数据质量管理工具预研——Griffin VS Deequ VS Great expectations VS Qualitis
开源数据质量管理工具预研——Griffin VS Deequ VS Great expectations VS Qualitis。
概述
数据质量监控(DQC)是最近很火的一个话题,也是数据治理中最重要的一环。有一句话说得好。数据质量未必是数据治理中最重要的一部分,但是数据质量可能是让数据治理工作全部崩盘的第一步。
所以做好数据质量监控非常重要,废话少说本文将从开源数据质量解决方案预研的角度,带大家了解目前四个比较成熟的数据质量管理工具,希望对大家做技术选型的时候有一些帮助。
对于开源框架的研究,对于我们自研数据质量的工具也有巨大的帮助。
1、Apache Griffin
在开源数据质量解决方案——Apache Griffin入门宝典一文中,对Griffin有过详细的介绍。
Griffin是一个开源的大数据数据质量解决方案,由eBay开源,它支持批处理和流模式两种数据质量检测方式,是一个基于Hadoop和Spark建立的数据质量服务平台 (DQSP)。它提供了一个全面的框架来处理不同的任务,例如定义数据质量模型、执行数据质量测量、自动化数据分析和验证,以及跨多个数据系统的统一数据质量可视化。
Griffin于2016年12月进入Apache孵化器,Apache软件基金会2018年12月12日正式宣布Apache Griffin毕业成为Apache顶级项目。
Griffin官网地址:https://griffin.apache.org/
Github地址:https://github.com/apache/griffin
Griffin的架构分为三个部分。
各部分的职责如下:
- Define:主要负责定义数据质量统计的维度,比如数据质量统计的时间跨度、统计的目标(源端和目标端的数据数量是否一致,数据源里某一字段的非空的数量、不重复值的数量、最大值、最小值、top5的值数量等)
- Measure:主要负责执行统计任务,生成统计结果
- Analyze:主要负责保存与展示统计结果
