验证和交叉验证(Validation & Cross Validation)
之前在《训练集,验证集,测试集(以及为什么要使用验证集?)(Training Set, Validation Set, Test Set)》一文中已经提过对模型进行验证(评估)的几种方式。下面来回顾一下什么是模型验证的正确方式,并详细说说交叉验证的方法。
验证(Validation):把数据集随机分成训练集,验证集,测试集(互斥)。用训练集训练出模型,然后用验证集验证模型,根据情况不断调整模型,选出其中最好的模型,记录最好的模型的各项设置,然后据此再用(训练集+验证集)数据训练出一个新模型,作为最终的模型,最后用测试集评估最终的模型。
(注:这是一个完整的模型评估和模型选择过程。如果仅对单个模型进行评估,只需要前面两个步骤:用训练集训练出模型,然后用验证集验证模型。)
需要注意的是:有时我们拿到的数据是按类别排序好的,此时我们千万不能简单地把前n项作为训练集,后m项作为验证集,而是要把数据集重新洗牌,然后再随机抽取(抽取后不放回)。此外,需要尽量使得训练集和验证集的数据分布一致。比如说在分类任务中,训练集和验证集应保持相似的类别比例。这需要通过特定的采样方法来达到这一结果,这种采样方法称为分层采样(Stratified Sampling),简单来说就是如果训练集中有60%的正例,那么验证集中也需要有差不多60%的正例。分层采样也可以和交叉验证结合使用。
有些资料上把验证也算作交叉验证的一种方式,称为留出法(Holdout Validation),但在我的概念中它不应该算作交叉验证,因为数据并没有被交叉使用(既用作训练,又用作验证)。但是多次验证(多次随机划分训练集和验证集)然后取平均值则是一种交叉验证方法,称为蒙特卡洛交叉验证,下面会详细说。
下面来说说什么是交叉验证:
交叉验证(Cross Validation)也是一种模型验证技术。简单来说就是重复使用数据。除去测试集,把剩余数据进行划分,组合成多组不同的训练集和验证集,某次在训练集中出现的样本下次可能成为验证集中的样本,这就是所谓的“交叉”。最后用各次验证误差的平均值作为模型最终的验证误差。
为什么要用交叉验证?
大家知道,之前我们说的留出法(holdout)需要从数据集中抽出一部分作为验证集。如果验证集较大,那么训练集就会变得很小,如果数据集本身就不大的话,显然这样训练出来的模型就不好。如果验证集很小,那么此验证误差就不能很好地反映出泛化误差。此外,在不同的划分方式下,训练出的不同模型的验证误差波动也很大(方差大)。到底以哪次验证误差为准?谁都不知道。但是如果将这些不同划分方式下训练出来的模型的验证过程重复多次,得到的平均误差可能就是对泛化误差的一个很好的近似。
交叉验证的几种方法:
1. 留一法(Leave One Out Cross Validation,LOOCV)
假设数据集一共有m个样本,依次从数据集中选出1个样本作为验证集,其余m-1个样本作为训练集,这样进行m次单独的模型训练和验证,最后将m次验证结果取平均值,作为此模型的验证误差。
(注:这里说的数据集都是指已经把测试集划分出去的数据集,下同)
留一法的优点是结果近似无偏,这是因为几乎所有的样本都用于模型的拟合。缺点是计算量大。假如m=1000,那么就需要训练1000个模型,计算1000次验证误差。因此,当数据集很大时,计算量是巨大的,很耗费时间。除非数据特别少,一般在实际运用中我们不太用留一法。
2. K折交叉验证(K-Fold Cross Validation)
把数据集分成K份,每个子集互不相交且大小相同,依次从K份中选出1份作为验证集,其余K-1份作为训练集,这样进行K次单独的模型训练和验证,最后将K次验证结果取平均值,作为此模型的验证误差。当K=m时,就变为留一法。可见留一法是K折交叉验证的特例。
根据经验,K一般取10。(在各种真实数据集上进行实验发现,10折交叉验证在偏差和方差之间取得了最佳的平衡。)
