基于R的Bilibili视频数据建模及分析——预处理篇
基于R的Bilibili视频数据建模及分析——预处理篇
文章目录

0、写在前面
实验环境
- Python版本:
Python3.9 - Pycharm版本:
Pycharm2021.1.3 - R版本:
R-4.2.0 - RStudio版本:
RStudio-2021.09.2-382
该实验一共使用4个数据集,但文章讲述只涉及到一个数据集,并且对于每个数据集的分析,数据大小在110条左右
1、项目介绍
1.1 项目背景
Bilibili是国内比较热门的视频网站,本次实验是通过对Bilibili四个不同专区视频数据进行R使用的统计分析、聚类分析以及建模分析。
1.2 数据来源
- 数据来源于和鲸社区
https://www.heywhale.com/mw/dataset/62a45d284619d87b3b2b9147/file
数据字段描述说明
- title:视频的标题
- duration:视频时长
- publisher:视频作者
- descriptions:视频描述信息
- pub_time:视频发布时间
- view:视频播放量
- comments:视频评论数
- praise:视频点赞量
- coins:视频投币数
- favors:视频收藏数
- forwarding:视频转发量
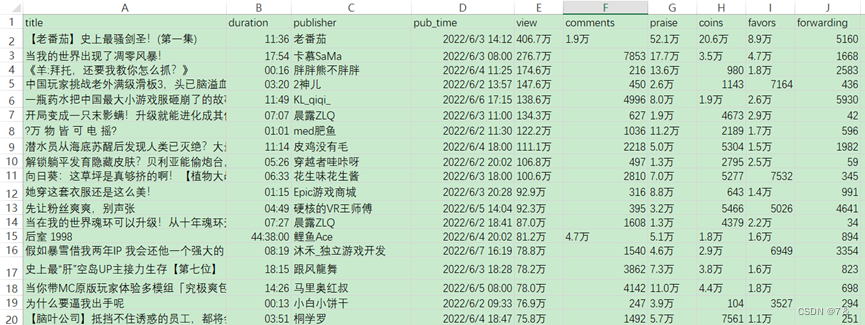
1.3 数据集展示
表单机游戏——游戏区:
2、数据预处理
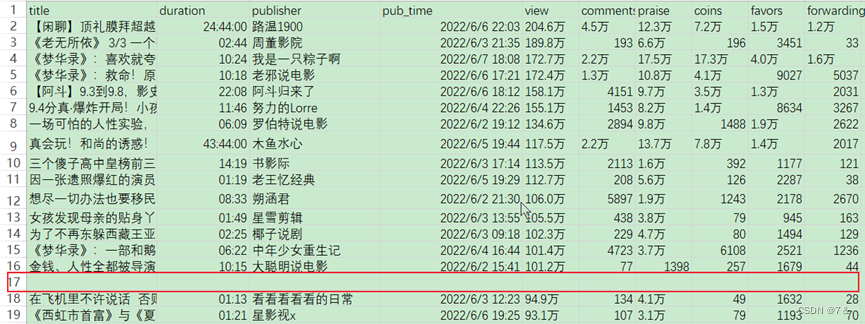
2.1 删除空数据
整行数据为空,直接删除
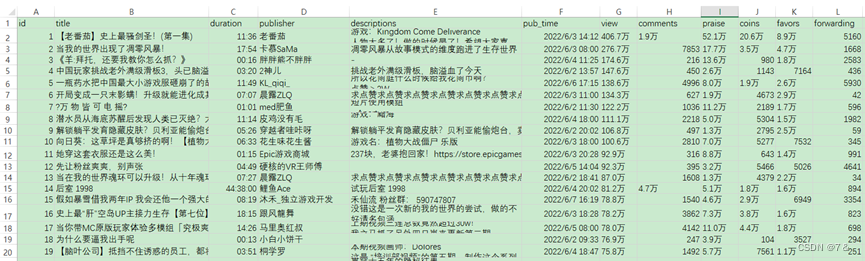
2.2 增加id字段
在Excel每张表的首列添加id字段,
预处理后数据展示:
2.3 处理数值字段
对于
view,comments,praise,coins,favors,forwarding这些数值型字段,原始数据中,1万以上的数值是以xxx.xx万的形式展示的,为方便后续统计,此处将这些类型的字段值转换为常规数字格式。
此处的预处理操作使用Python来处理,代码如下
import pandas as pd
data1 = pd.read_csv('data/videos1.csv', encoding='utf8')
print(data1.shape)
print('---------------------------------------')
# TODO 处理数值字段(view,comments,praise,coins,favors,forwarding)
import pandas as pd
import operator
data1 = pd.read_csv('data/videos1.csv', encoding='utf8')
print(data1.head(3))
print('-------------------------------------------------------')
# # TODO id,title,duration,publisher,pub_time,view,comments,praise,coins,favors,forwarding
def operateVideos1() :
for i in range(0, len(data1)):
# if i == 0 :
# print(data1.iloc[i])
# print(data1.iloc[i][5])
id = data1.iloc[i][0]
view = data1.iloc[i][5]
comments = data1.iloc[i][6]
praise = data1.iloc[i][7]
coins = data1.iloc[i][8]
favors = data1.iloc[i][9]
forwarding = data1.iloc[i][10]
if operator.contains(view, '万'):
num = int(float(view[0: len(view) - 1]) * 10000)
data1._set_value(i, "view", num)
if operator.contains(comments, '万'):
num = int(float(comments[0: len(comments) - 1]) * 10000)
data1._set_value(i, "comments", num)
if operator.contains(praise, '万'):
num = int(float(praise[0: len(praise) - 1]) * 10000)
data1._set_value(i, "praise", num)
if operator.contains(coins, '万'):
num = int(float(coins[0: len(coins) - 1]) * 10000)
data1._set_value(i, "coins", num)
if operator.contains(favors, '万'):
num = int(float(favors[0: len(favors) - 1]) * 10000)
data1._set_value(i, "favors", num)
if operator.contains(forwarding, '万'):
num = int(float(forwarding[0: len(forwarding) - 1]) * 10000)
data1._set_value(i, "forwarding", num)
data1.to_csv('out/v1.csv', index=False)
operateVideos1()
预处理之后的部分数据展示:
数据集1:

3、参考资料
- 多元统计分析及R使用(第五版)
结束!
