pandas数据处理
首先,数据加载
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数,期中read_csv和read_table这两个使用最多。


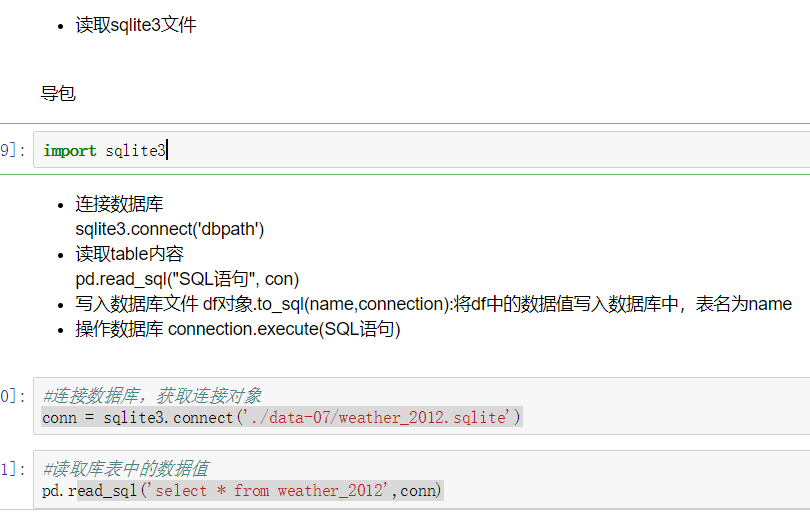
1、删除重复元素
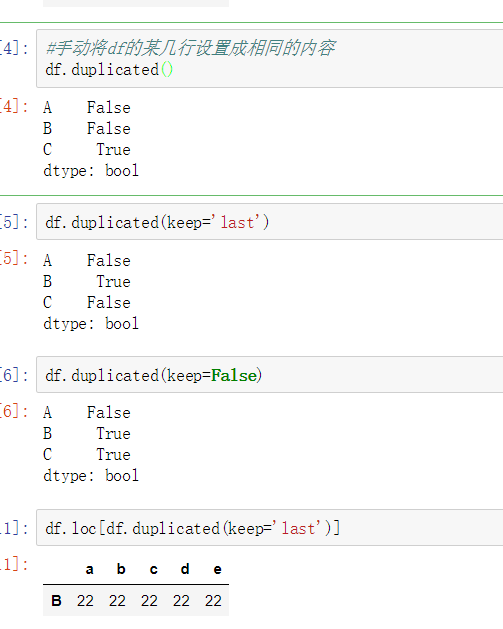
使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True。
- keep参数:指定保留哪一重复的行数据
- True 重复的行- 创建具有重复元素行的DataFrame
from pandas import Series,DataFrame
import numpy as np
import pandas as pd #创建一个df
np.random.seed(10)
df = DataFrame(data=np.random.randint(0,100,size=(3,5)),index=['A','B','C'],columns=['a','b','c','d','e'])
df
# a b c d e
A 9 15 64 28 89
B 93 29 8 73 0
C 40 36 16 11 54 df.loc['B'] = ['','','','','']
df.loc['C'] = ['','','','','']
df
# a b c d e
A 9 15 64 28 89
B 22 22 22 22 22
C 22 22 22 22 22
- 使用duplicated查看所有重复元素行
