ProxySQL(8):SQL语句的重写规则
文章转载自: https://www.cnblogs.com/f-ck-need-u/p/9309760.html
为什么要重写SQL语句
ProxySQL在收到前端发送来的SQL语句后,可以根据已定制的规则去匹配它,匹配到了还可以去重写这个语句,然后再路由到后端去。
什么时候需要重写SQL语句?
对于下面这种简单的读、写分离,当然用不上重写SQL语句。
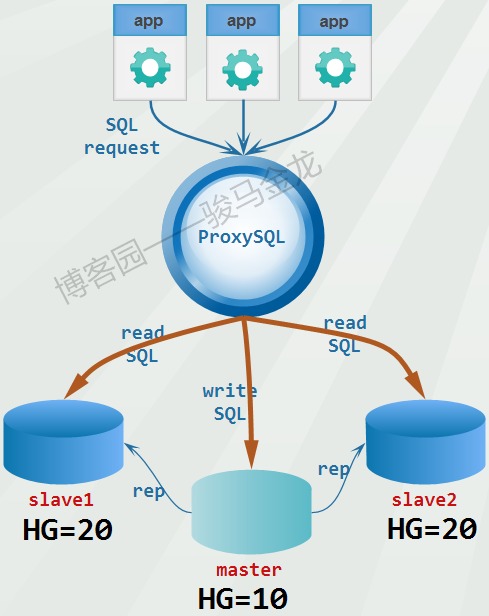
这样的读写分离,实现起来非常简单。如下:
mysql_replication_hostgroups:
+------------------+------------------+----------+
| writer_hostgroup | reader_hostgroup | comment |
+------------------+------------------+----------+
| 10 | 20 | cluster1 |
+------------------+------------------+----------+
mysql_servers:
+--------------+----------+------+--------+--------+
| hostgroup_id | hostname | port | status | weight |
+--------------+----------+------+--------+--------+
| 10 | master | 3306 | ONLINE | 1 |
| 20 | slave1 | 3306 | ONLINE | 1 |
| 20 | slave2 | 3306 | ONLINE | 1 |
+--------------+----------+------+--------+--------+
mysql_query_rules:
+---------+-----------------------+----------------------+
| rule_id | destination_hostgroup | match_digest |
+---------+-----------------------+----------------------+
| 1 | 10 | ^SELECT.*FOR UPDATE$ |
| 2 | 20 | ^SELECT |
+---------+-----------------------+----------------------+
但是,复杂一点的,例如ProxySQL实现sharding功能。对db1库的select_1语句路由给hg=10的组,将db2库的select_2语句路由给hg=20的组,将db3库的select_3语句路由给hg=30的组。
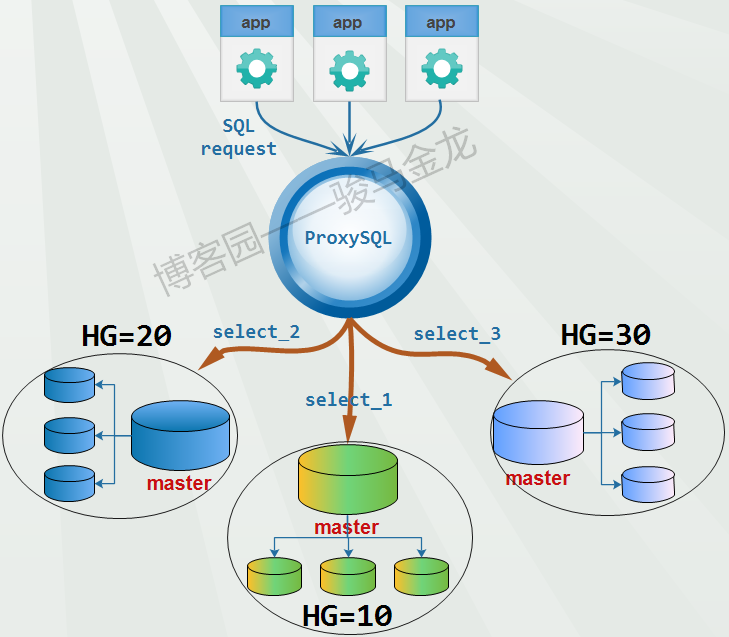
在ProxySQL实现sharding时,基本上都需要将SQL语句进行重写。这里用一个简单的例子来说明分库是如何进行的。
假如,计算机学院it_db占用一个数据库,里面有一张学生表stu,stu表中有代表专业的字段zhuanye(例子只是随便举的,请无视合理性)。
it_db库: stu表
+---------+----------+---------+
| stu_id | stu_name | zhuanye |
+---------+----------+---------+
| 1-99 | ... | Linux |
+---------+----------+---------+
| 100-150 | ... | MySQL |
+---------+----------+---------+
| 151-250 | ... | JAVA |
+---------+----------+---------+
| 251-550 | ... | Python |
+---------+----------+---------+
分库时,可以为各个专业创建库。于是,创建4个库,每个库中仍保留stu表,但只保留和库名对应的学生数据:
Linux库:stu表
+---------+----------+---------+
| stu_id | stu_name | zhuanye |
+---------+----------+---------+
| 1-99 | ... | Linux |
+---------+----------+---------+
MySQL库:stu表
+---------+----------+---------+
| stu_id | stu_name | zhuanye |
+---------+----------+---------+
| 100-150 | ... | MySQL |
+---------+----------+---------+
JAVA库:stu表
+---------+----------+---------+
| stu_id | stu_name | zhuanye |
