Zipkin+Sleuth 链路追踪整合
1.Zipkin
是一个开放源代码分布式的跟踪系统
它可以帮助收集服务的时间数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现
每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,展示多少跟踪请求经过了哪些服务,该系统让开发者可通过一个web前端轻松地收集和分析数据,可非常方便的监测系统中存在的瓶颈
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch
生产数据量大的情况则推荐使用Elasticsearch
2.Spring Cloud Sleuth
为服务之间的调用提供链路追踪,通过使用Sleuth可以让我们快速定位某个服务的问题
分布式服务追踪系统包括:数据收集、数据存储、数据展示
通过Sleuth产生的调用链监控信息,让我们可以得知微服务之间的调用链路,但是监控信息只输出到控制台不太方便查看
Sleuth和Zipkin结合,将信息发送到Zipkin,利用Zipkin的存储来存储信息,利用Zipkin UI来展示信息
1.使用curl下载
curl -sSL https://zipkin.io/quickstart.sh | bash -s
下载了文件zipkin-server-2.19.1-exec.jar
2.启动服务
java -jar zipkin-server-2.19.-exec.jar

通过http://localhost:9411可访问zipkin的监控页面
因为还没有客户端,所以还没有数据
默认启动方式会将日志数据存在内存中,一旦服务重启会清空数据,可以使用es进行持久化存储
3.应用
添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
spring-cloud-dependencies
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Finchley.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
配置
spring.application.name=demo
spring.zipkin.base-url=http://localhost:9411
spring.sleuth.sampler.probability=1.0
