java实现wordCount的map
打开IDEA,File——new ——Project,新建一个项目
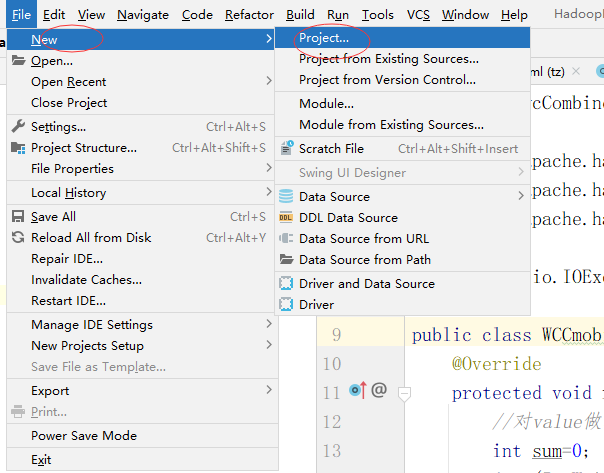
我们已经安装好了maven,不用白不用
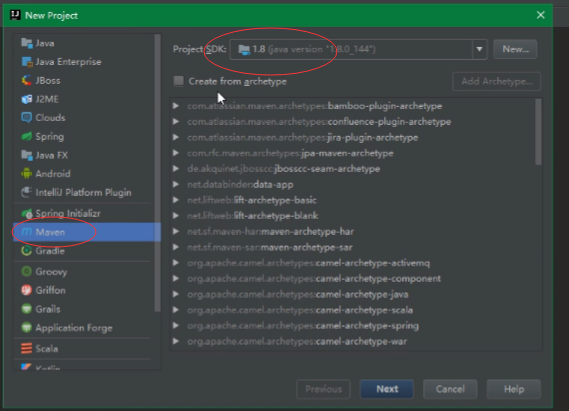
这里不要选用骨架,Next。在写上Groupid,Next。
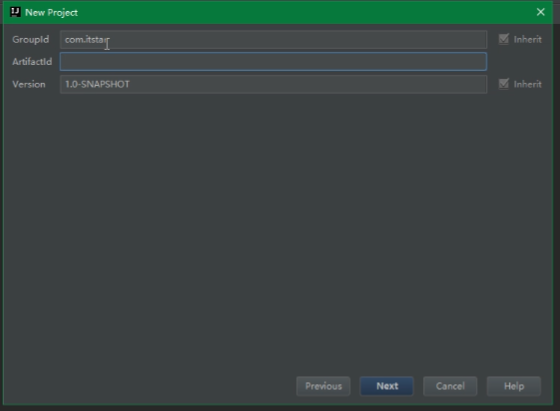
写上项目名称,finish。ok。
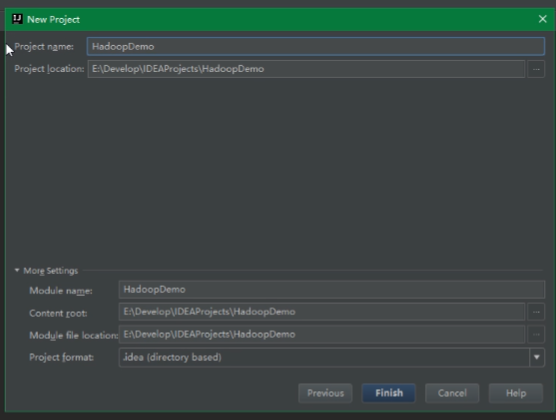
一个项目就建好了,他长这样:
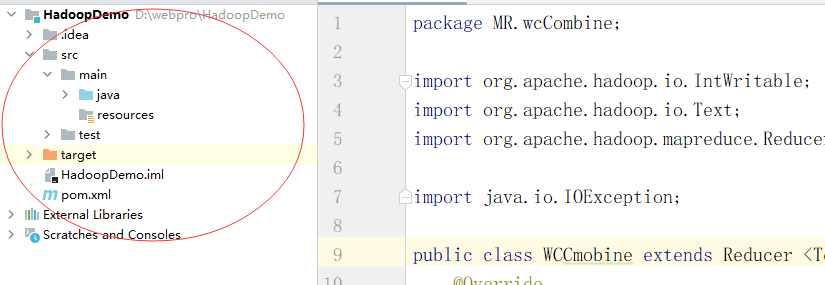
新建的项目要配置一下maven。毕竟我们马上就要用它。然后导入依赖
打开pom.xml
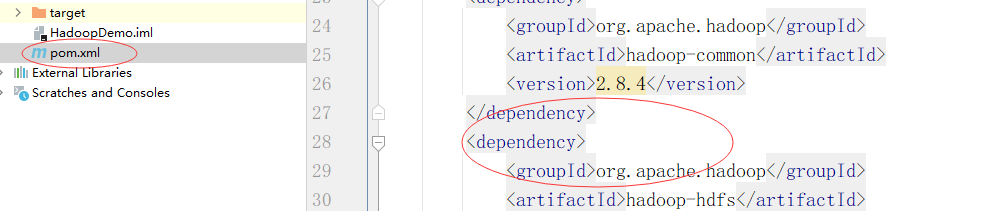
不愿意一个一个敲的话,可以使用cv大法。
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
等待下载的时候我们可以创建项目了。打开src——main——java,右键Package,我们在这里新建一个package。我们在这里包里面写一个wordcount的案例
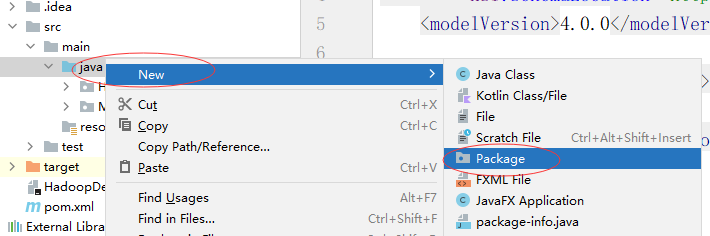
名字就叫MR
 .