+---------+----------+---------+
| 151-250 | ... | JAVA |
+---------+----------+---------+
Python库:stu表
+---------+----------+---------+
| stu_id | stu_name | zhuanye |
+---------+----------+---------+
| 251-550 | ... | Python |
+---------+----------+---------+
于是,原来查询MySQL专业学生的SQL语句:
select * from it_db.stu where zhuanye='MySQL' and xxx;
分库后,该SQL语句需要重写为:
select * from MySQL.stu where 1=1 and xxx;
至于如何达到上述目标,本文结尾给出了一个参考规则。
sharding而重写只是一种情况,在很多使用复杂ProxySQL路由规则时可能都需要重写SQL语句。下面将简单介绍ProxySQL的语句重写,为后文做个铺垫,在之后介绍ProxySQL + sharding的文章中有更多具体的用法。
SQL语句重写
在mysql_query_rules表中有match_pattern字段和replace_pattern字段,前者是匹配SQL语句的正则表达式,后者是匹配成功后(命中规则),将原SQL语句改写,改写后再路由给后端。
需要注意几点:
- 如果不设置replace_pattern字段,则不会重写。
- 要重写SQL语句,必须使用match_pattern的方式做正则匹配,不能使用match_digest。因为match_digest是对参数化后的语句进行匹配。
- ProxySQL支持两种正则引擎:RE2和PCRE,默认使用的引擎是PCRE。这两个引擎默认都设置了caseless修饰符(re_modifiers字段),表示匹配时忽略大小写。还可以设置其它修饰符,如global修饰符,global修饰符主要用于SQL语句重写,表示全局替换,而非首次替换。
- 因为SQL语句千变万化,在写正则语句的时候,一定要注意"贪婪匹配"和"非贪婪匹配"的问题。
- stats_mysql_query_digest表中的digest_text字段显示了替换后的语句。也就是真正路由出去的语句。
本文的替换规则出于入门的目的,很简单,只需掌握最基本的正则知识即可。但想要灵活运用,需要掌握PCRE的正则,如果您已有正则的基础,可参考我的一篇总结性文章:pcre和正则表达式的误点。
例如,将下面的语句1重写为语句2。
例如,将下面的语句1重写为语句2。
select * from test1.t1;
select * from test1.t2;
插入如下规则:
delete from mysql_query_rules;
select * from stats_mysql_query_digest_reset where 1=0;
insert into mysql_query_rules(rule_id,active,match_pattern,replace_pattern,destination_hostgroup,apply)
values (1,1,"^(select.*from )test1.t1(.*)","\1test1.t2\2",20,1);
load mysql query rules to runtime;
save mysql query rules to disk;
select rule_id,destination_hostgroup,match_pattern,replace_pattern from mysql_query_rules;
+---------+-----------------------+------------------------------+-----------------+
| rule_id | destination_hostgroup | match_pattern | replace_pattern |
+---------+-----------------------+------------------------------+-----------------+
| 1 | 20 | ^(select.*from )test1.t1(.*) | \1test1.t2\2 |
+---------+-----------------------+------------------------------+-----------------+
然后执行:
$ proc="mysql -uroot -pP@ssword1! -h127.0.0.1 -P6033 -e"
$ $proc "select * from test1.t1;"
+------------------+
| name |
+------------------+
| test1_t2_malong1 |
| test1_t2_malong2 |
| test1_t2_malong3 |
+------------------+
可见语句成功重写。
再看看规则的状态。
