Redis高可用之主从复制原理演进分析
Redis高可用之主从复制原理演进分析
在很久之前写过一篇 Redis 主从复制原理的简略分析,基本是一个笔记类文章。
一、什么是主从复制
1.1 什么是主从复制
主从复制,从名字可以看出,至少需要 2 台 Redis 服务器,一台叫主 Redis 服务器,一台叫从 Redis 服务器,也可以把他们叫做主节点(主 Redis 服务器)从节点(从 Redis 服务器)。然后把主 Redis 服务器上的数据复制到从 Redis 服务器上,这就是主从复制。后续也会源源不断的把数据从主节点复制到从节点。
1.2 怎么设置主从复制
怎么设置主 Redis 服务器,怎么设置从 Redis 服务器?
比如有 2 台 Redis 服务器,ip 分别为:192.168.1.100 和 192.168.1.101。
- 第一种方法
设置方法:在 Redis 的配置文件 redis.conf 中配置:replicaof masterip masterport
比如将 192.168.1.100 这台服务器设置为主(master)服务器,那么就在服务器 192.168.1.101 的配置文件里设置如下:
replicaof 192.168.1.100 6379
然后重启服务器,这样主服务器就是 192.168.1.100,从服务器就是 192.168.1.101。
- 第二种方法
还可以用 redis-cli 客户端连接到 192.168.1.101,然后执行命令 replicaof 192.168.1.100 6379。
这种方式如果从 Redis 重启后,主从关系就消失了。
- 第三种方法
在 redis-server 启动参数中增加 --replicaof 192.168.1.100 6379 参数
说明:Redis 5.0 后,replicaof 命令已经替换了 slaveof 命令,但是为了兼容 slaveof 还是可以用。
一台主服务器也可以有多台从服务器,从服务器也可以有从服务器。
二、为什么要主从复制
主从复制后就有多份数据,相当于有多个副本,既是备份也是容灾。
为什么要有主从复制功能?
其实问的就是 Redis 主从复制有什么作用,带来了啥好处。
- 负载均衡
数据量大的时候,为了减轻服务器压力,会用读写分离模式来分摊流量,主服务器负责写,从服务器负责读。当然主服务器也可以读。
- 故障恢复
主服务器出现问题时候,从服务器还可以继续提供服务。并且也可以把从服务器提升为主服务器,这就是 Redis 的哨兵模式。
高可用的数据冗余方式。
- 数据冗余
多了一份数据,故障了,就可以快速恢复数据。
三、怎么进行主从复制
主从数据同步就是把主服务器生成的 RDB 数据文件复制到从服务器上,然后解析 RDB 文件,在从服务器上生成对应的数据。或同步相关的命令。
3.1 主从复制同步的演进
在 Redis2.8 之前,都是全量数据复制。也就是说,断线重连后,也是重新全量复制数据。这种方式把很多原来同步过了的数据又重新同步一次,这种方式的数据同步效率太低。
在 Redis2.8 之后,增加了部分重同步模式,也就是增加增量数据同步,只同步需要同步的数据。这就改进了之前的数据同步模式。
什么时候进行全量数据同步?第一次数据同步时候就进行全量数据同步。有时主从数据不一致时也需要全量同步。
什么时候进行增量数据同步?比如断线重连后,就进行增量数据同步。
3.2 Redis2.8之前复制
Redis2.8 之前主从同步有 2 个部分:全量同步,命令传播。
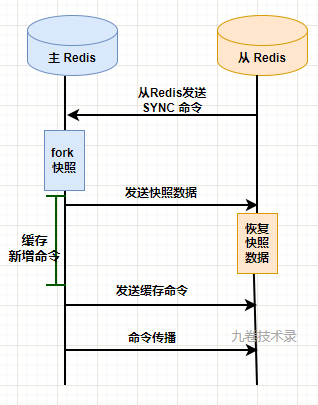
全量同步:主从节点建立连接,主节点回复后,从节点向主节点发送 SYNC 命令,把从节点服务器状态更新到当前主节点服务器状态。主节点创建全量数据的 RDB 快照文件,然后发送给从节点,从节点加载 RDB 文件恢复对应的数据。主节点再继续发送复制过程中积压在缓冲区内的新增命令到从节点,使从节点的数据到达和主节点数据一致。