样本采集量,默认为0.1,为了测试修改为1,正式环境一般使用默认值
package com.example.demo.controller; import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController; @RestController
public class Demo { @RequestMapping("hello")
public String hello() {
return "Hello World!";
}
}
运行示例,在postman里执行http://localhost:8080/hello
再查看http://localhost:9411,出现了刚刚访问的服务,选择并点击追踪
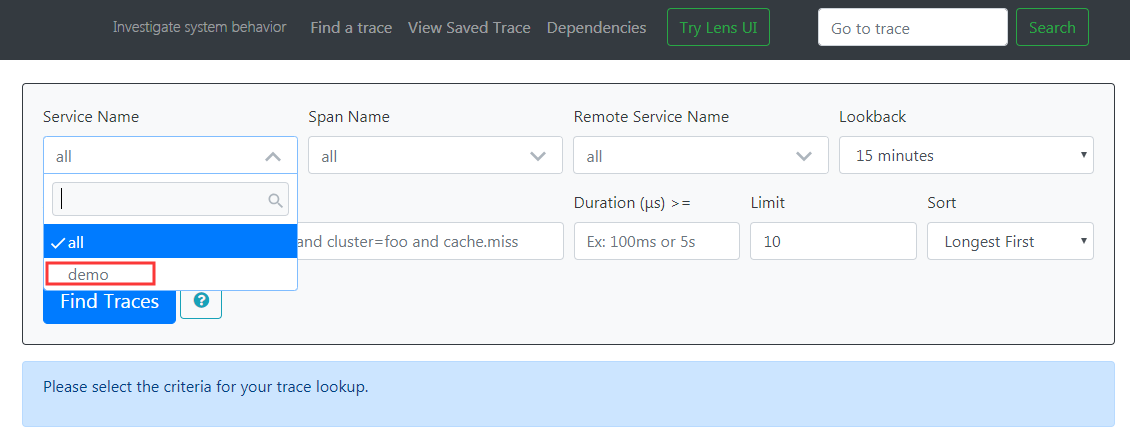
选择demo服务,点击Find Traces
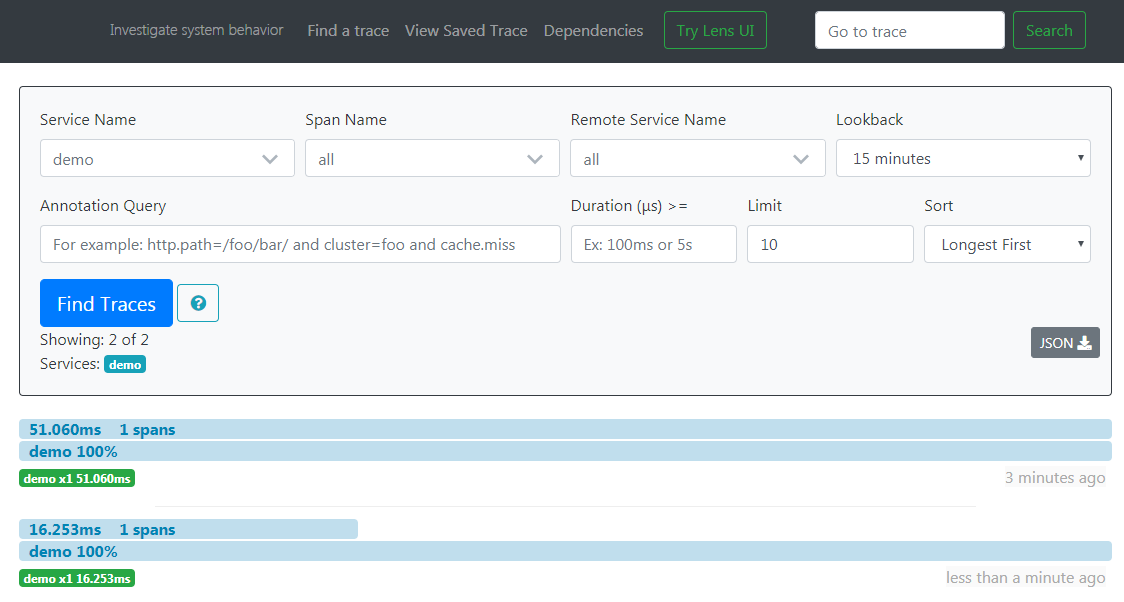
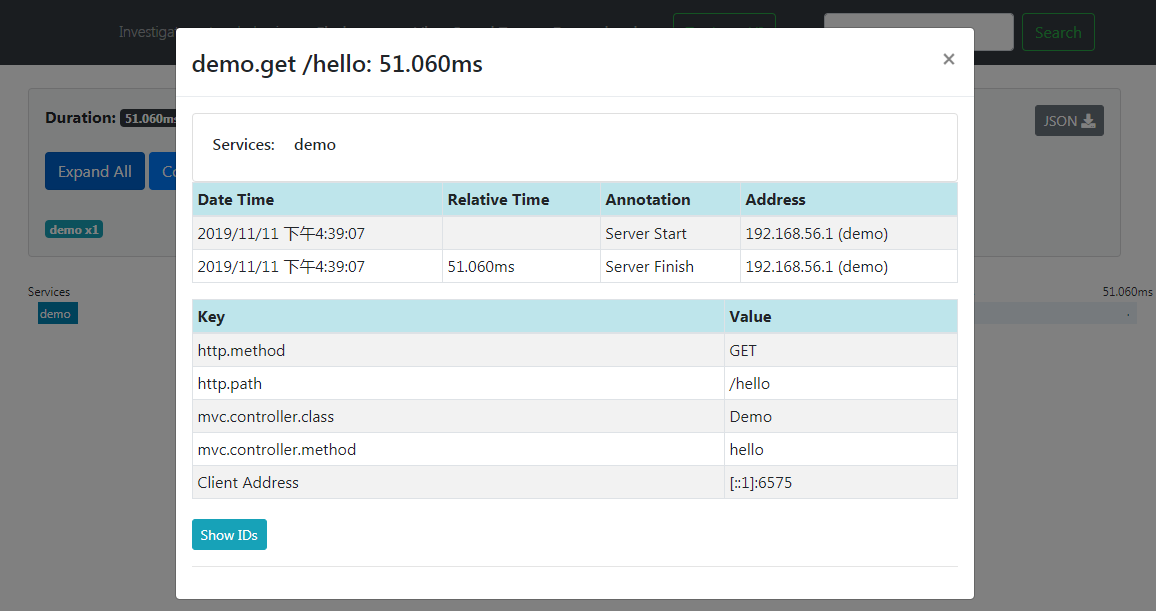
点击调用记录查看详情页面,可以看到每一个服务所耗费的时间和顺序
3.通过ElasticSearch进行存储
ElasticSearch安装启动(安装说明)
zipkin服务启动命令改为
java -DSTORAGE_TYPE=elasticsearch -DES_HOSTS=http://localhost:9200 -jar zipkin-server-2.19.1-exec.jar
zipkin会在es中创建以zipkin开头日期结尾的index,并且默认以天为单位分割
使用kibana查看数据(kibana使用)


https://zipkin.io/pages/quickstart.html
Zipkin+Sleuth 链路追踪整合的更多相关文章
- SpringCloud Sleuth + Zipkin 实现链路追踪
一.Sleuth介绍 为什么要使用微服务跟踪? 它解决了什么问题? 1.微服务的现状? 随着业务的发展,单体架构变为微服务架构,并且系统规模也变得越来越大,各微服务间的调用关系也变得越来越复杂 ...
- spring cloud 2.x版本 Sleuth+Zipkin分布式链路追踪
前言 本文采用Spring cloud本文为2.1.8RELEASE,version=Greenwich.SR3 本文基于前两篇文章eureka-server.eureka-client.eureka ...
