态分布的假设。
在Jarque-Bera检验中,我们首先计算样本数据的偏度和峰度,然后根据公式计算出JB统计量,最后对其进行显著性检验。
Jarque-Bera检验的原假设是:样本数据符合正态分布。如果p值较小,则拒绝原假设,即认为样本数据不符合正态分布。
1 #进行Jarque-Bera检验
2 print('-------------------------------------------')
3 jb_test = sm.stats.stattools.jarque_bera(model.resid)
4 print('Jarque-Bera test:')
5 print('JB:', jb_test[0])
6 print('p-value:', jb_test[1])
7 print('Skew:', jb_test[2])
8 print('Kurtosis:', jb_test[3])

6.3Ljung-Box检验
Ljung-Box检验是一种用于检验时间序列数据是否存在自相关性的方法。它基于时间序列模型的残差,可以用来判断残差之间是否存在显著的线性相关性。
在进行Ljung-Box检验时,我们首先计算时间序列模型的残差,并对其进行平方处理(Q值)。然后根据公式计算出LB统计量和相应的p值,最后对其进行显著性检验。
Ljung-Box检验的原假设是:时间序列模型的残差之间不存在自相关性。如果p值较小,则拒绝原假设,即认为残差之间存在显著的自相关性。
1 print('-------------------------------------------')
2 lb_test= sm.stats.diagnostic.acorr_ljungbox(model.resid, return_df=True,lags=5)
3 print('Ljung-Box test:','\n',lb_test)

6.4DW检验
DW检验是一种用来检验线性回归模型是否存在自相关性的方法,其中DW代表Durbin-Watson。该检验方法通常应用于时间序列数据中的多元线性回归分析中,可以用于判断误差项(残差)的时间序列是否具有自相关结构。
DW统计量的取值范围为0~4,当DW统计量接近2时,表明误差项不存在一阶自相关;DW小于2,则存在正自相关;DW大于2则存在负自相关。根据经验规律,DW统计量在1.5 ~ 2.5之间可以认为不存在自相关;小于1.5表示存在正自相关;大于2.5表示存在负自相关。
1 # 进行DW检验
2 print('-------------------------------------------')
3 dw_test = sm.stats.stattools.durbin_watson(model.resid)
4 print('Durbin-Watson test:')
5 print('DW:', dw_test)

6.5利用QQ图看正态性
QQ图,全称Quantile-Quantile图,是一种用于检验数据分布是否符合某种理论分布(通常为正态分布)的方法。它通过将数据的样本分位数与理论分位数进行比较,并将其绘制成散点图的方式来展示数据的分布情况。
如果样本分布与理论分布一致,则散点图应该大致呈现出一条直线。如果两者之间存在差异,则散点图会偏离一条直线,并呈现出“S”型或其他非线性形状,这表明样本数据的分布与理论分布不一致。
1 #QQ图看正态性
2 qqplot(model.resid, line="q", fit=True)
3 plt.show()

七.模型评价
7.1生成模型预测数据
利用已生成的模型对数据进行重新预测,代原值计算后 通过反向差分运算(前期没有进行差分运算则不需要,前期差分运算了几步这里要反向运算几步)的数据 与 原数据(真实数据)进行比对。
1 #模型预测
2 print('-------------------------------------------')
3 predict= model.predict(1,95)#dynamic=True)
4 # print('模型预测:','\n',predict)
5 #反向差分运算
6 # 对差分后的时间序列进行逆差分运算,两个参数:差分数据序列和原始数据序列
7 def inverse_diff(diff_series, original_series):
8 inverted = []
9 prev = original_series.iloc[0]
10 for val in diff_series:
11 current = val + prev
12 inverted.append(current)
13 prev = current
14 return pd.Series(inverted, index=original_series.index[1:])
15 n_predict=inverse_diff(predict,t_s)
16 print('模型预测:','\n',n_predict)

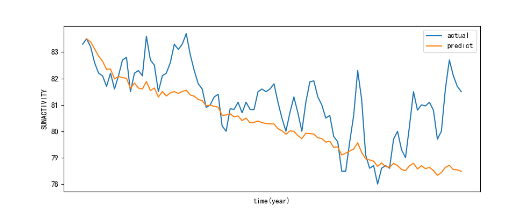
7.2真实值与预测值划入同意图像进行比对
1 # #画图
2 plt.figure(figsize=(10,4))
3 plt.plot(t_s.index,t_s,label='actual')
4 plt.plot(predict.index,n_predict,label='predict')
5 plt.xticks([])
6 plt.legend(['actual','predict'])
7 plt.xlabel('time(year)')
8 plt.ylabel('SUNACTIVITY')
9 plt.show()
八.未来数据预测
进行未来某几期的数据预测,steps=2表示要预测未来两期, alpha=0.05表示预测的未来数据的95%的置信区间。预测结果仍需进行反向差分运算。
1 print('-------------------------------------------')
2 # 进行三步预测,并输出95%置信区间
3 steps=3 #未来三期预测
4 forecast= model.get_forecast(steps=steps)
