大数据技术之kettle(2)——练习三个基本操作
一、同一数据库两表数据关联更新
实现效果:把stu1的数据按id同步到stu2,stu2有相同id则更新数据
步骤:
1.在mysql中创建两张表:
mysql>create database kettle;
mysql>use kettle;
mysql>create table stu1 (id int ,name varchar(20),age int);
mysql>create table stu2 (id int ,name varchar(20));
2.往两张表中插入一些数据:
mysql>insert into stu1 values(1001,’zhangsan’,20),(1002,’lisi’,18),(1003,’wangwu’,23);
mysql>insert into stu2 values(1001,’wukong’);
3.在kettle中新建转换,点击左上角文件—新建—转换到核心对象界面,点击输入,找到表输入拖拽到中间

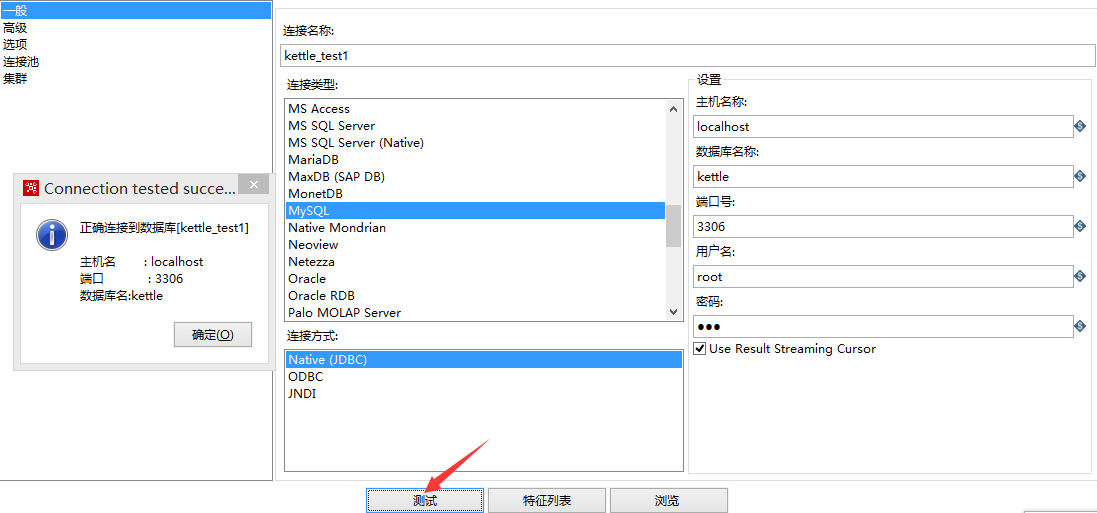
4.双击表输入,在数据库连接中配置mysql数据库连接(注意jar包mysql-connector-java-5.1.34-bin.jar要放在kettle的lib文件夹中)

输入完信息后点击测试,显示正确连接。
5.sql语句中输入select * from stu1;
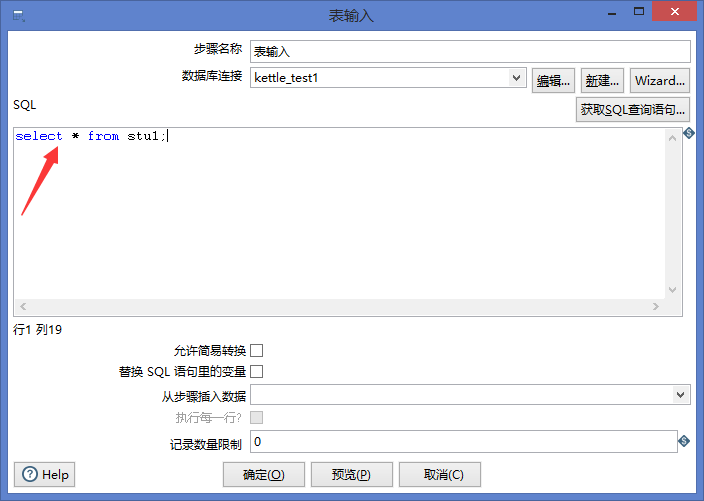
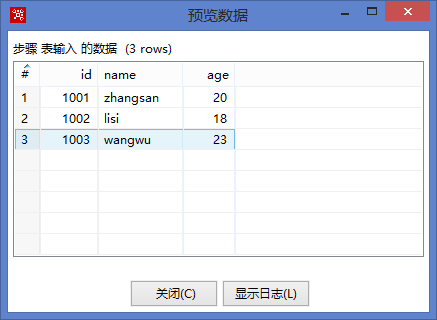
点击预览可以看到数据
6.在输出中找到插入/更新组件拖拽到中间,点住表输入shift+鼠标左键连接到插入/更新组件上

双击插入/更新,点击目标表浏览,选择stu2
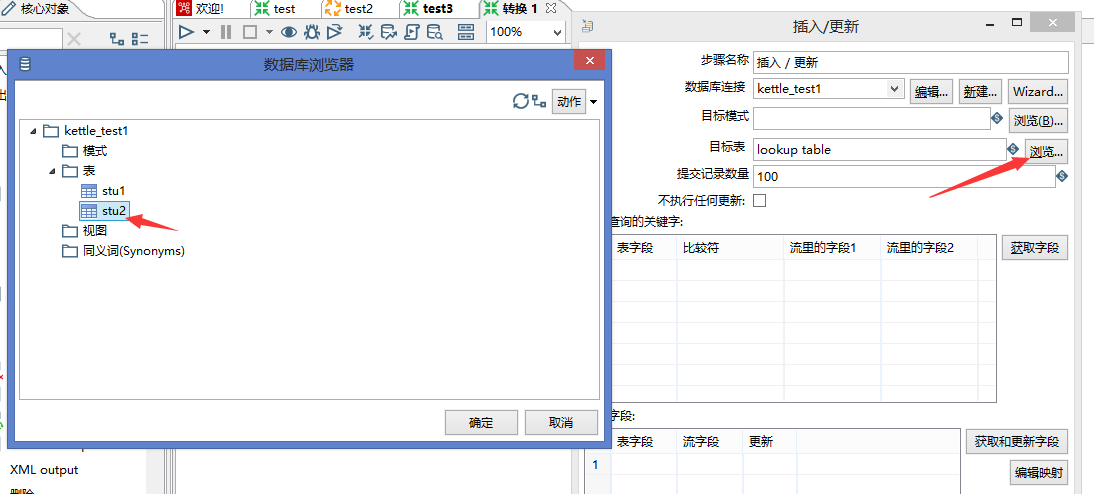
点击获取字段获取到3个字段
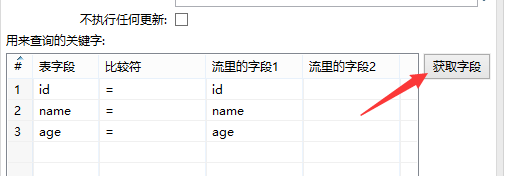
