为树莓派添加一个强实时性前端[原创cnblogs.com/helesheng]

树莓派是最近流行嵌入式平台,其自由的开源特性以及低廉的价格,吸引了来 自全球的大量极客和计算机大咖的关注。来自各大树莓派社区的幕后英雄,无私地在这个开源硬件平台上做了大量的工作,将其打造成了世界上通用性最好,也最自由的计算机学习平台之一。我本人感兴趣的学习主题是Linux操作系统和Python编程,在流连于各大树莓派社区向各位大神学习的过程中感觉获益良多。结合自己擅长的实时信号处理工作,也做了一些小小的尝试。不能说做了什么独创性工作,但愿意分享给各位后来者。以下原创内容欢迎网友转载,但请注明出处:cnblogs.com/helesheng
一、树莓派Raspbian系统的实时性
Raspbian是树莓派最常用的Debian Linux操作系统,也是树莓派官方推荐的系统。这个系统集成了Debian系统的良好看操作性和易用性,具有非常成熟的开源支持。但Linux系统内核并非实时操作系统,在对系统硬件进行操作时很难保证系统的实时性。
用以下shell命令安装Python GPIO,对其实时性进行测试。
sudo apt-get install Python-dev
sudo apt-get install Python-rpi.gpio
树莓派安装Python GPIO
测试仪器是逻辑分析仪,简单连接BCM模式下的#17号引脚如下图所示。

图1 用逻辑分析仪分析Raspbian的实时性
注:如果不清楚树莓派GPIO的引脚位置可以通过在Linux终端输入指令:gpio readall 来查询BCM和wirePi模式下引脚的位置。
编辑以下简单Python测试脚本:
#coding: utf-8
import RPi.GPIO as GPIO
import time
GPIO.setmode(GPIO.BCM) #引脚采用BCM编码
GPIO.setup(17, GPIO.OUT) #将对应的GPIO配置为输出
DLY_TM = 0.001#延迟时间单位为秒
try:
while True:
GPIO.output(17,GPIO.HIGH)
time.sleep(DLY_TM)
GPIO.output(17,GPIO.LOW)
time.sleep(DLY_TM)
except KeyboardInterrupt:
print("It is over!")
GPIO.cleanup()
树莓派Python实时性测试代码
用逻辑分析仪测试#17引脚输出的波形如左下图所示。
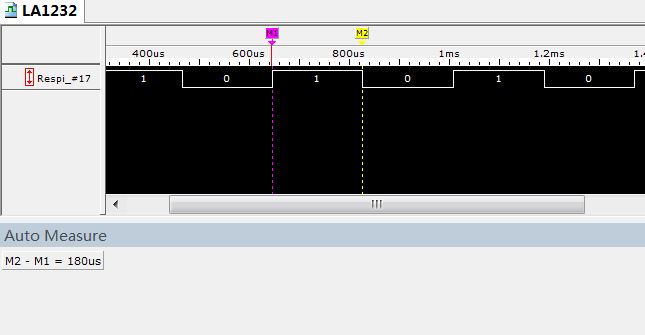
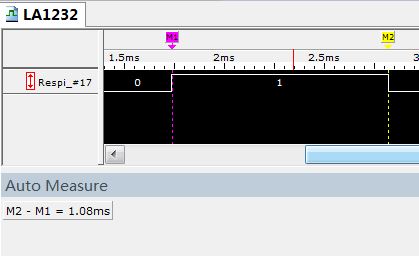
图2a Python代码输出的1ms延时波形 图2b Python代码输出的100us延时波形
由上图可知,实际的延迟时间为1.08ms(紫色标签M1和黄色标签M2之间的时间差),实时误差约为80us。
将上面代码中的延迟时间DLY_TM改为0.0001(100us),测试结果如下图。可见实际的延迟时间为180us,实时误差仍为约为80us。
这个80us的延时误差应该是由Linux内核调度器和Python解释器共同造成的,很难进一步降低。且上述测试是在树莓派空载情况下进行的——当Linux内核调度更多线程时这个延迟时间不但将进一步增加,而且可能变成一个随机时间。
80us数量级的实时误差,对于控制自动小车、3D打印机这类应用已经绰绰有余,但对于需要精确控制时间的任务显然是不够的。
由于Python具有非常强大的数字信号处理能力,但树莓派不含有A/D转换器,我决定为树莓派添加一个强实时性的高速A/D,D/A转换装置,在树莓派上实现Python实时数字信号处理
根据孔径(Aperture Jitter)抖动理论,两次采样间时间间隔的随机变化,将造成A/D和D/A转换信噪比(SNR)和有效分辨率(ENOB)的降低,这种采样间隔之间的随机变化称为孔径抖动。这里计划为树莓派设计一个转换率为1MSPS,包含和A/D和D/A转换功能,辨率为12bits的模拟前端。根据孔径抖动和信噪比之间的计算公式[1]:
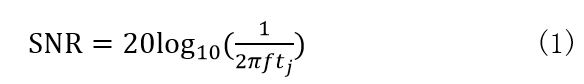
其中tj是孔径抖动时间。根据上式得到采样频率、信噪比和要求的孔径抖动之间的关系图[2]。
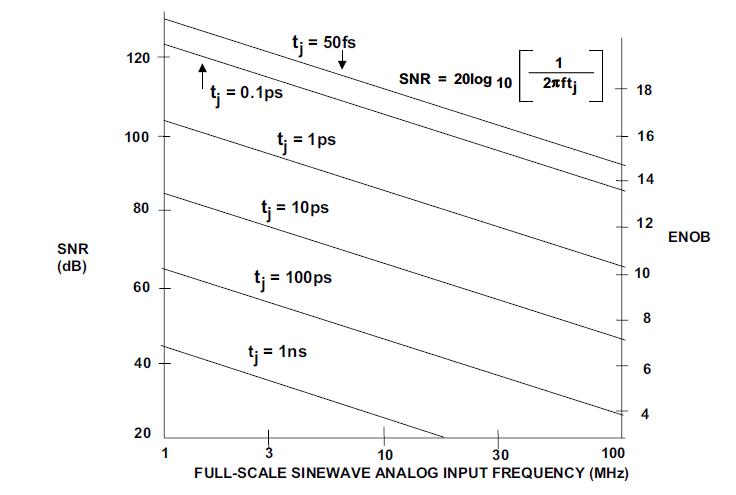
图3 采样频率、信噪比和孔径抖动的关系
由上图可知为达到1MSPS下10~12bits的有效分辨率ENOB(或60Db以上的信噪比),应将孔径抖动时间控制在100ps以下,远远小于树莓派(运行Linux系统条件下)能够提供的80us的时间分辨率,为此必须采用实时性更强的模拟前端控制器。
二、总体设计思路
