Google搜索为什么不能无限分页?

这是一个很有意思却很少有人注意的问题。
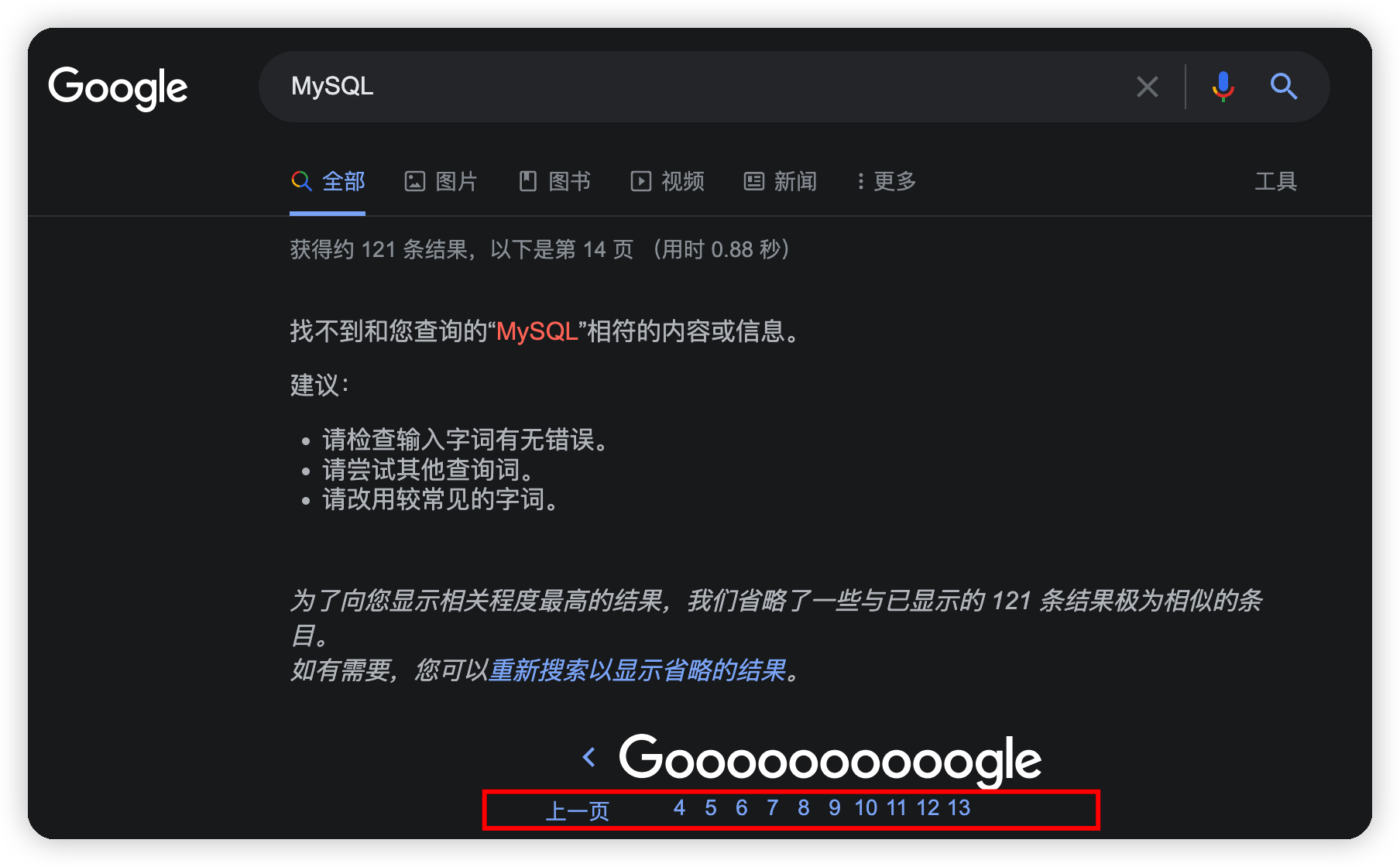
当我用Google搜索MySQL这个关键词的时候,Google只提供了13页的搜索结果,我通过修改url的分页参数试图搜索第14页数据,结果出现了以下的错误提示:
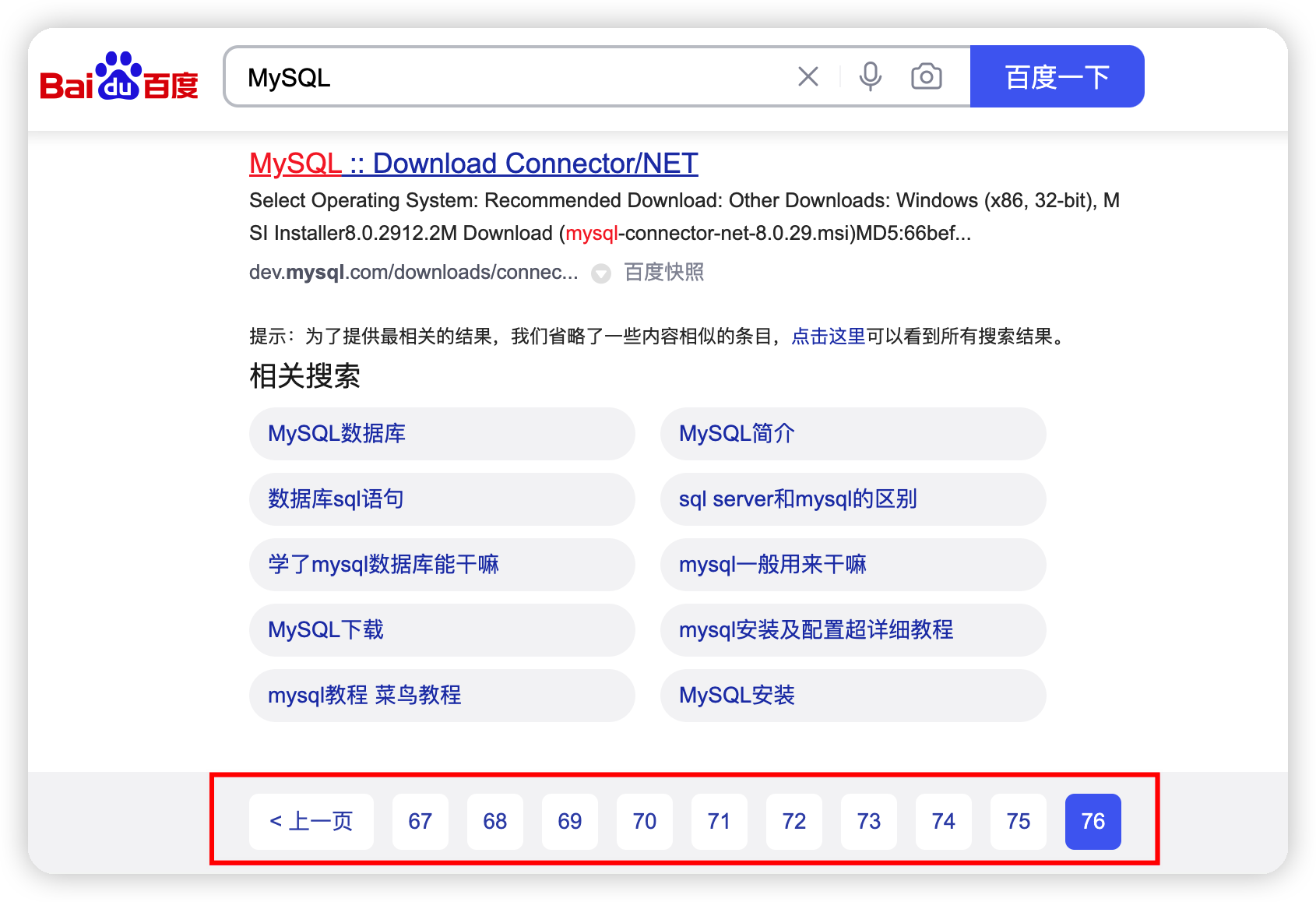
百度搜索同样不提供无限分页,对于MySQL关键词,百度搜索提供了76页的搜索结果。
为什么不支持无限分页
强如Google搜索,为什么不支持无限分页?无非有两种可能:
- 做不到
- 没必要
「做不到」是不可能的,唯一的理由就是「没必要」。
首先,当第1页的搜索结果没有我们需要的内容的时候,我们通常会立即更换关键词,而不是翻第2页,更不用说翻到10页往后了。这是没必要的第一个理由——用户需求不强烈。
其次,无限分页的功能对于搜索引擎而言是非常消耗性能的。你可能感觉很奇怪,翻到第2页和翻到第1000页不都是搜索嘛,能有什么区别?
实际上,搜索引擎高可用和高伸缩性的设计带来的一个副作用就是无法高效实现无限分页功能,无法高效意味着能实现,但是代价比较大,这是所有搜索引擎都会面临的一个问题,专业上叫做「深度分页」。这也是没必要的第二个理由——实现成本高。
我自然不知道Google的搜索具体是怎么做的,因此接下来我用ES(Elasticsearch)为例来解释一下为什么深度分页对搜索引擎来说是一个头疼的问题。
为什么拿ES举例子
Elasticsearch(下文简称ES)实现的功能和Google以及百度搜索提供的功能是相同的,而且在实现高可用和高伸缩性的方法上也大同小异,深度分页的问题都是由这些大同小异的优化方法导致的。
什么是ES
ES是一个全文搜索引擎。
全文搜索引擎又是个什么鬼?
