PyTables学习 (数据保存形式,对象树结构)
参考自http://www.pytables.org/usersguide/introduction.html
PyTables的主要目的是提供一个好的操作HDF5文件的方法。
HDF文件是分层数据格式(Hierarchical Data Format)的简称。数据主要由组(Groups)和数据集(Datasets)组成。其中,组的作用类似于文件夹,用于包含数据集或者其他组。组之间层层包含,构成了分层次的结构。由于HDF5文件具有分层存储的特点,可以保存元数据,支持多种压缩模式,具有即时压缩的特点。因此HDF5文件非常适合存储大容量,包含元信息的科学数据。
PyTables的数据形式
在PyTables中的数据集主要有两种形式: 表(tables)和数组(array)。
其中,表是由结构相同的记录(records)组成。记录存储了不同的字段(fields),每个字段的存储的变量的数据类型是相同的。在HDF5的术语中,表中的记录也被称为复合数据类型。
比如,声明一个类(class),包含命名的字段和类型信息:
class Particle(IsDescription):
name = StringCol(16) # 16-character String
idnumber = Int64Col() # signed 64-bit integer
ADCcount = UInt16Col() # unsigned short integer
TDCcount = UInt8Col() # unsigned byte
grid_i = Int32Col() # integer
grid_j = Int32Col() # integer # A sub-structure (nested data-type)
class Properties(IsDescription):
pressure = Float32Col(shape=(2,3)) # 2-D float array (single-precision)
energy = Float64Col(shape=(2,3,4)) # 3-D float array (double-precision)
之后,就可以基于这个类构造表,然后向其中写数据并保存。
另一个重要的是数组,他类似于表,但不同之处在于其中所有的组件都是同构的。它们有不同的特点,比如泛型,可扩展,可变长度。
主要特性
Pytables具有如下优点:Python所具备的面向对象和可内省,HDF5强大的数据管理功能,NumPy的灵活性,以及Numexpr对大规模网格对象数据的操作能力。具有以下特性:
- 支持表实体:可以定制数据,在表中添加或删除记录。还支持大量行(最多 2**63,远超出内存容量)。
- 多维和嵌套表的单元格:表中的元素可以是任意维度的数据。可以声明由其他列组成的列。
- 对表列的索引支持:对于大型表,并且想要快速查找满足某些条件的列中的值,则非常有用。
- 支持数值数组:NumPy数组,可用作表的有用补充,以存储同类数据。
- 可扩展的数组:在磁盘上的现有数组中的任何一个维度添加新元素。此外,您可以使用强大的扩展切片机制访问数据集的一部分,而无需将所有完整的数据集加载到内存中。
- 可变长度数组:数组中的元素数量可以因行而异。这在处理复杂数据时提供了很大的灵活性。
- 支持分层数据模型:允许用户清晰地构建所有数据。 PyTables 在内存中构建了一个对象树,用于复制底层文件数据结构。访问文件中的对象是通过遍历和操作此对象树来实现的。
- 用户定义的元数据:除了支持系统元数据(如表格的行数、形状、风格等)外,还可以指定任意元数据(例如,室温或收集的 IP 流量协议)作为补充实际数据的含义。
- 读取/修改通用 HDF5 文件的能力:PyTables可以访问和修改大多数 HDF5 文件,例如复合类型数据集(可以映射到 Table 对象)、同构数据集(可以映射到 Array 对象)或可变长度记录数据集(可以映射到 VLArray 对象)。此外,如果一个数据集不受支持,它将被映射到一个特殊的 UnImplemented 类(请参阅 UnImplemented 类),这将使用户看到数据在那里,尽管它无法访问(仍然可以访问数据集中的属性和一些元数据)。
- 数据压缩:支持即时数据压缩(使用 Zlib、LZO、bzip2 和 Blosc 压缩库)。当您有重复模式时,启用压缩可以节省分析数据的时间。
- 高性能 I/O:表和数组对象的读写速度仅受底层 I/O 子系统性能的限制。此外,如果您的数据是可压缩的,那么这个限制也是可以克服的!