Admin> select rule_id,hits from stats_mysql_query_rules;
+---------+------+
| rule_id | hits |
+---------+------+
| 1 | 1 |
| 2 | 0 |
+---------+------+
Admin> select hostgroup,count_star,digest_text from stats_mysql_query_digest;
+-----------+------------+------------------------+
| hostgroup | count_star | digest_text |
+-----------+------------+------------------------+
| 20 | 1 | select * from test1.t2 | <--已替换
+-----------+------------+------------------------+
更简单的,还可以直接替换单词。例如:
delete from mysql_query_rules;
select * from stats_mysql_query_digest_reset where 1=0;
insert into mysql_query_rules(rule_id,active,match_pattern,replace_pattern,destination_hostgroup,apply)
values (1,1,"test1.t1","test1.t2",20,1);
load mysql query rules to runtime;
save mysql query rules to disk;
select rule_id,destination_hostgroup,match_pattern,replace_pattern from mysql_query_rules;
+---------+-----------------------+---------------+-----------------+
| rule_id | destination_hostgroup | match_pattern | replace_pattern |
+---------+-----------------------+---------------+-----------------+
| 1 | 20 | test1.t1 | test1.t2 |
+---------+-----------------------+---------------+-----------------+
sharding:重写分库SQL语句
以本文前面sharding示例中的语句为例,简单演示下sharding时的分库语句怎么改写。更完整的sharding实现方法,见后面的文章。
#原来查询MySQL专业学生的SQL语句:
select * from it_db.stu where zhuanye='MySQL' and xxx;
|
|
|
\|/
#改写为查询分库MySQL的SQL语句:
select * from MySQL.stu where 1=1 and xxx;
以下是完整语句:关于这个规则中的正则部分,稍后会解释。
delete from mysql_query_rules;
select * from stats_mysql_query_digest_reset where 1=0;
insert into mysql_query_rules(rule_id,active,apply,destination_hostgroup,match_pattern,replace_pattern)
values (1,1,1,20,"^(select.*?from) it_db\.(.*?) where zhuanye=['""](.*?)['""] (.*)$","\1 \3.\2 where 1=1 \4");
load mysql query rules to runtime;
save mysql query rules to disk;
select rule_id,destination_hostgroup dest_hg,match_pattern,replace_pattern from mysql_query_rules;
+---------+---------+-----------------------------------------------------------------+-----------------------+
| rule_id | dest_hg | match_pattern | replace_pattern |
+---------+---------+-----------------------------------------------------------------+-----------------------+
| 1 | 20 | ^(select.*?from) it_db\.(.*?) where zhuanye=['"](.*?)['"] (.*)$ | \1 \3.\2 where 1=1 \4 |
