Zipkin+Sleuth 链路追踪整合
1.Zipkin
是一个开放源代码分布式的跟踪系统
它可以帮助收集服务的时间数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现
每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图,展示多少跟踪请求经过了哪些服务,该系统让开发者可通过一个web前端轻松地收集和分析数据,可非常方便的监测系统中存在的瓶颈
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch
生产数据量大的情况则推荐使用Elasticsearch
2.Spring Cloud Sleuth
为服务之间的调用提供链路追踪,通过使用Sleuth可以让我们快速定位某个服务的问题
分布式服务追踪系统包括:数据收集、数据存储、数据展示
通过Sleuth产生的调用链监控信息,让我们可以得知微服务之间的调用链路,但是监控信息只输出到控制台不太方便查看
Sleuth和Zipkin结合,将信息发送到Zipkin,利用Zipkin的存储来存储信息,利用Zipkin UI来展示信息
1.使用curl下载
curl -sSL https://zipkin.io/quickstart.sh | bash -s
下载了文件zipkin-server-2.19.1-exec.jar
2.启动服务
java -jar zipkin-server-2.19.-exec.jar

通过http://localhost:9411可访问zipkin的监控页面
因为还没有客户端,所以还没有数据
默认启动方式会将日志数据存在内存中,一旦服务重启会清空数据,可以使用es进行持久化存储
3.应用
添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
spring-cloud-dependencies
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Finchley.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
配置
spring.application.name=demo
spring.zipkin.base-url=http://localhost:9411
spring.sleuth.sampler.probability=1.0
样本采集量,默认为0.1,为了测试修改为1,正式环境一般使用默认值
package com.example.demo.controller; import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController; @RestController
public class Demo { @RequestMapping("hello")
public String hello() {
return "Hello World!";
}
}
运行示例,在postman里执行http://localhost:8080/hello
再查看http://localhost:9411,出现了刚刚访问的服务,选择并点击追踪
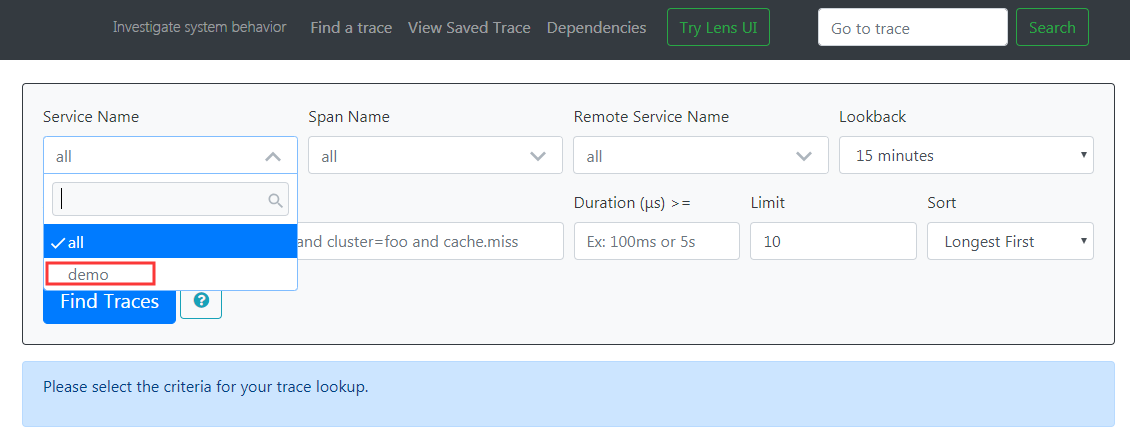
选择demo服务,点击Find Traces