由于stu1与stu2通过id关联,故删除name和age字段,然后点击编辑映射,编辑2个表之间的映射
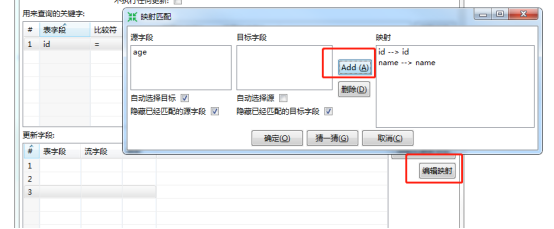
确定后如图:
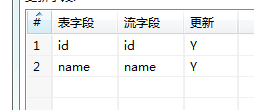
更新处,修改id的属性为n,确定。然后保存运行,到数据库中查看结果。
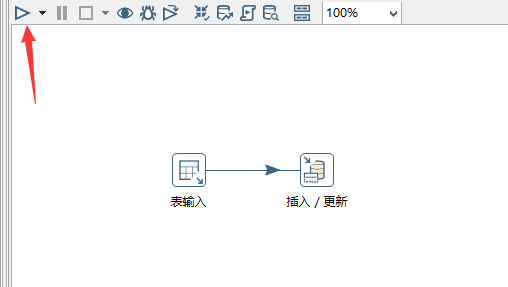
最后生成了一个文件,如下:
二、使用作业执行生成的转换文件
实现效果:使用作业执行“一”中的转换,并且额外在表stu2中添加一条数据
步骤:
新建一个作业

点击通用将start拖拽到作业中
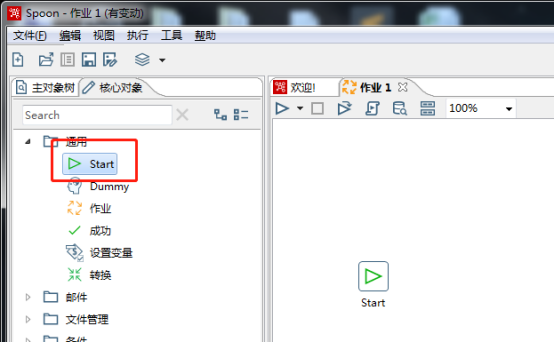
将转换拖拽过来,将start与转换相连接
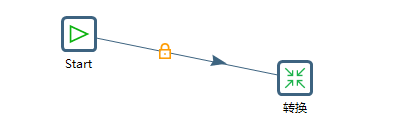
双击转换,选择之前做好的job
左侧脚本中选择sql组件拖拽过来并连接
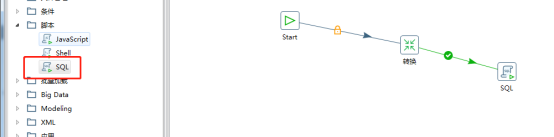
新建连接配置mysql数据库,并写插入sql语句

确定,保存job并执行
三、将A数据库中的a表经过ETL过程导入B数据库中
sql语句地址:https://pan.baidu.com/s/1Eba9TEO3UO9Fjaz522VONw
实现效果:将hr数据库中的employees表,经过ETL过程,导入到scott数据库中;将列FIRST_NAME和LAST_NAME相连,中间用空格隔开,取名为“NAME”;将列PHONE_NUMBER中的区号加上括号(例如515.123.4567改为(515)123.4567),列名不变;在scott数据库中,该表的列名不变,表名改为dw_dim_employees。
实现步骤:
1.双击桌面的 图标进入到kettle的Transformation界面,双击转换切换到操作界面
在核心对象目录树下找到输入,点击前面的展开三角,找到表输入组件拖入到右侧工作区
同样的在输出中,找到表输出拖入到右侧工作区;在转换中找到字段选择拖入到右侧工作区。