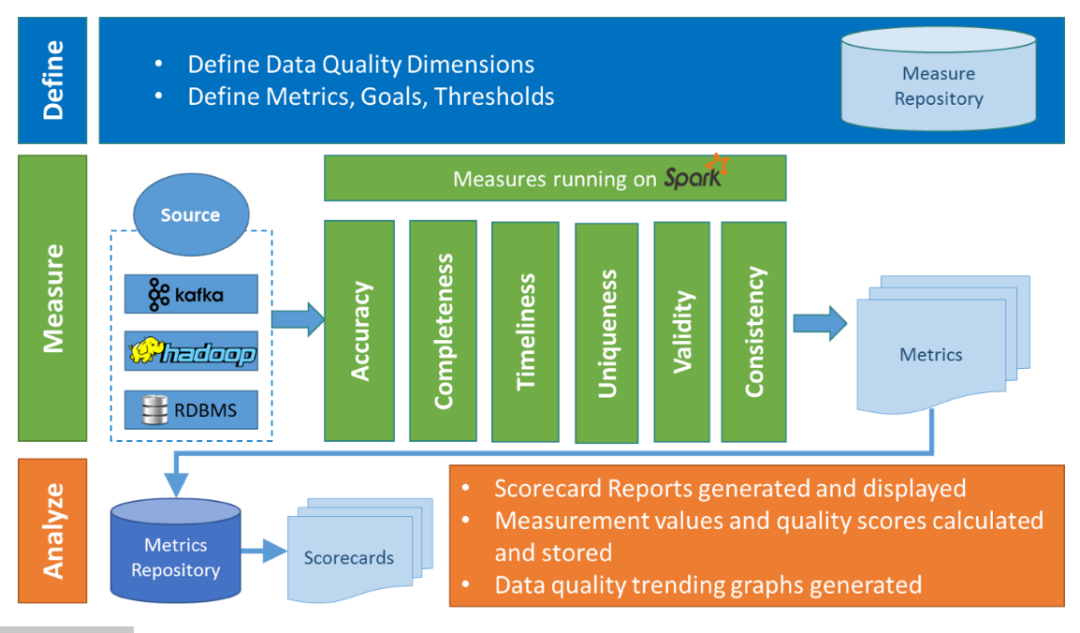
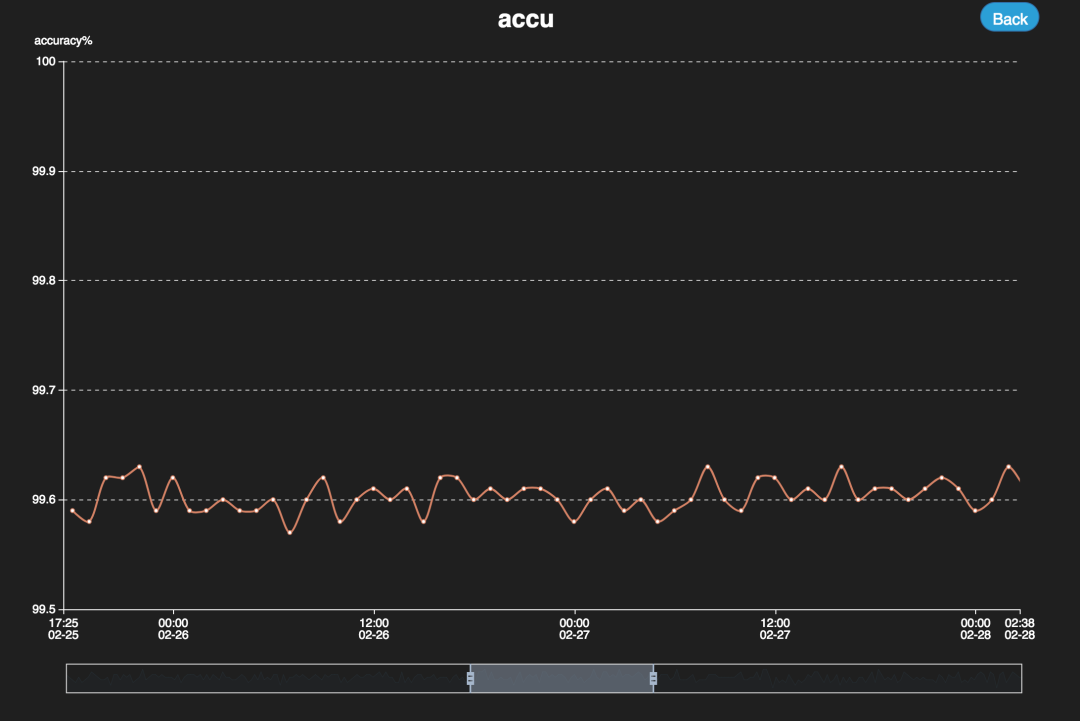
所以本身Griffin带了一个页面,可以通过页面设置进行一些监控结果展示。
Griffin对部分组件有依赖关系,这点要注意。
JDK (1.8 or later versions)
MySQL(version 5.6及以上)
Hadoop (2.6.0 or later)
Hive (version 2.x)
Spark (version 2.2.1)
Livy(livy-0.5.0-incubating)
ElasticSearch (5.0 or later versions)
当然Giffin也不是万能的,目前Griffin还是有很多的问题的,选择也要慎重:
Griffin的社区并不太活跃,可以共同讨论的人不多。
目前最新版本还是0.6,可能会有一些问题。
网上技术文档很少,当然这方面大数据流动也会不断的输出新的技术文档帮助大家。
2、Deequ
deequ是amazon开源的spark数据质量管理的工具。
其架构图如下所示:
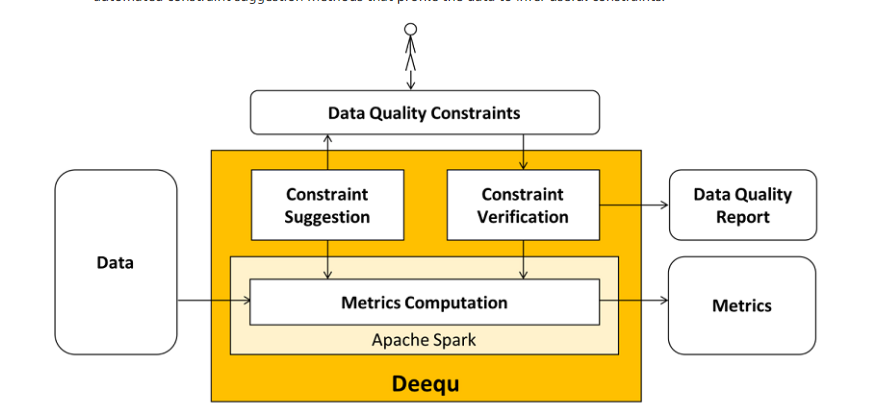
亚马逊内部正在使用 Deequ 来验证许多大型生产数据集的质量。数据集生产者可以添加和编辑数据质量约束。系统定期计算数据质量指标(使用数据集的每个新版本),验证数据集生产者定义的约束,并在成功时将数据集发布给消费者。在错误情况下,可以停止数据集发布,并通知生产者采取行动。数据质量问题不会传播到消费者数据管道,从而减少它们的爆炸半径。
要使用 Deequ,让我们看一下它的主要组件。
指标计算——Deequ 计算数据质量指标,即完整性、最大值或相关性等统计数据。Deequ 使用 Spark 从 Amazon S3 等源中读取数据,并通过一组优化的聚合查询计算指标。您可以直接访问根据数据计算的原始指标。
约束验证——作为用户,您专注于定义一组要验证的数据质量约束。Deequ 负责导出要在数据上计算的所需指标集。Deequ 生成数据质量报告,其中包含约束验证的结果。