试想一个场景,你偶然听到了一首旋律特别优美的歌曲,回家之后依然感觉余音绕梁,可是无奈你只记得一句歌词中的几个字:「伞的边缘」。这时候搜索引擎就发挥作用了。
使用搜索引擎你可以获取到带有「伞的边缘」关键词的所有结果,这些结果有一个术语,叫做文档。并且搜索结果是按照文档与关键词的相关性进行排序之后返回的。我们得到了全文搜索引擎的定义:
全文搜索引擎是根据文档内容查找相关文档,并按照相关性顺序返回搜索结果的一种工具
网上冲浪太久,我们会渐渐地把计算机的能力误以为是自己本身具备的能力,比如我们可能误以为我们大脑本身就很擅长这种搜索。恰恰相反,全文检索的功能是我们非常不擅长的。
举个例子,如果我对你说:静夜思。你可能脱口而出:床前明月光,疑是地上霜。举头望明月,低头思故乡。但是如果我让你说出带有「月」的古诗,想必你会费上一番功夫。
包括我们平时看的书也是一样,目录本身就是一种符合我们人脑检索特点的一种搜索结构,让我们可以通过文档ID或者文档标题这种总领性的标识来找到某一篇文档,这种结构叫做正排索引。

而全文搜索引擎恰好相反,是通过文档中的内容来找寻文档,诗词大会中的飞花令就是人脑版的全文搜索引擎。

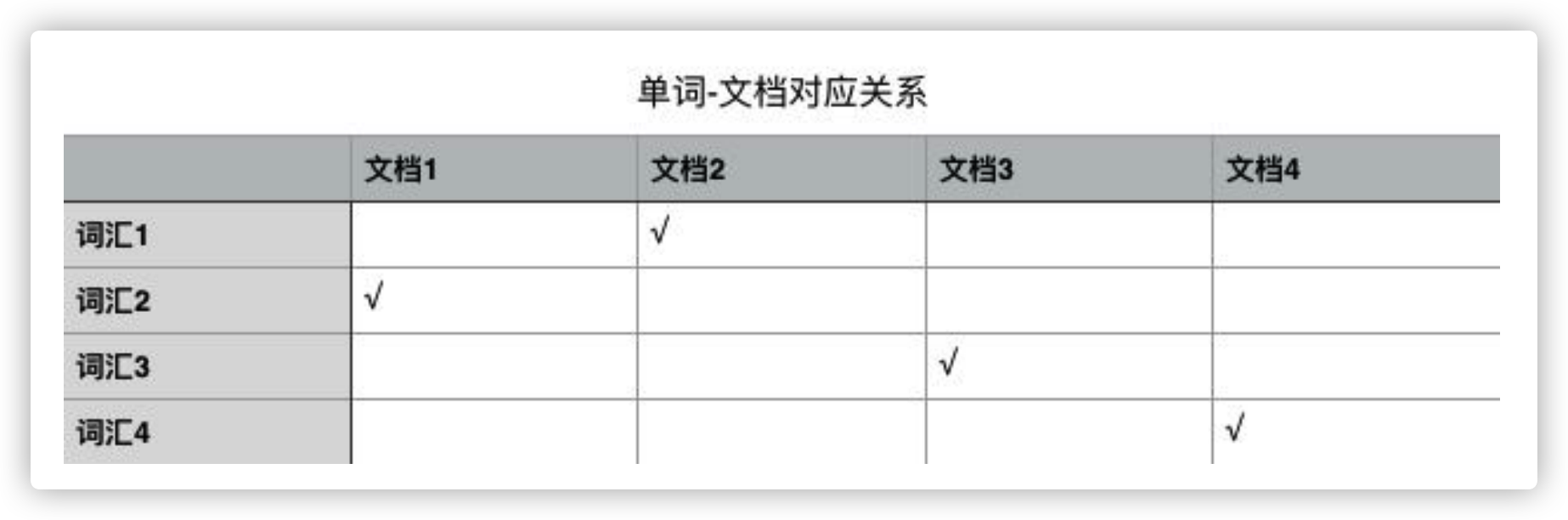
