[数据结构1.2-线性表] 动态数组ArrayList(.NET源码学习)
[数据结构1.2-线性表] 动态数组ArrayList(.NET源码学习)
在C#中,存在常见的九种集合类型:动态数组ArrayList、列表List、排序列表SortedList、哈希表HashTable、栈Stack、队列Queue、链表LinkedList、字典Dictionary、点列阵BitArray。本文将基于动态数组ArrayList,从源码的角度出发,分析其内部定义以及常用方法的实现。
【# 请先阅读注意事项】
【注:(1)以下提到的复杂度仅为算法本身,不计入算法之外的部分(如,待排序数组的空间占用)且时间复杂度为平均时间复杂度 。
(2)除特殊标识外,测试环境与代码均为.NET 6/C# 。
(3)默认情况下,所有解释与用例的目标数据均为升序。
(4)默认情况下,图片与文字的关系:图片下方,是该幅图片的解释。
(5)本文内容基本为本人理解所得,可能存在较多错误,欢迎指出并提出意见,请见谅。】
一、ArrayList的实现
(一) 构造函数
该数据结构有三种构造方法。即,三种初始化的方法:

创建一个(当前容量为0)空的Array对象。
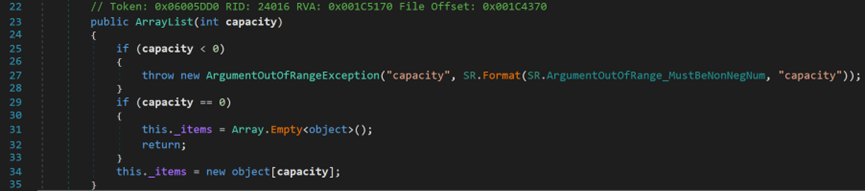
创建一个有大小的空的Array对象。

将某个非空集合转换为ArrayList类型。
从这三个构造方法可以初步得出以下结论:
1. 字段_items储存了动态集合本身。
2. 动态集合对象的创建调用的是Array中的方法,所以其本质依旧属于数组。
3. 动态集合的容量必须大于等于0;传入的其他集合不能为空,但长度可为0。
4. 有关AddRange()方法:

根据上方推断出的_items,可知此处的_size指的是ArrayList的当前长度。可以发现,该方法的作用是在原动态数组的某一特定位置,插入新数据集。

- Line 420~427:当待插入集合为空 或 插入起始索引非法时,抛出异常。
- Line 428、429:当且仅当待插入数据集长度大于0时,执行插入。

- Line 431:EnsureCapacity()方法的作用是,若当前容量为0,则初始化为4;否则以每次乘2的增长幅度,扩展当前容量。
- Line 432~440:利用Array中的Copy()方法,该方法在文章([数据结构1.1-线性表] 数组 (.NET源码学习) - PaperHammer - 博客园 (cnblogs.com))中有较详细的解释。
注意,AddRange()方法和InsertRange()方法均可被调用,前者是在动态集合末尾加上新的数据集;后者可在任意合法位置插入新数据集。但AddRange()方法也调用的是InsertRange()方法,正是因为有Line 432行的if语句。
(1)当调用AddRange()方法时,传入的index就是_size,所以此时不执行if语句内的内容。直接创建一个新数组array,将新数据集存入其中,再把该数组拼接到原动态数组的末尾。
(2)当调用InsertRange()方法时,若待插入数据集长度大于等于_size,则为情况(1),不执行if内的语句;待插入数据长度小于ArrayList的长度时(index < _size),从索引index开始,将原本在ArrayList中的数据向后移动,保证从index开始足够插入新的数据。
(二) 字段与属性
1. 三个私有字段:

其中,_items表示动态数组本身;_size表示动态数组当前存储的元素数;_version表示当前动态集合的版本号,在执行某些操作后,会使版本号+1,所以,理论上对于同一个动态数组这些操作总共只能执行有限次,即int的上限次。这些操作包含:属性(索引器)this[int indxe]、方法Add()、AddRange()、Clear()、Insert()、InsertRange()、Remove()、RemoveAt()、RemoveRange()、Reapt()、Reverse()、SetRange()、Sort()。
2. 七个公共属性:
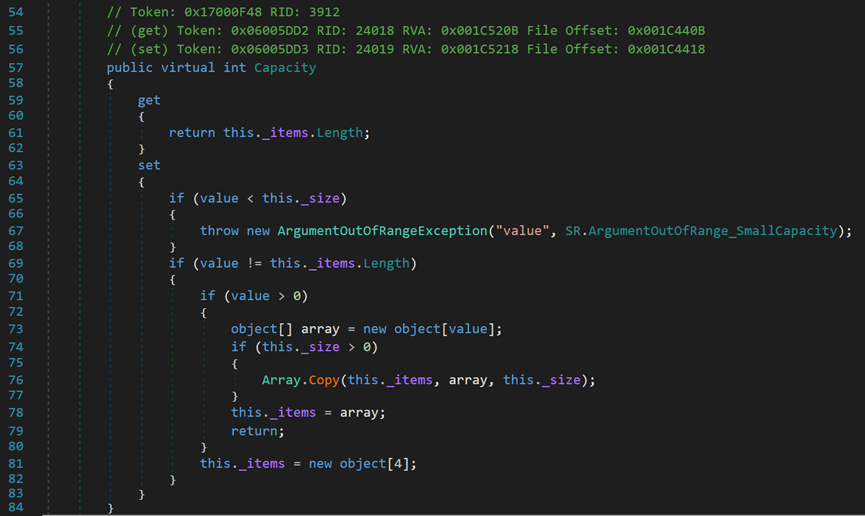
(1)Capacity,读/写,表示当前的容量上限,不是当前储存的元素个数。
- Line 59:get访问器返回的是_items,即动态数组本身的当前容量。
- Line 63:set访问器,用于更改当前容量上限。
- Line 65:value表示外部传入的值。当外部传值(设定的Capacity)小于当前元素个数(非容量)时,抛出异常。
- Line 71、74:若传入的值为正且内部已存在元素时(已初始化的动态数组,在不存放任何值时,Capacity为0),则初始化一个长度为value的数组,将原动态数组中的元素Copy进新数组,再赋值回_items;若传入的值为正但内部不存在元素,即_size为0,则不进行Copy。
- Line 81:某条件下,初始化对象数组为容量为4的数组。
有关Capacity的运行流程参照下图,图片分析过程已逐行标号,若存在问题,欢迎在评论区提出。

