python爬虫之requests库
在python爬虫中,要想获取url的原网页,就要用到众所周知的强大好用的requests库,在2018年python文档年度总结中,requests库使用率排行第一,接下来就开始简单的使用requests库吧.
配置好python环境后,python配置大家应该都会,至于path路径下载安装界面右下角就有add to path 很简便,这里主要是window环境下的使用,至于Linux环境,我暂时还没有深入了解,用yum install或者 wget命令都是可行的.
在window环境下,推荐是用pip进行安装,因为便捷而且不用考虑文件的解压路径:
pip install requests
首先requests有文档说明,requests文档 多观察库文档,有利于我们了解该库创建者的意图,现在可以尝试使用requests库获取一个网页的源代码了:代码如下
import requests url='https://www.cnblogs.com/hxms/p/10412179.html' response=requests.get(url) print(respones.text)
requests code
但是为了更好获取源代码,还需要对该代码进行一定的优化,比如是否考虑statue_code==200,响应码是否正常,正常还可以请求该网页,否则返回错误原因,代码如下:
import requests
def get_page():
try:
url="https://www.cnblogs.com/hxms/p/10412179.html"
response=requests.get(url)
if response.status_code==200:
return response.text
except requests.ConnectionError:
return None
get_page()
requests Codes
运用了get_page的函数,对requests的方法进行优化,最后还可以添加main函数进行打印输出
def main():
data=get_page()
print(data)
if __name__ == "__main__":
main()
进行如下
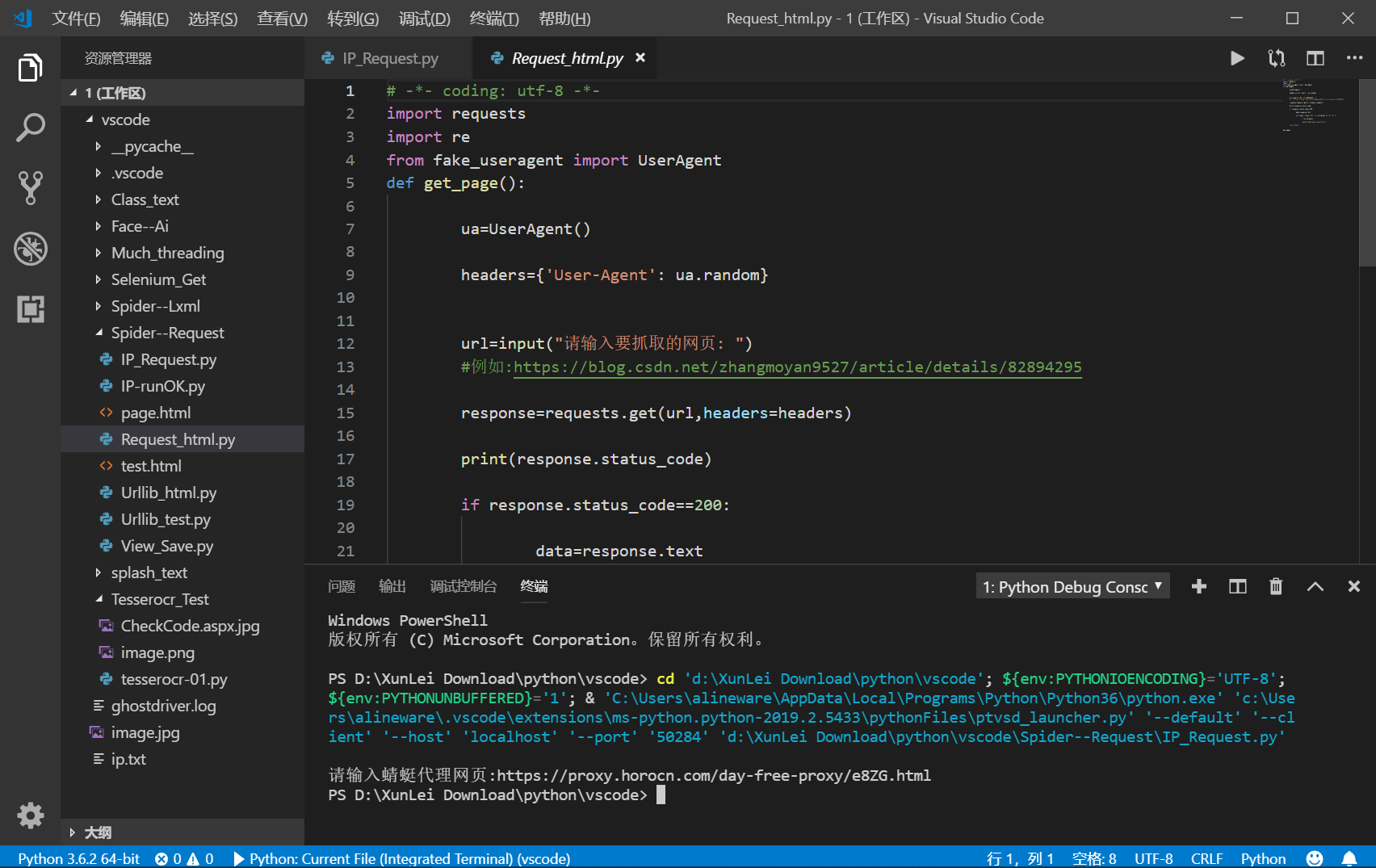
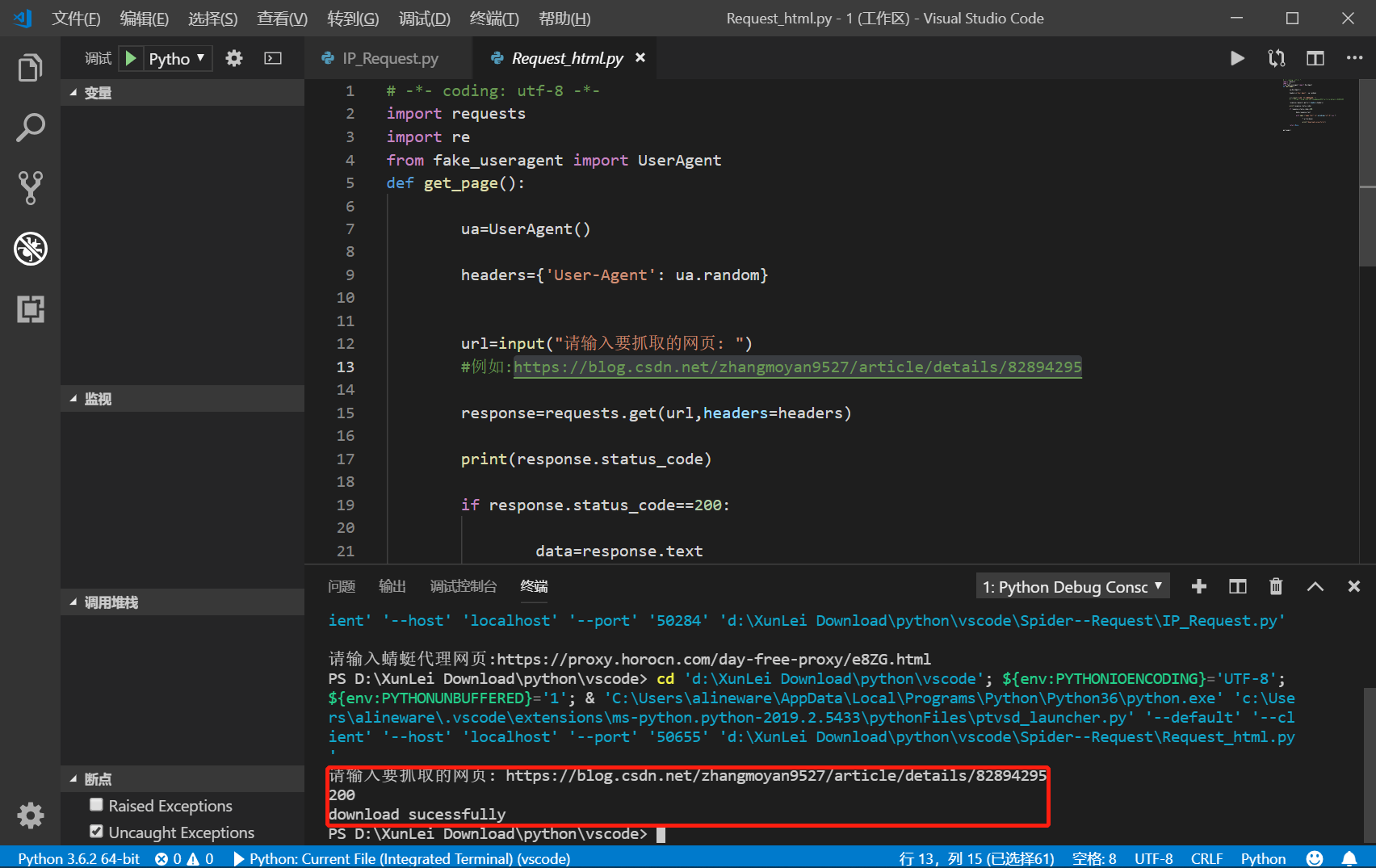

这样就可以简单的获取网页的源代码了,但是在现实过程中,网页是经过js渲染的,即可以理解为该HTML只是个空体,只是引用了某个js文本,这样就会造成requests请求的源代码出现错误,造成后期抓不到想要的数据,不过没有关系,F12提供了强大的抓包工具,无论是Ajax或者是直接js渲染的网页,我们都有相应的解决方法,例如利用selenium库进行自动化运行,抑或是xhr文件里的json字典格式化存储,都是可以解决这些问题的.