- spring cloud 系列第7篇 —— sleuth+zipkin 服务链路追踪 (F版本)
源码Gitub地址:https://github.com/heibaiying/spring-samples-for-all 一.简介 在微服务架构中,几乎每一个前端的请求都会经过多个服务单元协调来提 ...
- Spring Cloud 系列之 Sleuth 链路追踪(一)
随着微服务架构的流行,服务按照不同的维度进行拆分,一次请求往往需要涉及到多个服务.互联网应用构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发.可能使用不同的编程语言来实现.有可能布在了 ...
- Spring Cloud 系列之 Sleuth 链路追踪(二)
本篇文章为系列文章,未读第一集的同学请猛戳这里:Spring Cloud 系列之 Sleuth 链路追踪(一) 本篇文章讲解 Sleuth 基于 Zipkin 存储链路追踪数据至 MySQL,Elas ...
- zipkin分布式链路追踪系统
基于zipkin分布式链路追踪系统预研第一篇 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Inf ...
- Spring Cloud 系列之 Sleuth 链路追踪(三)
本篇文章为系列文章,未读前几集的同学请猛戳这里: Spring Cloud 系列之 Sleuth 链路追踪(一) Spring Cloud 系列之 Sleuth 链路追踪(二) 本篇文章讲解 Sleu ...
- SpringCloud之链路追踪整合Sleuth(十三)
前言 SpringCloud 是微服务中的翘楚,最佳的落地方案. 在一个完整的微服务架构项目中,服务之间的调用是很复杂的,当其中某一个服务出现了问题或者访问超时,很 难直接确定是由哪个服务引起的,所以 ...
- 原理分析dubbo分布式应用中使用zipkin做链路追踪
zipkin是什么 Zipkin是一款开源的分布式实时数据追踪系统(Distributed Tracking System),基于 Google Dapper的论文设计而来,由 Twitter 公司开 ...
随机推荐
- UI系统的分类
1.DSL系统:UI领域特定语言 html markdown; 与平台无关,只与通用UI领域有关: 2.平台语言系统(通用语言系统) UI概念在平台和通用语言中的表示. 一.信息表达: 基本信息:文本 ...
- 重温Elasticsearch
什么是 Elasticsearch ? Elasticsearch (ES) 是一个基于 Lucene 构建的开源.分布式.RESTful 接口全文搜索引擎.还是一个分布式文档数据库,其中每个字段均是 ...
- vue基于页面中按钮权限控制
main.js // 权限 /** 权限指令,对按钮权限的控制 **/ Vue.directive('allow', { bind: function(el, binding) { // 通过当前按钮 ...
- vector的使用注意事项
示例1: #include "iostream" #include "vector" using namespace std; int main(void) { ...
- 洛谷p3398仓鼠找suger题解
我现在爱死树链剖分了 题目 具体分析的话在洛谷blog里 这里只是想放一下改完之后的代码 多了一个son数组少了一个for 少了找size最大的儿子的for #include <cstdio&g ...
- JMeter压测工具安装及使用总结
一.安装 进入apache官网https://www.apache.org/dist/jmeter/binaries下载Windows版本JMeter: 二.配置环境变量 下载之后解压,配置环境变量 ...
- 【POJ3414】Pots
本题传送门 本题知识点:宽度优先搜素 + 字符串 题意很简单,如何把用两个杯子,装够到第三个杯子的水. 操作有六种,这样就可以当作是bfs的搜索方向了 // FILL(1) 把第一个杯子装满 // F ...
- SpringBoot:使用Jenkins自动部署SpringBoot项目(二)具体配置
1.启动Jenkins 在浏览器输入ip:port后,进入Jenkins初始化界面,需要查看文件,得到密码. 输入密码进入初始化界面,选择推荐插件安装. 安装完成创建账号,进入Jenkins主界面. ...
- mfs分布式文件系统,分布式存储,高可用(pacemaker+corosync+pcs),磁盘共享(iscsi),fence解决脑裂问题
一.MFS概述 MooseFS是一个分布式存储的框架,其具有如下特性:(1)通用文件系统,不需要修改上层应用就可以使用(那些需要专门api的dfs很麻烦!).(2)可以在线扩容,体系架构可伸缩性极强. ...
- Android Studio 点运行启用时,列表中不显示虚拟机,但是实际上在AVD Manager中已经添加了2个虚拟设备了
Android Studio 点运行启用时,列表中不显示虚拟机,但是实际上在AVD Manager中已经添加了2个虚拟设备了 百度上找了一下方法, 情况出现:打开androidstudio,一直连接不 ...