常见的实时控制方案有MCU和FPGA两种,FPGA实时性最好,但开发难度较大,成本也高,与树莓派的开源和低成本精神不完全吻合,比较合理的方案是用MCU实现。但如果采用传统的MCU定时器软件中断法来实现转换定时控制,则定时精度受中断服务程序入口的影响,孔径抖动在MCU指令周期数量级。以72MHz的STM32F103系列为例,定时器中断法产生的孔径抖动在1/72MHz≈13.9ns数量级,远高于12bits@1MSPS的A/D和D/A转换要求。但STM32为它的ADC模块提供了强有力的DMA支持,DMA对转换结果的转存不受指令影响,可以实现极佳的采样定时控制,将孔径抖动降低到1ns以下。
采用STM32作为实时模拟前端的控制器,还要实现树莓派和STM32之间的数据交互——树莓派发送数据给STM32来进行D/A转换;接收STM32进行A/D转换的结果。树莓派扩展接口提供了GPIO、SPI、I2C(SMBUS)等几种接口,为降低传输延迟我采用了速度最快的SPI接口来连接STM32实时前端。传输过程中树莓派作为SPI主机,用户通过用户界面驱动SPI口发起通信;STM32作为SPI从机被动进行通信,以上传A/D转换结果和接受D/A转换数据。
当树莓派不发起通信的时候,STM32通过DMA1通道1不停地将转换结果写入其内部RAM中的A/D转换循环缓冲区中,同时不断地将D/A循环缓冲区中的数据从D/A转换器中输出。当树莓派接收到用户命令进行通信时,首先通过GPIO通知STM32。STM32在收到命令后,找到A/D缓冲区最后放入循环队列中的数据,并将整个队列中的数据按时间顺序搬运到发送缓冲区,再通过GPIO告诉树莓派“可以开始通信了”。树莓派在收到STM32发来的确认信息后发起连续的SPI通信,一方面通过MOSI引脚将希望D/A转换器转换的数据队列发送给STM32,另一方面从MISO口接收STM32发送缓冲区中的A/D转换数据。其结构框图如下图所示。
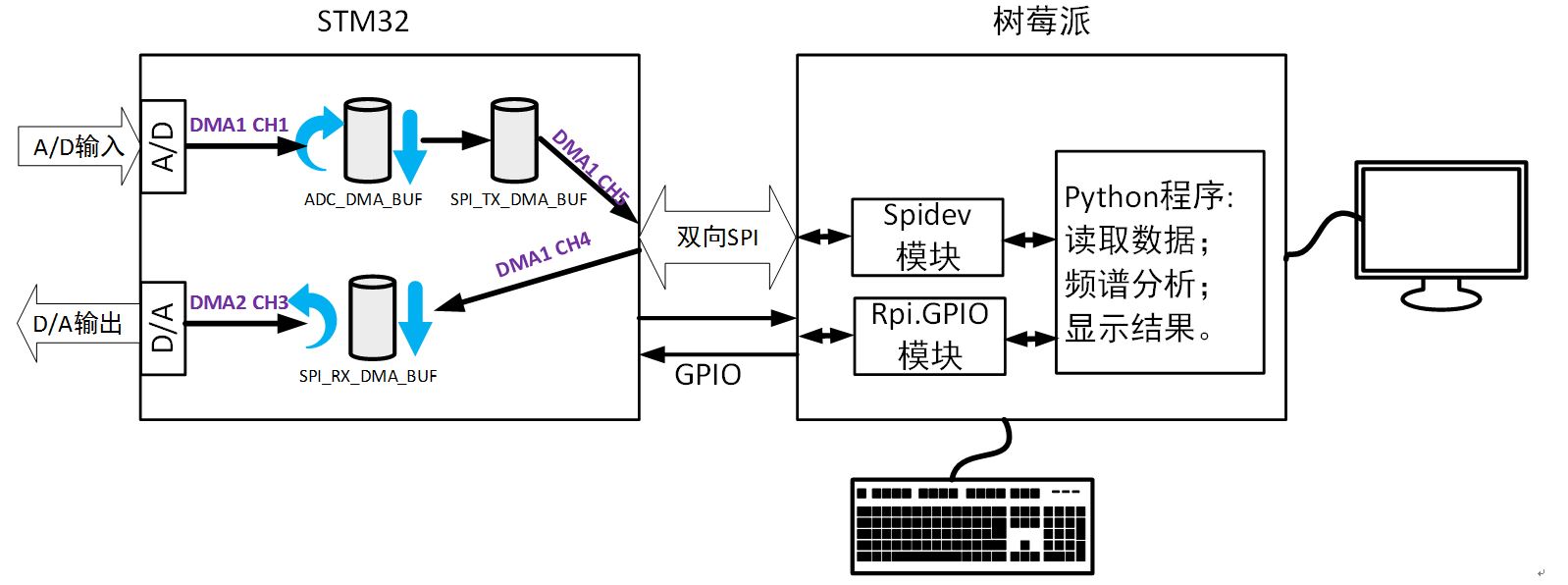
图4 树莓派和实时性前端功的能框图
根据上述思路,我设计了下图左侧所示的PCB:模拟信号从最左侧的单排针接插件进入;STM32的SPI和GPIO接口则通过下图中部的标准的树莓派扩展接口连接到树莓派上。其中STM32使用了集成A/D和D/A转换器的Cortex-M3系列芯片STM32F103RC。

图5 树莓派和实时性前端功的实物图
三、在树莓派上用Python NumPy和Matplotlib编写信号处理算法
NumPy和Matplotlib是Python上著名的数值计算和图形扩展库,提供了丰富而强大的信号处理和显示功能。其使用方法类似常用的Matlab,但幸运的是在开源的Linux和Python世界里,它们都是免费的!在树莓派上没有安装它们的小伙伴们可以用以下指令安装。
sudo apt-get install python-numpy python-scipy python-matplotlib
树莓派上安装matplotlib很可能由于缺少Cario图形库无法运行,如果出现这种情况请执行以下指令。
sudo apt-get install python-gi-cairo
在Python脚本中如下方式导入上述两个模块,就可以在树莓派上开心的玩耍数字信号处理了。
import numpy as np
import matplotlib.pyplot as plt
1、产生D/A输出所需的信号
利用NumPy产生正弦信号的Python脚本如下:
index = np.arange(D_LEN)
s = 1000*np.sin(2*np.pi*index*2/D_LEN) + 2048;
熟悉Matlab的小伙伴看起来是不是非常亲切。还可以为D/A产生的信号增加几个高次谐波,将第二句改为:
s = 1000*np.sin(2*np.pi*index*2/D_LEN) + 200*np.sin(2*np.pi*index*20/D_LEN) + 40*np.sin(2*np.pi*index*50/D_LEN) +2048
最后为方便Python和实时信号前端的数据传输,将s强制类型转换为16位无符号整型:
s=s.astype(np.uint16)#将numpy对象s强制类型转换为16位无符号整形
2、对A/D采集到的数据进行简单处理
为了演示NumPy和Matplotlib的信号处理和绘图功能,我对A/D采集得到的数据进行了简单的处理。
1)绘制采集到数据的波形,Python脚本代码如下。
plt.subplot(211)
delta_t = 1/Sample_rate#两点之间的时间间隔
t_scale=np.linspace(0,delta_t*D_LEN,num=D_LEN)*(10**6)
#计算x轴,也就是时间轴的数值,最后乘与10**6是将时间单位折算为us
plt.plot(t_scale,res_float, '-r')
plt.grid(True)
plt.title("Time Domain WaveForm")
plt.xlabel("t(us)")
plt.ylabel("A(V)")
plt.show()
Python-Matplotlib绘制时域波形
其中,Sample_rate是A/D转换的采样率;t_scale是一个NumPy数组,内容是显示的X轴数值;res_float也是一个数组,内容是折算为电压值的A/D转换结果。subplot()方法将打开一个2行1列的绘图窗口,这个时域波形被绘制在第1行第1列的波形图中。