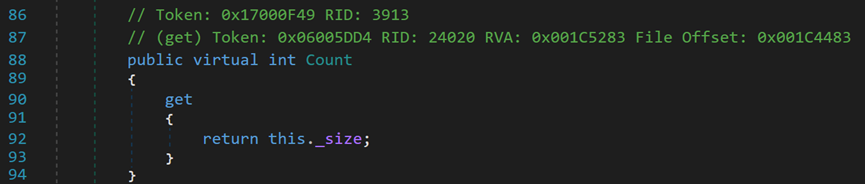
(2)Count,只读,返回当前元素个数。区别于容量Capacity。
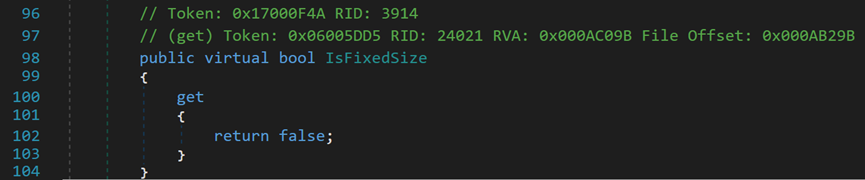
(3)IsFixedSize,只读,指示数组是否具有固定大小。此处默认为false且不可更改,因为要保证其动态性。
若要创建大小固定的动态数组,可以调用静态方法FixedSize()方法,由该方法创建的动态数组不能再添加或移除元素,但是允许修改现有元素。
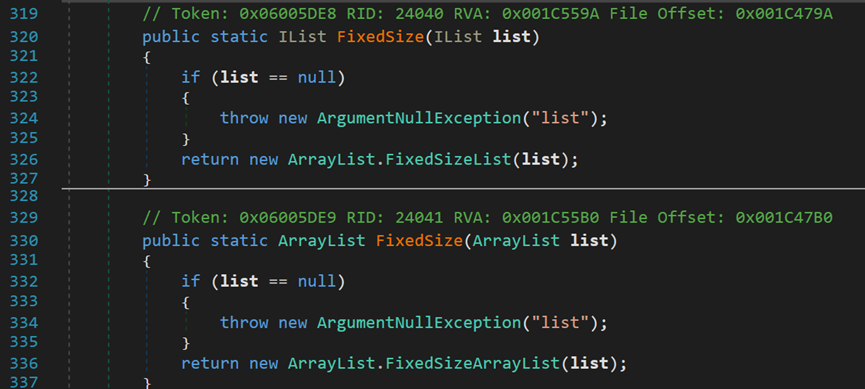

该属性包含在一个新的类FixedSize中,是一个内部类。

(4)IsReadOnly,只读,指示当前对象是否为只读对象。

(5)IsSynchronSized,只读,指示对动态数组的访问是否同步(线程安全)。

(6) SyncRoot,只读,获取可用于同步访问动态数组的对象,即IsSynchronized值为true的动态数组对象。
【(5)、(6)的详细内容将在今后的有关线程的文章中论述】
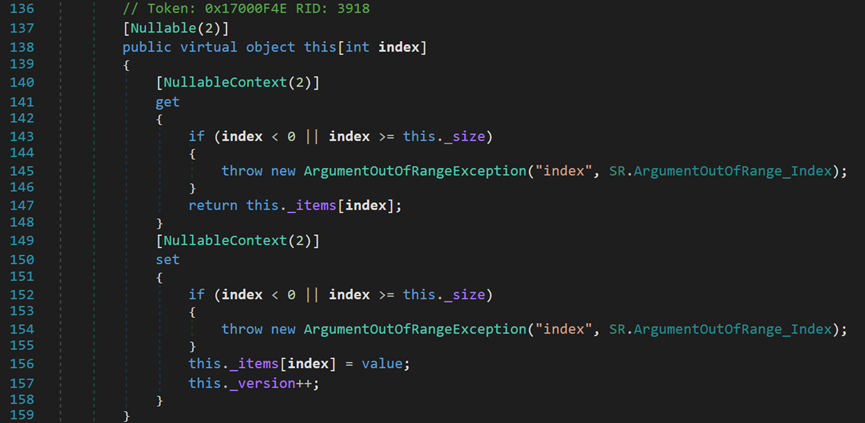
(7)索引器:可以使用索引运算符来访问某个数据结构中的对象。
其中get属性为要返回的对象;set属性用于将对应的元素和索引一一对应,此处的value指代动态数组中的元素。
小结 一
1. 动态数组之所以称为“动态”,是因为其大小可以在程序运行时改变,而不是像Array一样,在初始化时就指明长度大小且不可更改。
2. 动态数组中的Capacity是可以保存的元素数,即容量;Count是实际的元素数。
3. 其内部元素可以为null,可以重复,可以为不同类型;但不能将多维数组作为其元素。

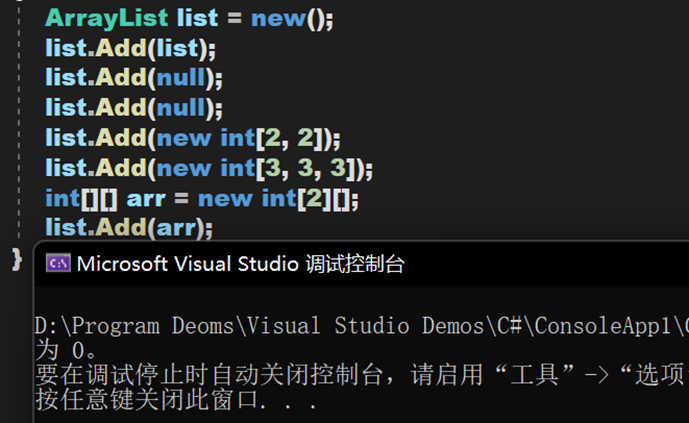
据微软的说法,多维数组不能作为ArrayList的元素,但实测后似乎没有问题,有知道如何理解微软的那句话的学者可以评论交流。
二、ArrayList的常用方法
(一) Add()、AddRange()、Insert()和InsertRange()方法

Add(),公共虚方法,在原动态数组末尾插入单个值。
- Line 8:添加元素时,若当前长度与容量相同,即容量已达上限,则先扩容。
- Line 10:更新索引器的索引。
- Line 11:更新版本号。
- Line 12、13:保存原元素数;将当前元素数+1。
- Line 14:返回值原元素数,等价为末位索引、新加入元素的索引。