命令传播:主节点和从节点保持连接,主节点将继续向从节点发送命令流,保证主节点上的数据集发生了变更同样在从数据集上也发生变更。
流程图:
3.3 Redis2.8之后复制
以 redis6.0 版本来介绍。
Redis2.8 之后全量复制与上面(Redis2.8之前)复制步骤差不多,SYNC 命令变成了 PSYNC 命令,之后增加了部分重同步。部分重同步改进了之前的每次需要全量同步问题。
增加了部分重同步,这个要怎么做才能兼容之前的全量同步呢?怎么知道从库复制到哪儿了?第一个从库肯定要记录下从库复制到哪儿了,下次断线重连时就可以告诉主库该从哪个地方开始复制了。主库也要记录自己的一些复制信息。Redis 用了几个概念就把这些问题给解决了,Replication ID,offset,replication_backlog。
- Replication ID:复制 ID。这是一个较大的随机字符串,标记一个给定的数据集。每个主节点都会用这个 Repli ID 来标识内部数据集,从节点 ID。当从节点加入时,这个 repli id 就初始化了。
- offset:复制偏移量。每个主节点都有这个 offset 偏移量,主节点将自己产生的数据发送给从节点时,发送多少字节数据,自身 offset 就会增加多少。从节点也有自己 offset,从节点写入数据时,offset 也会增加。断线重连时,就可以知道从哪里开始同步了。offset 需配合下面的复制积压缓冲区工作。
- replication_backlog:复制积压缓冲区。它是在主节点上的一个环形缓冲区,用来存储主节点向从节点传递的命令。它是大小固定,存储的命令有限,所有超出了就会删除。从节点进行增量同步时,主节点会根据 offset 从 replication_backlog 中拷贝从节点缺失的数据到从节点。
Replication ID, offset,这一对来标识数据集版本。
Redis2.8之后就是用上面这几个概念实现部分数据重同步的。从节点发送主节点的 replid 和从节点的一个 offset,主节点拿到这个replid 和自己的 replid 比较,如果是一样,并且这个 offset 也在 backlog 中能找到,那就可以可以进行部分重同步。
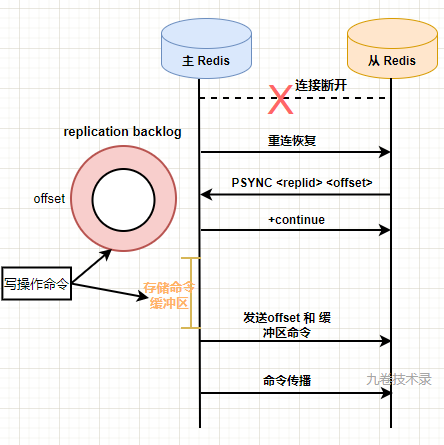
全量复制步骤
- 主从节点先建立连接
建立连接后,从节点使用命令 PSYNC <replid> <offset> 向主节点发起同步请求。如果主从节点是第一次复制,那么命令为 PSYNC ? -1,replid 为 ?,因为是第一次复制不知道主库的 replid。offset 为 -1,表示第一次复制。
主节点收到 PSYNC 命令后,会用 FULLRESYNC 命令响应,带上主节点的 replid 和 offset 返回给从库,从库会记录下这两个参数。便于以后判断是否需要部分重同步。
- 同步数据
主节点执行 bgsave 命令生成 RDB 文件,生成完后把文件发送给从节点,从节点加载 RDB 文件。这个过程中,主节点不会阻塞,依然会接收客户端的命令请求,当然,这些请求不会写在之前的 RDB 文件里,为了保持主从数据一致,这些命令会存储在 replication buffer 中,记录 RDB 文件后的所有写操作。
- 同步缓冲的命令数据
协商就是根据先前定义好步骤来发送相关命令,为同步做准备工作。有点协议的意思。步骤如下:
当主库把 RDB 文件传送给从节点完成后,就会把 replication buffer 中的写命令操作发送给从节点,从节点执行这些操作命令,主从节点同步完成。
- 命令传播
之后会继续向从节点发送主节点的操作命令,从节点执行这些命令,保持主从数据的一致。
上面是一个主体的同步步骤,更加详细的步骤要分析源码了。
发送步骤与 Redis2.8 之前全量同步没有多大区别。
部分数据同步
部分数据同步,解决的是主从节点在同步命令时候,网络断了在连上时,Redis2.8 之前会在全量同步数据,显然开销太大,不合理。能不能只把断线后的数据同步一份,而不是全量同步?