+---------+---------+-----------------------------------------------------------------+-----------------------+
然后执行分库查询语句:
proc="mysql -uroot -pP@ssword1! -h127.0.0.1 -P6033 -e"
$proc "select * from it_db.stu where zhuanye='MySQL' and 1=1;"
看看是否命中规则,并成功改写SQL语句:
Admin> select rule_id,hits from stats_mysql_query_rules;
+---------+------+
| rule_id | hits |
+---------+------+
| 1 | 1 |
+---------+------+
Admin> select hostgroup,count_star,digest_text from stats_mysql_query_digest;
+-----------+------------+-------------------------------------------+
| hostgroup | count_star | digest_text |
+-----------+------------+-------------------------------------------+
| 20 | 1 | select * from MySQL.stu where ?=? and ?=? |
| 10 | 1 | select @@version_comment limit ? |
+-----------+------------+-------------------------------------------+
解释下前面的规则:
match_pattern:
- "^(select.*?from) it_db\.(.*?) where zhuanye=['""](.*?)['""] (.*)$"
replace_pattern:
- "\1 \3.\2 where 1=1 \4"
^(select.*?from) :表示不贪婪匹配到from字符。之所以不贪婪匹配,是为了避免子查询或join子句出现多个from的情况。
it_db\.(.*?):这里的it_db是稍后要替换掉为"MySQL"字符的部分,而it_db后面的表稍后要附加在"MySQL"字符后,所以对其分组捕获。
zhuanye=['""](.*?)['""]:
- 这里的zhuanye字段稍后是要删除的,但后面的字段值"MySQL"需要保留作为稍后的分库,因此对字段值分组捕获。同时,字段值前后的引号可能是单引号、双引号,所以两种情况都要考虑到。
- ['""]:要把引号保留下来,需要对额外的引号进行转义:双引号转义后成单个双引号。所以,真正插入到表中的结果是['"]。
- 这里的语句并不健壮,因为如果是zhuanye='MySQL"这样单双引号混用也能被匹配。如果要避免这种问题,需要使用PCRE的反向引用。例如,改写为:zhuanye=(['""])(.*?)\g[N],这里的[N]要替换为(['""])对应的分组号码,例如\g3。
(.*)$:匹配到结束。因为这里的测试语句简单,没有join和子查询什么的,所以直接匹配。
"\1 \3.\2 where 1=1 \4":这里加了1=1,是为了防止出现and/or等运算符时前面缺少表达式。例如 (.*)$捕获到的内容为 and xxx=1,不加上1=1的话,将替换为where and xxx=1,这是错误的语句,所以1=1是个占位表达式。
可见,要想实现一些复杂的匹配目标,正则表达式是非常繁琐的。所以,很有必要去掌握PCRE正则表达式。
ProxySQL(8):SQL语句的重写规则的更多相关文章
- MySQL中间件之ProxySQL(8):SQL语句的重写规则
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.为什么要重写SQL语句 ProxySQL在收到前端发送来的SQL语 ...
- mysql学习之 sql语句的技巧及优化
一.sql中使用正则表达式 select name,email from user where email Regexp "@163[.,]com$"; sql语句中使用Regex ...
- 一条Sql语句分组排序并且限制显示的数据条数
如果我想得到这样一个结果集:分组排序,并且每组限定记录集的数量,用一条SQL语句能办到吗? 比如说,我想找出学生期末考试中,每科的前3名,并按成绩排序,只用一条SQL语句,该怎么写? 表[TScore ...
- LINQ to SQL语句(7)之Exists/In/Any/All/Contains
适用场景:用于判断集合中元素,进一步缩小范围. Any 说明:用于判断集合中是否有元素满足某一条件:不延迟.(若条件为空,则集合只要不为空就返回True,否则为False).有2种形式,分别为简单形式 ...