5 table=pd.DataFrame(forecast.summary_frame())
6
7 # print(table.iloc[1])
8 table.iloc[0]=table.iloc[0]+t_s[-1]
9 # print(table.iloc[0, 0])
10 for i in range(steps-1):
11 table.iloc[i+1]=table.iloc[i+1]+table.iloc[i, 0]
12 print(table)

Python完整代码:


import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.graphics.tsaplots import plot_acf,plot_pacf #ACF与PACF
import statsmodels.tsa.stattools as ts #adf检验
from statsmodels.tsa.arima.model import ARIMA #ARIMA模型
from statsmodels.graphics.api import qqplot #qq图
from statsmodels.stats.diagnostic import acorr_ljungbox as lb_test #用于LingBox随机性检验 plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False df=pd.read_excel('M17.xlsx')
print(df["水位"].head()) # 创建一个DatetimeIndex对象,指定时间范围为2021年1月1日到1月5日
dates = pd.date_range(start='1860-01-01', end='1955-12-31',freq='AS')
# 创建一个Series对象,将列表作为数据,DatetimeIndex对象作为索引
t_s = pd.Series(data=df["水位"].tolist(), index=dates)
t_s.index = t_s.index.strftime('%Y') #时序图
plt.plot(df['年份'],df['水位'])
plt.xlabel("年份")
plt.ylabel("水位")
plt.show() #纯随机性检验(白噪声检验)
#Ljung-Box 检验,LB检验,用来做纯随机性检验的,单位根检验也属于
print('-------------------------------------------')
print("随机性检验:",'\n',lb_test(df["水位"], return_df=True,lags=5))
# 进行ADF检验
result = ts.adfuller(df['水位'])
# 输出ADF结果
print('-------------------------------------------')
print('ADF检验结果:')
print('ADF Statistic: %f' % result[0])
print('p-value: %f' % result[1])
print('Lags Used: %d' % result[2])
print('Observations Used: %d' % result[3])
print('Critical Values:')
for key, value in result[4].items():
print('\t%s: %.3f' % (key, value)) ##### 差分运算
def diff(timeseries):
new_df=timeseries.diff(periods=1).dropna()#dropna删除NaN
new_df.plot(color='orange',title='diff1')
return new_df
#进行一阶差分
print("============================================================")
ndf=diff(df["水位"])
print(ndf)
# dif = pd.Series(np.diff(df['水位'], n=1))
# print(dif)
#再次进行ADF检验
result2 = ts.adfuller(ndf)
# 输出ADF结果
print('-------------------------------------------')
print('差分后序列的ADF检验结果:')
print('ADF Statistic: %f' % result2[0])
print('p-value: %f' % result2[1])
print('Lags Used: %d' % result2[2])
print('Observations Used: %d' % result2[3])
print('Critical Values:')
for key, value in result2[4].items():
print('\t%s: %.3f' % (key, value)) #模型选择与定阶
#模型选择:绘制ACF与PACF,即自相关图和偏自相关图
#### 绘制ACF与PACF的图像
def plot_acf_pacf(timeseries): #利用ACF和PACF判断模型阶数
plot_acf(timeseries,lags=timeseries.shape[0]%2) #延迟数
plot_pacf(timeseries,lags=timeseries.shape[0]%2)
plt.show()
plot_acf_pacf(ndf) #迭代调优
print('-------------------------------------------')
#AIC
timeseries=ndf
AIC=sm.tsa.stattools.arma_order_select_ic(timeseries,max_ar=4,max_ma=4,ic='aic')['aic_min_order']
#BIC