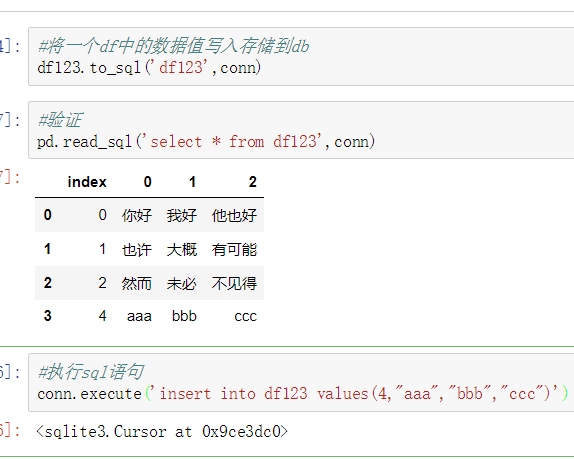
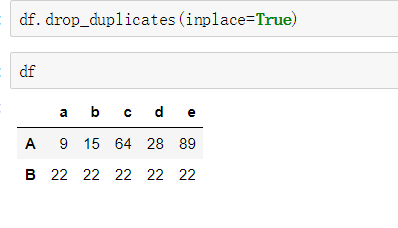
使用drop_duplicates()函数删除重复的行
- drop_duplicates(keep='first/last'/False)
2. 映射:指定替换
1) replace()函数:替换元素
使用replace()函数,对values进行映射操作
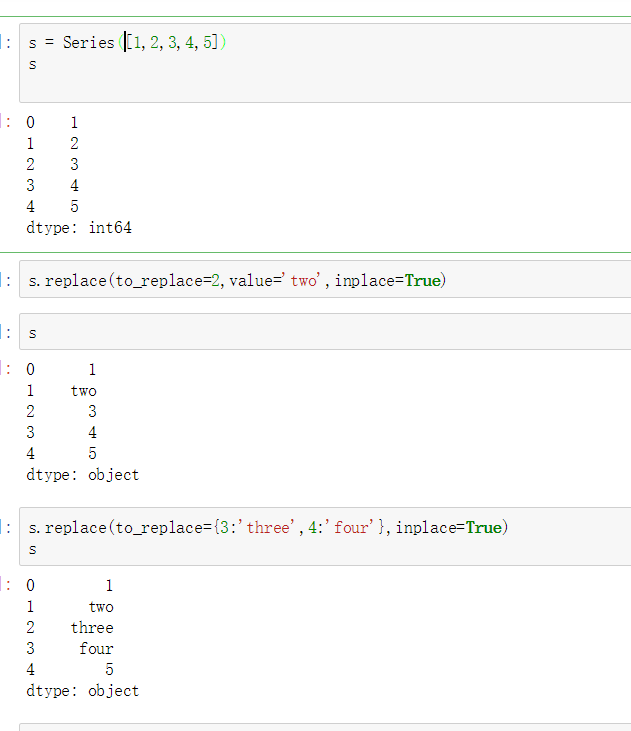
Series替换操作
- 单值替换
- 普通替换
- 字典替换(推荐)
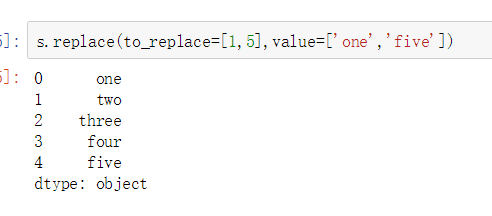
- 多值替换
- 列表替换
- 字典替换(推荐)
- 参数
- to_replace:被替换的元素
单值普通替换
eplace参数说明:
- method:对指定的值使用相邻的值填充替换
- limit:设定填充次数
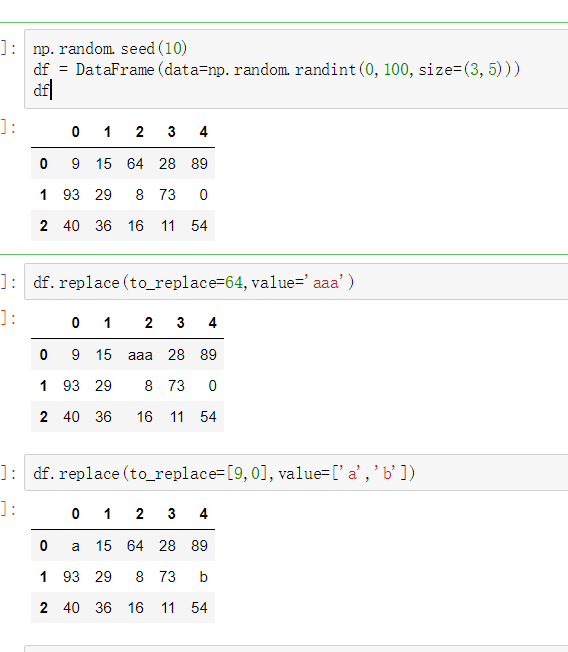
DataFrame替换操作
- 单值替换
- 普通替换: 替换所有符合要求的元素:to_replace=15,value='e'
- 按列指定单值替换: to_replace={列标签:替换值} value='value'
- 多值替换
- 列表替换: to_replace=[] value=[]
- 字典替换(推荐) to_replace={to_replace:value,to_replace:value}

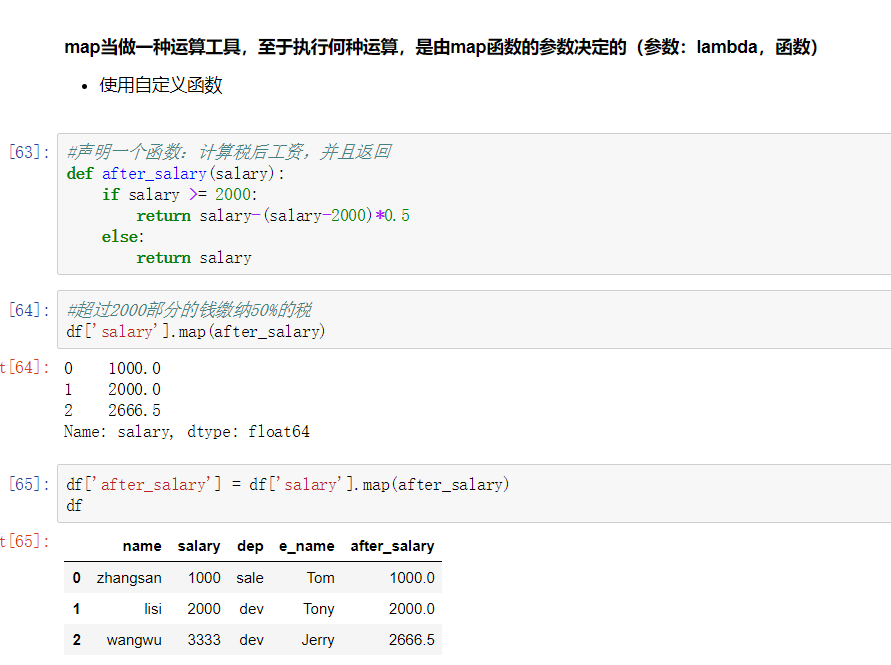
2) map()函数:新建一列 , map函数并不是df的方法,而是series的方法
