flink 实现ConnectedComponents 连通分量,增量迭代算法(Delta Iteration)实现详解
1、连通分量是什么?
首先需要了解什么是连通图、无向连通图、极大连通子图等概念,这些概念都来自数据结构-图,这里简单介绍一下。
下图是连通图和非连通图,都是无向的,这里不扩展有向图:

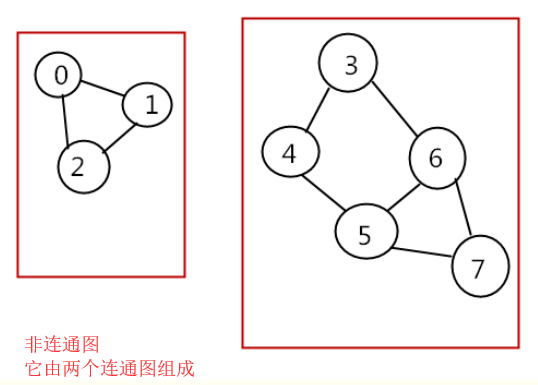
连通分量(connected component):无向图中的极大连通子图(maximal connected subgraph)称为原图的连通分量。 极大连通子图:
1.连通图只有一个极大连通子图,就是它本身。(是唯一的)
2.非连通图有多个极大连通子图。(非连通图的极大连通子图叫做连通分量,每个分量都是一个连通图)
3.称为极大是因为如果此时加入任何一个不在图的点集中的点都会导致它不再连通。
如果需要继续了解连通图相关的内容可以自行百度。
2、flink 实现连通分量算法,本例中将分量值小的数据传递到其他连接点,通过增量迭代实现。
2.1、数据准备
public class ConnectedComponentsData {
public static final long[] VERTICES = new long[] {
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
public static DataSet<Long> getDefaultVertexDataSet(ExecutionEnvironment env) {
List<Long> verticesList = new LinkedList<Long>();
for (long vertexId : VERTICES) {
verticesList.add(vertexId);
}
return env.fromCollection(verticesList);
}
public static final Object[][] EDGES = new Object[][] {
new Object[]{1L, 2L},
new Object[]{2L, 3L},
new Object[]{2L, 4L},
new Object[]{3L, 5L},
new Object[]{6L, 7L},
new Object[]{8L, 9L},
new Object[]{8L, 10L},
new Object[]{5L, 11L},
new Object[]{11L, 12L},
new Object[]{10L, 13L},
new Object[]{9L, 14L},
new Object[]{13L, 14L},
new Object[]{1L, 15L},
new Object[]{16L, 1L}
};
public static DataSet<Tuple2<Long, Long>> getDefaultEdgeDataSet(ExecutionEnvironment env) {
List<Tuple2<Long, Long>> edgeList = new LinkedList<Tuple2<Long, Long>>();
for (Object[] edge : EDGES) {
edgeList.add(new Tuple2<Long, Long>((Long) edge[0], (Long) edge[1]));
}
return env.fromCollection(edgeList);
}
}
2.2 算法实现,代码里有详细注释
/**
* @Description:
* 使用delta迭代实现连通分量算法。
* 最初,算法为每个顶点分配唯一的ID。在每个步骤中,顶点选择其自身ID及其邻居ID的最小值作为其新ID,并告知其邻居其新ID。算法完成后,同一组件中的所有顶点将具有相同的ID。
*
* 组件ID未更改的顶点不需要在下一步中传播其信息。因此,该算法可通过delta迭代轻松表达。我们在这里将解决方案集建模为具有当前组件ID的顶点,并将工作集设置为更改的顶点。因为我们最初看到所有顶点都已更改,所以初始工作集和初始解决方案集是相同的。
* 此外,解决方案集的增量也是下一个工作集。
* 输入文件是纯文本文件,必须格式如下:
*
* 顶点表示为ID并用换行符分隔。
* 例如,"1\n2\n12\n42\n63"给出五个顶点(1),(2),(12),(42)和(63)。
* 边缘表示为顶点ID的对,由空格字符分隔。边线由换行符分隔。
* 例如,"1 2\n2 12\n1 12\n42 63"给出四个(无向)边缘(1) - (2),(2) - (12),(1) - (12)和(42) - (63)。
* 用法:ConnectedComponents --vertices <path> --edges <path> --output <path> --iterations <n>
* 如果未提供参数,则使用{@link ConnectedComponentsData}中的默认数据和10次迭代运行程序。
*
**/
public class ConnectedComponents { //获取顶点数据
private static DataSet<Long> getVertexDataSet(ParameterTool params, ExecutionEnvironment env){
if(params.has("vertices")){
return env.readCsvFile(params.get("vertices")).types(Long.class)
.map(new MapFunction<Tuple1<Long>, Long>() {
@Override
public Long map(Tuple1<Long> value) throws Exception {
return value.f0;
}
});
}else{
System.out.println("Executing Connected Components example with default vertices data set.");
System.out.println("Use --vertices to specify file input.");
return ConnectedComponentsData.getDefaultVertexDataSet(env);