全文搜索引擎依赖的数据结构就是大名鼎鼎的倒排索引(「倒排」这个词就说明这种数据结构和我们正常的思维方式恰好相反),它是单词和文档之间包含关系的一种具体实现形式。
打住!不能继续展开了话题了,赶紧一句话介绍完ES吧!
ES是一款使用倒排索引数据结构、能够根据文档内容查找相关文档,并按照相关性顺序返回搜索结果的全文搜索引擎
高可用的秘密——副本(Replication)
高可用是企业级服务必须考虑的一个指标,高可用必然涉及到集群和分布式,好在ES天然支持集群模式,可以非常简单地搭建一个分布式系统。
ES服务高可用要求其中一个节点如果挂掉了,不能影响正常的搜索服务。这就意味着挂掉的节点上存储的数据,必须在其他节点上留有完整的备份。这就是副本的概念。

如上图所示,Node1作为主节点,Node2和Node3作为副本节点保存了和主节点完全相同的数据,这样任何一个节点挂掉都不会影响业务的搜索。满足服务的高可用要求。
但是有一个致命的问题,无法实现系统扩容!即使添加另外的节点,对整个系统的容量扩充也起不到任何帮助。因为每一个节点都完整保存了所有的文档数据。
因此,ES引入了分片(Shard)的概念。
PB级数量的基石——分片(Shard)