2)计算和绘制FFT产生的幅频特性
为减少数据时域截断造成的能量泄露,先对数据进行加窗处理,再将其显示在上面开启的绘图窗口的第2行的波形图中。代码如下:
sfa = np.abs(sfc)
sfa_half = sfa[0:int(D_LEN/2)]#由于FFT结果的对称性,只需要取一半数据。
sfa_lg_half = np.log10(sfa_half)*20
sfa_lg_half = sfa_lg_half - np.max(sfa_lg_half)#将最高能量点折算为0dB
plt.subplot(212)
delta_f = Sample_rate/(D_LEN) #FFT结果两点之间的频率间隔
f_scale=np.linspace(0,delta_f*D_LEN/2,num=D_LEN/2)/1000
#计算x轴,也就是频率轴数值,最后除以1000,表示将频率折算为KHz
plt.plot(f_scale,sfa_lg_half,'-b')
plt.title("Frequency Domain WaveForm")
plt.xlabel("f(KHz)")
plt.ylabel("A(dB)")
plt.grid(True)
plt.show()
Python NumPy MatPlotlib绘制频域波形
其中sw是经过加窗,且去除直流分量后的信号;D_LEN是以字节为单位的数据传输的长度,每个采样点对应两个字节,因此信号的长度为D_LEN/2;f_scale是绘图后X轴,也就是频率轴的数值;NumPy中的fft()方法输出快速傅里叶变换的结果,是个复数数组,sfa_lg是频率折算为dB后的数值。
四、STM32构成的实时性前端
如图4所示,由STM32构成的实现前端控制器主要完成以下工作:
- 通过DMA1的通道1(CH1)控制ADC完成固定采样率的A/D采集,并将数据存入到循环缓冲区ADC_DMA_BUF。
- 通过DMA1的通道4(CH4)和5(CH5)控制SPI口和树莓派通信:接收树莓派发送的D/A数据到缓冲区SPI_RX_DMA_BUF;向树莓派发送缓冲区SPI_TX_DMA_BUF中的A/D转换数据。
另外,为了在树莓派人机交互界面的同步下,有序的完成:采集、数据搬运和传输工作,实时前端要在两对GPIO连接:SHK_IN(树莓派输入/STM32输出)和SHK_OUT(树莓派输出/STM32输入)的同步下工作。
1、 由DMA1 CH1控制的A/D转换
A/D采集在STM32复位后不断的循环进行,DMA1的CH1被配置为循环模式,数据将采用循环队列的数据结构存储到宽度为半字(HalfWord,16bits)的ADC_DMA_BUF中。配置代码如下所示:
DMA_DeInit(DMA1_Channel1);
DMA_InitStructure.DMA_PeripheralBaseAddr = ADC1_DR_Address;//传输的源头地址
DMA_InitStructure.DMA_MemoryBaseAddr = (uint32_t)&ADC_DMA_BUF;//目标地址
DMA_InitStructure.DMA_DIR = DMA_DIR_PeripheralSRC; //外设作源头
DMA_InitStructure.DMA_BufferSize = (BUFF_SIZE - HEAD_SIZE)/; //数据长度BUFF_SIZE
DMA_InitStructure.DMA_PeripheralInc = DMA_PeripheralInc_Disable;//外设地址寄存器不递增
DMA_InitStructure.DMA_MemoryInc = DMA_MemoryInc_Enable;//内存地址递增
DMA_InitStructure.DMA_PeripheralDataSize = DMA_PeripheralDataSize_HalfWord; //外设传输以半字为单位
DMA_InitStructure.DMA_MemoryDataSize = DMA_MemoryDataSize_HalfWord;//内存以半字为单位
DMA_InitStructure.DMA_Mode = DMA_Mode_Circular;//循环模式
DMA_InitStructure.DMA_Priority = DMA_Priority_VeryHigh;//4优先级之一的
DMA_InitStructure.DMA_M2M = DMA_M2M_Disable; //非内存到内存
DMA_Init(DMA1_Channel1,&DMA_InitStructure);//根据以上参数初始化DMA_InitStructure
DMA_Cmd(DMA1_Channel1, ENABLE);//使能DMA1
控制A/D转换的DMA1CH1初始化
其中BUFF_SIZE是以字节为单位的传输缓冲区长度,可设为1024。HEAD_SIZE是以字节为单位传输数据包头长度,可设为24。采集缓冲区ADC_DMA_BUF的长度就是(BUFF_SIZE-HEAD_SIZE)/2。