BIC=sm.tsa.stattools.arma_order_select_ic(timeseries,max_ar=4,max_ma=4,ic='bic')['bic_min_order']
print('the AIC is{}\nthe BIC is{}\n'.format(AIC,BIC)) #模型构建
print('-------------------------------------------')
model= ARIMA(ndf, order=(1, 1, 2)).fit()
print(model.params)
print(model.summary()) #残差检验:检验残差是否服从正态分布,画图查看,然后检验
#残差图
model.resid.plot(figsize=(10,3))
plt.show()
#进行Jarque-Bera检验
print('-------------------------------------------')
jb_test = sm.stats.stattools.jarque_bera(model.resid)
print('Jarque-Bera test:')
print('JB:', jb_test[0])
print('p-value:', jb_test[1])
print('Skew:', jb_test[2])
print('Kurtosis:', jb_test[3]) # 进行Ljung-Box检验
print('-------------------------------------------')
lb_test= sm.stats.diagnostic.acorr_ljungbox(model.resid, return_df=True,lags=5)
print('Ljung-Box test:','\n',lb_test) # 进行DW检验
print('-------------------------------------------')
dw_test = sm.stats.stattools.durbin_watson(model.resid)
print('Durbin-Watson test:')
print('DW:', dw_test) #QQ图看正态性
qqplot(model.resid, line="q", fit=True)
plt.show() #模型预测
print('-------------------------------------------')
predict= model.predict(1,95)#dynamic=True)
# print('模型预测:','\n',predict)
#反向差分运算
# 对差分后的时间序列进行逆差分运算,两个参数:差分数据序列和原始数据序列
def inverse_diff(diff_series, original_series):
inverted = []
prev = original_series.iloc[0]
for val in diff_series:
current = val + prev
inverted.append(current)
prev = current
return pd.Series(inverted, index=original_series.index[1:])
n_predict=inverse_diff(predict,t_s)
print('模型预测:','\n',n_predict) # #画图
plt.figure(figsize=(10,4))
plt.plot(t_s.index,t_s,label='actual')
plt.plot(predict.index,n_predict,label='predict')
plt.xticks([])
plt.legend(['actual','predict'])
plt.xlabel('time(year)')
plt.ylabel('SUNACTIVITY')
plt.show() print('-------------------------------------------')
# 进行三步预测,并输出95%置信区间
steps=3 #未来三期预测
forecast= model.get_forecast(steps=steps)
table=pd.DataFrame(forecast.summary_frame()) # print(table.iloc[1])
table.iloc[0]=table.iloc[0]+t_s[-1]
# print(table.iloc[0, 0])
for i in range(steps-1):
table.iloc[i+1]=table.iloc[i+1]+table.iloc[i, 0]
print(table)
Python的完整包装之后的库:
1 import numpy as np
2 import pandas as pd
3 import matplotlib.pyplot as plt
4 import statsmodels.api as sm
5 from statsmodels.graphics.tsaplots import plot_acf,plot_pacf #ACF与PACF
6 import statsmodels.tsa.stattools as ts #adf检验
7 from statsmodels.tsa.arima.model import ARIMA #ARIMA模型
8 from statsmodels.graphics.api import qqplot #qq图
9 from statsmodels.stats.diagnostic import acorr_ljungbox as lb_test #用于LingBox随机性检验
10
11 plt.rcParams['font.sans-serif'] = ['SimHei']
12 plt.rcParams['axes.unicode_minus'] = False
13
14 class Time_ARIMA():
15 def __init__(self,path):
16 try:
17 self.df = pd.read_csv(path)