- 支持大于 2 GB 的文件
- 与架构无关:可以在大端机器(如 Sparc 或 MIPS)上编写文件并在小端机器(如 Intel 或 Alpha)上读取。此外,在 64 位平台(Intel-64、AMD-64、PowerPC-G5、MIPS、UltraSparc)上成功进行了测试。
对象树(The Object tree)
PyTables可以在一个树状结构中管理表和数组。为了实现这个功能,PyTables动态地创建了对象树的结构,从而模拟HDF5在磁盘中的存储方式。通过遍历动态树实现对HDF5对象的读取。通过检查节点的元数据(metadata),可以了解对象中存储了什么格式的数据。
在对象树中不同的节点,是PyTables类中的实体。有几种类,但最重要的类是结点(Node),组(Group)和叶(Leaf)类。Pytables树中所有的节点(nodes)都是结点(Node)类的实体。组和叶都是Node类的子类。组实体是包含了0个或更多个叶节点的组结构。叶实体是不再包含其他组或叶,只包含实际数据的容器。表(Table),数组(Array),CArray,Earray,VLArray,以及未定(UnImplemented)类则是叶的子类。
对组和叶进行操作类似于在Unix文件系统中对文件夹和文件进行操作。在 PyTables 中,对象树中的对象通常通过完整(绝对)路径名来引用。此完整路径可以指定为字符串(例如 '/subgroup2/table3',使用"/"作分隔符),或者以自然命名访问(例如file.root.subgroup2.table3)。
并非文件中的所有数据都加载到对象树中。元数据(即,描述实际数据结构的特殊数据)仅在用户希望访问时才加载。此外,实际数据直到用户请求时才读取。使用对象树(元数据),您可以检索有关磁盘上对象的信息,例如表名、标题、列名、列中的数据类型、行数,组的形状、类型码等。您还可以在树中搜索特定类型的数据,然后读取并处理这些数据。
值得注意的是,PyTables采用了元数据缓存系统,该系统延迟加载节点(即按需加载),并卸载一段时间未使用的节点。需要强调的是,节点在未被引用之后进入缓存,并且可以直接从缓存中恢复,而无需从磁盘执行反序列化过程。此功能允许以低内存消耗快速处理具有大型层次结构的文件,同时保留以前实现的对象树的所有强大浏览功能。
为了更好地理解这个对象树实体的动态特性,让我们从一个示例PyTables脚本(可以在examples/objecttree.py中找到)开始创建一个HDF5文件:
import tables as tb class Particle(tb.IsDescription):
identity = tb.StringCol(itemsize=22, dflt=" ", pos=0) # character String
idnumber = tb.Int16Col(dflt=1, pos = 1) # short integer
speed = tb.Float32Col(dflt=1, pos = 2) # single-precision # 以写模式打开一个文件
fileh = tb.open_file("objecttree.h5", mode = "w") # 得到HDF5根组
root = fileh.root # 创建组
group1 = fileh.create_group(root, "group1")
group2 = fileh.create_group(root, "group2") # 在根组中创建数组1
array1 = fileh.create_array(root, "array1", ["string", "array"], "String array") # 分别在组1,2中创建表1,2
table1 = fileh.create_table(group1, "table1", Particle)
table2 = fileh.create_table("/group2", "table2", Particle) # 在组1中创建最后一个表
array2 = fileh.create_array("/group1", "array2", [1,2,3,4]) # 填充表格
for table in (table1, table2):
# Get the record object associated with the table:
row = table.row # Fill the table with 10 records
for i in range(10):
# First, assign the values to the Particle record
row['identity'] = f'This is particle: {i:2d}'
row['idnumber'] = i
row['speed'] = i * 2. # This injects the Record values
row.append() # Flush the table buffers
table.flush() # Finally, close the file (this also will flush all the remaining buffers!)