A/D转换的配置代码如下所示:
ADC_InitStructure.ADC_Mode = ADC_Mode_Independent;//ADC1工作在独立模式
ADC_InitStructure.ADC_ScanConvMode = ENABLE;//模数转换工作在扫描模式
ADC_InitStructure.ADC_ContinuousConvMode = ENABLE;//模数转换工作在连续模式
ADC_InitStructure.ADC_ExternalTrigConv = ADC_ExternalTrigConv_None;
ADC_InitStructure.ADC_DataAlign = ADC_DataAlign_Right;//ADC数据右对齐
ADC_InitStructure.ADC_NbrOfChannel = ;//转换的ADC通道的数目为1
ADC_Init(ADC1, &ADC_InitStructure);
ADC_RegularChannelConfig(ADC1, ADC_Channel_0, , ADC_SampleTime_1Cycles5); //ADC1通道2转换顺序为1,
RCC_ADCCLKConfig(RCC_PCLK2_Div4); //设置ADC分频因子4,56MHz/4=14 MHz
ADC_DMACmd(ADC1, ENABLE); //使能ADC1的DMA传输方式
ADC_Cmd(ADC1, ENABLE); //使能ADC1
A/D的DMA配置
上述代码配置STM32的ADC的采样时间为1.5个ADC时钟周期,加上一次完整的逐次逼近过程所需的12.5个周期,共14个时钟周期。ADC时钟为外设时钟56MHz的四分之一,刚好14MHz,这样进行一次完整A/D转换的时间刚好为1us,即实现了1MSPS的采样率。ADC模块被配置为连续扫描通道1,并在转换完成后直接触发一次DMA1的数据传输。这样整个采集和存储工作由纯硬件来完成,无需软件干预,严格的控制了A/D转换的孔径抖动时间,有效的提升了A/D转换的实时性。
2、 由DMA2的CH3控制的D/A转换
DMA2的CH3也被配置为循环模式,程序运行过程中会不断的将SPI_RX_DMA_BUF中的数据发送到D/A转换器中,从而形成连续的波形。而DMA2 CH3向DAC发送数据的时间间隔就是两次D/A转换的间隔,所以DMA2的CH3需由额外的定时器(TMR)来触发传输。DMA2 CH3的配置代码如下所示:
DMA_DeInit(DMA2_Channel3); //根据默认设置初始化DMA2
DMA_InitStructure.DMA_PeripheralBaseAddr = DAC_DHR12R1_Address;//外设地址
DMA_InitStructure.DMA_MemoryBaseAddr = (u32)&SPI_RX_DMA_BUF; //内存地址
DMA_InitStructure.DMA_DIR = DMA_DIR_PeripheralDST;
//外设DAC作为数据传输的目的地
DMA_InitStructure.DMA_BufferSize = (BUFF_SIZE-HEAD_SIZE)/;
//数据长度为BUFF_SIZE
DMA_InitStructure.DMA_PeripheralInc = DMA_PeripheralInc_Disable;//外设地址寄存器不递增
DMA_InitStructure.DMA_MemoryInc = DMA_MemoryInc_Enable;//内存地址递增
DMA_InitStructure.DMA_PeripheralDataSize = DMA_PeripheralDataSize_HalfWord;
//外设传输以半字为单位
DMA_InitStructure.DMA_MemoryDataSize = DMA_MemoryDataSize_HalfWord;
//内存以半字为单位
DMA_InitStructure.DMA_Mode = DMA_Mode_Circular;//循环模式
DMA_InitStructure.DMA_Priority = DMA_Priority_High;//4优先级之一的(高优先级)
DMA_InitStructure.DMA_M2M = DMA_M2M_Disable;//非内存到内存
DMA_Init(DMA2_Channel3, &DMA_InitStructure);//根据以上参数初始化
DMA_Cmd(DMA2_Channel3, ENABLE);//使能DMA2的通道3
控制D/A转换的DMA2CH3初始化代码
触发DMA2的定时器为TMR2,其初始化代码如下所示:
TIM_PrescalerConfig(TIM2,-,TIM_PSCReloadMode_Update);//设置TIM2预分频值
TIM_SetAutoreload(TIM2, -);//设置定时器计数器值
TIM_SelectOutputTrigger(TIM2, TIM_TRGOSource_Update);
//TIM2触发模式选择,这里为定时器2溢出更新触发