关于requests库还有许多参数没用上,比如proxies(代理,抓取数量过大时会导致该请求网址对我们的IP进行封禁,导致304请求失败),headers(头请求),现在许多网页会设置反爬虫设置,如果你不加请求头的话,服务器是不会返回任何信息给你的,但是requests库为你提供了伪装浏览器的方法,运用User-Agent;host等运用字典添加进去,更容易获取我们想要的信息.更多方法可以参考上面的requests文档.
python爬虫之requests库的更多相关文章
- Python爬虫之requests库介绍(一)
一:Requests: 让 HTTP 服务人类 虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 ...
- Python爬虫:requests 库详解,cookie操作与实战
原文 第三方库 requests是基于urllib编写的.比urllib库强大,非常适合爬虫的编写. 安装: pip install requests 简单的爬百度首页的例子: response.te ...
- Python爬虫之requests库的使用
requests库 虽然Python的标准库中 urllib模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests宣传是 "HTTP for ...
- 【Python爬虫】Requests库的基本使用
Requests库的基本使用 阅读目录 基本的GET请求 带参数的GET请求 解析Json 获取二进制数据 添加headers 基本的POST请求 response属性 文件上传 获取cookie 会 ...
- python爬虫(1)requests库
在pycharm中安装requests库的一种方法 首先找到设置 搜索然后安装,蓝色代表已经安装 requests库中的get请求 与HTTP协议相对应,requests库也有七种请求方式. 获取ur ...
- python爬虫之requests库介绍(二)
一.requests基于cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们 ...
- Python爬虫之Requests库的基本使用
import requests response = requests.get('http://www.baidu.com/') print(type(response)) print(respons ...
- Python爬虫系列-Requests库详解
Requests基于urllib,比urllib更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 实例引入 import requests response = requests.get( ...
- python下载安装requests库
一.python下载安装requests库 1.到git下载源码zip源码https://github.com/requests/requests 2.解压到python目录下: 3.“win+R”进 ...
随机推荐
- ASP.Net GridView 基础
SP.NET 在开发过程中经常使用的微软提供的服务器控件(GridView),但在开发中很少使用界面化来操作.导致了有点不太会使用界面化操作了,还有就是一些不经常使用的属性也没什么印象了,在网上找了好 ...
- PAT——1025. 反转链表
给定一个常数K以及一个单链表L,请编写程序将L中每K个结点反转.例如:给定L为1→2→3→4→5→6,K为3,则输出应该为3→2→1→6→5→4:如果K为4,则输出应该为4→3→2→1→5→6,即最后 ...
- [LuoguP1360][USACP07MAR]黄金阵容均衡
[LuoguP1360][USACP07MAR]黄金阵容均衡(Link) 每天会增加一个数\(A\),将\(A\)二进制分解为\(a[i]\),对于每一个\(i\)都增加\(a[i]\),如果一段时间 ...
- 结构之美——优先队列基本结构(四)——二叉堆、d堆、左式堆、斜堆
实现优先队列结构主要是通过堆完成,主要有:二叉堆.d堆.左式堆.斜堆.二项堆.斐波那契堆.pairing 堆等. 1. 二叉堆 1.1. 定义 完全二叉树,根最小. 存储时使用层序. 1.2. 操作 ...
- C语言入门编程思维引导
编程思维引导: C语言中 include<stdio.h> 称之为导包,导入写好的函数库,多个则依次写 #define N 3 意思是将N这个字母定义为数字3 当使用的时候就直接用 i ...
- weblogic.xml中的虚拟目录的配置
项目中的Ueditor富文本编辑器中上传图片后要能够预览. 如下图: 实现: 配置weblogic的虚拟目录:项目名称是test 如图: 这个表示:所有的访问/uefile/*的路径都会被转发到服务器 ...
- QueryRunner cannot be resolved to a type:关于包不能正常导入的问题
在操作一个功能模块的时候,出现一个问题: 我原则是按着项目指导一步一步走的,但却出现, QueryRunner cannot be resolved to a type,这个问题应该属于Xxx can ...
- Extjs6 怎么重写框架的类
创建一个覆写(override)类的推荐方法如下: Ext.define('MyApp.overrides.panel.Panel', { override: 'Ext.panel.Panel', c ...
- CH4402 小Z的袜子(莫队)
描述 作为一个生活散漫的人,小Z每天早上都要耗费很久从一堆五颜六色的袜子中找出一双来穿.终于有一天,小Z再也无法忍受这恼人的找袜子过程,于是他决定听天由命-- 具体来说,小Z把这N只袜子从1到N编号, ...
- Redis 单机和多实例部署
作者:北京运维 1. 安装环境说明 OS 版本:CentOS 7.5.1804 Redis 版本:redis-3.2.12 Redis 下载页面:http://download.redis.io/re ...