2.将这3个组件连接起来,先选中表输入,Shift+鼠标左键拖拽到字段选择上,再选中字段选择同样的Shift+鼠标左键拖拽到表输出上并选定为主输出步骤。
3.双击表输入,数据库连接处点击新建,连接名称填写hr,连接类型选择mysql。。。与“上边一中的操作一致”
4.点击下面测试,弹出正确连接数据库hr,点击确定保存设置
在表输入的SQL框中输入如下SQL语句
SELECT EMPLOYEE_ID, CONCAT(FIRST_NAME, ' ', LAST_NAME) AS NAME
, CONCAT('(', SUBSTR(PHONE_NUMBER, 1, 3), ')', SUBSTR(PHONE_NUMBER, 5)) AS PHONE_NUMBER
, HIRE_DATE, JOB_ID, SALARY, COMMISSION_PCT, NAGER_ID
, DEPARTMENT_ID
FROM employees
点击预览数据,确认无误后点击确定关闭
5.双击字段选择,点击获取选择的字段,得到10个字段后点击确定关闭
双击表输出,依然在数据库连接处点击新建
在数据库连接界面填入如下信息:回到表输出界面,在目标表中填写表名:dw_dim_employees,勾选指定数据库字段,点击下面数据库字段点击获取字段。
点击右下角SQL按钮,点击启动
弹出保存提示,选择是,找到一个文件路径(如桌面/项目脚本),为job起个名字
运行成功
大数据技术之kettle(2)——练习三个基本操作的更多相关文章
- 大数据技术之kettle
大数据技术之kettle 第1章 kettle概述 1.1 什么是kettle kettle是一款开源的ETL工具,纯java编写,可以在Windows.Linux.Uni ...
- 大数据技术之kettle(1)——安装
一. kettle概述 1.kettle是一款开源的ETL工具,纯java编写,可以在Windows.Linux.Unix上运行,绿色无需安装,数据抽取高效稳定. 2.kettle的两种设计 简述: ...