.
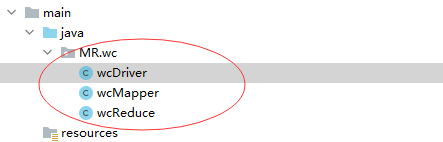
mr下再建一个包:wc。如图:

在wc下新建一个java类:wcMapper。这个类负责读取单词,生成map(键值对)
再创建一个wcReduce类。这个类负责聚合,把key相同的数据放到一起,并且累加value。
再创建一个wcDriver类,驱动类主要用于关联Mapper 和 Reducer 以及 提交整个程序。就像这样:
在写代码之前,我们先看一个mapreduce编程规范:
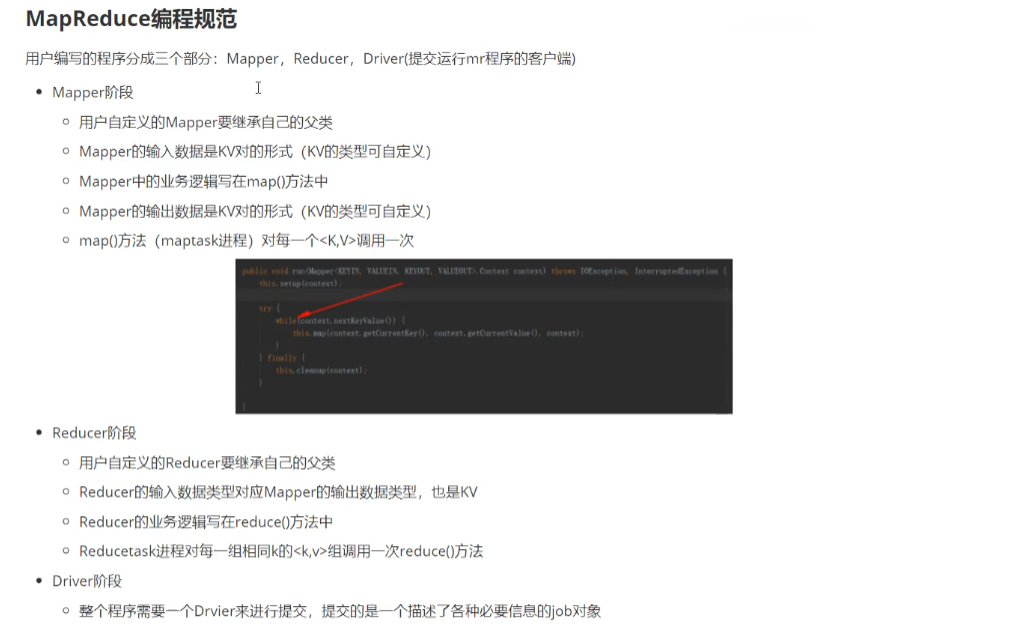
继续看代码,我们先写wcMapper类
package MR.wc;
/**
* 按行读取数据,拆成一个一个的单词
* */
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**继承Mapper类,这个类要是hadoop.mapreduce.Mapper
* 这里有一个泛型, Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>KEYIN,VALUEIN 规定数据是以什么类型进入map程序(MR程序提供了几种类型)
* KEYIN这个参数表示读取文件的行数,一般是数字类型。由于是文件可能会很大,一般不用int,而是用long
* VALUEIN这个参数表示读取数据的格式,也就是单词的格式,这里就是字符串
* 我们的对象要在节点之间通过网络传输,就需要序列化。但是java的序列化是一个重量级序列化框架,一个对象被序列化后,会附带很多额外的信息
* (各种校验信息,header,继承体系等),不便于在网络中高效传输。所以hadoop开发了一套序列化机制(writable),精简,高效
*
*
*/
public class wcMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
Text ko=new Text();
IntWritable vo=new IntWritable(1);//value值默认为1
//重写map方法,key跟value是我们读取进来的数据,数据处理玩以后就放到congtext(上下文)里面
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//读取到的这一行数据先转成String类型
String line = value.toString();
//按照空格切分单词
String[] words = line.split(" ");
//处理数据
for (String word : words) {
//keyout设置成单词
ko.set(word);
//通过上下把处理好的数据写出
context.write(ko,vo);
}
}}
到这里,map这个过程就写完了,这个过程就实现了按行读取数据,并且把单词转化成了key,value的形式,给每个单词的value值标成了1,然后通过上下文把数据写出,在wc这个程序中,实际上就是把这个key,value传给了wcRecude。让reduce过程去按照key聚合value。
常用java类型对应的HadoopWritable类型:

java实现wordCount的map的更多相关文章
- Spark:用Scala和Java实现WordCount
http://www.cnblogs.com/byrhuangqiang/p/4017725.html 为了在IDEA中编写scala,今天安装配置学习了IDEA集成开发环境.IDEA确实很优秀,学会 ...