ES将每个索引(ES中一系列文档的集合,相当于MySQL中的表)分成若干个分片,分片将尽可能平均地分配到不同的节点上。比如现在一个集群中有3台节点,索引被分成了5个分片,分配方式大致(因为具体如何平均分配取决于ES)如下图所示。
这样一来,集群的横向扩容就非常简单了,现在我们向集群中再添加2个节点,则ES会自动将分片均衡到各个节点之上:
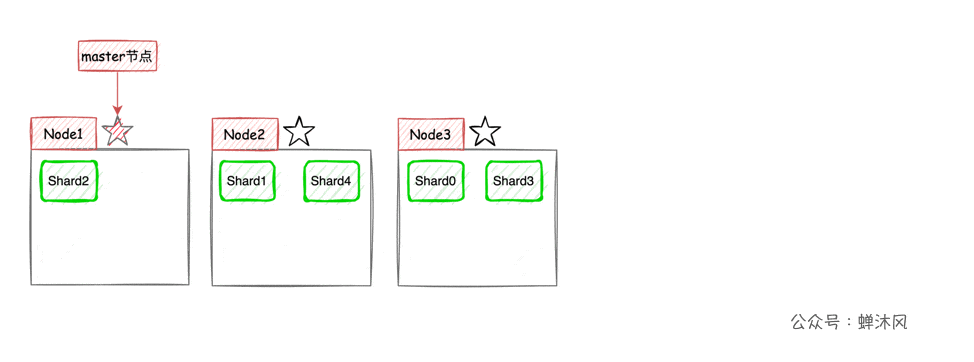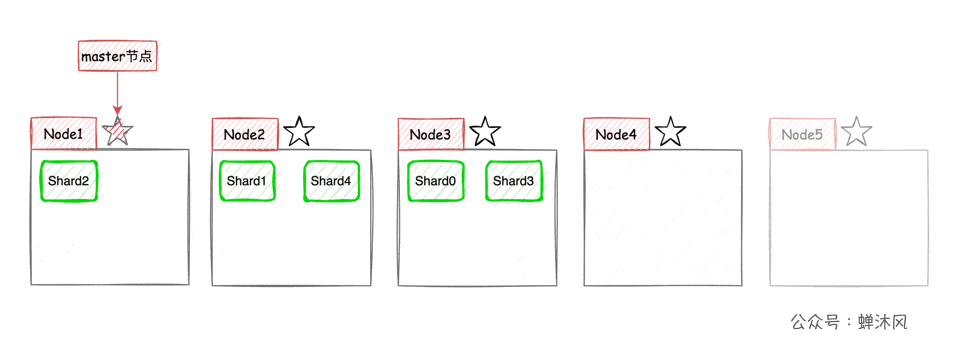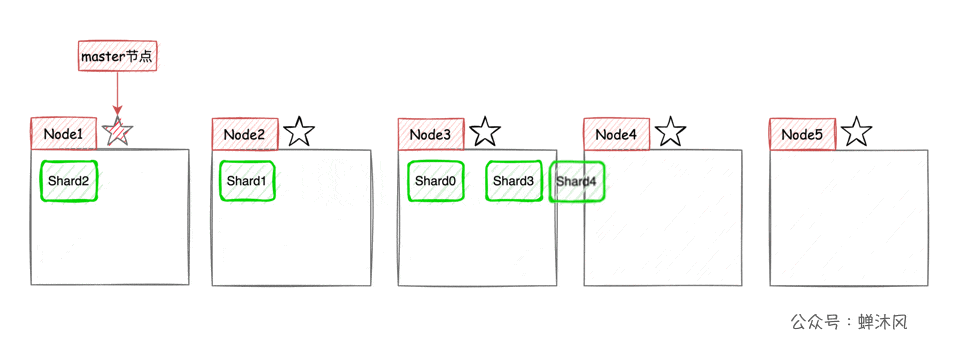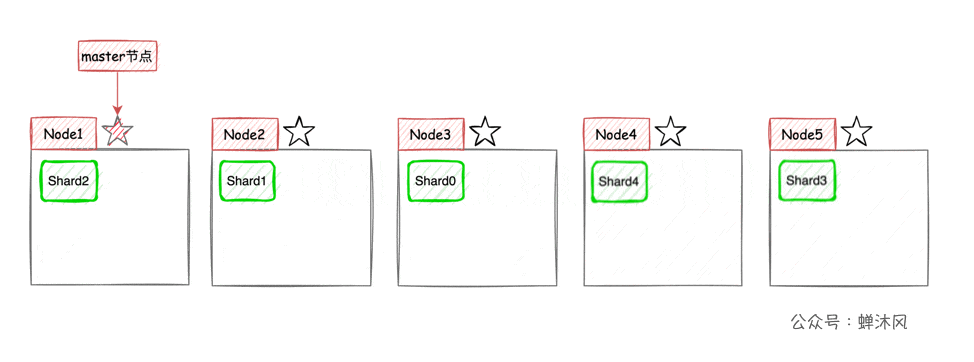
高可用 + 弹性扩容
副本和分片功能通力协作造就了ES如今高可用和支持PB级数据量的两大优势。
现在我们以3个节点为例,展示一下分片数量为5,副本数量为1的情况下,ES在不同节点上的分片排布情况:
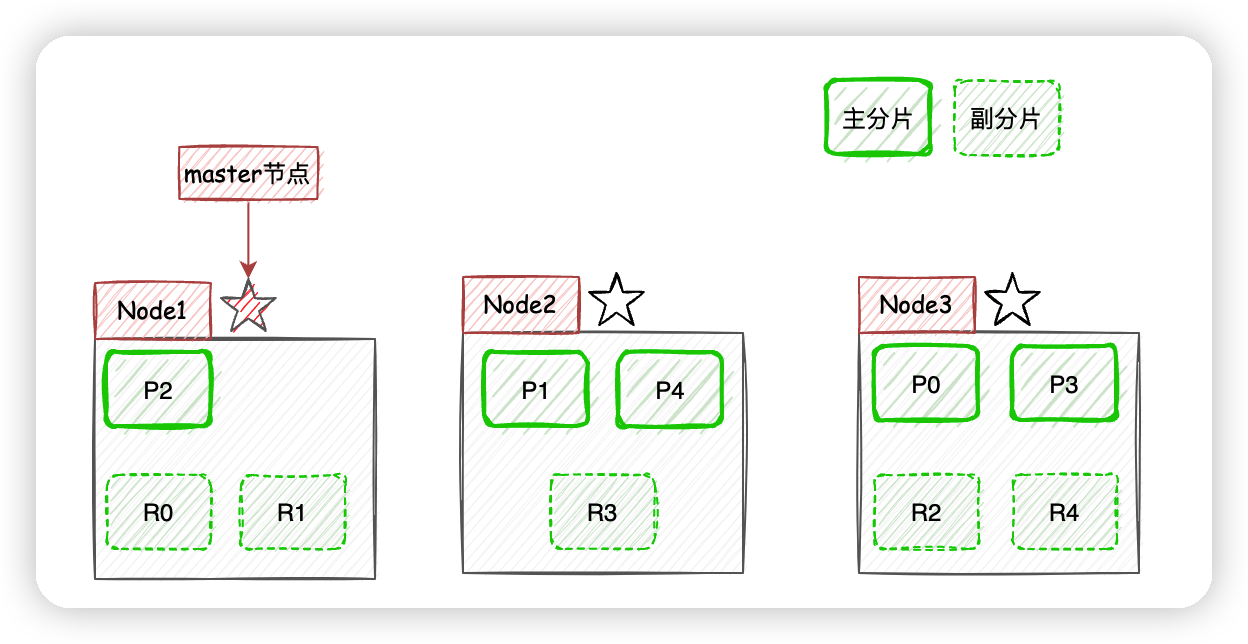
有一点需要注意,上图示例中主分片和对应的副本分片不会出现在同一个节点上,至于为什么,大家可以自己思考一下。
文档的分布式存储
ES是怎么确定某个文档应该存储到哪一个分片上呢?