AddRange(),公共虚方法,在原动态数组末尾插入新的数据集,其调用的是内部的InsertRange()方法。

InsertRange(),公共虚方法,在某一特定位置插入某一数据集。
- Line 3:index为插入的起始索引/位置。
- Line 5:需要保证待插入的数据集非空。
- Line 9:需要保证指定索引合法。
- Line 14:保证待插入的数据集有元素。
- Line 19:若不插入在末尾,则将一定位置的元素后移,让出足够的位置。
- Line 21~25:将待插入数据复制到新数组中,将新数组的值复制到动态数组的对应位置;更新元素数和版本号。
注意到,该方法内部并未显式更新索引器。原因可能是:此处创建了一个数组,数组本身就是通过索引访问的,将集合c复制给数组,使得集合c内部的元素可由索引访问;将array再复制给动态数组,将数组可由索引访问的特性保留了下来,因此此处无需显式更新索引器。
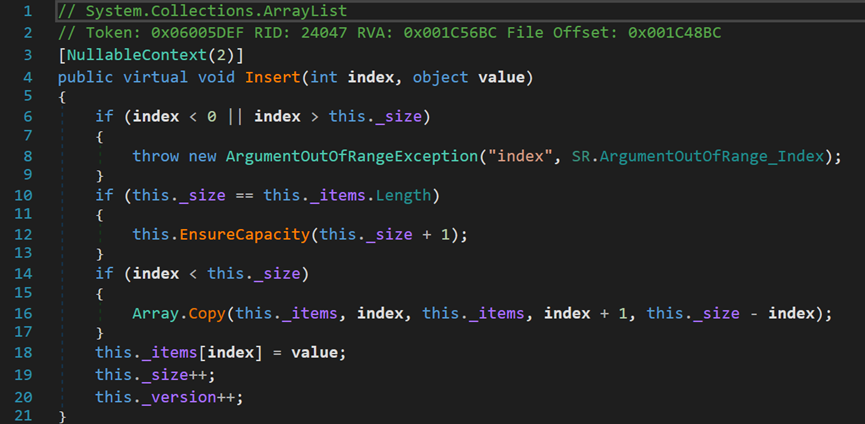
Insert(),公共虚方法,在某一特定位置插入单个数据。
形式和之前的Add()方法相差不大,只是增加了一个特定位置的参数。
(二) BinarySearch()方法
该方法为二分查找法,使用的前提是元素有序。其调用的是Array类中的BinarySearch()方法,用于查找某个元素所在的位置/索引,不存在则返回一个较为特殊的值,后文会提到。
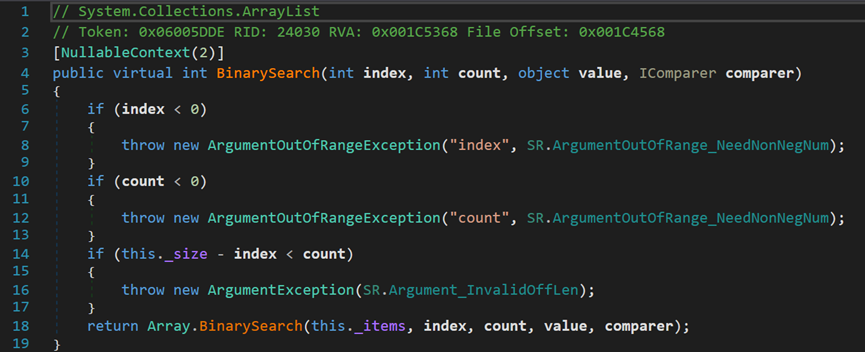
- Line 4:index表示查找的起始索引;count表示查找数量;value表示查找的对象;compare表示比较器对象。
- Line 14:需要保证长度 - 起始索引 = 剩余元素 >= 查找数量。
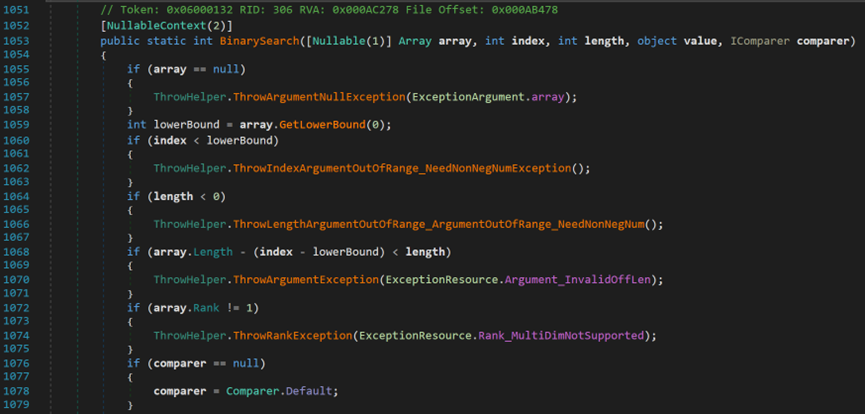
- Line 1059:GetLowerBound()方法和C++中的LowerBound()方法不是同一个用法。此处的GetLowerBound()方法返回的是,数组中指定维度第一个元素的索引;C++中的LowerBound()方法返回的是,集合中从索引0开始,第一个小于等于目标元素的元素索引,不存在返回-1。
- Line 1072:Array.Rank属性,表示数组的维度。

- Line 1080~1082:i表示起始位置;num表示长度;array2表示尝试将array转换为数组类型的数组对象。
- Line 1087:GetMedian()方法返回的是两个数的平均值,即中间值。
- Line 1091:num2存储中间位置元素和value值的大小关系。
- Line 1098~1109:num2 == 0二者相等,直接返回目标元素所在索引;num2 == -1 < 0中间元素小于目标值,则将左界定为 中间位置+1;反之定位 中间位置-1。
- Line1111:若未找到元素,则返回~i。此时的I == num + 1 == index + length,即,搜索区间的长度。其中,运算符 ~ 的作用是将值对应的二进制每位取反。
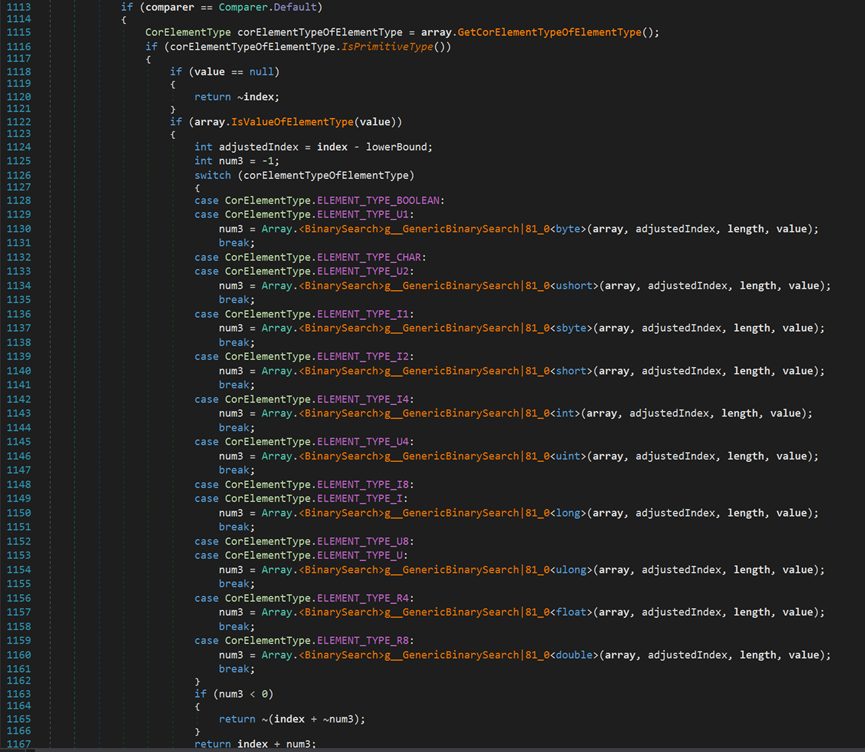
- Line 1116:判断数组中的元素是否为基元类型(.NET类库中默认存在的数据类型)。
- Line 1124:记录需要查找的区间的起始索引。
- Line 1125:nums3记录目标元素在数组中的索引。
之后,根据不同的数据类型,进入到不同到重载方法中进行查找(以下以int为例)
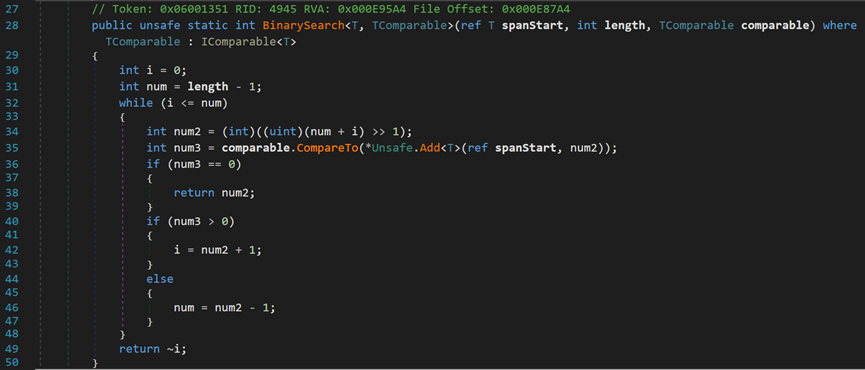
所调用的BinarySearch()方法位于类SpanHelpers中,在比较时运用到了指针,所以方法被标记为unsafe。
- Line 28:spanStart为待查找区间;length为查找长度;comparable为比较器对象。
之后的部分就是熟悉的双指针/折半查找。
进行上述两个过程的前提分别是转换后的array != null和比较器对象为默认值,若都不符合,则进行以下面的方式进行查找。

该方法和第一种成功转换的方法基本一致,只是直接在原数组中进行查找,使用非默认比较器对象。
(三) Clear()方法
【注:对于该方法的源码分析,以下多数内容位推断得出,可能存在较多错误,还请各位大佬指正】
由于动态数组本质还是数组,所以调用的大部分方法均是类Array中的方法。