约束建议- 您可以选择定义自己的自定义数据质量约束,或使用自动约束建议方法来分析数据以推断有用的约束。
Deequ 和 Spaek关联密切,使用Spark技术框架的可以考虑,目前Deequ 已经更新到2.X版本,使用的也比较多,社区较为活跃。
Github地址:
https://github.com/awslabs/deequ
3、Great Expectations
可能很多同学对这个框架比较陌生,但是在数据科学领域great_expectations可是一个很火的框架。
github地址:https://github.com/great-expectations/great_expectations
目前标星已近7K。
Great expectations是一个python的工具包,Python近几年在数据分析领域大放异彩,而Python本身对于数据质量问题的解决一直是一个大问题。而Great expectations正好弥补了这方面的不足。
由于对Python支持良好,部分公司采用Airflow,Great expectations等Python技术栈来进行数据质量的解决方案建设。
Great expectations社区非常活跃,最新版本为0.15,但是版本更新非常快,bug修复也很快,值得长期关注。
4、Qualitis
对于微众那套大数据平台熟悉的同学,对于Qualitis不会陌生。
Qualitis是一个支持多种异构数据源的质量校验、通知、管理服务的数据质量管理平台,用于解决业务系统运行、数据中心建设及数据治理过程中的各种数据质量问题。
Qualitis基于Spring Boot,依赖于Linkis进行数据计算,提供数据质量模型构建,数据质量模型执行,数据质量任务管理,异常数据发现保存以及数据质量报表生成等功能。并提供了金融级数据质量模型资源隔离,资源管控,权限隔离等企业特性,具备高并发,高性能,高可用的大数据质量管理能力。
Github地址为:
https://github.com/WeBankFinTech/Qualitis
官网给出了其余Griffen的对比,优势还是很多的。