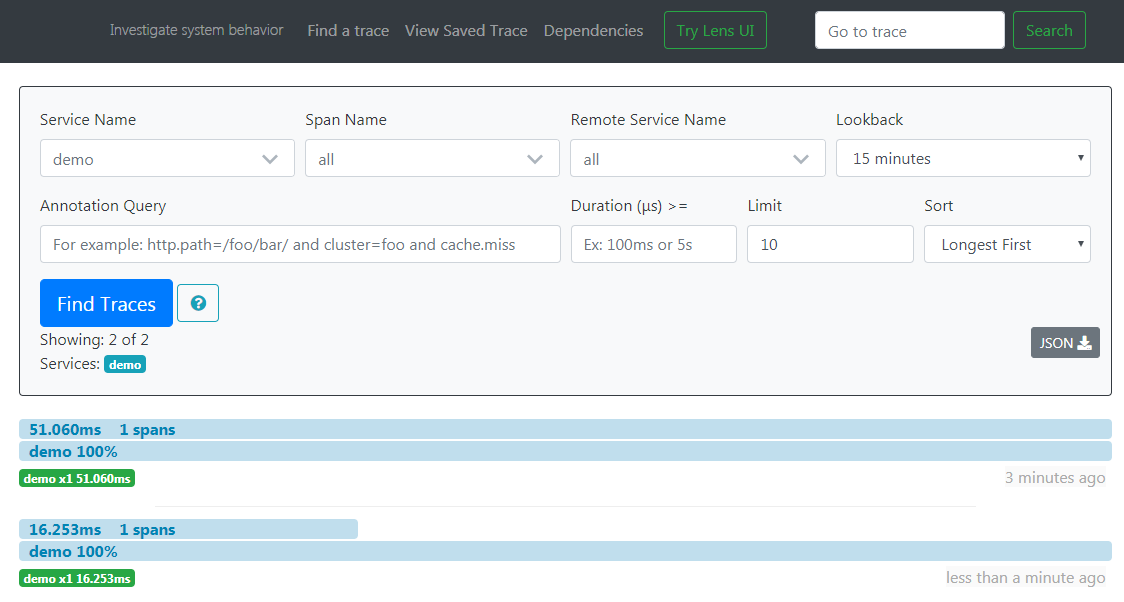
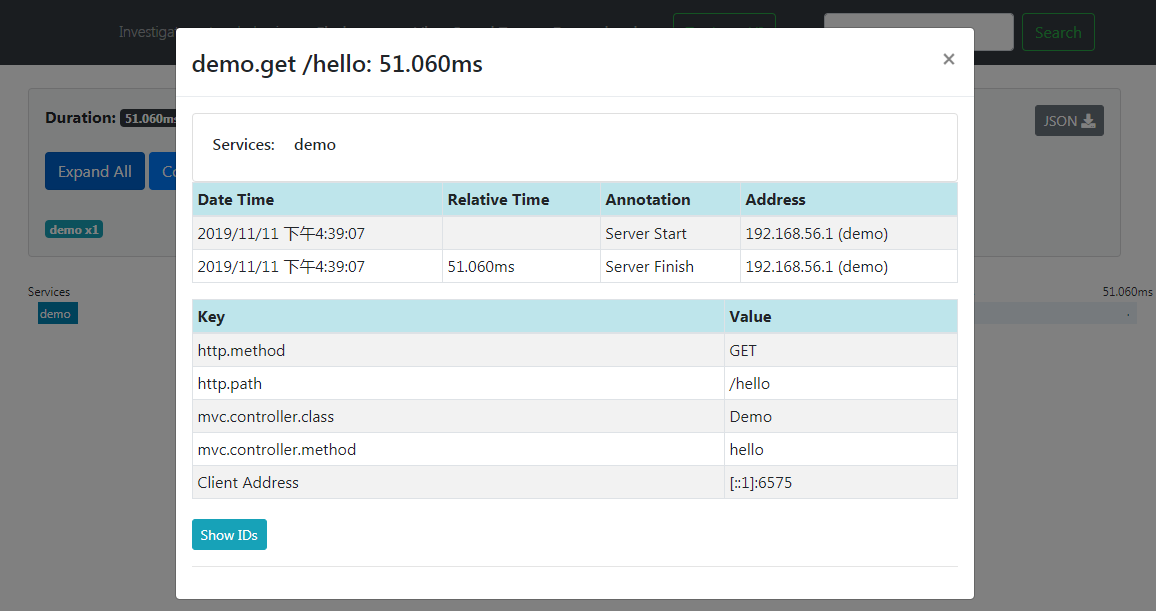
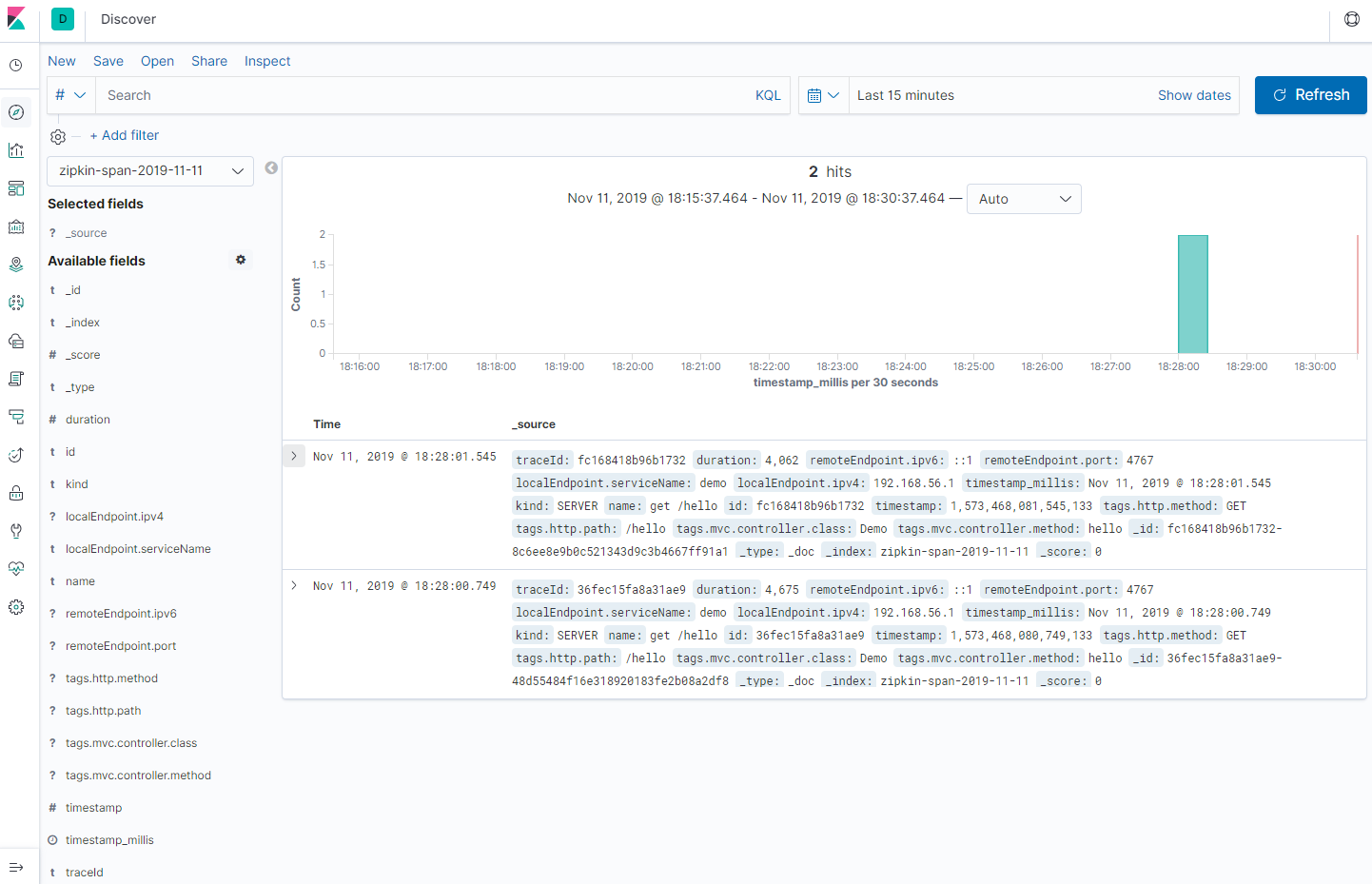
点击调用记录查看详情页面,可以看到每一个服务所耗费的时间和顺序
3.通过ElasticSearch进行存储
ElasticSearch安装启动(安装说明)
zipkin服务启动命令改为
java -DSTORAGE_TYPE=elasticsearch -DES_HOSTS=http://localhost:9200 -jar zipkin-server-2.19.1-exec.jar
zipkin会在es中创建以zipkin开头日期结尾的index,并且默认以天为单位分割
使用kibana查看数据(kibana使用)


https://zipkin.io/pages/quickstart.html
Zipkin+Sleuth 链路追踪整合的更多相关文章
- SpringCloud Sleuth + Zipkin 实现链路追踪
一.Sleuth介绍 为什么要使用微服务跟踪? 它解决了什么问题? 1.微服务的现状? 随着业务的发展,单体架构变为微服务架构,并且系统规模也变得越来越大,各微服务间的调用关系也变得越来越复杂 ...
- spring cloud 2.x版本 Sleuth+Zipkin分布式链路追踪
前言 本文采用Spring cloud本文为2.1.8RELEASE,version=Greenwich.SR3 本文基于前两篇文章eureka-server.eureka-client.eureka ...