网络断线后,就有部分命令数据没有同步到从节点上去,那我们能不能保存这部分命令数据?重连后,将断开期间的这部分命令重新同步给从节点,这样就不需要全量同步。
Redis2.8 之后引入了 replication_backlog 复制积压缓冲区,前面有讲到这个概念。命令一方面会传输给从节点,另外还会记录在这个复制积压缓冲区里。Redis 使用一个环形缓冲区的结构保存最近的一些命令。在缓冲区中,对字节进行编号,这个编号在 Redis 中叫复制偏移量。

是否部分同步条件?
- 从节点 replid 和 主节点的 replid 相同
- 复制偏移量 offset 在复制积压缓冲区的 backlog_off 和 offset 范围之间。
如果满足上面的 2 个条件,就进行部分数据重同步。
四、Redis4.0的同源增量同步
先看两个问题
1.从节点重启后丢失了原主节点的节点编号和复制偏移量,这导致重启后需要全量复制,这个很好办,把这些信息保存下来
2.主从切换后,主节点信息变化了,导致从节点需要全量数据同步,这个也好办,只要能确认新主节点数据是从原主节点复制过来就可以了
Redis4.0 后,对 PSYNC 进行了改进,提出了同源增量复制解决方案,来解决上面提到的两个全量复制问题。
第1个:从节点重启后,需要跟主节点全量数据同步,为什么?本质原因,是从节点丢失了主节点的编号信息和偏移量信息。Redis4.0后,就把主节点的编号信息写入到 RDB 中持久化保存。
第2个:主从切换后,从节点需要和主节点全量同步,为什么?原因就是新的主节点不认识原来主节点的编号信息。切换后怎么才能识别到呢?Redis4.0 后,主从切换后,新的主节点会将先前的主节点信息记录下来,这样新主节点就知道自己原先数据是从哪个旧主节点同步来的,大家都是从同一个地方出来的,应该接受部分数据同步策略。
五、Redis6.0无盘同步复制
什么叫无盘?
原先的同步复制是通过 fork 一个子进程生成 RDB 快照文件,RDB 存储在磁盘上,然后传输 RDB 文件,从节点服务器在恢复 RDB 文件数据。
无盘,就是说不生成 RDB 文件,不通过 RDB 来传输数据。而是直接通过网络来传输数据。
怎么做到无盘呢?
