Multi-shot Pedestrian Re-identification via Sequential Decision Making
Multi-shot Pedestrian Re-identification via Sequential Decision Making
2019-07-31 20:33:37
Code: https://github.com/TuSimple/rl-multishot-reid
1. Background and Motivation:
本文引入 DRL 到 person re-ID 任务,通过序列决策来完成难易样本的识别问题。主要动机如下图所示:

2. The Proposed Method:
2.1 Image-level feature extraction:
作者对图像特征提取,采用了多个组合损失函数的形式,即:classification loss, pairwise verification loss, and triplet verification loss。用了两种经典的骨干网络,即:Inception-BN 和 AlexNet。作者将一个序列中所有图像的 feature 进行聚合,得到 l2-normalized features,即:
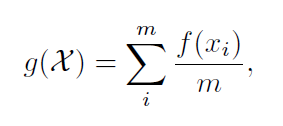
并且根据 l (*, *) 进行 identities 的排序,即:
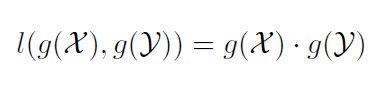
2.2 Sequence Level Feature Aggregation :
作者将该问题看做是 Markov Decision Processes (MDP), 表达为 (S, A, T, R)。 在每一个步骤中,agent 将会从两个输入序列中得到一个选择的图像对,来观察 state,然后选择一个动作,接下来该 agent 将会得到一个奖励 r。在此之后,如果序列没有结束,该智能体将会接收下一个 image pair,然后得到一个新的 state。
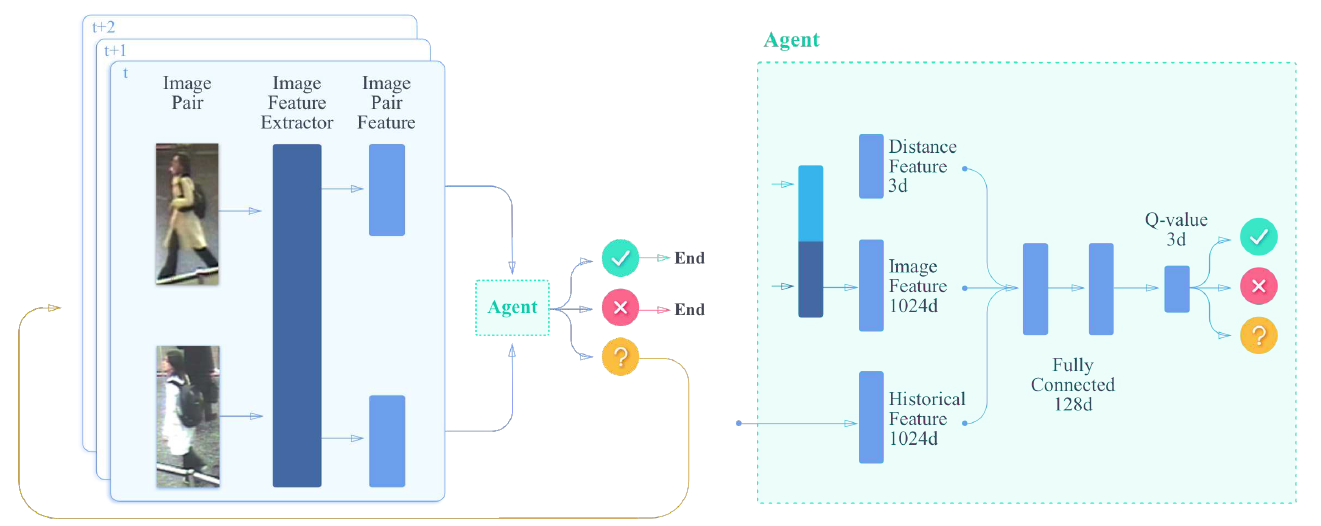
Actions and Transitions:
首先随机的从两个序列中,选择两个图像,构成 image pair。然后将该样本对输入到 agent 中,agent 会输出三个动作:same, different, and unsure。前两个动作将会停止当前的 episode,然后即可输出当前的结果。作者认为当智能体收集到了足够的信息,并且足够自信来进行决策的时候,就可以及时停止以避免不必要的计算代价。如果智能体选择的 action 是 unsure,那么我们将会选择其他的 image pair 来进行判别。
Rewards:我们定义如下的奖励情况:
如果 agent 给定的结果和 gt 一致,那么给定 +1 的奖励;
如果 at 与 gt 不同,奖励将是 -1;要么当 t = $t_{max}$ 时,at 仍然是 unsure 的时候;
当 t < $t_{max}$,$a_t$ 是 unsure 的时候,奖励是 $r_p$ ;
这里的 rp 可能是 + 也可能是 -,具体看情况:If rp is negative, it will be penalized for requesting more pairs; on the other hand, if rp is positive, we encourage the agent to gather more pairs, and stop gathering when it has collected $t_{max}$ pairs to avoid a penalty of -1. 这个值,将会极大地影响最终 agent 的行为。
States and Deep Q-learning:
我们使用 deep Q-learning 来找到最优的策略。对于每一个 state and action $(s_t, a_t)$, $Q(s_t, a_t)$ 代表了当前状态和动作下的折扣的累积奖励。在训练阶段,我们可以迭代的更新 Q-function:
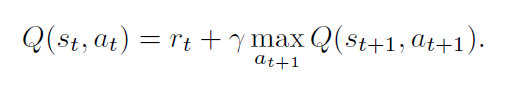
在时刻 t,状态 st 由如下的三个部分构成:
1). the first part is the observation $o_t$,即图像的特征;
2). the second part is a weighted average of the difference between historical image features of two sequences; 权重计算方法如下:

3). we also augment the image features with hand-crafted features for better discrimination.
3. Experimental Results:
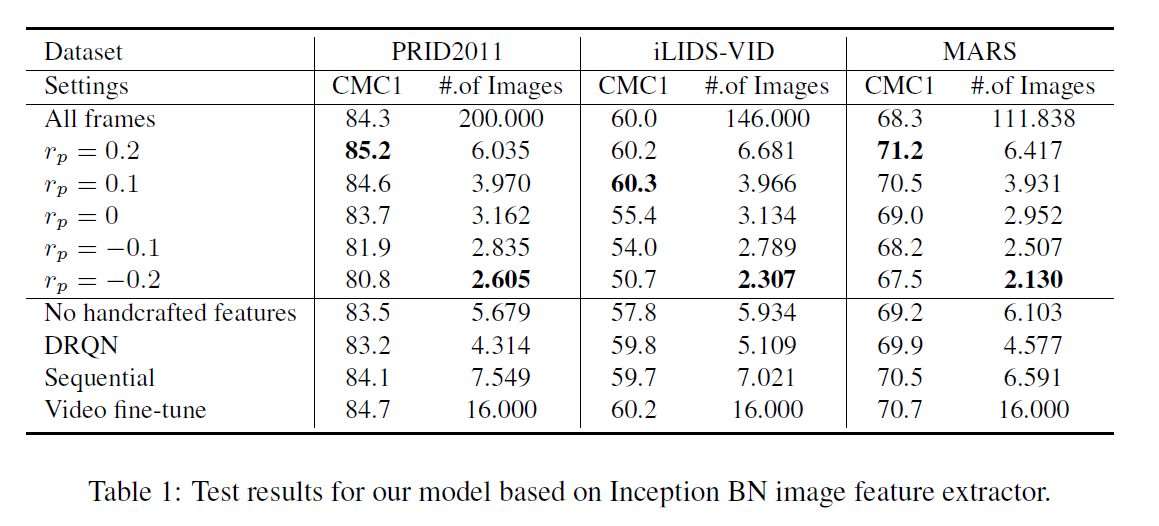

==
Multi-shot Pedestrian Re-identification via Sequential Decision Making的更多相关文章
- Parallel Gradient Boosting Decision Trees
本文转载自:链接 Highlights Three different methods for parallel gradient boosting decision trees. My algori ...