fileh.close()
这个小程序创建了一个名为 objecttree.h5 的 HDF5 文件,其结构如图 所示。创建文件时,对象树中的元数据会在内存中更新,而实际数据会保存到磁盘。当您关闭文件时,对象树不再可用。但是,当您重新打开此文件时,对象树将根据磁盘上的元数据在内存中重建(这是以惰性方式完成的,以便仅加载用户所需的对象),从而允许您使用它与最初创建它时的方式完全相同。
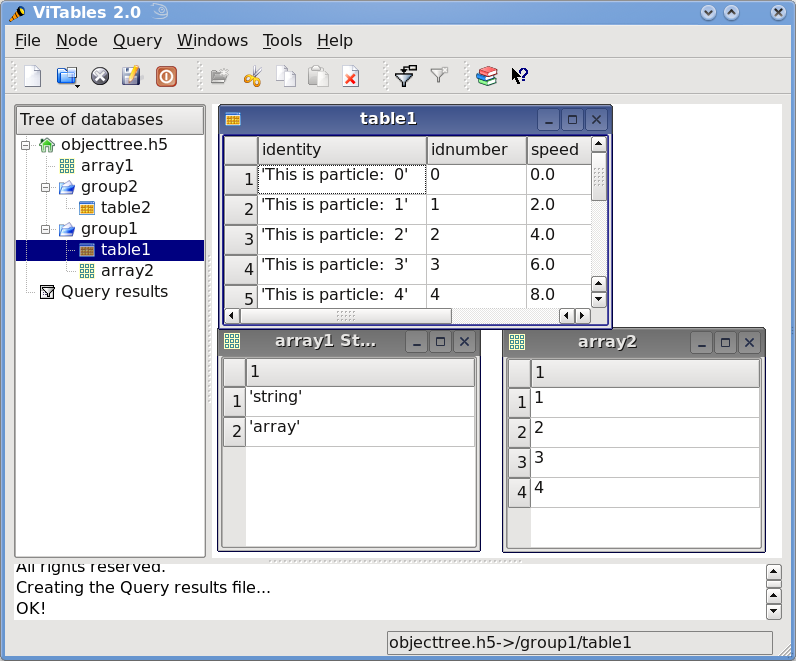
图 1:具有 2 个子组、2 个表和 1 个数组的 HDF5 示例。
在图 2 中,您可以看到读取上述 objecttree.h5 文件时创建的对象树示例(实际上,读取任何受支持的通用 HDF5 文件时总是会创建这样的对象树)。花点时间理解它是值得的,它将帮助您理解内存中 PyTables 对象的关系。

图 2:PyTables 对象树示例。
PyTables学习 (数据保存形式,对象树结构)的更多相关文章
- 【学习总结】iOS 数据保存几种方式总结
在iOS开发过程中,不管是做什么应用,都会碰到数据保存的问题.将数据保存到本地,能够让程序的运行更加流畅,不会出现让人厌恶的菊花形状,使得用户体验更好.下面介绍一下数据保存的方式: NSKeyedAr ...
- Android学习笔记——保存数据到SQL数据库中(Saving Data in SQL Databases)
知识点: 1.使用SQL Helper创建数据库 2.数据的增删查改(PRDU:Put.Read.Delete.Update) 背景知识: 上篇文章学习了保存文件,今天学习的是保存数据到SQL数据库中 ...
- Android学习笔记-保存数据的实现方法2-SharedPreferences
Android下,数据的保存,前面介绍过了,把数据保存到内存以及SD卡上,这次我们就介绍一下,更为常用的采用SharedPreferences的方式来保存数据, 1,得到SharedPreferenc ...
- Android学习笔记-保存数据的实现方法1
Android开发中,有时候我们需要对信息进行保存,那么今天就来介绍一下,保存文件到内存,以及SD卡的一些操作,及方法,供参考. 第一种,保存数据到内存中: //java开发中的保存数据的方式 pub ...