- Line 8:快刀斩乱麻,执行完Clear()方法后,将_size归零。
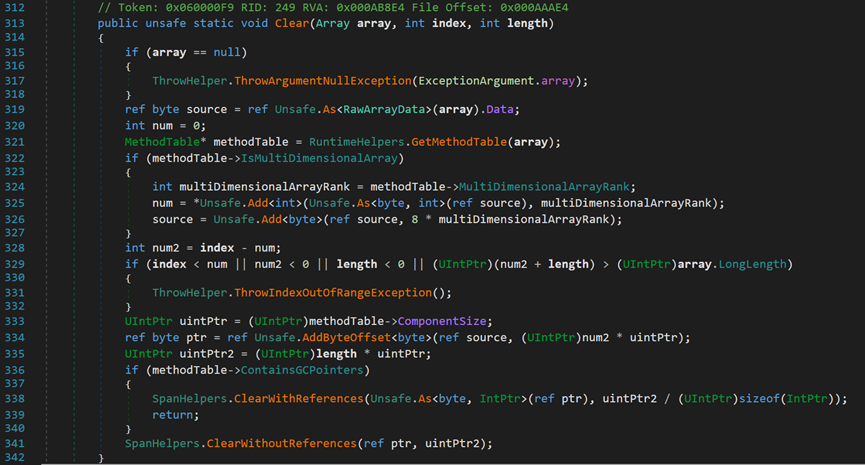
可以发现,一个感觉简单的清除元素的方法,执行起来却较为复杂。
【注:有关Int与IntPtr的区别会在后文提到,可先行转跳查看】
- Line 313:array为待清空数组;index为要清空部分的起始索引;length为要清空的长度。
- Line 319:将对象array强制转换为RawArrayData类型并获取其数据类型所占的字节数,供后面的指针偏移使用。
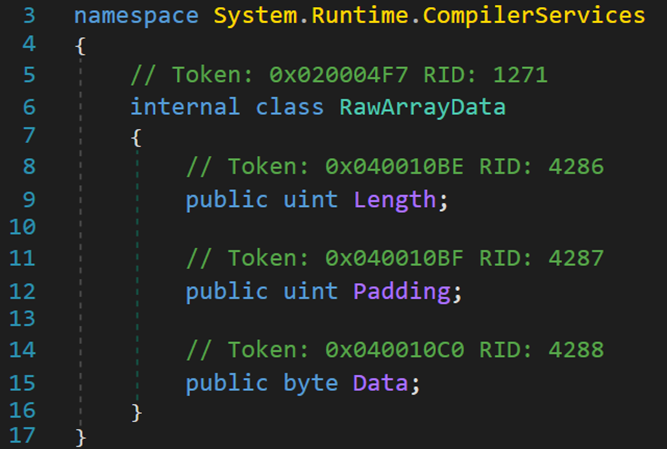
- Line 321:类MethodTable,方法表,内部有一个结构体,包含了7个字段和6个属性。(该类将在后文介绍)
- Line 322:IsMultiDimensionalArray属性,判断传入的对象是否为多维数组。其中,运算符 -> 称为间接引用运算符,用于从某个对象中读取出某个值。
- Line 324:获取多维数组维度。
- Line 325:将int类型的source强制转换为byte类型,并将起始指针向后(偏移)移动。目的是为了重新定位数组的起始索引位置,num中存储的就相当于是数组的起始索引。其中,Unsafe.Add(T, Int32)方法,用于向给定的托管指针添加偏移量。
- Line 326:更新占用的字节总数Unsafe.As<TFrom, TTo>(TFrom)方法,将给定的托管指针重新解释为类型值的新托管指针。
- Line 328:num2 = 清除部分的起始索引 – 数组的起始索引。删除的长度
- Line 329:若 清除部分的起始索引 < 数组的起始索引(等价于num2 < 0) 或 清空的长度 < 0 或 非清空部分的长度 + 清空部分的长度 > 总长度,则抛出异常。
- Line 333:uintPtr表示array内部单个元素所占的字节数。
- Line 334:ptr表示从索引0开始到刚好需要清除的元素起(num2 * unitPtr)所占的字节数,即确定清除起点。
- Line 335:unitPtr2以指针的形式表示需要清除的元素的长度。
【注:关于类Unsafe中的内容会在今后的文章中解释】
- Line 336:判断对象是否包含对于该指针对象的垃圾回收器。在C#中指针分为托管指针(ref,out等)与非托管指针(*,&等),在CLR中,对于非托管对象需要手动进行释放,即手动垃圾回收。
如果运行正常,最终都会进入到SpanHelpers类中的ClearWithReferences()方法。从方法名称上看,可以推断出其不仅删除了集合中的元素,还删除了该集合用于存储元素的引用指向。即,删除了元素和分配给集合存储元素的内存空间位置。
下面是ClearWithReferences()方法
【注:关于ContainsGCPointer,其相关解释仅为推断内容,有待证实】
(1)对于不包含GCPointer的对象,需要自行定义新的清除方法,进入Line 341处的方法:
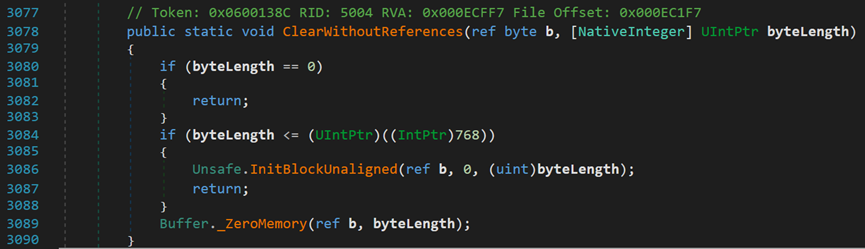
- Line 3078:b表示开始清除的起始位置;byteLength表示清除长度。
- Line 3080:byteLength为0,相当于不清除。
- Line 3084: (UIntPtr)((IntPtr)768)可能表示基于CLR中的某一规则,允许数组一类的数据结构在内存块中占用的某个上限值,若超过该上限则需要调用类Buffer中的_ZeroMemory()方法

该方法获取待清除数组的首地址,之后执行一个扩展方法,需要在外部写一个清除方法,特殊处理;若没有超过上限则执行下面的方法。
- Line 3086:InitBlockUnaligned()方法,在给定位置使用给定的初始值初始化内存块。
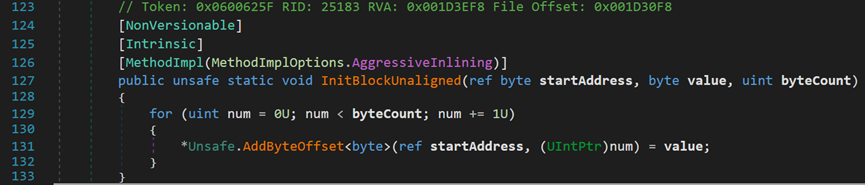

startAddress表示引用要初始化的内存块开头的托管指针;value表示要初始化内存块的所有字节的值;byteCount表示要初始化的字节数。

据微软官方的说法,该方法不用于初始化可供使用的运行内存。那么推测其原理应该是通过重置内存块上的分配信息,以达到清除某数据结构中元素的目的。被重置的内存块将不再被任何结构占用,可再次自由分配。
(2)对于内部包含GCPointer的对象,收到GC的管控,可自行回收,进入Line 338处的方法:

- Line 3093:ip也表示清除的起始位置;pointerSizeLength也表示清除的长度。与刚才方法不同的是,其传入起点的类型为整形指针,而不是byte。
- Line 3095:若删除的长度大于等于8,则每次清除以8为单位,即每次清除8个元素在内存块上的内容及分配信息。
- Line 3107~3117:若删除长度小于等于0,说明删除长度为0(因为其类型为UIntPtr,本质为无符号整型,最小值为0)则不执行任何操作;若删除长度大于0且小于2,说明删除长度为1,则跳转至标记IL_12F处,直接将ip所代表的指针置为0,使得该数组对ip指针对应的内存单元失去所有权;若删除长度大于2且小于4,说明删除长度为3,Line 3125处先将ip后移一位并将其置为0(中间),Line 3126处将ip后移3位再前移一位(末尾),Line 3128处将ip置为0(开头)。
- Line 3118~3124:若删除的长度小于8,则依旧通过指针位移的方式,将其逐一置为0。
通过简要分析可以得出,该方法的时间复杂度位O(n),因为其需要通过指针进行遍历并修改每一个值;空间复杂度为O(n),因为其创建了MethodTable,用于存储传入数组的相关信息。
虽然其较为复杂,但效率且不低,下面将通过对比Clear()方法、新建对象和单纯遍历删除这三种方式的耗时。数据量为10万,进行100万次,由于JIT的特性,第一次启动程序会耗时较高,于是不保留第一次的测试数据。
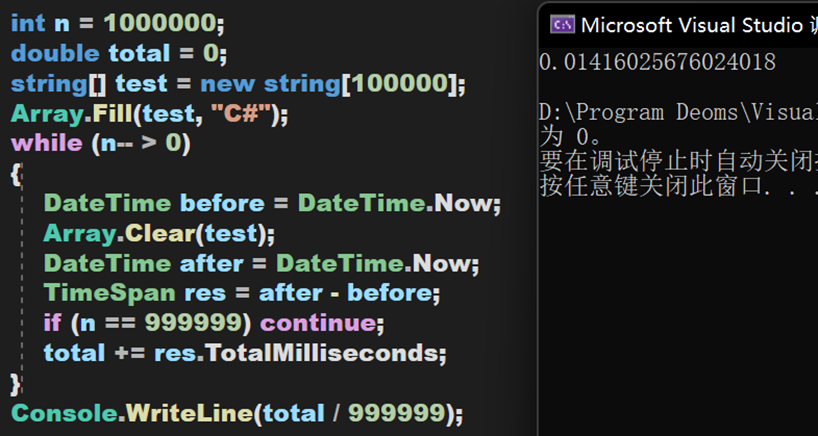
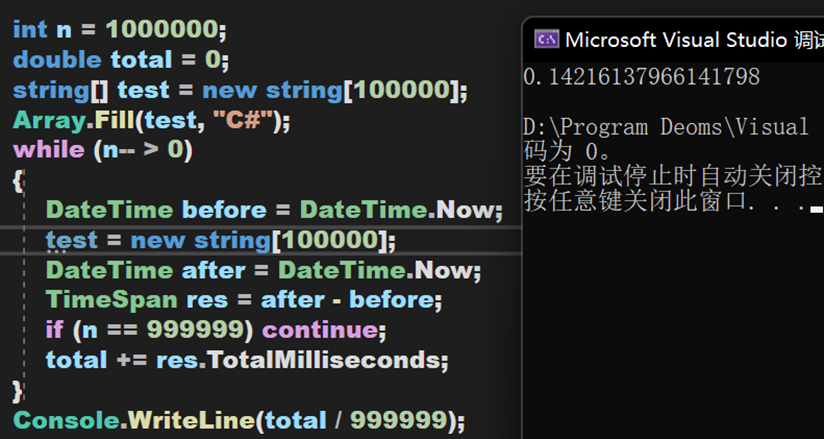
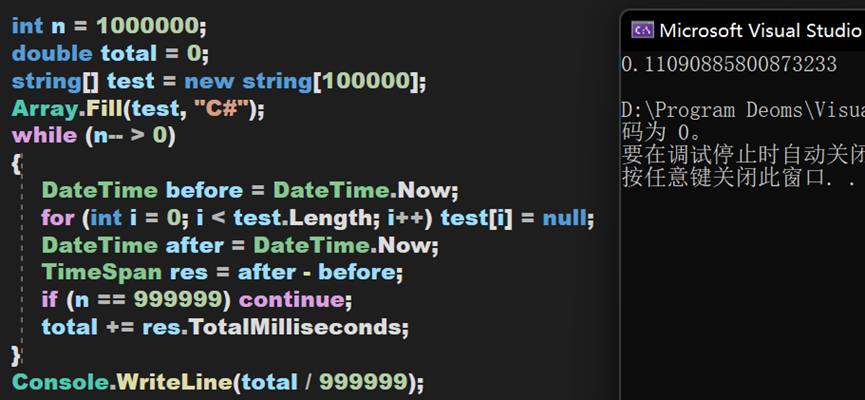
小结 二
(1)在数据量庞大时,Clear()方法能保持较高的效率,其次是手动清除,最后是创建新对象。
(2)在测试string类型前,也跑了一遍int类型,同样的到的类似的结果。不过横向对比可以得出,值类型的清除效率要比引用类型更高。
(3)理论上,从简单的分析可以知道手动清除只是遍历,而创建新对象是在堆与栈中反复读取与写入,所以创建新对象效率比较低。这样的结果或许也得益于CLR等相关架构的优化,具体有关CLR的相关内容,将会在今后专门写文章进行分析。
(4)以下是有关Clear()方法的执行流程简图:【字迹不清,还请见谅】
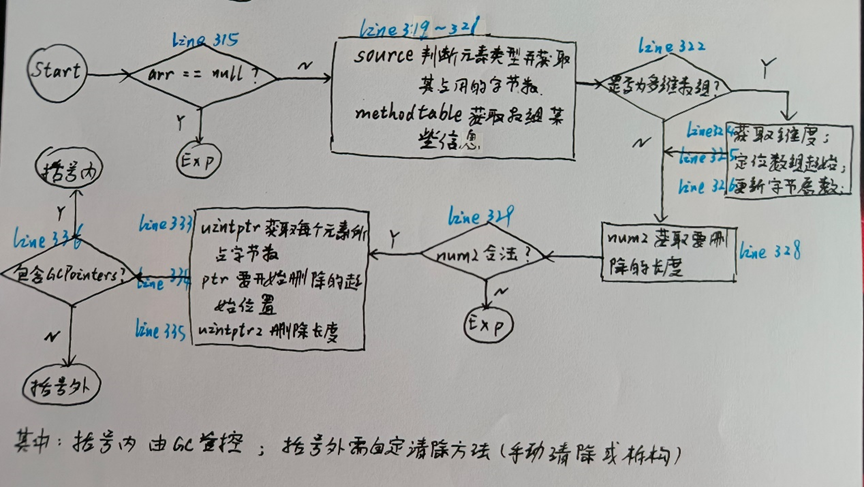
(四) Contains()方法
Contains()方法不论是在动态数组还是在其他线性数据结构中都经常被使用,其实现原理也很简单,就是单纯的遍历数组。时间复杂度O(n),空间复杂度O(1)。
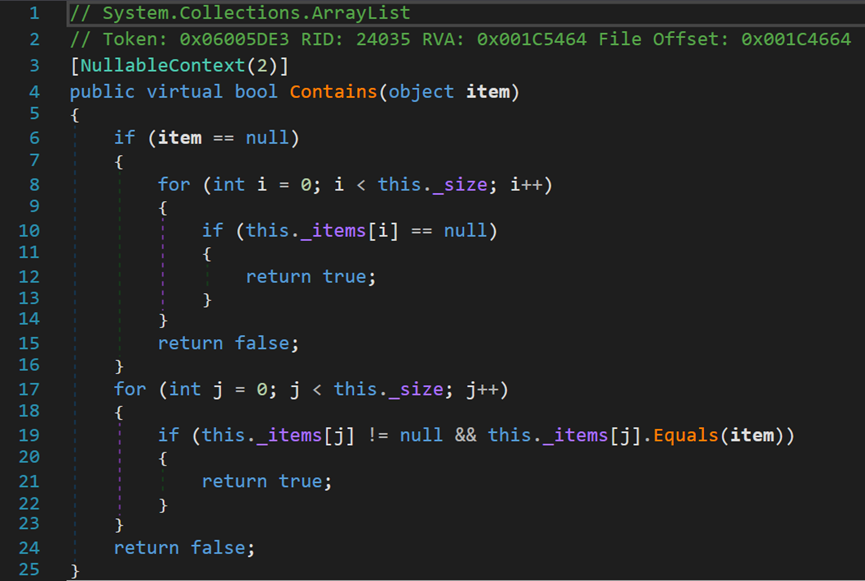
(五) IndexOf()、LastIndexOf()方法
Contains()方法只是查找元素是否包含在集合中,而这两种方法在查找后还将返回元素所在的索引位置。时间复杂度O(n),空间复杂度O(n)。
首先是IndexOf()方法,其从索引0开始,返回第一个与目标值相等的索引。
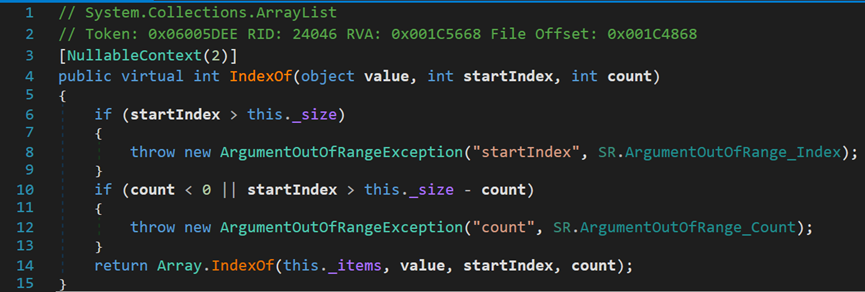
两个if用于判断起始索引是否越界;查找长度是否小于0或以startIndex为起点,查找过程中是否会越界。之后调用类Array中的IndexOf()方法。
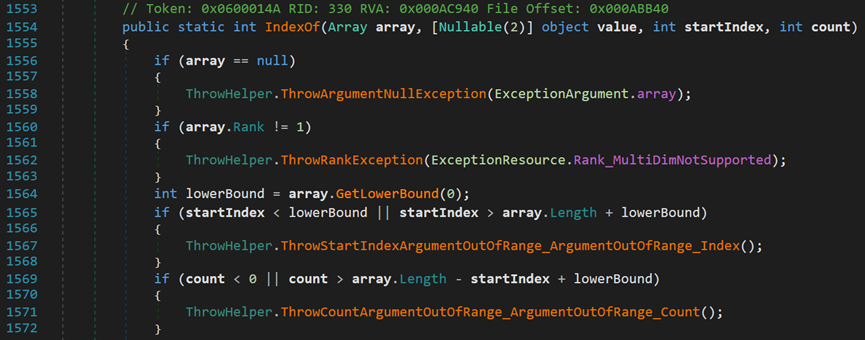
- Line 1554:array为待查找的数组;value为目标值;starIndex为查找的起始索引;count为查找的长度。
- Line 1560:该方法仅适用于一维数组。
- Line 1564:获取数组中指定维度第一个元素的索引。其中,0表示第一维度。即,获取起始索引。
- Line 1565、1569:保证startIndex与count的合法性。
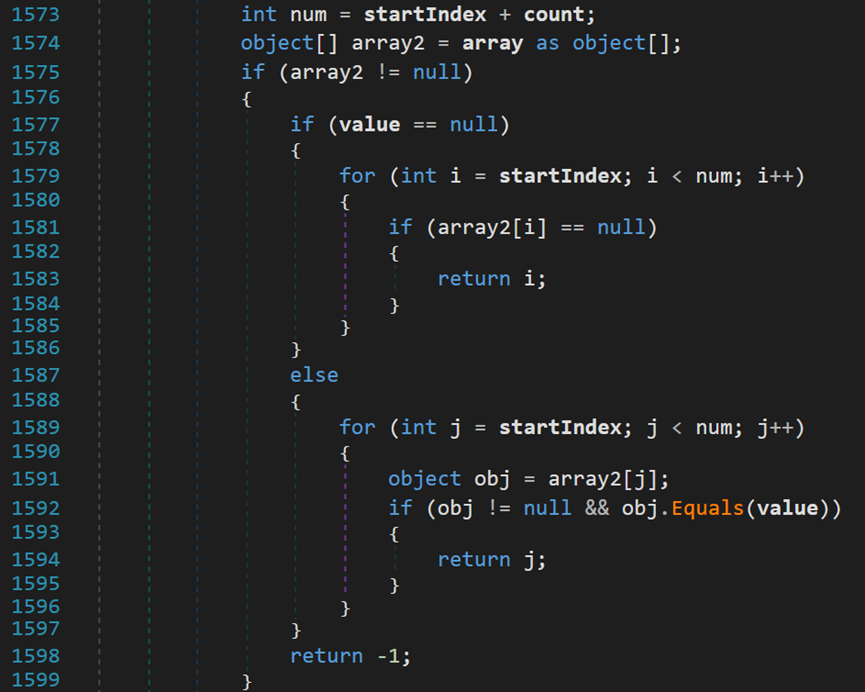
- Line 1573:num表示查找的结束位置。
- Line 1574:尝试将array转换为object类型的数组。
- Line 1575~1599:若转换成功,当value为null时,使用运算符“==”逐项判断,相等则返回索引;当value不为null时,使用Equals()方法逐项判断,相等则返回索引。若在序列中未找到与目标元素相等的值,则返回-1。
其中,等于运算符“==”和Equals()方法的区别,在比较值类型时,均比较在栈中的内容;比较引用类型时,运算符“==”比较的是存放在栈中引用地址,Equals()方法比较的是堆中的内容。