Redis6.0 后,它也是先 fork 一个子进程,这个子进程 dump 数据,它通过管道回写给主节点,主节点在将数据发送给从节点,这样的过程就是无盘传输。
六、Redis7.0共享复制缓冲区
6.1 多从库时主库占用内存过多问题
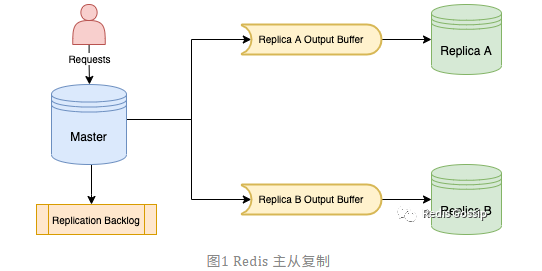
(from: https://mp.weixin.qq.com/s/UlHksrqFq0yfKh1uMFvYNg 作者:shooterIT)
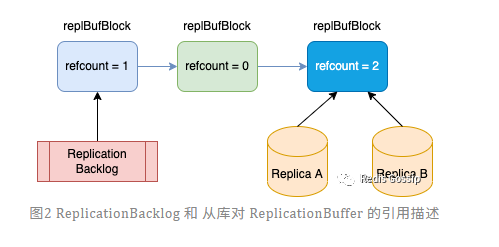
如图所示,对于 Redis 主库,当用户的写请求到达时,主库会将变更命令分别写入所有从库的缓冲区(OutputBuffer),以及复制积压缓冲区(ReplicationBacklog)。全量同步也会执行该逻辑。所以在全量同步阶段经常会触发 client-output-buffer-limit,主库断开与从库的连接,导致主从同步失败,甚至出现循环持续失败的情况。
所有从库的连接在主库上是独立的,也就是说每个从库 OutputBuffer 占用的内存空间也是独立的,那么主从复制消耗的内存就是所有从库缓冲区内存大小之和。如果我们设定从库的 client-output-buffer-limit 为 1GB,如果有三个从库,则在主库上可能会消耗 3GB 的内存用于主从复制。另外,真实环境中从库的数量不是确定的,这也导致 Redis 实例的内存消耗不可控。
from: https://mp.weixin.qq.com/s/UlHksrqFq0yfKh1uMFvYNg 作者:shooterIT
6.2 OutputBuffer 拷贝和释放的堵塞问题
- ReplicationBacklog 的限制
- OutputBuffer 拷贝和释放的堵塞问题
具体内容请看这里:https://mp.weixin.qq.com/s/UlHksrqFq0yfKh1uMFvYNg
6.3 解决方案:共享复制缓冲区
具体方案请看这里:https://mp.weixin.qq.com/s/UlHksrqFq0yfKh1uMFvYNg 作者:shooterIT
七、参考
- https://redis.io/docs/manual/replication/ redis 复制功能
- https://mp.weixin.qq.com/s/a4JTKKTCEyz1W0FIF5fVZA Redis 主从复制的演进历程与百度实践 - 百度
- https://mp.weixin.qq.com/s/UlHksrqFq0yfKh1uMFvYNg Redis 7.0 共享复制缓冲区的设计与实现-ShooterIT
- 《Redis设计与实现》
Redis高可用之主从复制原理演进分析的更多相关文章
- Redis高可用之主从复制实践(四)
0.Redis目录结构 1)Redis介绍及部署在CentOS7上(一) 2)Redis指令与数据结构(二) 3)Redis客户端连接以及持久化数据(三) 4)Redis高可用之主从复制实践(四) 5 ...
- redis高可用(主从复制)
熟练掌握redis需要从 reids如何操作5种基本数据类型,redis如何集群,reids主从复制,redis哨兵机制redis持久化 reids主从复制 的作用可以:实现数据备份,读写分离,集群, ...
- Redis高可用之哨兵模式Sentinel配置与启动(五)
0.Redis目录结构 1)Redis介绍及部署在CentOS7上(一) 2)Redis指令与数据结构(二) 3)Redis客户端连接以及持久化数据(三) 4)Redis高可用之主从复制实践(四) 5 ...
- Redis高可用之集群配置(六)
0.Redis目录结构 1)Redis介绍及部署在CentOS7上(一) 2)Redis指令与数据结构(二) 3)Redis客户端连接以及持久化数据(三) 4)Redis高可用之主从复制实践(四) 5 ...
- Redis 高可用架构设计(转载)
转载自:https://mp.weixin.qq.com/s?__biz=MzA3NDcyMTQyNQ==&mid=2649263292&idx=1&sn=b170390684 ...