基于R的Bilibili视频数据建模及分析——预处理篇的更多相关文章
- (转)基于RTP的H264视频数据打包解包类
最近考虑使用RTP替换原有的高清视频传输协议,遂上网查找有关H264视频RTP打包.解包的文档和代码.功夫不负有心人,找到不少有价值的文档和代码.参考这些资料,写了H264 RTP打包类.解包类,实现 ...
- 基于RTP的H264视频数据打包解包类
from:http://blog.csdn.net/dengzikun/article/details/5807694 最近考虑使用RTP替换原有的高清视频传输协议,遂上网查找有关H264视频RTP打 ...
- Twitter基于R语言的时序数据突变检测(BreakoutDetection)
Twitter开源的时序数据突变检测(BreakoutDetection),基于无参的E-Divisive with Medians (EDM)算法,比传统的E-Divisive算法快3.5倍以上,并 ...
- 【FFMPEG】基于RTP的H264视频数据打包解包类
最近考虑使用RTP替换原有的高清视频传输协议,遂上网查找有关H264视频RTP打包.解包的文档和代码.功夫不负有心人,找到不少有价值的文档和代码.参考这些资料,写了H264 RTP打包类.解包类,实现 ...
- 【Wyn Enterprise BI知识库】 认识多维数据建模与分析 ZT
与业务系统类似,商业智能的基础是数据.但是,因为关注的重点不同,业务系统的数据使用方式和商业智能系统有较大差别.本文主要介绍的就是如何理解商业智能所需的多维数据模型和多维数据分析. 数据立方体 多维数 ...
- Kaggle-tiantic数据建模与分析
1.数据可视化 kaggle中数据解释:https://www.kaggle.com/c/titanic/data 数据形式: 读取数据,并显示数据信息 data_train = pd.read_cs ...
- 基于Python接口自动化测试框架+数据与代码分离(进阶篇)附源码
引言 在上一篇<基于Python接口自动化测试框架(初级篇)附源码>讲过了接口自动化测试框架的搭建,最核心的模块功能就是测试数据库初始化,再来看看之前的框架结构: 可以看出testcase ...
- 数据源管理 | 基于DataX组件,同步数据和源码分析
本文源码:GitHub·点这里 || GitEE·点这里 一.DataX工具简介 1.设计理念 DataX是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).HDF ...
- R语言中文社区历史文章整理(类型篇)
R语言中文社区历史文章整理(类型篇) R包: R语言交互式绘制杭州市地图:leafletCN包简介 clickpaste包介绍 igraph包快速上手 jiebaR,从入门到喜欢 Catterpl ...
- 机器学习与数据科学 基于R的统计学习方法(基础部分)
1.1 机器学习的分类 监督学习:线性回归或逻辑回归, 非监督学习:是K-均值聚类, 即在数据点集中找出“聚类”. 另一种常用技术叫做主成分分析(PCA) , 用于降维, 算法的评估方法也不尽相同. ...
随机推荐
- Chrome 中的 JavaScript 断点设置和调试技巧--转自hanguokai.com
你是怎么调试 JavaScript 程序的?最原始的方法是用 alert() 在页面上打印内容,稍微改进一点的方法是用 console.log() 在 JavaScript 控制台上输出内容.嗯~,用 ...
- 面试题-react
对react的理解 是什么 React 是一个用于构建用户界面的 JavaScript 库. 能干什么 可以通过组件化的方式构建大型的,快速响应的大型web应用 如何做 声明式 React 使用jsx ...
- stream 链式结构
Double totalPaymentAmount = Optional.ofNullable(wayfairMonthBill.getPaymentAmountDetailJson()) .filt ...
- 利用position: absolute最简便实现水平居中的css样式
html <div class="horizontal-center"></div> css .horizontal-center { left: 50%; ...
- spring cloud 配置文件加密解密
1.底包 <dependency> <groupId>org.springframework.security</groupId> <artifact ...
- 8个你可能不知道的令人震惊的 HTML 技巧
程序员面试题库分享 1.前端面试题库 (面试必备) 推荐:★★★★★ 地址:前端面试题库 2.前端技术导航大全 推荐:★★★★★ 地址:前端技术导航大全 3.开发者颜色 ...
- D. Steps to One
题意 初始有一个空数组\(a\),接下来每次操作会这么做: 在\([1,n]\)中选择一个数,将其拼接在数组\(a\)后. 计算数组\(a\)的\(\gcd\). 如果结果是\(1\),退出. 否则, ...
- ES6的Map和Set的了解和练习
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- win7下MongoDB安装配置
之前看windows下安装MongoDB操作很是简单,今天在自己笔记本上安装一次,各种小问题.参照网上各大神帖子,再记录下个简单流程以便以后记得. 1.MongoDB官网上下载安装包 2.运行安装包, ...
- DevOps Gitlab环境部署
DevOps 介绍 目录 DevOps 介绍 一.DevOps 介绍 1.1.1 DevOps 介绍 1.1.2 CI/CD简介 1.1.2 Gitlab安装与使用 一.DevOps 介绍 1.1.1 ...