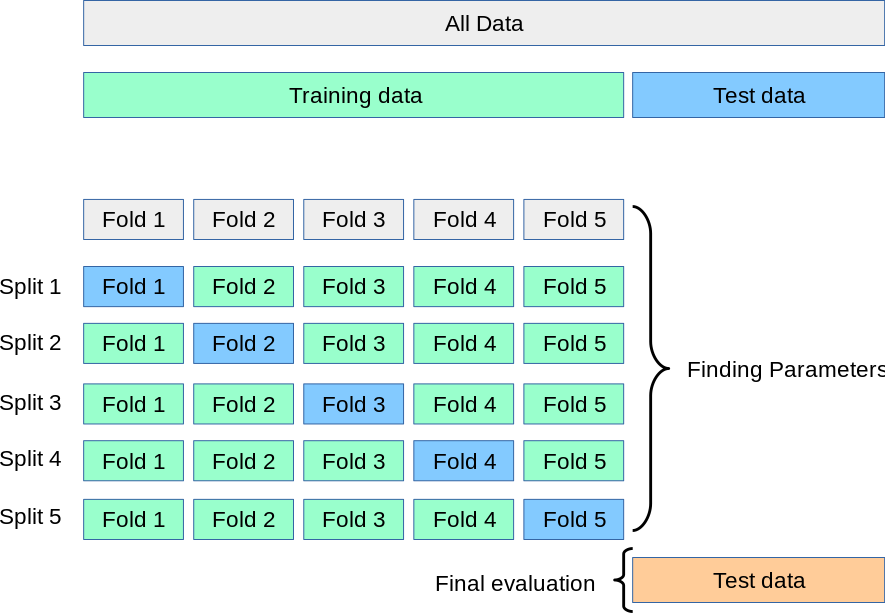
3. 多次K折交叉验证(Repeated K-Fold Cross Validation)
每次用不同的划分方式划分数据集,每次划分完后的其他步骤和K折交叉验证一样。例如:10 次 10 折交叉验证,即每次进行10次模型训练和验证,这样一共做10次,也就是总共做100次模型训练和验证,最后将结果平均。这样做的目的是让结果更精确一些。(研究发现,重复K折交叉验证可以提高模型评估的精确度,同时保持较小的偏差。)
4. 蒙特卡洛交叉验证(Monte Carlo Cross Validation)
即将留出法(holdout)进行多次。每次将数据集随机划分为训练集和验证集,这样进行多次单独的模型训练和验证,最后将这些验证结果取平均值,作为此模型的验证误差。与单次验证(holdout)相比,这种方法可以更好地衡量模型的性能。与K折交叉验证相比,这种方法能够更好地控制模型训练和验证的次数,以及训练集和验证集的比例。缺点是有些观测值可能从未被选入验证子样本,而有些观测值可能不止一次被选中。(偏差大,方差小)
总结:在数据较少的情况下,使用K折交叉验证来对模型进行评估是一个不错的选择。如果数据特别少,那么可以考虑用留一法。当数据较多时,使用留出法则非常合适。如果我们需要更精确一些的结果,则可以使用蒙特卡洛交叉验证。
此外,需要特别注意的是:如果我们要对数据进行归一化处理或进行特征选择,应该在交叉验证的循环过程中执行这些操作,而不是在划分数据之前就将这些步骤应用到整个数据集。
上面说的是对单个模型进行的交叉验证。如果要在多个不同设置的模型中进行选择,那么步骤和验证类似:首先按照不同的交叉验证方法划分数据集,训练出不同模型后,按交叉验证误差选出其中最好的模型,记录最好的模型的各项设置,然后据此再用(训练集+验证集)数据训练出一个新模型,作为最终的模型,最后用测试集评估最终的模型。
可以看出,在上述模型评估和模型选择过程中,除了对模型进行评估之外,验证和交叉验证还有另外一个作用,就是对超参数进行优化。之前我们所说的根据情况不断调整模型就是其中一种超参数优化方式,叫做试错。另外一种超参数优化方式是:列出各种不同超参数设置的算法;使用验证或交叉验证方法在训练数据上训练出这些不同的模型,然后对这些模型在验证集上的性能进行评估;之后选择其中最好的模型对应的超参数设置。这种超参数优化方式称为网格搜索。当然还有其他的超参数优化方式,请见:超参数优化方法(Hyperparameter Tuning)---试错(Babysitting),网格搜索(Grid Search),随机搜索(Random Search),贝叶斯优化(Bayesian Optimization)。
对于超参数优化,推荐用10折交叉验证。
验证和交叉验证(Validation & Cross Validation)的更多相关文章
- 使用交叉验证法(Cross Validation)进行模型评估
scikit-learn中默认使用的交叉验证法是K折叠交叉验证法(K-fold cross validation):它将数据集拆分成k个部分,再用k个数据集对模型进行训练和评分. 1.K折叠交叉验证法 ...
- sklearn交叉验证法(Cross Validation)
import numpy as np from sklearn import datasets from sklearn.cross_validation import train_test_spli ...
- 几种交叉验证(cross validation)方式的比较
模型评价的目的:通过模型评价,我们知道当前训练模型的好坏,泛化能力如何?从而知道是否可以应用在解决问题上,如果不行,那又是哪里出了问题? train_test_split 在分类问题中,我们通常通过对 ...