}
} //获取边数据
private static DataSet<Tuple2<Long,Long>> getEdgeDataSet(ParameterTool params,ExecutionEnvironment env){
if(params.has("edges")){
return env.readCsvFile(params.get("edges")).fieldDelimiter(" ").types(Long.class,Long.class);
}else {
System.out.println("Executing Connected Components example with default edges data set.");
System.out.println("Use --edges to specify file input.");
return ConnectedComponentsData.getDefaultEdgeDataSet(env);
}
} public static void main(String args[]) throws Exception{
final ParameterTool params = ParameterTool.fromArgs(args); ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); //缺省10次迭代,或者从参数中获取
final int maxIterations = params.getInt("iterations",10); //make parameters available in the web interface
env.getConfig().setGlobalJobParameters(params); // read vertex and edge data
DataSet<Long> vertices = getVertexDataSet(params, env);
//对应的加了一组反转的边
DataSet<Tuple2<Long,Long>> edges = getEdgeDataSet(params, env).flatMap(new UndirectEdge()); // assign the initial components (equal to the vertex id)
//初始化顶点元组
DataSet<Tuple2<Long, Long>> verticesWithInitialId =
vertices.map(new DuplicateValue<>()); // open a delta iteration
DeltaIteration<Tuple2<Long,Long>,Tuple2<Long,Long>> iteration = verticesWithInitialId
.iterateDelta(verticesWithInitialId,maxIterations,0); // apply the step logic: join with the edges, select the minimum neighbor, update if the component of the candidate is smaller
DataSet<Tuple2<Long, Long>> changes = iteration.getWorkset().join(edges)
.where(0).equalTo(0)
.with(new NeighborWithComponentIDJoin())
.groupBy(0).aggregate(Aggregations.MIN, 1)
.join(iteration.getSolutionSet()).where(0).equalTo(0)
.with(new ComponentIdFilter()); // close the delta iteration (delta and new workset are identical)
DataSet<Tuple2<Long, Long>> result = iteration.closeWith(changes, changes); // emit result
if (params.has("output")) {
result.writeAsCsv(params.get("output"), "\n", " ");
// execute program
env.execute("Connected Components Example");
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
result.print();
} } /**
* Undirected edges by emitting for each input edge the input edges itself and an inverted version.
* 因为是无向连通图,反转边元组edges是为了将所有顶点(vertex)都放在Tuple2的第一个元素中,
* 这样合并原来的元组和反转的元组后,生成的新元组的第一个元素将包括所有的顶点vertex,下一步就可以用join进行关联
*/
public static final class UndirectEdge implements FlatMapFunction<Tuple2<Long,Long>,Tuple2<Long,Long>>{
Tuple2<Long,Long> invertedEdge = new Tuple2<>();
@Override
public void flatMap(Tuple2<Long, Long> value, Collector<Tuple2<Long, Long>> out) throws Exception {
invertedEdge.f0 = value.f1;
invertedEdge.f1 = value.f0; out.collect(value);
out.collect(invertedEdge);
}
} /**
* Function that turns a value into a 2-tuple where both fields are that value.