- spring cloud 系列第7篇 —— sleuth+zipkin 服务链路追踪 (F版本)
源码Gitub地址:https://github.com/heibaiying/spring-samples-for-all 一.简介 在微服务架构中,几乎每一个前端的请求都会经过多个服务单元协调来提 ...
- Spring Cloud 系列之 Sleuth 链路追踪(一)
随着微服务架构的流行,服务按照不同的维度进行拆分,一次请求往往需要涉及到多个服务.互联网应用构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发.可能使用不同的编程语言来实现.有可能布在了 ...
- Spring Cloud 系列之 Sleuth 链路追踪(二)
本篇文章为系列文章,未读第一集的同学请猛戳这里:Spring Cloud 系列之 Sleuth 链路追踪(一) 本篇文章讲解 Sleuth 基于 Zipkin 存储链路追踪数据至 MySQL,Elas ...
- zipkin分布式链路追踪系统
基于zipkin分布式链路追踪系统预研第一篇 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Inf ...
- Spring Cloud 系列之 Sleuth 链路追踪(三)
本篇文章为系列文章,未读前几集的同学请猛戳这里: Spring Cloud 系列之 Sleuth 链路追踪(一) Spring Cloud 系列之 Sleuth 链路追踪(二) 本篇文章讲解 Sleu ...
- SpringCloud之链路追踪整合Sleuth(十三)
前言 SpringCloud 是微服务中的翘楚,最佳的落地方案. 在一个完整的微服务架构项目中,服务之间的调用是很复杂的,当其中某一个服务出现了问题或者访问超时,很 难直接确定是由哪个服务引起的,所以 ...
- 原理分析dubbo分布式应用中使用zipkin做链路追踪
zipkin是什么 Zipkin是一款开源的分布式实时数据追踪系统(Distributed Tracking System),基于 Google Dapper的论文设计而来,由 Twitter 公司开 ...
随机推荐
- Fiddler实现篡改接口请求和返回数据
步骤如下: 点击rules->Automatic Breakpoints,在这个选项下,我们可以看到三个可选项: Before Requests:在请求发出前拦截请求: After Reques ...
- What is the difference between Reactjs and Rxjs?--React is the V (View) in MVC (Model/View/Controller).
This is really different, React is view library; and Rxjs is reactive programming library for javasc ...
- Web安全之CSRF基本原理与实践
阅读目录 一:CSRF是什么?及它的作用? 二:CSRF 如何实现攻击 三:csrf 防范措施 回到顶部 一:CSRF是什么?及它的作用? CSRF(Cross-site Request Forger ...
- JavaScript基础10——正则
什么是正则? 正则表达式(regular expression)是一个描述字符规则的对象.可以用来检查一个字符串是否含有某个字符,将匹配的字符做替换或者从某个字符串中取出某个条件的子串等. ...
- REdis一致性方案探讨
REdis功能强大众所周知,能够大幅简化开发和提供大并发高性能,但截止到REdis-5.0.5仍然存在如下几大问题: 一致性问题 这是由于REdis的主从复制采用的是异步复制,异常时可能发生主节点的数 ...
- SSH登录慢解方案 - 关闭UseDNS加速
每次登录SSH时总是要停顿等待一会儿才能连接上,,这是因为OpenSSH服务器有一个DNS查找选项UseDNS默认情况下是打开的. UseDNS 选项打开状态下,当通过终端登录SSH服务器时,服务器端 ...
- 19 条效率至少提高 3 倍的 MySQL 技巧
阅读本文大概需要 4 分钟. 来源:https://zhuanlan.zhihu.com/p/49888088 本文我们来谈谈项目中常用的 MySQL 优化方法,共 19 条,具体如下: 1.EXPL ...
- Gamma阶段第四次scrum meeting
每日任务内容 队员 昨日完成任务 明日要完成的任务 张圆宁 #91 用户体验与优化https://github.com/rRetr0Git/rateMyCourse/issues/91(持续完成) # ...
- 一分钟理解什么是REST和RESTful
从事web开发工作有一小段时间,REST风格的接口,这样的词汇总是出现在耳边,然后又没有完全的理解,您是不是有和我相同的疑问呢?那我们一起来一探究竟吧! 就是用URL定位资源,用HTTP描述操作. 知 ...
- rabbitmq在linux下单节点部署和基本使用
RabbitMQ是基于erlang开发的消息服务,官网为:https://www.rabbitmq.com,RabbitMQ要依赖erlang运行,所以要先安装erlang环境,rabbitmq可以用 ...