18 except:
19 self.df=pd.read_excel(path)
20 # print(self.df.iloc[:,0])
21 start=str(self.df.iloc[0,0])+'-01-01'
22 end=str(self.df.iloc[-1,0])+'-01-01'
23 # 创建一个DatetimeIndex对象,指定时间范围为2021年1月1日到1月5日
24 dates = pd.date_range(start=start, end=end, freq='AS')
25 # 创建一个Series对象,将列表作为数据,DatetimeIndex对象作为索引
26 self.t_s = pd.Series(data=self.df.iloc[:,1].tolist(), index=dates)
27 self.t_s.index = self.t_s.index.strftime('%Y')
28 # print(self.t_s)
29 self.timeseries=None
30 self.flag=0
31 self.BIC=None
32 self.model=None
33
34 def Timing_Diagram(self):
35 # 时序图
36 plt.plot(self.t_s)
37 plt.xlabel(self.df.iloc[:,0].name)
38 plt.xticks(np.arange(0,self.df.shape[0], step=10)) #设置横坐标间距
39 plt.ylabel(self.df.iloc[:,1].name)
40 plt.show()
41
42 def Diff_pre_sequence_test(self):
43 # 纯随机性检验(白噪声检验)
44 # Ljung-Box 检验,LB检验,用来做纯随机性检验的,单位根检验也属于
45 print('==================原始序列的纯随机性检验==================')
46 print("Ljung-Box检验:", '\n', lb_test(self.df.iloc[:,1], return_df=True, lags=5))
47 # 进行ADF检验
48 result = ts.adfuller(self.df.iloc[:,1])
49 # 输出ADF结果
50 print('---------------------ADF检验结果----------------------')
51 print('ADF Statistic: %f' % result[0])
52 print('p-value: %f' % result[1])
53 print('Lags Used: %d' % result[2])
54 print('Observations Used: %d' % result[3])
55 print('Critical Values:')
56 for key, value in result[4].items():
57 print('\t%s: %.3f' % (key, value))
58 print('====================================================')
59
60 def Diff_operation(self,timeseries=None):
61 try:
62 #二阶及以上差分
63 ndf = timeseries.diff(periods=1).dropna() # dropna删除NaN
64 except:
65 #一阶差分
66 ndf = self.t_s.diff(periods=1).dropna() # dropna删除NaN
67 ndf.plot(color='orange', title='残差图')
68 self.flag+=1
69 self.timeseries=ndf
70 print(self.flag)
71 return ndf
72
73 def Diff_after_sequence_testing(self):
74 # 再次进行ADF检验
75 if self.flag==0:
76 print("未进行差分运算,不必再次进行ADF检验")
77 else:
78 result2 = ts.adfuller(self.timeseries)
79 # 输出ADF结果
80 print('------------差分后序列的ADF检验结果------------')
81 print('ADF Statistic: %f' % result2[0])
82 print('p-value: %f' % result2[1])
83 print('Lags Used: %d' % result2[2])
84 print('Observations Used: %d' % result2[3])
85 print('Critical Values:')
86 for key, value in result2[4].items():
87 print('\t%s: %.3f' % (key, value))
88
89
90 def ACF_and_PACF(self):
91 # 绘制ACF与PACF的图像,利用ACF和PACF判断模型阶数
92 # print(int(self.t_s.shape[0]/2))
93 if self.flag == 0:
94 plot_acf(self.t_s, lags=int(self.t_s.shape[0] / 2) - 1) # 延迟数
95 plot_pacf(self.t_s, lags=int(self.t_s.shape[0] / 2) - 1)
96 plt.show()
97 else:
98 plot_acf(self.timeseries, lags=int(pd.Series(self.timeseries).shape[0] / 2 - 1)) # 延迟数
99 plot_pacf(self.timeseries, lags=int(pd.Series(self.timeseries).shape[0] / 2 - 1))