* 将每个点(vertex)映射成(id,id),表示用id值初始化顶点(vertex)的Component-ID (分量ID)
* 实际上是(Vertex-ID, Component-ID)对,这个Component-ID就是需要比较以及传播的值
*/
@FunctionAnnotation.ForwardedFields("*->f0")
public static final class DuplicateValue<T> implements MapFunction<T,Tuple2<T,T>>{
@Override
public Tuple2<T, T> map(T value) throws Exception {
return new Tuple2<>(value,value);
}
} /**
* UDF that joins a (Vertex-ID, Component-ID) pair that represents the current component that
* a vertex is associated with, with a (Source-Vertex-ID, Target-VertexID) edge. The function
* produces a (Target-vertex-ID, Component-ID) pair.
* 通过(Vertex-ID, Component-ID)顶点对与(Source-Vertex-ID, Target-VertexID)边对的连接,
* 得到(Target-vertex-ID, Component-ID)对,这个对是相连顶点的新的分量值,
* 下一步这个相连顶点分量值将与原来的自己的分量值比较大小,并保留小的那一对,通过增量迭代传播。
* 这个地方有点烧脑。这个步骤主要目的就是传播分量。
*/
@FunctionAnnotation.ForwardedFieldsFirst("f1->f1")
@FunctionAnnotation.ForwardedFieldsSecond("f1->f0")
public static final class NeighborWithComponentIDJoin implements JoinFunction<Tuple2<Long, Long>, Tuple2<Long, Long>, Tuple2<Long, Long>> { @Override
public Tuple2<Long, Long> join(Tuple2<Long, Long> vertexWithComponent, Tuple2<Long, Long> edge) {
return new Tuple2<>(edge.f1, vertexWithComponent.f1);
}
} /**
* Emit the candidate (Vertex-ID, Component-ID) pair if and only if the
* candidate component ID is less than the vertex's current component ID.
* 从上一步的(Target-vertex-ID, Component-ID)对与SolutionSet里的原始数据进行比对,保留小的,
* 增量迭代部分由系统框架实现了。
*/
@FunctionAnnotation.ForwardedFieldsFirst("*")
public static final class ComponentIdFilter implements FlatJoinFunction<Tuple2<Long, Long>, Tuple2<Long, Long>, Tuple2<Long, Long>> { @Override
public void join(Tuple2<Long, Long> candidate, Tuple2<Long, Long> old, Collector<Tuple2<Long, Long>> out) {
if (candidate.f1 < old.f1) {
out.collect(candidate);
}
}
} }
3、执行结果
(3,1)
(7,6)
(1,1)
(11,1)
(12,1)
(6,6)
(15,1)
(5,1)
(4,1)
(16,1)
(13,8)
(9,8)
(14,8)
(2,1)
(10,8)
(8,8)
flink 实现ConnectedComponents 连通分量,增量迭代算法(Delta Iteration)实现详解的更多相关文章
- python 排序算法总结及实例详解
python 排序算法总结及实例详解 这篇文章主要介绍了python排序算法总结及实例详解的相关资料,需要的朋友可以参考下 总结了一下常见集中排序的算法 排序算法总结及实例详解"> 归 ...
- SSD算法及Caffe代码详解(最详细版本)
SSD(single shot multibox detector)算法及Caffe代码详解 https://blog.csdn.net/u014380165/article/details/7282 ...
- 关联规则算法(The Apriori algorithm)详解
一.前言 在学习The Apriori algorithm算法时,参考了多篇博客和一篇论文,尽管这些都是很优秀的文章,但是并没有一篇文章详解了算法的整个流程,故整理多篇文章,并加入自己的一些注解,有了 ...
- SSD(single shot multibox detector)算法及Caffe代码详解[转]
转自:AI之路 这篇博客主要介绍SSD算法,该算法是最近一年比较优秀的object detection算法,主要特点在于采用了特征融合. 论文:SSD single shot multibox det ...