- 大数据技术之kettle安装使用
kettle是一款开源的ETL工具,纯java编写,可以在Windows.Linux.Unix上运行,绿色无需安装,数据抽取高效稳定. kettle的两种设计 简述: Transformation(转 ...
- 参加2013中国大数据技术大会(BDTC2013)
2013年12月5日-6日参加了为期两天的2013中国大数据技术大会(Big Data Technology Conference, BDTC2013),本期会议主题是:“应用驱动的架构与技术 ”.大 ...
- 大数据技术人年度盛事! BDTC 2016将于12月8-10日在京举行
2016年12月8日-10日,由中国计算机学会(CCF)主办,CCF大数据专家委员会承办,中国科学院计算技术研究所和CSDN共同协办的2016中国大数据技术大会(Big Data Technology ...
- 2016中国大数据技术大会( BDTC ) 共商大数据时代发展之计
中国大数据技术大会(BDTC)的前身是Hadoop中国云计算大会(HadoopinChina,HiC).从2008年仅60余人参加的技术沙龙发展到当下数千人的技术盛宴,目前已成为国内最具影响力.规模最 ...
- 大数据技术生态圈形象比喻(Hadoop、Hive、Spark 关系)
[摘要] 知乎上一篇很不错的科普文章,介绍大数据技术生态圈(Hadoop.Hive.Spark )的关系. 链接地址:https://www.zhihu.com/question/27974418 [ ...
- 从大数据技术变迁猜一猜AI人工智能的发展
目前大数据已经成为了各家互联网公司的核心资产和竞争力了,其实不仅是互联网公司,包括传统企业也拥有大量的数据,也想把这些数据发挥出作用.在这种环境下,大数据技术的重要性和火爆程度相信没有人去怀疑. 而A ...
- 大数据技术 - MapReduce的Combiner介绍
本章来简单介绍下 Hadoop MapReduce 中的 Combiner.Combiner 是为了聚合数据而出现的,那为什么要聚合数据呢?因为我们知道 Shuffle 过程是消耗网络IO 和 磁盘I ...
随机推荐
- Step by Step to create orders by consuming SAP Commerce Cloud Restful API
Recently Jerry is working on an integration project about creating orders in Wechat platform by cons ...
- array_reduce() 与 array_map()
相似部分: 二者同为 处理数组函数,可遍历 数组中的每一个元素, 对其通过 function callback(){} 处理. 不同处: 参数: array_reduce( array, callba ...
- SQL SERVER-Extendevent检测TempDB增长
--创建Session收集数tempDB增长数据 CREATE EVENT SESSION [Database_Growth_Watchdog] ON SERVER ADD EVENT sqlserv ...
- Android笔记(四十一) Android中的数据存储——SQLite(三)select
SQLite 通过query实现查询,它通过一系列参数来定义查询条件. 各参数说明: query()方法参数 对应sql部分 描述 table from table_name 表名称 colums s ...
- nginx 代理 websocket
nginx 代理 websocket nginx 首先确认版本必须是1.3以上 map指令的作用: 该作用主要是根据客户端请求中$http_upgrade 的值,来构造改变$connection_up ...
- React中的State与Props
一.State 1.什么是 state 一个组件的显示形态可以由数据状态和外部参数决定,其中,数据状态为 state,外部参数为 props 2.state 的使用 组件初始化时,通过 this.st ...
- docker安装之mariadb
https://hub.docker.com/_/mariadb?tab=description Supported tags and respective Dockerfile links 10.4 ...
- k8s安装之calico.yaml
这个calico有点长,我也没有仔细看完. 但部署上去是可用的. 如果节点超过200台,那最好要另外一套配置... 而对于我们,差不多下面的配置够用了. veth_mtu: "1440&qu ...
- robot framework 笔记(一)
背景: 平时使用rf时会用到一些方法,长时间不用就会忘记,本文用来记录当做自己的小笔记 内容持续更新中········ 一.robot framework 大小写转换 1.转换小写: ${low} E ...
- CDH6.2离线安装(整理版)
1.概述 CDH,全称Cloudera's Distribution, including Apache Hadoop.是Hadoop众多分支中对应中的一种,由Cloudera维护,基于稳定版本的Ap ...