100 plt.show()
101
102 def Model_order_determination(self):
103 # 迭代调优
104 if self.flag==0:
105 timeseries=self.t_s
106 else:
107 timeseries=self.timeseries
108 # AIC
109 AIC = sm.tsa.stattools.arma_order_select_ic(timeseries, max_ar=4, max_ma=4, ic='aic')['aic_min_order']
110 # BIC
111 BIC = sm.tsa.stattools.arma_order_select_ic(timeseries, max_ar=4, max_ma=4, ic='bic')['bic_min_order']
112 print('---AIC与BIC准则定阶---')
113 print('the AIC is{}\nthe BIC is{}\n'.format(AIC, BIC),end='')
114 print('--------------------')
115 self.BIC=BIC
116
117 def Model_building(self):
118 if self.flag==0:
119 timeseries=self.t_s
120 else:
121 timeseries=self.timeseries
122 model = ARIMA(timeseries, order=(self.BIC[0], self.flag, self.BIC[1])).fit()
123 print('--------参数估计值-------')
124 print(model.params)
125 print(model.summary())
126 self.model=model
127
128 def Model_building_artificial(self,order=(0,0,0)):
129 if self.flag==0:
130 timeseries=self.t_s
131 else:
132 timeseries=self.timeseries
133 model = ARIMA(timeseries, order=order).fit()
134 print('--------参数估计值-------')
135 print(model.params)
136 print(model.summary())
137 self.model = model
138
139 def Model_checking(self):
140 # 残差检验:检验残差是否服从正态分布,画图查看,然后检验
141 # 残差图
142 self.model.resid.plot(figsize=(10, 3))
143 plt.title("残差图")
144 plt.show()
145
146 # 进行Jarque-Bera检验
147 jb_test = sm.stats.stattools.jarque_bera(self.model.resid)
148 print("==================================================")
149 print('------------Jarque-Bera检验-----------')
150 print('Jarque-Bera test:')
151 print('JB:', jb_test[0])
152 print('p-value:', jb_test[1])
153 print('Skew:', jb_test[2])
154 print('Kurtosis:', jb_test[3])
155
156 # 进行Ljung-Box检验
157 lb_test = sm.stats.diagnostic.acorr_ljungbox(self.model.resid, return_df=True, lags=5)
158 print('------------Ljung-Box检验-------------')
159 print('Ljung-Box test:', '\n', lb_test)
160
161 # 进行DW检验
162 dw_test = sm.stats.stattools.durbin_watson(self.model.resid)
163 print('---------------DW检验----------------')
164 print('Durbin-Watson test:')
165 print('DW:', dw_test)
166 print("==================================================")
167
168 # QQ图看正态性
169 qqplot(self.model.resid, line="q", fit=True)
170 plt.title("Q-Q图")
171 plt.show()
172
173 def Model_prediction_accuracy(self):
174 # 模型预测
175 if self.flag==0:
176 n_predict = self.model.predict(1, self.t_s.shape[0])
177 print('模型预测:', '\n', n_predict)
178 else:
179 # 反向差分运算
180 # 对差分后的时间序列进行逆差分运算,两个参数:差分数据序列和原始数据序列
181 def inverse_diff(diff_series, original_series):
182 inverted = []
183 prev = original_series.iloc[0]
184 for val in diff_series:
185 current = val + prev
186 inverted.append(current)
187 prev = current