DAC_InitStructure.DAC_Trigger = DAC_Trigger_T2_TRGO;//定时器2触发
DAC_InitStructure.DAC_WaveGeneration = DAC_WaveGeneration_None;//无波形产生
DAC_InitStructure.DAC_OutputBuffer = DAC_OutputBuffer_Disable;//DAC_OutputBuffer_Enable;//不使能输出缓存
DAC_Init(DAC_Channel_1, &DAC_InitStructure);//根据以上参数初始化DAC结构体
DAC_Cmd(DAC_Channel_1, ENABLE);// 使能DAC通道1
DAC_DMACmd(DAC_Channel_1, ENABLE);//使能DAC通道1的DMA
TIM_Cmd(TIM2, ENABLE);//使能定时器2
触发DMA2的TMR2配置
TMR2的定时的溢出计数值被设置为7*8=56,在56MHz主频下将产生1MHz的溢出率,即D/A转换器的刷新率也是1MSPS。如前所述,如果采用在TMR2中断中由软件来刷新DAC,将会提高造成D/A输出间隔的孔径抖动。因此这里选择了通过定时器硬件触发DMA传输的方式来实现D/A数据的刷新的方式,大大提高了D/A输出波形的信噪比。
3、 由DMA1的CH4和CH5控制的SPI数据交互
A/D和D/A转换由硬件控制,并自动定时进行的,但与树莓派的数据交互却是由树莓派发起的,与STM32中的程序运行不同步。如图4所示,双方在握手信号SHK_IN和SHK_OUT的控制下,通过SPI口的双向交互数据。其中树莓派发起通信,作为SPI主机;STM32作为从机。由于从机无法预知主机何时发起通信,因此也通过DMA来实现自动收发数据,其中DMA1 CH4负责接收D/A转换数据,DMA1 CH5负责发送A/D数据。DMA1 CH4和CH5的配置代码如下所示:
RCC_AHBPeriphClockCmd(RCC_AHBPeriph_DMA1, ENABLE);//使能DMA1时钟
DMA_DeInit(DMA1_Channel4);//DMA1的通道4是SPI2的接收通道
DMA_InitStructure.DMA_PeripheralBaseAddr = ((uint32_t)(SPI2_BASE+0x0C));
//外设地址,SPI1的基地址加上SPI_DR的偏移地址0X0C
DMA_InitStructure.DMA_MemoryBaseAddr = (uint32_t)&SPI_RX_DMA_BUF;
//存储器地址
DMA_InitStructure.DMA_DIR = DMA_DIR_PeripheralSRC; //外设作为数据源
DMA_InitStructure.DMA_BufferSize = BUFF_SIZE;//数据长BUFF_SIZE
DMA_InitStructure.DMA_PeripheralInc = DMA_PeripheralInc_Disable;
//外设地址寄存器不递增
DMA_InitStructure.DMA_MemoryInc = DMA_MemoryInc_Enable;//内存地址递增
DMA_InitStructure.DMA_PeripheralDataSize = DMA_PeripheralDataSize_Byte;
//外设传输以字节为单位
DMA_InitStructure.DMA_MemoryDataSize = DMA_MemoryDataSize_Byte;
//内存以字节为单位
DMA_InitStructure.DMA_Mode = DMA_Mode_Circular;//循环模式
DMA_InitStructure.DMA_Priority = DMA_Priority_Medium;//4优先级之一的(高优先)
DMA_InitStructure.DMA_M2M = DMA_M2M_Disable; //非内存到内存
DMA_Init(DMA1_Channel4, &DMA_InitStructure);
DMA_Cmd(DMA1_Channel4, ENABLE);//使能DMA1通道2
//DMA1的通道5配置为spi2输出
DMA_DeInit(DMA1_Channel5);//DMA1的通道5是SPI2的发送通道
DMA_InitStructure.DMA_PeripheralBaseAddr = ((uint32_t)(SPI2_BASE+0x0C));
//外设地址,SPI1的基地址加上SPI_DR的偏移地址0X0C
DMA_InitStructure.DMA_MemoryBaseAddr = (uint32_t)&SPI_TX_DMA_BUF;
//存储器地址
DMA_InitStructure.DMA_DIR = DMA_DIR_PeripheralDST; //外设作为数据目的
DMA_InitStructure.DMA_BufferSize = BUFF_SIZE;//数据长BUFF_SIZE