- Line 1600、1601:若转换失败,则获取array的元素的类型。由于可以存储任何类型,所以ArrayList转换为数组后,其类型为object。
- Line 1607:判断value的类型是否与array的类型相同。
- Line 1609:此处的adjustIndex相当于startIndex。
- Line 1611:根据不同的类型,调用不同的查找策略。传入的adjustIndex相当于是将startIndex作为0,开始查找。
- Line 1640:num2用于存储最后的结果。若>=0说明找到了对于的元素,则返回从startIndex开始,向后num2位。即,索引位置;否则没有找到,返回-1。

如果不是基元类型,则取出每一个元素,逐一比较,相等返回索引;没有找到则返回-1。
接下来是LastIndexOf()方法,从方法名上可以推断出,其查找顺序是从后向前。

只看关键部分代码


startIndex为起始索引,向前查找count位,直到num。除此之外,其余均与IndexOf()方法一致。
(六) Reverse()方法
时间复杂度O(n),空间复杂度O(1)。
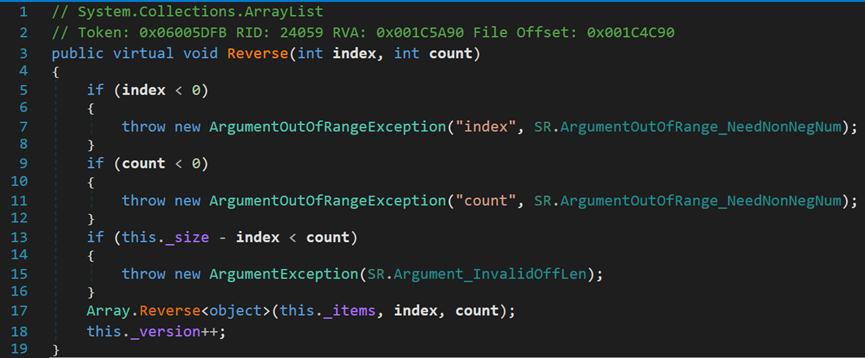