188 return pd.Series(inverted, index=original_series.index[1:])
189
190 predict = self.model.predict(1, pd.Series(self.timeseries).shape[0])
191 n_predict = inverse_diff(predict, self.t_s)
192 print('模型预测:', '\n',n_predict)
193 print('-------------------------------------------')
194
195 # #画图
196 plt.figure(figsize=(10, 4))
197 plt.plot(self.t_s.index, self.t_s, label='actual')
198 plt.plot(n_predict.index, n_predict, label='predict')
199 # plt.xticks([])
200 plt.xticks(np.arange(0, self.df.shape[0], step=10)) # 设置横坐标间距
201 plt.legend(['actual', 'predict'])
202 plt.xlabel('time(year)')
203 plt.ylabel('SUNACTIVITY')
204 plt.title("真实值与预测值对比")
205 plt.show()
206
207 def Future_prediction(self,steps=2):
208 # 进行三步预测,并输出95%置信区间
209
210 # steps = 3 # 未来三期预测
211 forecast = self.model.get_forecast(steps=steps)
212 table = pd.DataFrame(forecast.summary_frame())
213
214 # print(table.iloc[1])
215 table.iloc[0] = table.iloc[0] + self.t_s[-1]
216 # print(table.iloc[0, 0])
217 for i in range(steps - 1):
218 table.iloc[i + 1] = table.iloc[i + 1] + table.iloc[i, 0]
219 table.index = table.index.strftime('%Y')
220 print('--------------------------------------------------------------')
221 print(table)
222 print('--------------------------------------------------------------')
TARMA
对应的调用方式:
1 import TARMA
2 ts=TARMA.Time_ARIMA(path='./M17.xlsx') #实例化对象(放入文件路径)
3 ts.Timing_Diagram() #时序图
4 ts.Diff_pre_sequence_test() #纯随机性检验
5 # 进行一阶差分
6 ts.Diff_operation() #进行一阶差分,当ADF检验合适即平稳且非白噪声序列不进行差分
7 ts.Diff_after_sequence_testing() #差分运算后的ADF检验
8 ts.ACF_and_PACF() #自相关图与偏自相关图
9
10 ts.Model_order_determination() #根据AIC准则与BIC准则进行机器定阶
11
12 #下面两种定阶方式二选一
13 ts.Model_building_artificial(order=(1,1,2)) #模型构建(人工定阶),order中的三个参数为p,d,q
14 # ts.Model_building_machine() #模型构建(基于机器自己定阶)
15
16 ts.Model_checking() #模型检验
17 ts.Model_prediction_accuracy() #模型可行性预测
18 ts.Future_prediction(steps=3) #未来数据预测默认为两期,steps参数可自定义
test
用Python语言进行时间序列ARIMA模型分析的更多相关文章
- 基于R语言的时间序列指数模型
时间序列: (或称动态数列)是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列.时间序列分析的主要目的是根据已有的历史数据对未来进行预测.(百度百科) 主要考虑的因素: 1.长期趋势(Lon ...
- 基于Python的信用评分卡模型分析(二)
上一篇文章基于Python的信用评分卡模型分析(一)已经介绍了信用评分卡模型的数据预处理.探索性数据分析.变量分箱和变量选择等.接下来我们将继续讨论信用评分卡的模型实现和分析,信用评分的方法和自动评分 ...
- 时间序列ARIMA模型
时间序列ARIMA模型 1.数据的平稳性与差分法 让均值和方差不发生明显的变化(让数据变平稳),用差分法 2.ARIMA模型-----差分自回归平均移动模型 求解回归的经典算法:最大似然估计.最小二乘 ...
- 时间序列 ARIMA 模型 (三)
先看下图: 这是1986年到2006年的原油月度价格.可见在2001年之后,原油价格有一个显著的攀爬,这时再去假定均值是一个定值(常数)就不太合理了,也就是说,第二讲的平稳模型在这种情况下就太适用了. ...
- 基于Python的信用评分卡模型分析(一)
信用风险计量体系包括主体评级模型和债项评级两部分.主体评级和债项评级均有一系列评级模型组成,其中主体评级模型可用“四张卡”来表示,分别是A卡.B卡.C卡和F卡:债项评级模型通常按照主体的融资用途,分为 ...
- ARIMA模型
ARIMA模型(英语:Autoregressive Integrated Moving Average model),差分整合移动平均自回归模型,又称整合移动平均自回归模型(移动也可称作滑动),时间序 ...