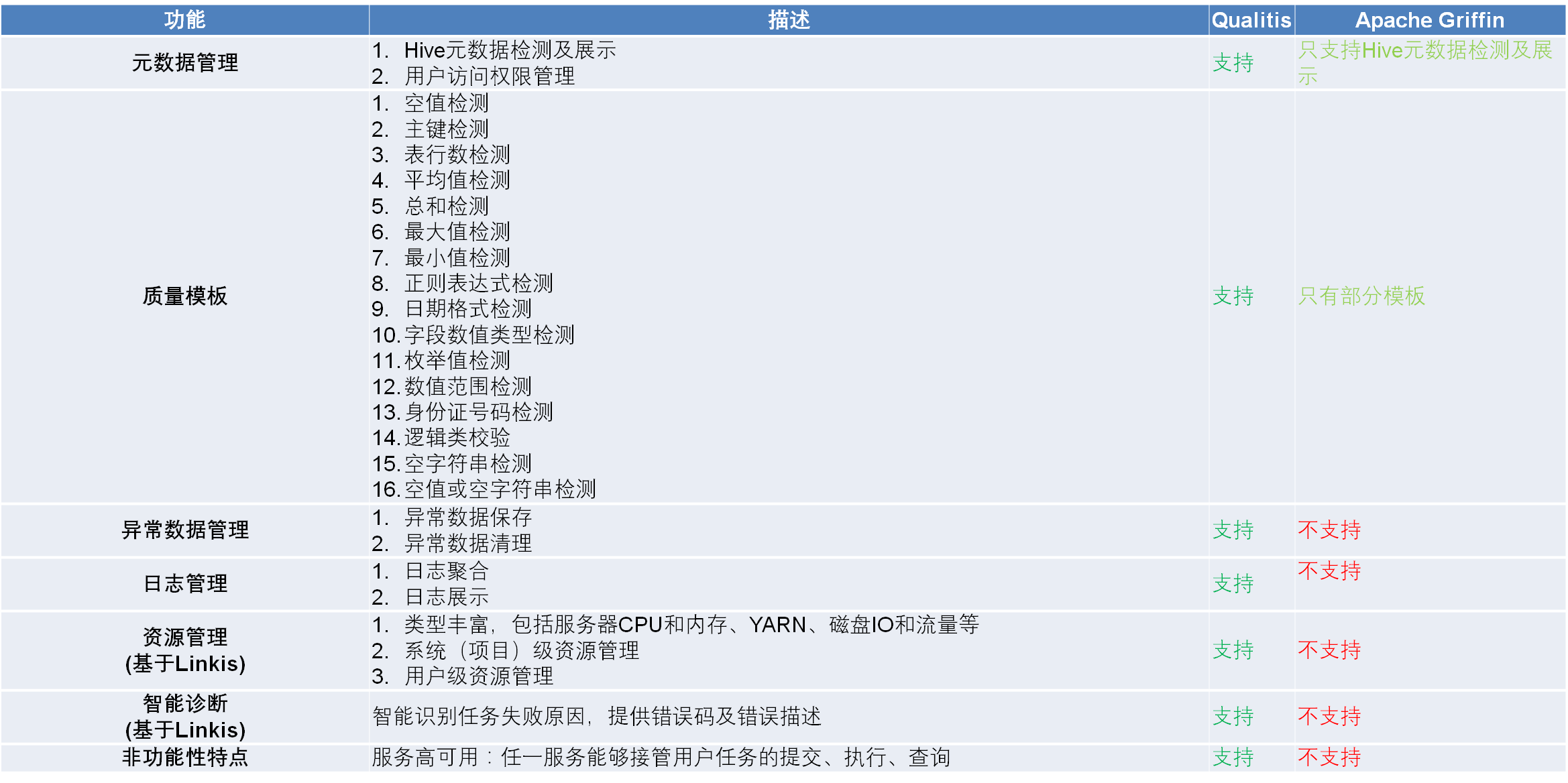
目前Qualitis有社区支持,整体还是很活跃的。
但是由于Qualitis对Linkis的依赖,灵活性要差一些,要用就得用全套的。
总之,对于数据质量工具的探索还不能停止,也期待更多优质的项目和工具的出现,我们会保持持续的关注。
数据治理的理论体系比较健全,但是实践工具太少,可以参考的工具也太少。
为了更专注提高效率,目前数据治理相关学习交流群按不同方向做了区分,欢迎大家扫码入群:

另外 数据治理工具箱 知识星球也已成立,这是一个数据治理落地实践方向的知识星球。大数据流动发布的数据治理相关文章与资料(包括付费内容)都将在知识星球进行长期同步。星球的目标是收集数据治理实践工具的相关资料,并定期组织实战学习小组,让数据治理的相关资料可以长久的保存,同时也解决文章被频繁抄袭的问题,欢迎大家加入。
最后提醒,文档版权为公众号 大数据流动 所有,请勿商用。相关技术问题以及安装包可以联系笔者独孤风加入相关技术交流群讨论获取。
数据质量管理工具预研——Griffin VS Deequ VS Great expectations VS Qualitis的更多相关文章
- [转] 前后端分离开发模式的 mock 平台预研
引入 mock(模拟): 是在项目测试中,对项目外部或不容易获取的对象/接口,用一个虚拟的对象/接口来模拟,以便测试. 背景 前后端分离 前后端仅仅通过异步接口(AJAX/JSONP)来编程 前后端都 ...
- DB数据导出工具分享
一个根据数据库链接字符串,sql语句 即可将结果集导出到Excel的工具 分享,支持sqlserver,mysql. 前因 一个月前朋友找到我,让我帮忙做一个根据sql导出查询结果到Excel的工具( ...
- 来了解质量管理工具——质量屋(HOQ)
质量屋(The House Of Quality),又名HOQ,它是质量功能配置(QFD)的核心.一般QFD的学习会涉及到.同时HOQ也是项目管理十大知识领域领域中质量管理工具中的一种,今天我们就来了 ...