DMA_InitStructure.DMA_PeripheralInc = DMA_PeripheralInc_Disable;
//外设地址寄存器不递增
DMA_InitStructure.DMA_MemoryInc = DMA_MemoryInc_Enable;//内存地址递增
DMA_InitStructure.DMA_PeripheralDataSize = DMA_PeripheralDataSize_Byte;
//外设传输以字节为单位
DMA_InitStructure.DMA_MemoryDataSize = DMA_MemoryDataSize_Byte;
//内存以字节为单位
DMA_InitStructure.DMA_Mode = DMA_Mode_Circular;//循环模式
DMA_InitStructure.DMA_Priority = DMA_Priority_High;//4优先级之一的
DMA_InitStructure.DMA_M2M = DMA_M2M_Disable; //非内存到内存
DMA_Init(DMA1_Channel5, &DMA_InitStructure);
DMA_Cmd(DMA1_Channel5, ENABLE);//使能DMA1通道3
控制SPI收发数据的DMA1CH4和CH5的配置
由于A/D转换数据在不断的刷新中,树莓派发起通信的时A/D转换数据可能存放到了缓冲区ADC_DMA_BUF的任意位置。如果直接将ADC_DMA_BUF中的数据发送给树莓派,则树莓派得到的将是一个首地址指针错误的循环队列,无法解读为正确的数据。因此,我采用了图4所示的双缓冲数据结构,树莓派发起通信时首先读取DMA1 CH1的当前位置,再根据这个首地址指针将ADC_DMA_BUF中的数据按顺序重新搬运到发送缓冲区SPI_TX_DMA_BUF中。然后再启动DMA2 CH4和CH5的SPI通信,将数据发送给树莓派。控制ADC_DMA_BUF和SPI_TX_DMA_BUF数据结构调整的代码如下所示:
Curr_point = (BUFF_SIZE - HEAD_SIZE)/-DMA_GetCurrDataCounter(DMA1_Channel1);
//读取当前DMA正在操作的数据点,函数DMA_GetCurrDataCounter返回的是剩余待传输的数据,所以要求当前地址应该用缓冲区的长度减去这个值
Curr_point = Curr_point*; //每次DMA存储两个字节,变换为字节地址
j=;
for(i=Curr_point;i<(BUFF_SIZE - HEAD_SIZE);i++){
SPI_TX_DMA_BUF[j] = *((char*)ADC_DMA_BUF+i);
j++;}
for(i=;i<Curr_point;i++){
SPI_TX_DMA_BUF[j] = *((char*)ADC_DMA_BUF+i);
j++;}
A/D缓冲区的数据结构调整
虽然D/A转换也是不断循环进行的,但对于D/A数据缓冲区的刷新却没有A/D数据缓冲区的问题:树莓派可以在任何时刻整体刷新D/A缓冲区,输出波形将在一个DMA周期后输出正确的新数据波形。
五、用树莓派的SPI和GPIO控制实时前端
为实现树莓派和实时前端的数据交互,需要使用树莓派扩展接口中的两个GPIO口和一个SPI设备。
1、 用Python控制GPIO
GPIO的安装使用较简单,如本文第一部分所述在Linux的shell命令行中安装控制GPIO模块后就可以在Python脚本中导入GPIO模块来使用。本程序只用到3个GPIO,分别用于读取按键和与STM32的握手信号,它们的初始化代码如下所示:
GPIO.setmode(GPIO.BCM)#将GPIO的引脚编号设置为BCM模式
RP_SHK_IN = 6 #树莓派的输入握手引脚,连接RT_STM32的输出握手引脚
RP_SHK_OUT = 5 #树莓派的输出握手引脚,连接RT_STM32的输入握手引脚
KEY_C = 25 #树莓派的按键输入引脚,用于接收数据交互的启动信号
GPIO.setup(RP_SHK_IN, GPIO.IN, pull_up_down = GPIO.PUD_UP)
GPIO.setup(RP_SHK_OUT, GPIO.OUT)
GPIO.setup(KEY_C, GPIO.IN,pull_up_down=GPIO.PUD_UP)
GPIO.output(RP_SHK_OUT,True)
与前端握手的GPIO配置
其中需要注意的是GPIO.setpu()方法的第三个参数:pull_up_down = GPIO.PUD_UP,这个参数用于将这个GPIO配置为弱上拉模式,以保证在没有输入信号的时候,这个GPIO是高电平。接下来只需要通过GPIO.input()方法来读取GPIO状态,和GPIO.output()来设置输出电平即可。这里就不再赘述了。
2、 用Python控制SPI口
树莓派的SPI配置相对较麻烦,首先需要开启这个功能,可以在命令行中用:
sudo raspi-config