可以发现,其原理是通过交换指针实现的。
- Line 2029:array表示待反转数组;index表示反转的起始索引;length表示反转长度。
- Line 2051:ptr表示要反转的部分的起始索引。即,index索引对应的内存地址。其中,GetArrayDataReference()方法,获取数组的内存地址,据C++中的指针含义,其表示第一个元素的内存地址,&array[0]。通过Unsafe.Add()方法,将指针向后偏移index位。
- Line 2052:ptr2表示要反转部分的末尾索引。即,index+length索引对应的内存地址。将ptr向后偏移length位,再向前偏移1位,指向反转末尾。
- Line 2055~2057:进行内存地址的交换。
- Line 2058~2059:分别将两处的指针向后/前,移动,进行下一次交换。
- Line 2061:直到ptr == ptr2,即,表示同一位置的时候,结束循环,完成交换。
小结 三(有关Array、ArrayList和List)
(1)Array是C#中最早的数据结构,其在内存中是连续存储的,且同索引进行访问及相关操作,有较高的效率。但连续的存储形式,使得其在插入和删除上效率低下,且在声明时需要指定长度,过短会溢出;过长会浪费。
(2)为了弥补数组的缺点,引入了动态数组ArrayList。其本质还是数组,不过是在数组的基础上增加了一定的灵活性,其多数内部方法依旧基于类Array。但继承了IList接口的它,具有灵活的长度,同时不受数据类型的限制,可在一个对象中存储任意类型。但正是因为不受类型的限制,频繁的装箱拆箱操作,导致了一定的性能损耗和不安全性。
(3)随着.NET(以前称为.NET Framework)的发展,又引入了集合List,每个集合具有固定的类型,只能存放相应类型的数据;在内存中不连续;且长度为动态的。可以说兼容了数组和动态集合的优点,因此也成为目前使用最为广泛的数据结构之一。该数据结构在之后的文章中会提到
[# 有关结构体MethodTable(方法表)]
【注:由于关于该结构体的相关资料较少,故以下内容多以推测为主,可能存在较多错误。】

该结构体在命名空间System.Runtime.CompilerServices下,据书籍《Pro .NET Performance》的说法:MethodTable是由一个类的所有方法的相关信息所组成。即,主要用于存储对象的基本信息,在必要时候进行提供。其是一个内部的(internal)结构体,结构体内部包含7个公共的字段和6个公共属性。
先来看7个字段
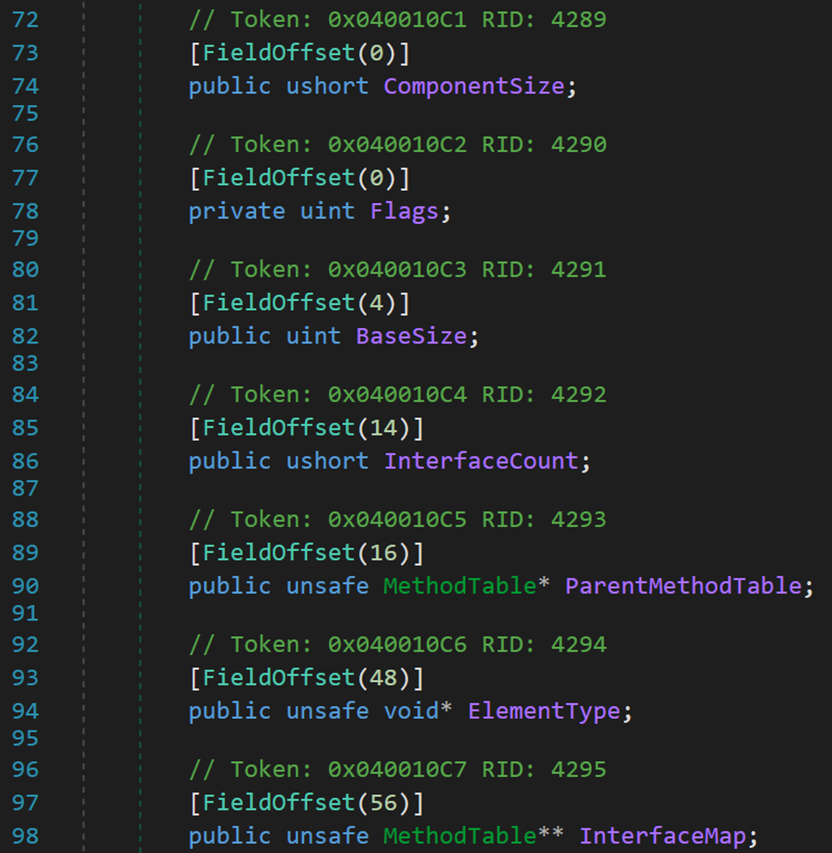
- Line 74:ComponentSize,直译为元件大小,表示内部元素所占的字节数。
- Line 78:Flags,可能用于存储某些标志的共性。
- Line 82:BaseSize,用于存储数组维度的相关信息。
- Line 86:InterfaceCount,据字面意思是表示接口的数量,这里应该是表示继承或派生的接口数。
- Line 90:ParentMethodTable指针,表示指向该类型的父对象。
- Line 94:ElementType,表示对象本身的数据类型。
- Line 98:InterfaceMap,map有图、表的含义。其可能表示和该对象有关的接口关系。
接下来是6个属性

