11、spark内核架构剖析与宽窄依赖
一、内核剖析
1、内核模块
1、Application
2、spark-submit
3、Driver
4、SparkContext
5、Master
6、Worker
7、Executor
8、Job
9、DAGScheduler
10、TaskScheduler
11、ShuffleMapTask and ResultTask
2、图解
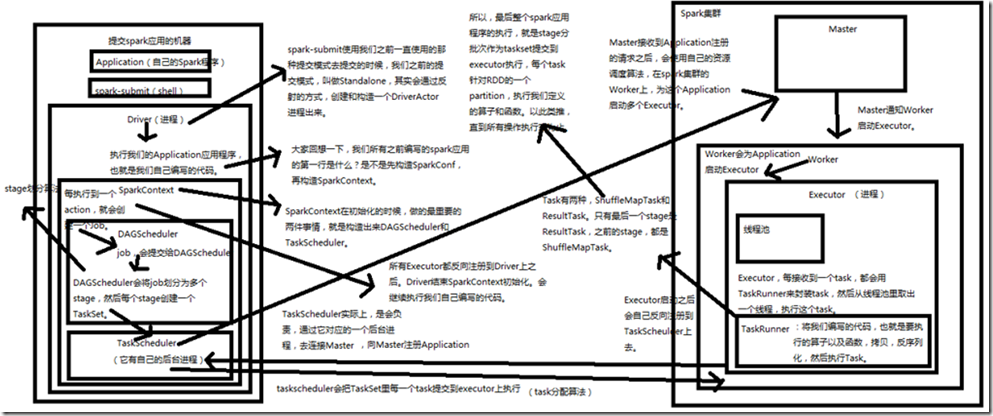
自己编写的Application,就是我们自己写的程序,拷贝到用来提交spark应用的机器,使用spark-submit提交这个Application,提交之后,spark-submit在Standalone模式下会通过反射的方式,创建和构造一个DriverActor进程。 启动DriverActor进程后,开始执行Application应用程序,也就是我们自己编写的代码,第一件事就是构造SparkContext,这时,会初始化DAGScheduler和TaskScheduler,
构造完TaskScheduler后,TaskScheduler实际上,是会负责,通过一个后台进程,去连接Master,向Master注册Application; Master接收到Application注册的请求之后,会使用自己的资源调度算法,在Spark集群的Wroker上,为这个Application启动多个Executor,Master通知Wroker启动Executor; Executor启动之后,会自动反向注册到TaskScheduler上去,所有Executor都反向注册到Driver上之后,Driver结束SparkContext初始化,会继续执行我们自己编写的代码
每执行到一个Action,就会创造一个job,job会提交给DAGScheduler; DAGScheduler会将多个job划分为多个stage(stage划分算法),然后每个stage创建一个TaskSet,TaskSet会给TaskScheduler,TaskScheduler会把TaskSet里每一个task提交到Executor上执行(task分配算法); Task有两种,ShuffleMapTask和ResultTask,只有最后一个stage是ResultTask,之前的stage,都是ShuffleMapTask; Executor每接收到一个task,都会用TaskRunner来封装task,然后从线程池里取出一个线程,执行这个task; TaskRunner,将我们编写的代码,也就是要执行的算子以及函数,拷贝,反序列化,然后执行task。 所以,最后整个Spark应用程序的执行,就是stage分批次作为taskset提交到Executor执行,每个task针对RDD的一个partition,执行我们定义的算子和函数,依次类推,直到所有操作完为止;
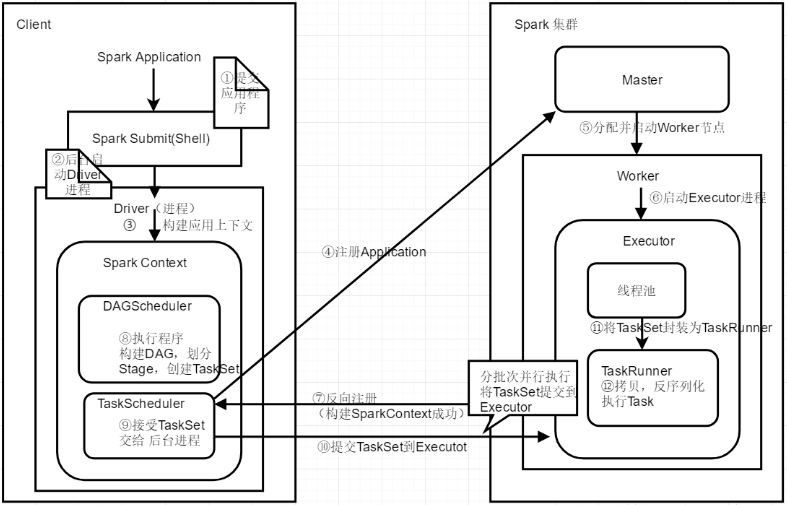
1、首先是提交打包的应用程序,使用Spark submit或者spark shell工具执行。 2、提交应用程序后后台会在后台启动Driver进程(注意:这里的Driver是在Client上启动,如果使用cluster模式提交任务,
Driver进程会在Worker节点启动)。 3、开始构建Spark应用上下文。一般的一个Spark应用程序都会先创建一个Sparkconf,然后来创建SparkContext。如下代码所示:
val conf=new SparkConf() val sc=new SparkContext(conf)。在创建SparkContext对象时有两个重要的对象,DAGScheduler和TaskScheduler(具体作用后面会详细讲解)。 4、构建好TaskScheduler后,它对应着一个后台进程,接着它会去连接Master集群,向Master集群注册Application。 5、Master节点接收到应用程序之后,会向该Application分配资源,启动一个或者多个Worker节点。 6、每一个Worker节点会为该应用启动一个Executor进程来执行该应用程序。 7、向Master节点注册应用之后,master为应用分配了节点资源,在Worker启动Executor完成之后,此时,Executo会向TaskScheduler反向注册,以让它知道Master为应用
程序分配了哪几台Worker节点和Executor进程来执行任务。到此时为止,整个SparkContext创建完成。 8、创建好SparkContext之后,继续执行我们的应用程序,每执行一个action操作就创建为一个job,将job交给DAGScheduler执行,然后DAGScheduler会将多个job划
分为stage(这里涉及到stage的划分算法,比较复杂)。然后每一个stage创建一个TaskSet。 9、实际上TaskScheduler有自己的后台进程会处理创建好的TaskSet。 10、然后就会将TaskSet中的每一个task提交到Executor上去执行。(这里也涉及到task分配算法,提交到哪几个worker节点的executor中去执行)。 11、Executor会创建一个线程池,当executor接收到一个任务时就从线程池中拿出来一个线程将Task封装为一个TaskRunner。 12、在TaskRunner中会将我们程序的拷贝,反序列化等操作,然后执行每一个Task。对于这个Task一般有两种,ShufflerMapTask和ResultTask,只有最后一个stage的task
是ResultTask,其它的都是ShufflerMapTask。 13、最后会执行完所有的应用程序,将stage的每一个task分批次提交到executor中去执行,每一个Task针对一个RDD的partition,执行我们定义的算子和函数,直到全部
执行完成。
二、宽窄依赖
1、Wordcount图解

2、宽窄依赖
宽依赖(Shuffle Dependency),就是Shuffle,每一个父RDD的partition中的数据,都可能会传输一部分到下一个RDD的每个partition中,此时就会出现,父RDD和子RDD的partition之间,具有交互错综复杂的关系,
那么,这种情况,就叫做两个RDD之间是宽依赖,同时,他们之间发生的操作,是Shuffle;
窄依赖(Narrow Dependency),一个RDD,对它的父RDD,只有简单的一对一依赖关系,也就是说,RDD的每个partition,仅仅依赖于父RDD中的一个partition,父RDD和子RDD的partition之间的对应关系是一对一的
这种情况下,是简单的RDD之间的依赖关系,也被称之为窄依赖;
11、spark内核架构剖析与宽窄依赖的更多相关文章
- SQLServer内核架构剖析 (转载)
SQL Server内核架构剖析 (转载) 这篇文章在我电脑里好长时间了,今天不小心给翻出来了,觉得写得很不错,因此贴出来共享. 不得不承认的是,一个优秀的软件是一步一步脚踏实地积累起来的,众多优秀的 ...