命令来开启命令行下的树莓派配置程序,并从中开启SPI功能。如果你安装了图形界面则简单得多,Raspbian系统的开始菜单中打开Preferences菜单下的Raspberry Pi Configuration,就可以在下图所示的图形界面中开启SPI功能。

图6 开启Raspibian的SPI功能
在https://pypi.python.org/pypi/spidev/3.1下载树莓派的SPI模块spidev,并通过以下命令安装这个模块:
tar –zxvf spidev-3.1.tar.gz
cd spidev
sudo python setup.py install
安装spidiv
安装成功后,如下图所示可以在/dev下看到spidev0.0和spidev0.1两个设备, 这两个SPI设备拥有同样的时钟和数据传输引脚,只是片选引脚不同。

图7 SPI设备
spidev模块在Python下的使用并不复杂,首先导入模块:
import spidev
其次初始化SPI口,Python代码如下:
spi = spidev.SpiDev()
bus = 0
device = 0
spi.open(bus , device)
spi.max_speed_hz = 10000000
spi.mode = 0b00
#[CPOL|CPHA]CPOL是SCK空闲时的电平;CPHA是时钟的第几个边沿读数
初始化SPI口
其中open()方法的两个参数分别是SPI口的编号和片选引脚的编号。max_speed_hz是以Hz为单位的SPI同步时钟频率,这里使用了10MHz的通信频率。而mode属性只有两个位,第一个位CPOL表示通信空闲时SCK的电平——0为低电平,1为高电平;第二个位CPHA表示在时钟SCK的第几个边沿读取SPI数据线上的数据——0为在空闲状态恢复的第一个边沿读取SPI数据,而1表示在空闲恢复后的第二个边沿读取数据。这里将这两个位都设置为0,表示SCK在空闲状态处于低电平,而进入通信后在SCK的第一个边沿,也就是上升沿开始读取数据。
Spidev中读写SPI口的方法为xfer(),使用示例代码为:
rx_data = spi.xfer(tx_data)
其中tx_data是由待发送数据构成的Python列表,长度不限。返回rx_data是和tx_data长度相同的列表,存放了SPI收到的数据。
3、 树莓派主程序
与实时前端进行通信的树莓派Python主程序负责完成:发送D/A转换数据包,接收A/D转换数据包,以及和用户实时交互的工作。其代码如下所示:
try:
while True:
time.sleep(0.01)
if(GPIO.input(KEY_C) == False):
#以下开始控制RT_STM32模块
GPIO.output(RP_SHK_OUT,False)#启动一次实时采集
print("Beginning a A/D&D/A processing...")
while (GPIO.input(RP_SHK_IN) == True):
#RT_STM32模块输出为高电平表示AD转换等操作还没有完成,需要等待
time.sleep(0.001)
print("The data is transporting!")#以下进行读取数据的工作
rx_data = spi.xfer(tx_data)#调用spidev模块进行连续数据收发
#列表tx_data中存放的是发送给STM32的D/A输出的数据
#列表rx_data得到的是STM32的A/D采集到的数据
GPIO.output(RP_SHK_OUT,True)#结束本次采集和数据交换
#以下将以字节为单位收发的数据拼接为16bits的数据
rx_short = []
for i in range(int(D_LEN)): #将以字节存储的数据转换为字形式
rx_short = rx_short + [rx_data[i*2] + rx_data[i*2+1]*256]
#每次添加一个数,被以列表的形式添加在原有列表的最后
rx_head = rx_data[D_LEN*2::]#后面的数据是数据包的头信息
#以下将整型数据转换为0-3.3V的电压值
res_float=[]
for x in rx_short:
temp_float = x*3.3/4096#将数据折算为电压
res_float = res_float + [temp_float]
np.savetxt("last_data.csv",res_float,delimiter = ',')#保存测试数据。
plot_time_frq_wave(res_float)#绘制时域和频域波形
print("This A/D&D/A processing is complete!")
while(GPIO.input(KEY_C) == False): #等待按键释放
time.sleep(0.01)
print(".....")
print("Please press the KEY to start a A/D&D/A processing!")
except KeyboardInterrupt:
print("Program is over.")
