java实现wordCount的map
打开IDEA,File——new ——Project,新建一个项目
我们已经安装好了maven,不用白不用
这里不要选用骨架,Next。在写上Groupid,Next。
写上项目名称,finish。ok。
一个项目就建好了,他长这样:
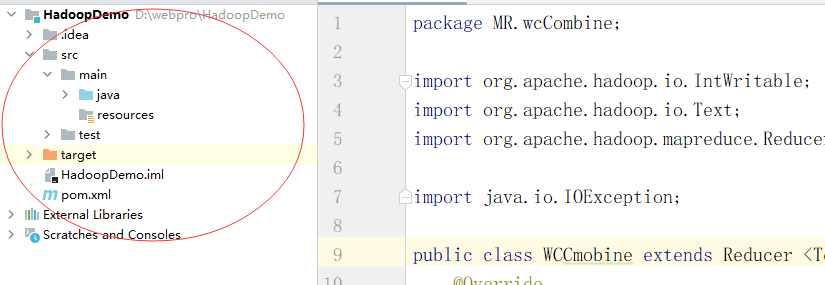
新建的项目要配置一下maven。毕竟我们马上就要用它。然后导入依赖
打开pom.xml
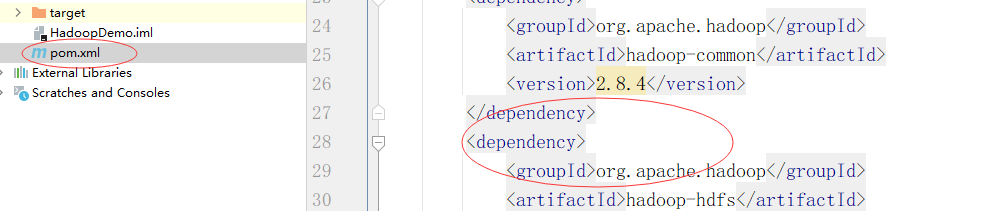
不愿意一个一个敲的话,可以使用cv大法。
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
等待下载的时候我们可以创建项目了。打开src——main——java,右键Package,我们在这里新建一个package。我们在这里包里面写一个wordcount的案例
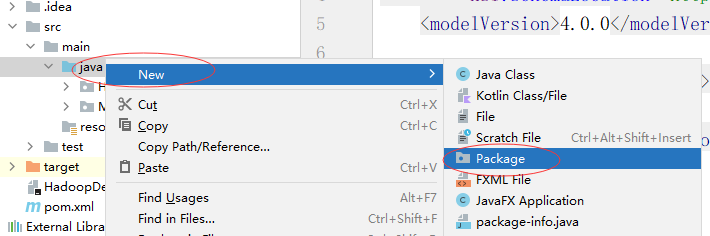
名字就叫MR
 .
.
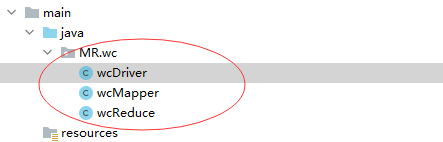
mr下再建一个包:wc。如图:

在wc下新建一个java类:wcMapper。这个类负责读取单词,生成map(键值对)
再创建一个wcReduce类。这个类负责聚合,把key相同的数据放到一起,并且累加value。
再创建一个wcDriver类,驱动类主要用于关联Mapper 和 Reducer 以及 提交整个程序。就像这样:
在写代码之前,我们先看一个mapreduce编程规范:
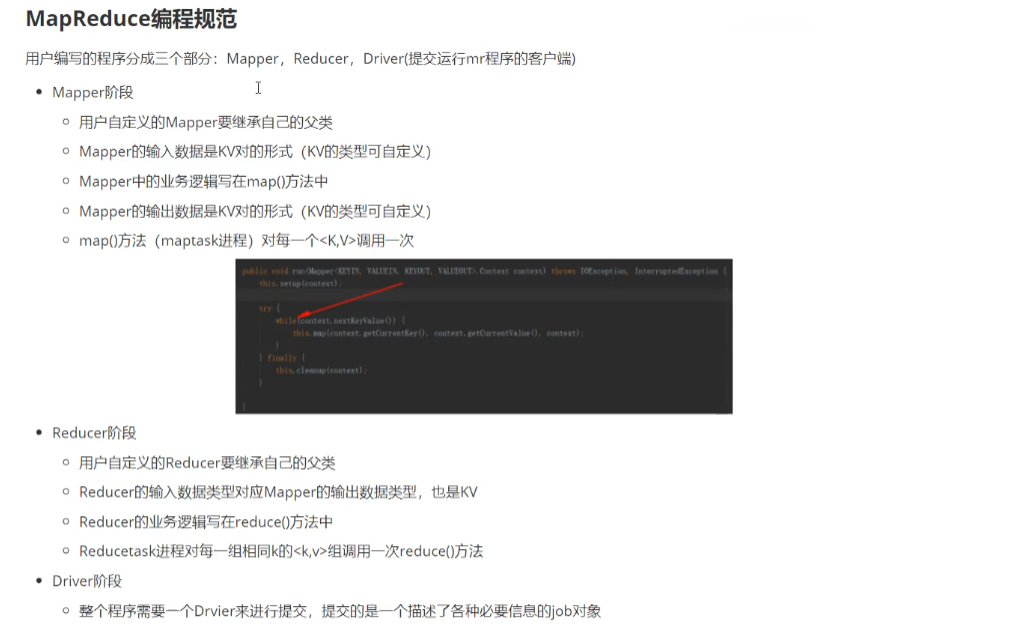
继续看代码,我们先写wcMapper类
package MR.wc;
/**
* 按行读取数据,拆成一个一个的单词
* */
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**继承Mapper类,这个类要是hadoop.mapreduce.Mapper
* 这里有一个泛型, Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>KEYIN,VALUEIN 规定数据是以什么类型进入map程序(MR程序提供了几种类型)
* KEYIN这个参数表示读取文件的行数,一般是数字类型。由于是文件可能会很大,一般不用int,而是用long
* VALUEIN这个参数表示读取数据的格式,也就是单词的格式,这里就是字符串