- 程序员必备!Sonar代码质量管理工具
Sonar 是一个用于代码质量管理的开放平台.通过插件机制,Sonar 可以集成不同的测试工具,代码分析工具,以及持续集成工具. Sonar 概述 Sonar 是一个用于代码质量管理的开放平台.通过插 ...
- 【原创】BI解决方案选型之ETL数据整合工具对比
一.背景 在企业BI平台建设过程中,数据整合始终是一切的基础,简单BI项目可以通过存储过程来实现,而复杂.全面.多方异构数据来源等就大大增加了复杂性,存储过程的可管理性.可维护性.容错性等就无法很好的 ...
- Nvidia NVENC 硬编码预研总结
本篇博客记录NVENC硬编码的预研过程 github: https://github.com/MarkRepo/NvencEncoder 步骤如下: (1)环境搭建 (2)demo编译,测试,ARG ...
- 基于MaxCompute的数仓数据质量管理
声明 本文中介绍的非功能性规范均为建议性规范,产品功能无强制,仅供指导. 参考文献 <大数据之路——阿里巴巴大数据实践>——阿里巴巴数据技术及产品部 著. 背景及目的 数据对一个企业来说已 ...
- 一篇文章看懂TPCx-BB(大数据基准测试工具)源码
TPCx-BB是大数据基准测试工具,它通过模拟零售商的30个应用场景,执行30个查询来衡量基于Hadoop的大数据系统的包括硬件和软件的性能.其中一些场景还用到了机器学习算法(聚类.线性回归等).为了 ...
- Charted – 自动化的可视化数据生成工具
Charted 是一个让数据自动生成可视化图表的工具.只需要提供一个数据文件的链接,它就能返回一个美丽的,可共享的图表.Charted 不会存储任何数据.它只是获取和让链接提供的数据可视化. 在线演示 ...
随机推荐
- PHP代码审计之命令注入攻击
PHP漏洞-命令注入攻击 命令注入攻击 PHP中可以使用下列5个函数来执行外部的应用程序或函数 system.exec.passthru.shell_exec.``(与shell_exec功能相同) ...
- Invocation failed Unexpected end of file from server java.lang.RuntimeException: Invocation failed Unexpected end of file from server
Android studio 提交 push的时候报错. Invocation failed Unexpected end of file from serverjava.lang.RuntimeEx ...
- 2┃音视频直播系统之浏览器中通过 WebRTC 拍照片加滤镜并保存
一.拍照原理 好多人小时候应该都学过,在几张空白的纸上画同一个物体,并让物体之间稍有一些变化,然后连续快速地翻动这几张纸,它就形成了一个小动画,音视频播放器就是利用这样的原理来播放音视频文件的 播放器 ...
- Java 对象头那点事
概览 对象头 存放:关于堆对象的布局.类型.GC状态.同步状态和标识哈希码的基本信息.Java对象和vm内部对象都有一个共同的对象头格式. (后面做详细介绍) 实例数据 存放:类的数据信息,父类的信息 ...
- Spring 源码(14)Spring Bean 的创建过程(5)
到目前为止,我们知道Spring创建Bean对象有5中方法,分别是: 使用FactoryBean的getObject方法创建 使用BeanPostProcessor的子接口InstantiationA ...
- 斯坦福NLP课程 | 第11讲 - NLP中的卷积神经网络
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- vue大型电商项目尚品汇(前台篇)day02
现在正式回归,开始好好做项目了,正好这一个项目也开始慢慢的开始起色了,前面的准备工作都做的差不多了. 而且我现在也开始慢慢了解到了一些项目才开始需要的一些什么东西了,vuex.router这些都是必备 ...
- 认识并安装WSL
认识并安装WSL(基于Windows的Linux子系统) 什么是WSL WSL(Windows Subsystem for Linux),这是在windows平台运行的linux子系统.也就是说可是不 ...
- 893. Groups of Special-Equivalent Strings - LeetCode
Question 893. Groups of Special-Equivalent Strings Solution 题目大意: AB两个字符串相等的条件是:A中偶数位出现的字符与B中偶数位出现的字 ...
- linux篇-linux 下tomcat服务每天定时启动
1l先准备一个脚本 #!/bin/sh #./etc/profile export JAVA_HOME=/usr/java/jdk1.6.0_45 sh /home/tomcat-bingchuang ...