通过上面的映射算法,ES将文档数据均匀地分散在各个分片中,其中routing默认是文档id。
此外,副本分片的内容依赖主分片进行同步,副本分片存在意义就是负载均衡、顶上随时可能挂掉的主分片位置,成为新的主分片。
现在基础知识讲完了,终于可以进行搜索了。
ES的搜索机制
一图胜千言:
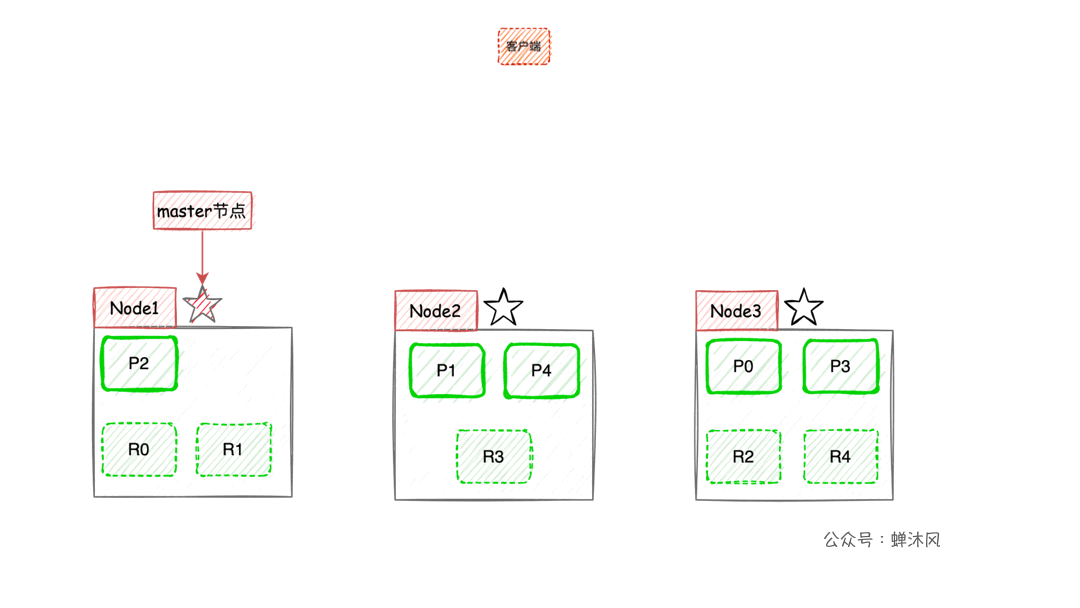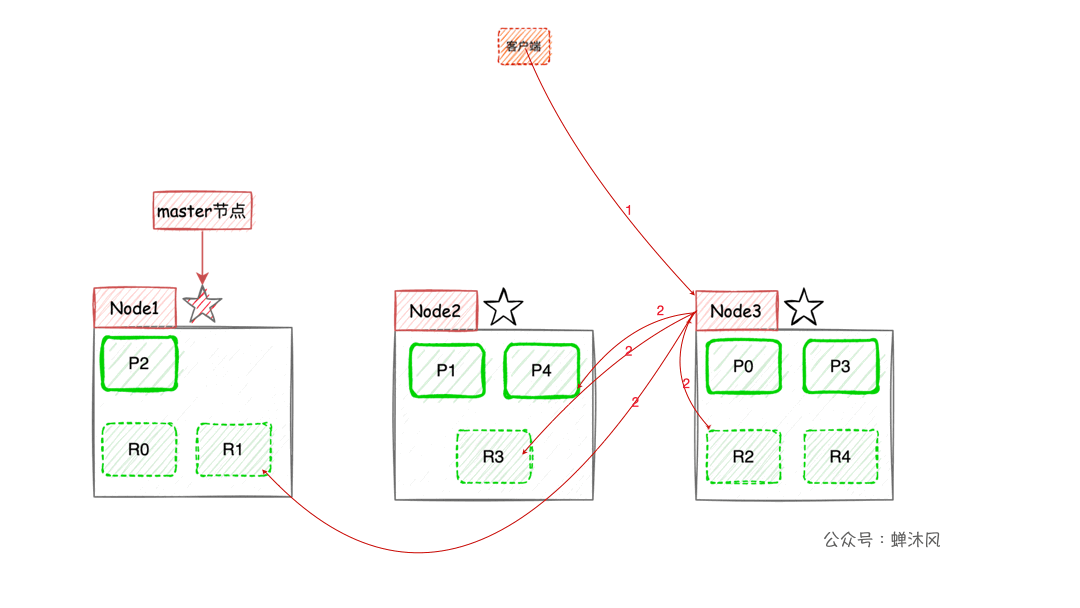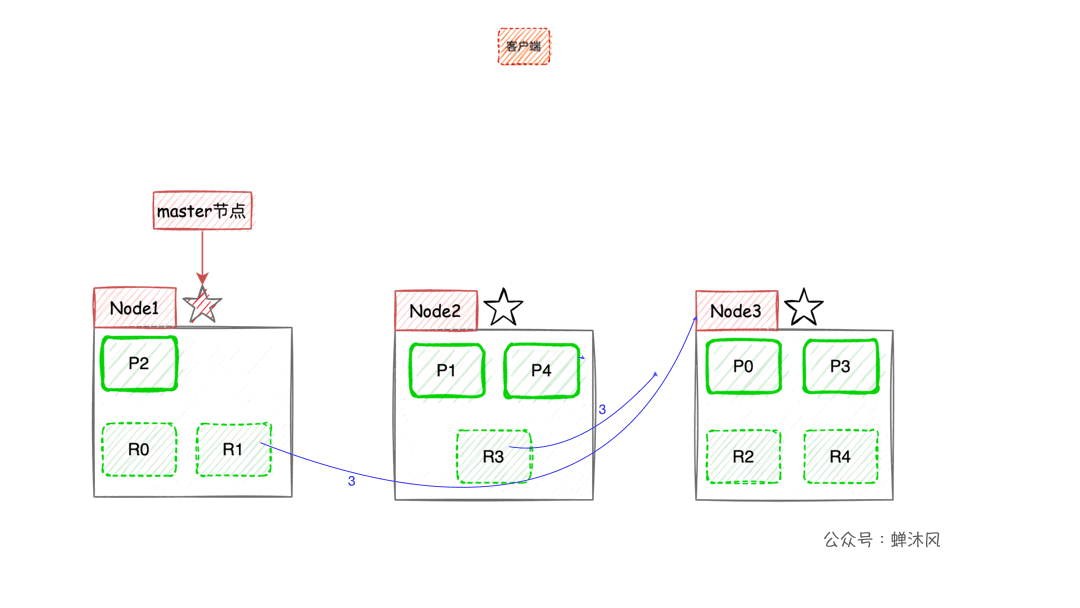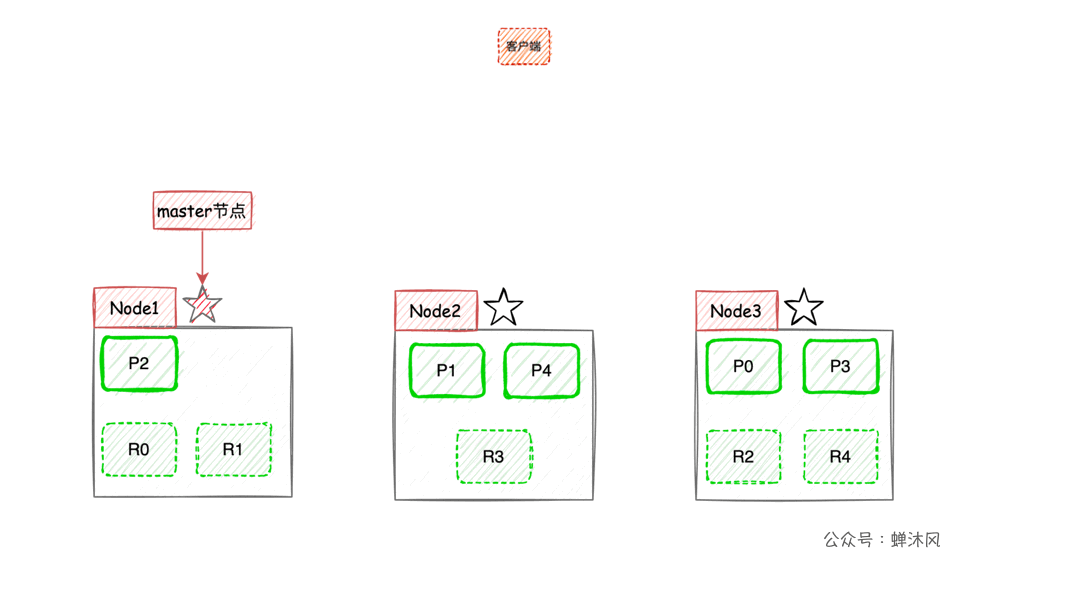
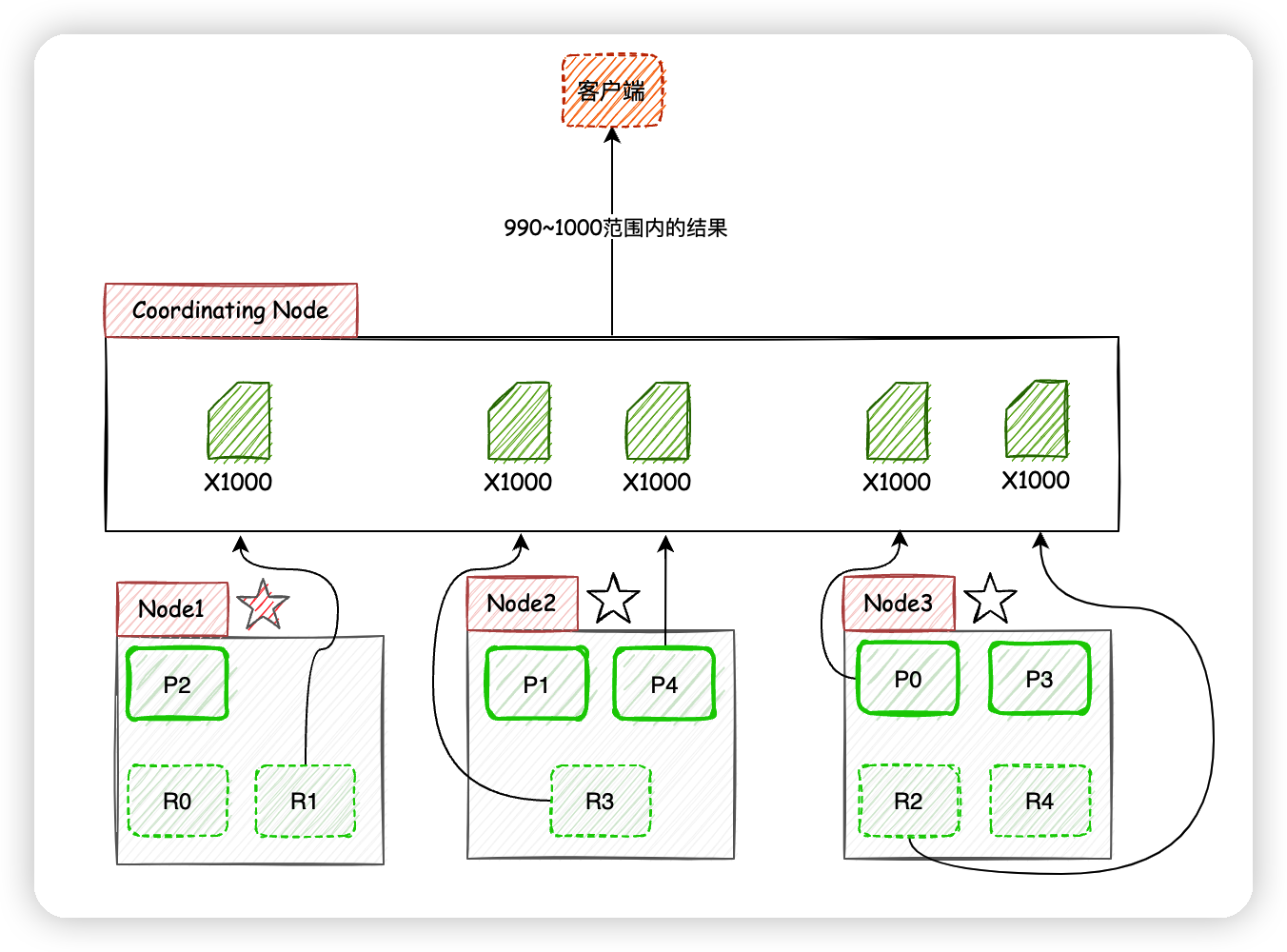
- 客户端进行关键词搜索时,
ES会使用负载均衡策略选择一个节点作为协调节点(Coordinating Node)接受请求,这里假设选择的是Node3节点; Node3节点会在10个主副分片中随机选择5个分片(所有分片必须能包含所有内容,且不能重复),发送search request;- 被选中的5个分片分别执行查询并进行排序之后返回结果给
Node3节点; Node3节点整合5个分片返回的结果,再次排序之后取到对应分页的结果集返回给客户端。
注:实际上
ES的搜索分为Query阶段和Fetch阶段两个步骤,在Query阶段各个分片返回文档Id和排序值,Fetch阶段根据文档Id去对应分片获取文档详情,上面的图片和文字说明对此进行了简化,请悉知。
现在考虑客户端获取990~1000的文档时,ES在分片存储的情况下如何给出正确的搜索结果。
获取990~1000的文档时,ES在每个分片下都需要获取1000个文档,然后由Coordinating Node聚合所有分片的结果,然后进行相关性排序,最后选出相关性顺序在990~1000的10条文档。
页数越深,每个节点处理的文档也就越多,占用的内存也就越多,耗时也就越长,这也就是为什么搜索引擎厂商通常不提供深度分页的原因了,他们没必要在客户需求不强烈的功能上浪费性能。
公众号「蝉沐风」,关注我,邂逅更多精彩文章
完。
Google搜索为什么不能无限分页?的更多相关文章
- 无限分页//////////////zz
由于网页的执行都是单线程的,在JS执行的过程中,页面会呈现阻塞状态.因此,如果JS处理的数据量过大,过程复杂,可能会造成页面的卡顿.传统的数据展现都以分页的形式,但是分页的效果并不好,需要用户手动点击 ...