- CAD把当前图上数据保存为一个二进流对象(com接口VB语言)
主要用到函数说明: MxDrawXCustomFunction::WriteBinStreamEx 把当前图上数据保存为一个二进流对象,详细说明如下: 参数 说明 LPCTSTR pszPasswor ...
- Libgdx学习记录14——数据保存Preferences,XmlReader
在游戏过程过程中,常常需要对某些数据进行保存,以确保下次运行时能够正确读取.如游戏中的金币.道具.游戏分数.已通过的关卡等. Libgdx中常用的数据保存方式有Preferences和XmlReade ...
- 2018百度之星开发者大赛-paddlepaddle学习(二)将数据保存为recordio文件并读取
paddlepaddle将数据保存为recordio文件并读取 因为有时候一次性将数据加载到内存中有可能太大,所以我们可以选择将数据转换成标准格式recordio文件并读取供我们的网络利用,接下来记录 ...
- Delphi:ClientDataset+TDataSetProvider的数据保存问题
看到一篇介绍ClientDataSet和TDataSetProvider,非常精彩,特此保存. ==================================================== ...
- Python小数据保存,有多少中分类?不妨看看他们的类比与推荐方案...
小数据存储 我们在编写代码的时候,经常会涉及到数据存储的情况,如果是爬虫得到的大数据,我们会选择使用数据库,或者excel存储.但如果只是一些小数据,或者说关联性较强且存在存储后复用的数据,我们该如何 ...
- 深度学习数据特征提取:ICCV2019论文解析
深度学习数据特征提取:ICCV2019论文解析 Goal-Driven Sequential Data Abstraction 论文链接: http://openaccess.thecvf.com/c ...
随机推荐
- 人工智能,丹青圣手,全平台(原生/Docker)构建Stable-Diffusion-Webui的AI绘画库教程(Python3.10/Pytorch1.13.0)
世间无限丹青手,遇上AI画不成.最近一段时间,可能所有人类画师都得发出一句"既生瑜,何生亮"的感叹,因为AI 绘画通用算法Stable Diffusion已然超神,无需美术基础,也 ...
- hash和hash tree
在理想情况下,我们希望不经过任何比较,一次存取便能得到所查的记录,那就必须在记的存储位置和它的关键字之间建立一个确定的对应关系,使每个关键字和一个唯一的存储位置对应,因而在查找时候,根据这个对应关系与 ...
- 图形学101 3 transform
2d中都可以写成xy 与矩阵乘以 xy的关系 齐次坐标
- Shiro+SpringBoot前后端分离中跨域,sessionId,302问题
1.解决跨域 @Configuration public class CorsConfig { public CorsConfiguration buildConfig() { CorsConfigu ...
- [NepCTF2022]signin
signin 题目 from Crypto.Util.number import getStrongPrime,bytes_to_long from gmpy2 import powmod,is_pr ...
- lg7863
傻题. 对于相邻的每个点,从高度高的点向高度低的点连边. 依靠差分的思想,设边权是高度差. 考虑第一问,答案显然是这个图dag路径覆盖,可以运行最大流. 考虑第二问.如果每连一条链,那么答案会加上这条 ...
- Windows Python2.7环境 安装paramiko模块(转)
http://t.zoukankan.com/staffyoung-p-5587450.html 链接,网上大多数都是同一篇文章 Paramiko是用python语言写的一个模块,遵循SSH2协议,支 ...
- java通过反射将对象A得属性值赋值给对象B
java通过反射将对象A得属性值赋值给对象B //测试类1public class Test1 { private String name; private String sex; private i ...
- Traefik官方文档以及翻译文档
https://www.qikqiak.com/traefik-book/ https://doc.traefik.io/traefik/
- 宝塔Linux定时shell
定时清除缓存文件 rm -rfv /www/wwwroot/www.xxx.com/runtime 定时解压,常用于定时恢复站点 解压到当前 cd /www/wwwroot/www.xxx.com t ...