- map是Series的一个函数
- map()可以映射新一列数据
- map()中可以使用lambd表达式
map()中可以使用方法,可以是自定义的方法
eg:map({to_replace:value})
- 注意 map()中不能使用sum之类的函数,for循环

注意:并不是任何形式的函数都可以作为map的参数。只有当一个函数具有一个参数且有返回值,那么该函数才可以作为map的参数。
3. 使用聚合操作对数据异常值检测和过滤
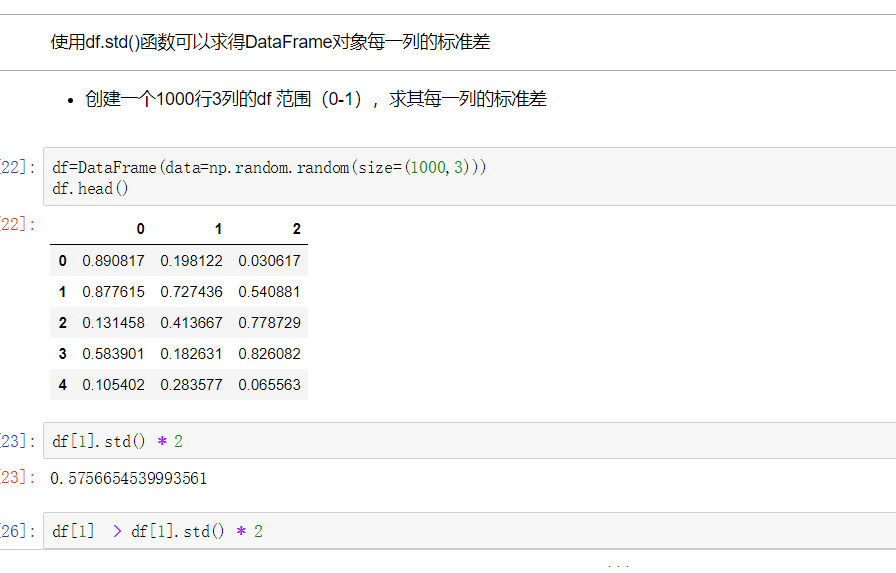

4. 排序
使用.take()函数排序
- take()函数接受一个索引列表,用数字表示,使得df根据列表中索引的顺序进行排序
- eg:df.take([1,3,4,2,5])
可以借助np.random.permutation()函数随机排序

随机抽样
当DataFrame规模足够大时,直接使用np.random.permutation(x)函数,就配合take()函数实现随机抽样
5. 数据分类处理
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心:
- groupby()函数
- groups属性查看分组情况
- eg: df.groupby(by='item').groups分组




pandas数据处理的更多相关文章
- python pandas 数据处理
pandas是基于numpy包扩展而来的,因而numpy的绝大多数方法在pandas中都能适用. pandas中我们要熟悉两个数据结构Series 和DataFrame Series是类似于数组的对象 ...