- 1、SQL可搜索可排序可分页存储过程, 2、范围内的随机时间 适用于sql 2008以上
-- ============================================= -- Author: 蜘蛛王 -- Create date: 2015-10-29 -- Descri ...
- 技术|程序员必须要学会Google搜索技巧
程序员必须要学会Google搜索技巧 摘要: 因为Google在我天朝被墙,学FQ请通过Bing进行搜索如何FQGoogle搜索技巧我曾经多次劝我的另一个朋友花10分钟学习一下Google通配符的使用 ...
- google搜索技巧汇总
由于不能访问google,可访问ggso.in进行搜索. 简单整理记录一下常用的一些Google搜索技巧:或操作一般搜索时,如果输入多个词,默认是与的关系,如输入词1和词2,即搜索同时包含词1和词2的 ...
- JS实现无限分页加载——原理图解
由于网页的执行都是单线程的,在JS执行的过程中,页面会呈现阻塞状态.因此,如果JS处理的数据量过大,过程复杂,可能会造成页面的卡顿.传统的数据展现都以分页的形式,但是分页的效果并不好,需要用户手动点击 ...
- Google搜索命令语法大全
以下是目前所有的Google搜索命令语法,它不同于Google的帮助文档,因为这里介绍 了几个Google不推荐使用的命令语法.大多数的Google搜索命令语法有它特有的使用格式,希望大家能正确使用. ...
- 访问Google搜索,Google学术镜像搜索
Google学术镜像搜索:http://dir.scmor.com/google/ 不用FQ也能访问谷歌搜索网站,让我们一起Google 不用FQ也能访问谷歌搜索网站,让我们一起Google(摘自:h ...
- 十大谷歌Google搜索技巧分享
前言:多数人在使用Google搜索的过程是非常低效和无谓的,如果你只是输入几个关键词,然后按搜索按钮,你将是那些无法得到Google全部信息的用户,在这篇文章中,Google搜索专家迈克尔.米勒将向您 ...
- Google搜索镜像
From:http://www.cnblogs.com/killerlegend/p/3783744.html Date:2014.6.12 By KillerLegend Google 搜索:htt ...
随机推荐
- Vue Element ui密码框校验
<el-form-item prop="repeat_Password" class="userName_color"> <el-input ...
- Pascal的旅行
[问题描述] 一块的nxn游戏板上填充着整数,每个方格上为一个非负整数.目标是沿着从左上角到右下角的任何合法路径行进,方格中的整数决定离开该位置的距离有多大,所有步骤必须向右或向下.请注意,0是一个死 ...
- Thread中,run方法和start方法的区别
1. 通过调用Thread类中的start()方法可以启动一个线程,但是线程并不是立刻运行,而是处于就绪态,一旦获取cpu时间片,则会立即运行run()方法 2. start()方法实现了多线程运行, ...
- 企业需要使用网络损伤仪 WANsim 的帮助,以便更高效地迁移到云端
正确解决与云环境中的应用程序部署有关的问题需要针对每个系统的独特需求以寻找特定的网络工具.网络损伤仪 WANsim 助力企业更高效地迁移到云端! 起初,云厂商以在云端办公相对于传统方式拥有更高的可靠性 ...
- 记一次线上websocket返回400问题排查
现象 生产环境websocket无法正常连接,服务端返回400 bad request,开发及测试环境均正常. 抓包排查 src:nginx服务器 172.16.177.193dst:imp应用服务器 ...
- SpringMVC踩坑2
Request processing failed; nested exception is org.mybatis.spring.MyBatisSystemException: nested exc ...
- vue - scss 引入 外部 在线 css
<style lang="scss"> @import url('https://fonts.googleapis.com/css2?family=Lobster&am ...
- gin框架使用【5.表单参数】
curl http://127.0.0.1:8080/users -X POST -d 'name=juanmaofeifei&age=10' package main import ( &q ...
- Educational Codeforces Round 121 (Rated for Div. 2)——A - Equidistant Letters
A - Equidistant Letters 题源:https://codeforces.com/contest/1626/problem/A 今天上午VP了这场CF,很遗憾的是一道题也没写出来,原 ...
- 关于fiddler抓包一键生成python脚本
本人贡献一篇关于抓包转换成脚本的文章 步骤一 打开fiddler,抓到包之后,保存成txt文件 步骤二 脚本里str_filename改成保存的文件名 步骤三 执行脚本一键转换 附上脚本,感谢关注~ ...