- Java集合框架之map
Java集合框架之map. Map的主要实现类有HashMap,LinkedHashMap,TreeMap,等等.具体可参阅API文档. 其中HashMap是无序排序. LinkedHashMap是自 ...
- Java中如何遍历Map对象的4种方法
在java中遍历Map有不少的方法.我们看一下最常用的方法及其优缺点. 既然java中的所有map都实现了Map接口,以下方法适用于任何map实现(HashMap, TreeMap, LinkedHa ...
- JAVA的容器---List,Map,Set (转)
JAVA的容器---List,Map,Set Collection├List│├LinkedList│├ArrayList│└Vector│ └Stack└SetMap├Hashtable├HashM ...
- 转!! Java中如何遍历Map对象的4种方法
在Java中如何遍历Map对象 How to Iterate Over a Map in Java 在java中遍历Map有不少的方法.我们看一下最常用的方法及其优缺点. 既然java中的所有map都 ...
- Java 集合系列 15 Map总结
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 08 Map架构
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- 【转】Java中如何遍历Map对
在Java中如何遍历Map对象 How to Iterate Over a Map in Java 在java中遍历Map有不少的方法.我们看一下最常用的方法及其优缺点. 既然java中的所有map都 ...
- 【转】Java中如何遍历Map对象的4种方法
原文网址:http://blog.csdn.net/tjcyjd/article/details/11111401 在Java中如何遍历Map对象 How to Iterate Over a Map ...
随机推荐
- 如何在 pyqt 中解决启用 DPI 缩放后 QIcon 模糊的问题
问题描述 如今显示器的分辨率越来越高,如果不启用 DPI 缩放,软件的字体和图标在高分屏下就会显得非常小,看得很累人.从 5.6 版本开始,Qt 便能支持 DPI 缩放功能,Qt6 开始这个功能是默认 ...
- 评估海外pop点网络质量,批量探测到整个国家运营商ip地址段时延
1 查询当地供应商所有AS号和IP地址段,如下 可以手动复制也可以爬下来,此次测试地址不多,手动复制下来再做下格式话 61.99.128.0/17 61.99.0.0/16 61.98.96.0/20 ...
- 【多线程】线程创建方式三:实现callable接口
线程创建方式三:实现callable接口 代码示例: import org.apache.commons.io.FileUtils; import java.io.File; import java. ...
- netty系列之:netty对marshalling的支持
目录 简介 netty中的marshalling provider Marshalling编码器 Marshalling编码的另外一种实现 总结 简介 在之前的文章中我们讲过了,jboss marsh ...
- 单例模式与pickle模块
目录 设计模式之单例模式 pickle模块 设计模式之单例模式 设计模式是前辈们发明的经过反复验证用于解决固定问题的固定套路,在IT行业中设计模式总共有23种,可以分为三大类:创建型.结构型.行为型. ...
- typora的下载和基本的使用
目录 typora的下载和基本的使用 typora的下载 typora基本的使用 选择自己喜爱的主题 创建标题 进入编程环境 改变文本样式 插入链接 插入图片 有序列表 无序列表 创建表格 单选框 表 ...
- 【Java面试】简述一下你对线程池的理解?
到底是什么面试题, 让一个工作了4年的精神小伙,只是去参加了一场技术面试, 就被搞得精神萎靡.郁郁寡欢! 这一切的背后到底是道德的沦丧,还是人性的扭曲. 让我们一起揭秘一下这道面试题. 关于, &qu ...
- README.exe 是的,你看错是EXE
SmartIDE让你的README变成可执行文档,再也不用编写无用的文档,再也不必操心环境问题. 作为开发者,拿到一个新的代码库的时候一般都会先去看README文件,通过这个文件可以知道这套代码所 ...
- python基础学习7
python基础学习7 内容概要 字符串的内置方法 字符串的内置方法(补充) 列表的内置方法 可变类型与不可变类型 队列与堆栈 内容详情 字符串的内置方法 # 1.strip 移除字符串首尾的指定字符 ...
- torch.nn.MSELoss()函数解读
转载自:https://www.cnblogs.com/tingtin/p/13902325.html