- ICCV 2017论文分析(文本分析)标题词频分析 这算不算大数据 第一步:数据清洗(删除作者和无用的页码)
IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017. IEE ...
- ICLR 2013 International Conference on Learning Representations深度学习论文papers
ICLR 2013 International Conference on Learning Representations May 02 - 04, 2013, Scottsdale, Arizon ...
- metasploit-post模块信息
Name Disclosure Date Rank Description ---- ...
- Andrew Ng机器学习公开课笔记–Reinforcement Learning and Control
网易公开课,第16课 notes,12 前面的supervised learning,对于一个指定的x可以明确告诉你,正确的y是什么 但某些sequential decision making问题,比 ...
- Learning Structured Representation for Text Classification via Reinforcement Learning 学习笔记
Representation learning : 表征学习,端到端的学习 pre-specified 预先指定的 demonstrate 论证;证明,证实;显示,展示;演示,说明 attempt ...
- David Silver强化学习Lecture1:强化学习简介
课件:Lecture 1: Introduction to Reinforcement Learning 视频:David Silver深度强化学习第1课 - 简介 (中文字幕) 强化学习的特征 作为 ...
- (转)Applications of Reinforcement Learning in Real World
Applications of Reinforcement Learning in Real World 2018-08-05 18:58:04 This blog is copied from: h ...
- 论文笔记之:SeqGAN: Sequence generative adversarial nets with policy gradient
SeqGAN: Sequence generative adversarial nets with policy gradient AAAI-2017 Introduction : 产生序列模拟数 ...
随机推荐
- .NET Framework 项目多环境下配置文件web.config
解决jenkins自动构建发布的问题,统一从git/svn库中获取项目文件,根据不同配置编译发布到多个运行环境中. 转自:https://www.cnblogs.com/hugogoos/p/6426 ...
- MavenWrapper替代Maven
1. 说明 jdk8已经安装成功 Maven已经安装成功 参见Maven Wrapper 2. Maven初始化项目 注:初次执行,Maven会下载很多jar,需等待几分钟 mvn archetype ...
- H3C 802.11网络的基本元素
- Python入门篇-functools
Python入门篇-functools 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.reduce方法 reduce方法,顾名思义就是减少 reduce(function,se ...
- 使用树莓派GPIO控制继电器
一.使用方法总结: VCC接+5v,GND接负,IN1接GPIO口, 二.然后使用Linux命令或者编程控制GPIO口高低电位即可,如:执行下列命令: gpio readall 列出所有针角 gp ...
- 《逆袭团队》第九次团队作业【Beta】Scrum meeting 3
项目 内容 软件工程 任课教师博客主页链接 作业链接地址 团队作业9:Beta冲刺与团队项目验收 团队名称 逆袭团队 具体目标 (1)掌握软件黑盒测试技术:(2)学会编制软件项目总结PPT.项目验收报 ...
- less-6
首先输入id=1和id=1’未报错,均显示You are in.....(如下图所示) 由上图可以看到,如果运行返回结果正确的时候只返回you are in...,不会返回数据库当中的信息了,可以从这 ...
- jquery ajax请求数据超时设置
var ajaxTimeoutTest = $.ajax({ url:'', //请求的URL timeout : 1000, //超时时间设置,单位毫秒 type : 'get', //请求方式,g ...
- python的多线程是否没有用了
python的多线程是否就完全没有用了呢? 相同的代码,为何有时候多线程会比单线程慢,有时又会比单线程快? 这主要跟运行的代码有关: 1. CPU密集型代码 (各种循环处理.计数等等 ),在这种情况下 ...
- vue中点击不同的em添加class去除兄弟级class
vue中使用v-for循环li 怎么点击每个li中的em给添加class删除兄弟元素 <html lang="en"> <head> <meta ch ...