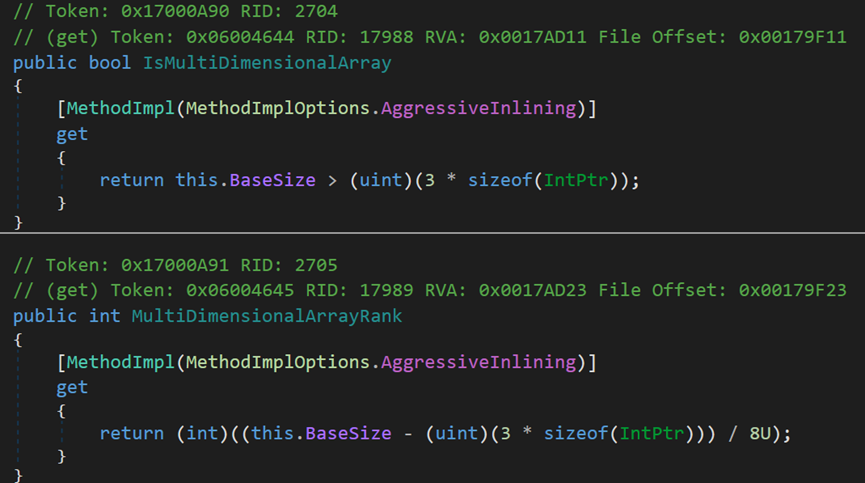
这几个属性均为只读,都反映了对象的一些信息。其中sizeof(IntPtr)的值据程序的位而定,32位值就为4;64位值就为8。
[# 有关数据类型Int与IntPtr]
整两种数据类型均可以称为整型。
对于Int,我们都很熟悉,属于基元类型,带符号的32位整数,默认值位0,十进制运算,-2,147,483,648到2,147,483,647,即-2^31到2^31 – 1。若加上前缀‘u’,则表示无符号类型。
对于IntPtr,表示一个有符号整数,用于表示内存地址。其中位宽度与指针相同,即其所占字节大小与基于其派生出的原类型(Int)大小相同。需要注意的是,此类型的实例应在32位进程中为32位,在64位进程中为64位。该类型可由支持指针的语言使用,并作为引用执行和不支持指针的语言之间的数据的常见方法。基本信息如下:
更多详细信息可参考IntPtr 结构 (System) | Microsoft Docs
总结
(1)ArrayList相较于数组而言具有更高的灵活性和空间利用性,但整体的性能不如泛型集合List<T>。
(2)类ArrayList旨在保存对象的异类集合,因此其通常不能保证排序的有序性和BinarySearch()方法的准确性,这也是整体性能不如泛型集合的主要原因。
(3)由于类ArrayList内部存在一个记录版本version的整型变量,因此其可能存在操作的上限次数。若的确存在,则不适用于当下的大量数据处理和交互的环境下。
(4)ArrayList里传入的实例不能访问到实例的属性,需要进行判断和转型,并赋值给中间变量才能被查看,如下图:
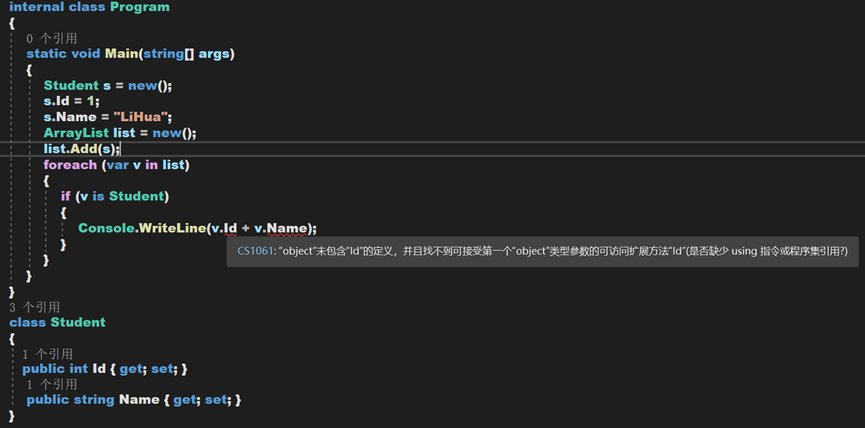
原因是,无论原本是声明类型,进入ArrayList后均被转换为object类型(装箱),要转回原本的类型(拆箱)才可以访问到原本属于自己的东西。
【感谢您可以抽出时间阅读到这里,因个人水平有限,可能存在错误,望各位大佬指正,留下宝贵意见,谢谢!】
[数据结构1.2-线性表] 动态数组ArrayList(.NET源码学习)的更多相关文章
- Arraylist的源码学习
@ 目录 ArrayList简介 ArrayList核心源码 ArrayList源码分析 System.arraycopy()和Arrays.copyOf()方法 两者联系与区别 ArrayList ...
- [数据结构-线性表1.2] 链表与 LinkedList<T>(.NET 源码学习)
[数据结构-线性表1.2] 链表与 LinkedList<T> [注:本篇文章源码内容较少,分析度较浅,请酌情选择阅读] 关键词:链表(数据结构) C#中的链表(源码) 可空类 ...
- 数据结构与算法系列2 线性表 使用java实现动态数组+ArrayList源码详解
数据结构与算法系列2 线性表 使用java实现动态数组+ArrayList源码详解 对数组有不了解的可以先看看我的另一篇文章,那篇文章对数组有很多详细的解析,而本篇文章则着重讲动态数组,另一篇文章链接 ...
- JavaScript 数据结构与算法之美 - 线性表(数组、栈、队列、链表)
前言 基础知识就像是一座大楼的地基,它决定了我们的技术高度. 我们应该多掌握一些可移值的技术或者再过十几年应该都不会过时的技术,数据结构与算法就是其中之一. 栈.队列.链表.堆 是数据结构与算法中的基 ...
- 数据结构C++版-线性表
PS:资料来源慕课网视频. 一.什么是线性表 线性表是n个数据元素的有限序列. 分类: 二.补充知识点 1.栈和队列有出操作.入操作,对应线性表(数组)为插入元素和删除元素,而线性表中要获取指定元素值 ...
- 数据结构——ArrayList的源码分析(你所有的疑问,都会被解答)
一.首先来看一下ArrayList的类图: 1,实现了RandomAccess接口,可以达到随机访问的效果. 2,实现了Serializable接口,可以用来序列化或者反序列化. 3,实现了List接 ...
- ArrayList实现源码分析
本文将以以下几个问题来探讨ArrayList的源码实现 1.ArrayList的大小是如何自动增加的 2.什么情况下你会使用ArrayList?什么时候你会选择LinkedList? 3.如何复制某个 ...
- JDK1.8源码学习-ArrayList
JDK1.8源码学习-ArrayList 目录 一.ArrayList简介 为了弥补普通数组无法自动扩容的不足,Java提供了集合类,其中ArrayList对数组进行了封装,使其可以自动的扩容或缩小长 ...
- ArrayList的源码分析
在项目中经常会用到list集合来存储数据,而其中ArrayList是用的最多的的一个集合,这篇博文主要简单介绍ArrayList的源码分析,基于JDK1.7: 这里主要介绍 集合 的属性,构造器,和方 ...
随机推荐
- 面试突击55:delete、drop、truncate有什么区别?
在 MySQL 中,删除的方法总共有 3 种:delete.truncate.drop,而三者的用法和使用场景又完全不同,接下来我们具体来看. 1.delete detele 可用于删除表的部分或所有 ...
- 【RocketMQ】MQ消息发送
消息发送 首先来看一个RcoketMQ发送消息的例子: @Service public class MQService { @Autowired DefaultMQProducer defaultMQ ...
- SQLite数据库损坏及其修复探究
数据库如何发生损坏 SQLite 数据库具有很强的抗损坏能力.在执行事务时如果发生应用程序崩溃.操作系统崩溃甚至电源故障,那么在下次访问数据库文件时,会自动回滚部分写入的事务.恢复过程是全自动的, ...
- 记安装AWVS14过程踩的坑
由于之前的AWVS14用着用着无法扫描了,一扫就是失败,一气之下就重装系统了.重装系统后发现安装还是不行,折腾了好久,终于找到方法了. 安装acunetix_14.1.210324124.exe 没啥 ...
- 关于react的props你需要知道的一个简单方法
//注意一点:函数名必须大写 function Clock(props) { return ( <div> <h1>Hello, world!</h1> <h ...
- ElasticSearch7.3学习(三十二)----logstash三大插件(input、filter、output)及其综合示例
1. Logstash输入插件 1.1 input介绍 logstash支持很多数据源,比如说file,http,jdbc,s3等等 图片上面只是一少部分.详情见网址:https://www.elas ...
- RPA 快手自动上传机器人
1.打开账号Cookie预存表格 2.机器人自动登录账号 3.机器人开始按照预设视频位置开始自动上传视频 4.机器人开始自动填写视频相关信息内容 5.完成后,可自动切换下一个账号继续上传
- 聊聊Netty那些事儿之从内核角度看IO模型
从今天开始我们来聊聊Netty的那些事儿,我们都知道Netty是一个高性能异步事件驱动的网络框架. 它的设计异常优雅简洁,扩展性高,稳定性强.拥有非常详细完整的用户文档. 同时内置了很多非常有用的模块 ...
- AI 绘画极简教程
昨天在朋友圈发了几张我用AI绘画工具Disco Diffusion画的画 既然有同学问,就写个极简教程吧,画个图是足够了,想要深入了解还是自行百度吧,可以找到更详细的教程. 第 0 步:学会上网,注册 ...
- 发评测赢好礼 | Serverless 函数计算征集令
随着云计算发展,云原生热度攀升,Serverless 架构崭露头角且发展势头迅猛.不仅被更多开发者所关注,市场占有率也逐年提高.阿里云函数计算(Function Compute)是一个事件驱动的全托管 ...