- java web应用调用python深度学习训练的模型
之前参见了中国软件杯大赛,在大赛中用到了深度学习的相关算法,也训练了一些简单的模型.项目线上平台是用java编写的web应用程序,而深度学习使用的是python语言,这就涉及到了在java代码中调用p ...
- 用python做时间序列预测九:ARIMA模型简介
本篇介绍时间序列预测常用的ARIMA模型,通过了解本篇内容,将可以使用ARIMA预测一个时间序列. 什么是ARIMA? ARIMA是'Auto Regressive Integrated Moving ...
- 基于R语言的ARIMA模型
A IMA模型是一种著名的时间序列预测方法,主要是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型.ARIMA模型根据原序列是否平稳以及 ...
- ARIMA模型——本质上是error和t-?时刻数据差分的线性模型!!!如果数据序列是非平稳的,并存在一定的增长或下降趋势,则需要对数据进行差分处理!ARIMA(p,d,q)称为差分自回归移动平均模型,AR是自回归, p为自回归项; MA为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数
https://www.cnblogs.com/bradleon/p/6827109.html 文章里写得非常好,需详细看.尤其是arima的举例! 可以看到:ARIMA本质上是error和t-?时刻 ...
随机推荐
- scrapy框架中的pipelines没有成功调用process_item方法
提示报错 原因: items没有接收到Spider的返回值,导致pipelines没有接收到items模块的返回值,检查Spider模块是否正确返回值,我这里的原因是,数据解析完成后没有yield i ...
- 实验七:基于REST API的SDN北向应用实践
(一)基本要求 编写Python程序,调用OpenDaylight的北向接口实现以下功能 (1) 利用Mininet平台搭建下图所示网络拓扑,并连接OpenDaylight: (2) 下发指令删除s1 ...
- Log4j日志框架使用
Log4j是Apache下的一款开源的日志框架,能够满足我们在项目中对于日志记录的需求.一般来讲,在项目中,我们会结合slf4j和log4j一起使用.Log4j提供了简单的API调用,强大的日志格式定 ...
- c/c++指针从浅入深介绍——基于数据内存分配的理解(上)
c/c++指针从浅入深介绍--基于数据内存分配的理解(上) 本文是对自我学习的一个总结以及回顾,文章内容主要是针对代码中的数据在内存中的存储情况以及存储中数值的变化来对指针进行介绍,是对指针以及数据在 ...
- ovs-dpdk:revalidator源码解析
revalidator是做什么的?需要知道哪些东西? 有关于revalidator需要弄明白的是以下三个问题: 通过ovs-vsctl list open_vs可以看到other_config里面有两 ...
- Linux 命令之 tar 操作符
tar -c: 建立压缩档案 -x:解压 -t:查看内容 -r:向压缩归档文件末尾追加文件 -u:更新原压缩包中的文件 这五个是独立的命令,压缩解压都要用到其中一个,可以和别的命令连用但只能用其中一个 ...
- return、break与continue的区别
前言 在上一篇文章中,壹哥给大家介绍了while.do-while两种循环结构,并且给大家总结了两种循环的区别.实际上,我们在利用循环执行重复操作的过程中,还存在着另一个需求:如何中止,或者说提前结束 ...
- MapReduce之简单的数据清洗----课堂测试
今天的课堂测试第一步是做简单的数据清洗,直到现在我才知道只是把文本文件的数据改成相应的格式,而我做的一直是寻找一条数据,并转换成相应的格式,但是呢,我感觉还是很高兴的,虽然没有按时完成任务,但也学到了 ...
- Terraform 系列-Terraform 项目的典型文件布局
系列文章 Terraform 系列文章 典型文件布局 - modules/ - services/ - webserver-cluster/ - examples/ - main.tf - outpu ...
- 一些随笔 No.2
数据库 单表VS多表联合 多表联合查询的优势区域在于敏捷开发,主要用于过于庞大却可拆分的储存需求 但是劣势也很明显:更多的查询约束条件会用掉数据库服务器额外的cpu/内存/io,也不方便更未来的分布式 ...