- 机器学习基础:(Python)训练集测试集分割与交叉验证
在上一篇关于Python中的线性回归的文章之后,我想再写一篇关于训练测试分割和交叉验证的文章.在数据科学和数据分析领域中,这两个概念经常被用作防止或最小化过度拟合的工具.我会解释当使用统计模型时,通常 ...
- 用交叉验证改善模型的预测表现-着重k重交叉验证
机器学习技术在应用之前使用“训练+检验”的模式(通常被称作”交叉验证“). 预测模型为何无法保持稳定? 让我们通过以下几幅图来理解这个问题: 此处我们试图找到尺寸(size)和价格(price)的关系 ...
- 模型构建<3>:交叉验证
交叉验证是模型比较选择的一种常用方法,本文对此进行总结梳理. 1.交叉验证的基本思想 交叉验证(cross validation)的基本思想就是重复地利用同一份数据. 2.交叉验证的作用 1)通过划分 ...
- 使用sklearn进行交叉验证
模型评估方法 假如我们有一个带标签的数据集D,我们如何选择最优的模型? 衡量模型好坏的标准是看这个模型在新的数据集上面表现的如何,也就是看它的泛化误差.因为实际的数据没有标签,所以泛化误差是不可能直接 ...
- 总结:Bias(偏差),Error(误差),Variance(方差)及CV(交叉验证)
犀利的开头 在机器学习中,我们用训练数据集去训练(学习)一个model(模型),通常的做法是定义一个Loss function(误差函数),通过将这个Loss(或者叫error)的最小化过程,来提高模 ...
- libsvm交叉验证与网格搜索(参数选择)
首先说交叉验证.交叉验证(Cross validation)是一种评估统计分析.机器学习算法对独立于训练数据的数据集的泛化能力(generalize), 能够避免过拟合问题.交叉验证一般要尽量满足:1 ...
随机推荐
- Spring-Cloud之Feign声明式调用-4
一.Feign受Retrofit.JAXRS-2.0和WebSocket影响,采用了声明式API 接口的风格,将Java Http 客户端绑定到它的内部. Feign 首要目的是将 Java Http ...
- 1.将控制器添加到 ASP.NET Core MVC 应用
模型-视图-控制器 (MVC) 体系结构模式将应用分成 3 个主要组件:模型 (M).视图 (V) 和控制器 (C). 模型(M):表示应用数据的类. 模型类使用验证逻辑来对该数据强制实施业务规则. ...
- 线程并发工具类之CountDownLatch的使用及原理分析
原文链接:http://www.studyshare.cn/blog/details/1149/1 java开发工具下载地址及安装教程大全,点这里.更多技术文章,在这里. 一.定义 CountDown ...
- 金融finaunce单词finaunce财经
金融(FINANCE或FINAUNCE)就是对现有资源进行重新整合之后,实现价值和利润的等效流通.(专业的说法是:实行从储蓄到投资的过程,狭义的可以理解为金融是动态的货币经济学.) 金融是人们在不确定 ...
- 二十六、聊聊mysql如何实现分布式锁
分布式锁的功能 分布式锁使用者位于不同的机器中,锁获取成功之后,才可以对共享资源进行操作 锁具有重入的功能:即一个使用者可以多次获取某个锁 获取锁有超时的功能:即在指定的时间内去尝试获取锁,超过了超时 ...
- JWT生成token及过期处理方案
业务场景 在前后分离场景下,越来越多的项目使用token作为接口的安全机制,APP端或者WEB端(使用VUE.REACTJS等构建)使用token与后端接口交互,以达到安全的目的.本文结合stacko ...
- cpython多进程
四 同步\异步and阻塞\非阻塞(重点) 同步: #所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不会返回.按照这个定义,其实绝大多数函数都是同步调用.但是一般而言,我们在说同步.异 ...
- CentOS7-NETWORK,SSH
SSH CentOS会自带SSH,直接启动服务, systemctl start sshd 打开配置文件 vi /etc/ssh/sshd_config 将文件中的下面2行注释去掉 PasswordA ...
- selenium+python自动化99-清空输入框clear()失效问题解决
前言 在使用selenium做UI自动化的时候,发现有些弹出窗上的输入框,输入文本后,使用clear()方法无效. 这样会导致再次输入时,字符串不是清空后输入,而是跟着后面输入一长串,导致结果不准. ...
- 数组,字符串,json互相转换
数组转字符串 var arr = [1,2,3,4,'巴德','merge']; var str = arr.join(','); console.log(str); // 1,2,3,4,巴德,me ...