* 我们的对象要在节点之间通过网络传输,就需要序列化。但是java的序列化是一个重量级序列化框架,一个对象被序列化后,会附带很多额外的信息
* (各种校验信息,header,继承体系等),不便于在网络中高效传输。所以hadoop开发了一套序列化机制(writable),精简,高效
*
*
*/
public class wcMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
Text ko=new Text();
IntWritable vo=new IntWritable(1);//value值默认为1
//重写map方法,key跟value是我们读取进来的数据,数据处理玩以后就放到congtext(上下文)里面
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//读取到的这一行数据先转成String类型
String line = value.toString();
//按照空格切分单词
String[] words = line.split(" ");
//处理数据
for (String word : words) {
//keyout设置成单词
ko.set(word);
//通过上下把处理好的数据写出
context.write(ko,vo);
}
}}
到这里,map这个过程就写完了,这个过程就实现了按行读取数据,并且把单词转化成了key,value的形式,给每个单词的value值标成了1,然后通过上下文把数据写出,在wc这个程序中,实际上就是把这个key,value传给了wcRecude。让reduce过程去按照key聚合value。
常用java类型对应的HadoopWritable类型:

java实现wordCount的map的更多相关文章
- Spark:用Scala和Java实现WordCount
http://www.cnblogs.com/byrhuangqiang/p/4017725.html 为了在IDEA中编写scala,今天安装配置学习了IDEA集成开发环境.IDEA确实很优秀,学会 ...
- Java集合框架之map
Java集合框架之map. Map的主要实现类有HashMap,LinkedHashMap,TreeMap,等等.具体可参阅API文档. 其中HashMap是无序排序. LinkedHashMap是自 ...
- Java中如何遍历Map对象的4种方法
在java中遍历Map有不少的方法.我们看一下最常用的方法及其优缺点. 既然java中的所有map都实现了Map接口,以下方法适用于任何map实现(HashMap, TreeMap, LinkedHa ...