- 算法笔记--sg函数详解及其模板
算法笔记 参考资料:https://wenku.baidu.com/view/25540742a8956bec0975e3a8.html sg函数大神详解:http://blog.csdn.net/l ...
- Python实现的数据结构与算法之基本搜索详解
一.顺序搜索 顺序搜索 是最简单直观的搜索方法:从列表开头到末尾,逐个比较待搜索项与列表中的项,直到找到目标项(搜索成功)或者 超出搜索范围 (搜索失败). 根据列表中的项是否按顺序排列,可以将列表分 ...
- Floyd算法(三)之 Java详解
前面分别通过C和C++实现了弗洛伊德算法,本文介绍弗洛伊德算法的Java实现. 目录 1. 弗洛伊德算法介绍 2. 弗洛伊德算法图解 3. 弗洛伊德算法的代码说明 4. 弗洛伊德算法的源码 转载请注明 ...
- Floyd算法(二)之 C++详解
本章是弗洛伊德算法的C++实现. 目录 1. 弗洛伊德算法介绍 2. 弗洛伊德算法图解 3. 弗洛伊德算法的代码说明 4. 弗洛伊德算法的源码 转载请注明出处:http://www.cnblogs.c ...
- Dijkstra算法(二)之 C++详解
本章是迪杰斯特拉算法的C++实现. 目录 1. 迪杰斯特拉算法介绍 2. 迪杰斯特拉算法图解 3. 迪杰斯特拉算法的代码说明 4. 迪杰斯特拉算法的源码 转载请注明出处:http://www.cnbl ...
随机推荐
- Nacos 知识点
Nacos 名字的由来(取红色的英文字符): Dynamic Naming and Configuration Service Nacos 是 Spring Cloud Alibaba 的一个组件,详 ...
- VC 静态库与动态库(三)动态库创建与使用_隐式链接
动态库分为二种,一种隐式链接,另一种显示调用.不论哪种动态库,本质都是运行时动态加载 隐式链接:程序运行时,由编译系统自动加载动态库,然后根据程序的引入表进行重定位,当程序退出时自动卸载动态库 显示调 ...
- Kubernetes prometheus+grafana k8s 监控
参考: https://www.cnblogs.com/terrycy/p/10058944.html https://www.cnblogs.com/weiBlog/p/10629966.html ...
- Shiro密码加密
Shiro密码加密 相关类 org.apache.shiro.authc.credential.CredentialsMatcher org.apache.shiro.authc.credential ...
- MyBatisPlus快速入门
MyBatisPlus快速入门 官方网站 https://mp.baomidou.com/guide 慕课网视频 https://www.imooc.com/learn/1130 入门 https:/ ...
- svn服务器端程序安装(二)
1.下载 Setup-Subversion-1.8.9-1.msi 2. 双击,一直next (1) 修改安装地址,要求是非中文无空格 3. 安装完成后,检查是否已添加到系统的环境变量PATH中,若没 ...
- java第三讲课后动手动脑及代码编写
1. 类就是类型,对象就是这种类型的实例,也就是例子.类是抽象的东西,对象是某种类的实实在在的例子.例如:车是一个类,汽车,自行车就是他的对象. 对象的定义方法? (1)对象声明:类名 对象名: (2 ...
- Codeforces.1029D.Isolation(DP 分块)
题目链接 \(Description\) 给定长为\(n\)的序列\(A_i\)和一个整数\(K\).把它划分成若干段,满足每段中恰好出现过一次的数的个数\(\leq K\).求方案数. \(K\le ...
- oracle--数据库扩容后出现ORA-27102
一,问题描述 Connected to an idle instance. SQL> startup nomount ORA: obsolete or deprecated parameter( ...
- qt no doubments matching "ui..h" could be found
问题情境描述: 自己单独添加的UI文件,然后添加一个类来使用这个UI文件,第一次输入UI Form名称时是大写,被添加到工程里面就是大写, 大写的情况下,添加action转到槽就会提示这个错误. 修改 ...