- Spark RDD基本概念、宽窄依赖、转换行为操作
目录 RDD概述 RDD的内部代码 案例 小总结 转换.行动算子 宽.窄依赖 Reference 本文介绍一下rdd的基本属性概念.rdd的转换/行动操作.rdd的宽/窄依赖. RDD:Resilie ...
- [转载]SQL Server内核架构剖析
原文链接:http://www.sqlserver.com.cn 我们做管理软件的,主要核心就在数据存储管理上.所以数据库设计是我们的重中之重.为了让我们的管理软件能够稳定.可扩展.性能优秀.可跟踪排 ...
- SQLSERVER内核架构剖析 (转)
我们做管理软件的,主要核心就在数据存储管理上.所以数据库设计是我们的重中之重.为了让我们的管理软件能够稳定.可扩展.性能优秀.可跟踪排错. 可升级部署.可插件运行,我们往往研发自己的管理软件开发平台. ...
- 小记--------spark内核架构原理分析
首先会将jar包上传到机器(服务器上) 1.在这台机器上会产生一个Application(也就是自己的spark程序) 2.然后通过spark-submit(shell) 提交程序 ...
- SQL Server内核架构剖析与NUMA
http://www.cnblogs.com/lyhabc/p/4272053.html http://www.cnblogs.com/lyhabc/archive/2013/02/05/289247 ...
- Spark- Spark内核架构原理和Spark架构深度剖析
Spark内核架构原理 1.Driver 选spark节点之一,提交我们编写的spark程序,开启一个Driver进程,执行我们的Application应用程序,也就是我们自己编写的代码.Driver ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- Spark运行时的内核架构以及架构思考
一: Spark内核架构 1,Drive是运行程序的时候有main方法,并且会创建SparkContext对象,是程序运行调度的中心,向Master注册程序,然后Master分配资源. 应用程序: A ...
随机推荐
- 创建包含CRUD操作的Web API接口-第一部
在这里,我们将创建一个新的Web API项目,它将使用实体框架实现Get,POST.PUT和DELETE方法来实现CRUD操作. 首先,在Visual Studio 2013 for Web expr ...
- idea多级目录不展开的问题
遇见了一个坑,idea新建的包,和它的上级包重叠在了一起,无法形成树状结构 原因呢,还是因为自己的不细心了,解决方案很简单,下面的是原情况 解决方案,点击左侧栏右上角的设置图表,注意看红框内 把第一行 ...
- docker 容器和镜像常用命令整理
- SWD下载k60
转:JTAG各类接口针脚定义,含义及SWD接线方式 IAR设置如下
- redhat6.7 yum网络源配置
RedHat自带的yum源需要当前系统注册了RHN才可以使用,如果没有注册,当使用yum时,会提示需要注册RHN 如果没有注册RHN,则意味着我们不能使用RedHat自带的yum源.这个时候,我们可以 ...
- Python开发之路:目录篇
第一部分:Python基础知识 本篇主要python基础知识的积累和学习,其中包括python的介绍.基本数据类型.函数.模块及面向对象等. 第一篇:Python简介 第二篇:Python基本知识 ...
- c# CryptoStream 类
- 快速入门 Python 数据分析实用指南
Python 现如今已成为数据分析和数据科学使用上的标准语言和标准平台之一.那么作为一个新手小白,该如何快速入门 Python 数据分析呢? 下面根据数据分析的一般工作流程,梳理了相关知识技能以及学习 ...
- linux 查看目录的剩余空间大小
两个命令df .du结合比较直观 df -h 查看整台服务器的硬盘使用情况 cd / 进入根目录 du ...
- substr()用法
知识点链接:http://www.cplusplus.com/reference/string/string/substr/ 注意: std::string str2 = str.substr (po ...