- Pandas数据处理实战:福布斯全球上市企业排行榜数据整理
手头现在有一份福布斯2016年全球上市企业2000强排行榜的数据,但原始数据并不规范,需要处理后才能进一步使用. 本文通过实例操作来介绍用pandas进行数据整理. 照例先说下我的运行环境,如下: w ...
- 数据分析入门——pandas数据处理
1,处理重复数据 使用duplicated检测重复的行,返回一个series,如果不是第一次出现,也就是有重复行的时候,则为True: 对应的,可以使用drop_duplicates来删除重复的行: ...
- pandas数据处理基础——筛选指定行或者指定列的数据
pandas主要的两个数据结构是:series(相当于一行或一列数据机构)和DataFrame(相当于多行多列的一个表格数据机构). 本文为了方便理解会与excel或者sql操作行或列来进行联想类比 ...
- Python———pandas数据处理
pandas模块 更高级的数据分析工具基于NumPy构建包含Series和DataFrame两种数据结构,以及相应方法 调用方法:from pandas import Series, DataFra ...
- Pandas数据处理+Matplotlib绘图案例
利用pandas对数据进行预处理然后再使用matplotlib对处理后的数据进行数据可视化是数据分析中常用的方法. 第一组例子(星巴克咖啡店) 假如我们现在有这样一组数据:星巴克在全球的咖啡店信息,如 ...
- pandas数据处理攻略
首先熟悉numpy随机n维数组的生成方法(只列出常用的函数): np.random.random([3, 4]) #生成shape为[3, 4]的随机数组,随机数范围[0.0, 1.0) np.ran ...
- pandas 数据处理
1. 查看数值数据的整体分布情况 datafram.describe() 输出: agecount 1463.000000mean 22.948052std 8.385384min 13.000000 ...
- Pandas数据处理 学习
pandas是在numpy的基础上建立的新程序库,提供了一种高效的DataFrame数据结构. DataFrame本质上是一种带行标签和列标签.支持相同数据类型和缺失值的多维数组. 先看版本信息: p ...
随机推荐
- openresty开发系列34--openresty执行流程之4访问阶段
openresty开发系列34--openresty执行流程之4访问阶段 访问阶段 用途:访问权限限制 返回403 nginx:allow 允许,deny 禁止 allow ip:deny ip: 涉 ...
- django项目模型字段
一个模型(model)就是一个单独的.确定的数据的信息源,包含了数据的字段和操作方法.通常,每个模型映射为一张数据库中的表. 基本的原则如下: 每个模型在Django中的存在形式为一个Python类 ...
- [LeetCode] 250. Count Univalue Subtrees 计算唯一值子树的个数
Given a binary tree, count the number of uni-value subtrees. A Uni-value subtree means all nodes of ...
- [LeetCode] 251. Flatten 2D Vector 压平二维向量
Implement an iterator to flatten a 2d vector. For example,Given 2d vector = [ [1,2], [3], [4,5,6] ] ...
- Dubbo版本升级
一.背景 早期内部使用的是当当网fork的Dubbox,由于现在Dubbo又开始重新维护,而且阿里将其捐献给了Apache,并成为了Apache的顶级项目.因此dubbo版本升级到2.7.1势在必行. ...
- springcloud 连接docker中运行的RabbitMQ消息中间件。
参考:https://blog.51cto.com/zero01/2173288 主要是记录几个坑: 第一个坑:开始订单服务中配置文件是: #配置rabbitmq 2019.5.17 added by ...
- web版本的用户登陆票据 FormsAuthenticationTicket
FormsAuthenticationTicket ticket = new FormsAuthenticationTicket(1, "username", DateTime.N ...
- 从GitLab上创建分支本地拉取项目和提交项目详解
很多公司前端项目都是部署在GitLab上的,今天我要分享的就是如何从GitLab上创建新的分支并在本地拉取和提交项目 一.在GitLab上面创建自己新的分支 首先你得注册一个账号,登陆之后进入项目Pr ...
- dockfile构建自己的tomcat
touch Dockerfile 在Dockerfile中输入以下内容 FROM centosMAINTAINER Irish<3395327965@qq.com>#把宿主机当前上下文的 ...
- Python-16-继承、封装、多态
一.继承 1. 概念 继承是一种创建新类的方式,新建的类可以继承一个或多个父类(python支持多继承),父类又可称为基类或超类,新建的类称为派生类或子类. 子类会“”遗传”父类的属性,从而解决代码重 ...