- JAVA的容器---List,Map,Set (转)
JAVA的容器---List,Map,Set Collection├List│├LinkedList│├ArrayList│└Vector│ └Stack└SetMap├Hashtable├HashM ...
- 转!! Java中如何遍历Map对象的4种方法
在Java中如何遍历Map对象 How to Iterate Over a Map in Java 在java中遍历Map有不少的方法.我们看一下最常用的方法及其优缺点. 既然java中的所有map都 ...
- Java 集合系列 15 Map总结
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 08 Map架构
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- 【转】Java中如何遍历Map对
在Java中如何遍历Map对象 How to Iterate Over a Map in Java 在java中遍历Map有不少的方法.我们看一下最常用的方法及其优缺点. 既然java中的所有map都 ...
- 【转】Java中如何遍历Map对象的4种方法
原文网址:http://blog.csdn.net/tjcyjd/article/details/11111401 在Java中如何遍历Map对象 How to Iterate Over a Map ...
随机推荐
- 在字节跳动,一个更好的企业级SparkSQL Server这么做
SparkSQL是Spark生态系统中非常重要的组件.面向企业级服务时,SparkSQL存在易用性较差的问题,导致难满足日常的业务开发需求.本文将详细解读,如何通过构建SparkSQL服务器实现使用效 ...
- Python模块 | EasyGui
(Python模块 | EasyGui | 2021/04/08) 目录 什么是 EasyGUI? [EasyGui中的函数] msbox | 使用示例 ynbox | 使用示例 ccbox | 使用 ...
- 虚拟 DOM 与 DOM Diff
虚拟 DOM 与 DOM Diff 本文写于 2020 年 9 月 12 日 虚拟 DOM 在今天已经是前端离不开的东西了,因为他的好处实在是太多了. 在<高性能 JavaScript>一 ...
- 搞定了!OAuth2使用验证码进行授权
现在验证码登录已经成为很多应用的主流登录方式,但是对于OAuth2授权来说,手机号验证码处理用户认证就非常繁琐,很多同学却不知道怎么接入. 认真研究胖哥Spring Security OAuth2专栏 ...
- 03-数据结构(C语言版)
Day01 笔记 1 数据结构基本理论 1.1 算法五个特性: 1.1.1 输入.输出.有穷.确定.可行 1.2 数据结构分类 1.2.1 逻辑结构:集合.线性.树形.图形 1.2.2 物理结构:顺序 ...
- 【SSM框架】Spring笔记 --- 事务详解
1.Spring的事务管理: 事务原本是数据库中的概念,在实际项目的开发中,进行事务的处理一般是在业务逻辑层, 即 Service 层.这样做是为了能够使用事务的特性来管理关联操作的业务. 在 Spr ...
- js 动画补间 Tween
1 /* RunningList (触发过程中可以安全的删除自己) 2 如果触发过程中删除(回调函数中删除正在遍历的数组), 不仅 len 没有变(遍历前定义的len没有变, 真实的len随之减少), ...
- 三面阿里,被Java面试官虐哭!现场还原真实的“被虐”场景
前言 人人都有大厂梦,我也不例外,从大三开始,就一直想进入阿里工作,大毕竟是大厂,想想也没那么容易,不过好在自己学历还过得去,项目经验也有得讲,所以今年也斗胆尝试了一下,直接就投了阿里云计算.简历是过 ...
- MySQL、SqlServer、Oracle,这三种数据库的优缺点,你知道吗?
盘点MySQL.SqlServer.Oracle 三种数据库优缺点 MySQL SqlServer Oracle 一.MySQL 优 点 体积小.速度快.总体拥有成本低,开源:支持多种操作系统:是开源 ...
- 接口测试postman深度挖掘应用①
一.测试接口前需要搞明白的原理: 1.在讲如何使用postman时,我们首先应该要了解网络的请求相应的知识,下面以fiddle进行抓包为例分析: 通过fiddler抓包我们不难发现,客户端也就是用户会 ...