- Oracle ------ SQLDeveloper中SQL语句格式化快捷键
Oracle SQL Developer中SQL语句格式化快捷键: 每次sql复制到SQL Developer面板的时候,格式老不对,而且看起来很不舒服,所有的sql都挤在一行完成. 这时我们可以全选 ...
- SQL语句优化
(1) 选择最有效率的表名顺序 ( 只在基于规则的优化器中有效 ) : ORACLE 的解析器按照从右到左的顺序处理 FROM 子句中的表名, FROM 子句中写在最后的表 ( 基础表dri ...
- LinqToDB 源码分析——生成与执行SQL语句
生成SQL语句的功能可以算是LinqToDB框架的最后一步.从上一章中我们可以知道处理完表达式树之后,相关生成SQL信息会被保存在一个叫SelectQuery类的实例.有了这个实例我们就可以生成对应的 ...
- 年终巨献 史上最全 ——LINQ to SQL语句
LINQ to SQL语句(1)之Where 适用场景:实现过滤,查询等功能. 说明:与SQL命令中的Where作用相似,都是起到范围限定也就是过滤作用的,而判断条件就是它后面所接的子句.Where操 ...
- LINQ to SQL语句(19)之ADO.NET与LINQ to SQL
它基于由 ADO.NET 提供程序模型提供的服务.因此,我们可以将 LINQ to SQL 代码与现有的 ADO.Net 应用程序混合在一起,将当前 ADO.NET 解决方案迁移到 LINQ to S ...
随机推荐
- nw.js的cookie操作
在实战中,我遇到nw.js cookie一个奇怪的现象. 当我写入cookie(非httponly)后,关闭nw.js.然后再打开nw.js发现cookie没有写入成功.经过摸索,发现 nw.js的c ...
- Dubbo源码(一) - SPI使用
为什么学SPI Dubbo 的可扩展性是基于 SPI 去实现的,而且Dubbo所有的组件都是通过 SPI 机制加载. 什么是SPI SPI 全称为 (Service Provider Interfac ...
- 技术分享 | Prometheus+Grafana监控MySQL浅析
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 简介 Prometheus 一套开源的监控&报警&时间序列数据库的组合,通常 Kubernetes 中都会 ...
- BTDetect用户手册和技术支持
BTDetect用户手册和技术支持 1. 程序主要功能 BTDetect是BT(BioTechnology) Detect 生物科技检测的缩写.本程序将根据用户的回答推断其两大基因类型.以及具体的小分 ...
- 杭州思科对 Apache DolphinScheduler Alert 模块的改造
杭州思科已经将 Apache DolphinScheduler 引入公司自建的大数据平台.目前,杭州思科大数据工程师 李庆旺 负责 Alert 模块的改造已基本完成,以更完善的 Alert 模块适应实 ...
- BZOJ4580/Luogu3147 [Usaco2016 Open]248
amazing #include <iostream> #include <cstdio> #include <cstring> #include <algo ...
- java中为什么只存在值传递(以传入自定义引用类型为例)
java中只有值传递 为什么这么说?两个例子: public class Student { int sage = 20; String sname = "云胡不归"; publi ...
- Java反射(重要)
全文内容 1: 获取字节码文件对象的三种方式 2: 获取公有,私有方法,并调用构造方法,成员方法 3: 获取并调用私有成员变量 4: 如何为实例对象的成员变量赋值 5: 文末有一些注意 tea1类代码 ...
- from表单、css选择器、css组合器、字体样式、背景属性、边框设置、display设置
目录 一.form表单 1.form表单功能 2.表单使用原理 二.前端基础之css 1.关于css的介绍 2.css语法 3.三种编写CSS的方式 3.1.style内部直接编写css代码 3.2. ...
- 深入解析Flutter下一代渲染引擎Impeller
作者 魏国梁:字节 Flutter Infra 工程师, Flutter Member,长期专注 Flutter 引擎技术 袁 欣:字节 Flutter Infra 工程师, 长期关注渲染技术发 ...