- Redis如何实现高可用【主从复制+哨兵机制+keepalived】
实现redis高可用机制的一些方法: 保证redis高可用机制需要redis主从复制.redis持久化机制.哨兵机制.keepalived等的支持. 主从复制的作用:数据备份.读写分离.分布式集群.实 ...
- redis如何实现高可用【主从复制、哨兵机制】
实现redis高可用机制的一些方法: 保证redis高可用机制需要redis主从复制.redis持久化机制.哨兵机制.keepalived等的支持. 主从复制的作用:数据备份.读写分离.分布式集群.实 ...
- Redis 高可用篇:你管这叫主从架构数据同步原理?
在<Redis 核心篇:唯快不破的秘密>中,「码哥」揭秘了 Redis 五大数据类型底层的数据结构.IO 模型.线程模型.渐进式 rehash 掌握了 Redis 快的本质原因. 接着,在 ...
- Redis高可用(持久化、主从复制、哨兵、集群)
Redis高可用(持久化.主从复制.哨兵.集群) 目录 Redis高可用(持久化.主从复制.哨兵.集群) 一.Redis高可用 1. Redis高可用概述 2. Redis高可用策略 二.Redis持 ...
随机推荐
- 程序思想中的冒泡法在python和1200PLC中scl高级编程中的应用
冒泡排序:是计算机科学领域里面的一种算法. header 这个算法名字的由来是因为在执行算法的时候越小的元素会经由交换慢慢"浮"到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧 ...
- 【点击云游台湾省】今天,老子云在台湾省建了个3D房子!
今日热搜仍然聚焦台湾省,中国新闻网发文:地图已经可以显示台湾省的每个街道.网友一片叫好! 台湾省通过平面图观察,难免看的不够真切,其实现在已经可以通过3D视角云游台湾省了! 老子云这次通过自研技术,还 ...
- mysql 8.0.28 查询语句执行顺序实测结果
TL;NRs 根据实测结果,MySQL8.0.28 中 SQL 语句的执行顺序为: (8) SELECT (5) DISTINCT <select_list> (1) FROM <l ...
- Linux 基于源码安装 Redis
1.下载 Redis: 前往 Redis 官网复制 Redis 相应版本的下载链接,到终端下载 2. 进入到指定目录, 下载 redis.tar.gz 包,运行 wget + 复制的下载链接 例如: ...
- 云服务器上搭建cobalt strike遇到的一些小问题
一.前言: 当你兴高采烈的买了一台云服务器,迫不及待地想去搭建传说中的神器cobalt strike的时候,你可能会遇到以下的一些小问题,这里我会列出对应的解决方法. 二.遇到的一些小问题 1.上传文 ...
- [多校 NOIP 联合模拟 20201130 T4] ZZH 的旅行(斜率优化dp,启发式合并,平衡树)
题面 题目背景 因为出题人天天被 ZZH(Zou ZHen) 吊打,所以这场比赛的题目中出现了 ZZH . 简要题面 数据范围 题解 (笔者写两个log的平衡树和启发式合并卡过的,不足为奇) 首先,很 ...
- 【java】学习路径21-基本类型的包装类
int i =100; //Integer i2 = new Integer(100); //我们发现已被弃用,现在我们一般的方法是使用valueOf Integer i2 = null; i2 = ...
- python自学笔记10:while循环和for循环
条件控制和循环控制是两种典型的流程控制方法,前面我们写了 if 条件控制,这节讲 for 循环和 while 循环. 循环是另一种控制流程的方式,一个循环体中的代码在程序中只需要编写一次,但可能会连续 ...
- Swift中的Result 类型的简单介绍
Swift 5引入了一个新的Result类型, 它使用枚举来处理异步函数的结果. 苹果文档对该类型的描述: A value that represents either a success or a ...
- KingbaseES DBLink 扩展介绍
DBLink 扩展插件功能与 Kingbase_FDW 类似,用于远程访问KingbaseES 数据库.相比于Kingbase_FDW,DBLink 功能更强大,可以执行DML,还可以通过 begin ...