GPIO.cleanup()#关闭用到的GPIO
Python主流程控制代码
整个程序的最外层是一个异常检测、处理程序:当终端收到“CTL+C”时终止程序,否则不断循环交互数据和显示结果。
第二层是一个无条件循环,用于检测和树莓派25号GPIO相连的按键,并消除按键上的抖动:如果有按键就开始一轮新的数据交互和显示,如果没有就继续循环和等待。
第三层代码在检测到按键后启动,用于和STM32交互数据然后显示结果:首先通过RP_SHK_OUT拉低来启动STM32的数据交互,待STM32准备好后通过将RP_SHK_IN拉低来通知树莓派,树莓派接到消息后通过xfer()方法来启动SPI数据传输。数据交互完成后存放在返回列表中的是以高低字节存放的8位数据,程序首先将它们拼接在一起,再将数据转换为0-3.3V的实际电压信号,并保存为CSV格式的数据文件。随后程序对这些数据进行前述的数据处理,随机显示数据和处理结果。最后,程序将等待本次按键释放,然后退回上一层代码等待按键来启动下一次数据交互和结果显示。
六、测试结果
1、 A/D采集的结果
用函数信号发生器分别产生20KHz、50KHz、100KHz和200KHz的正弦信号,并利用上述实时前端,以1MSPS采样率进行500次采样。树莓派中运行的Python程序调用NumPy模块进行FFT变换后得到的信号的频谱后,再调用matplotlib模块绘图,结果如下图8-图11所示。其中上部的红色波形是时域数据,下部的蓝色波形是红色数据的频谱图。
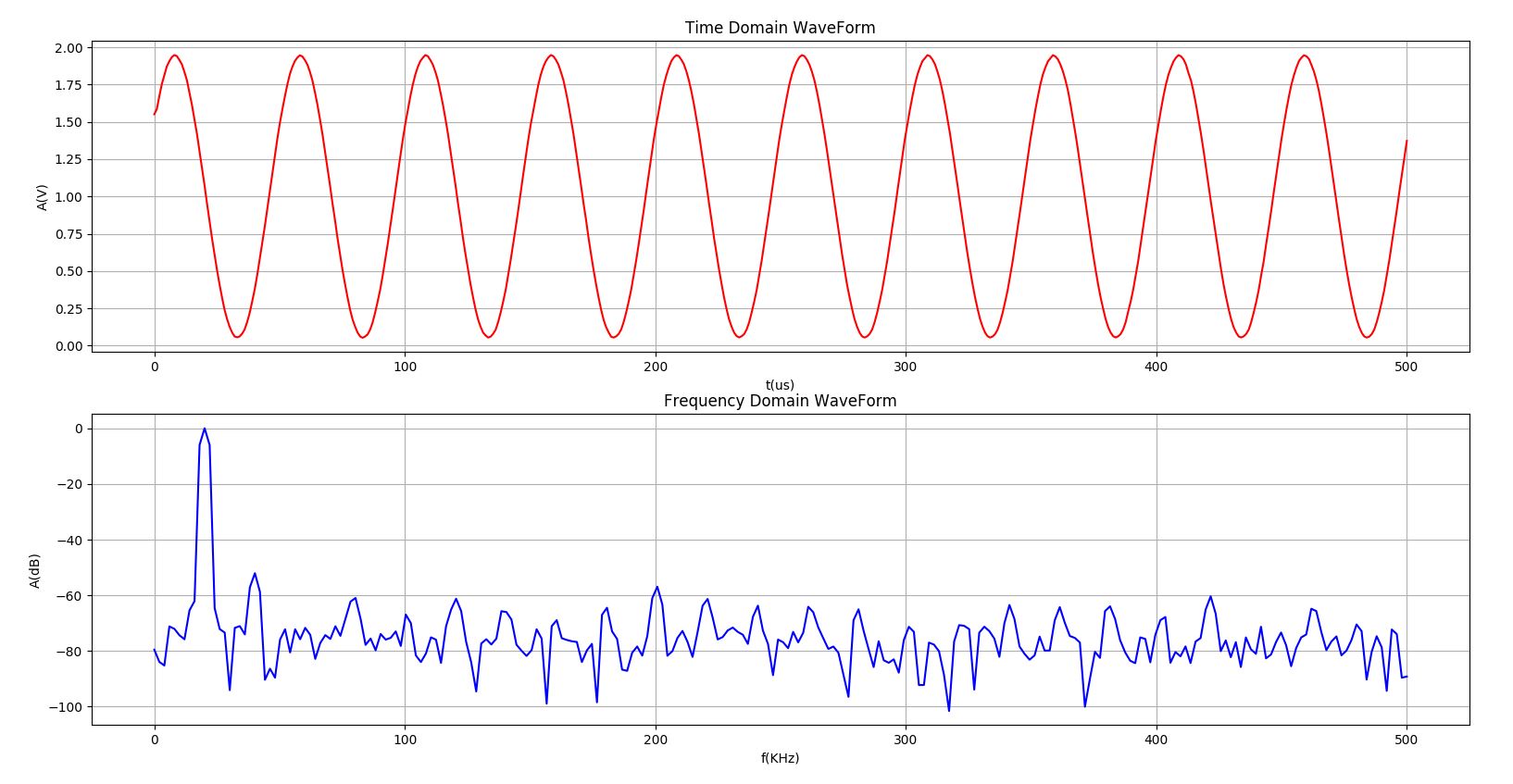
图8 对10KHz正弦信号采样和FFT变换的结果

图9 对50KHz正弦信号采样和FFT变换的结果
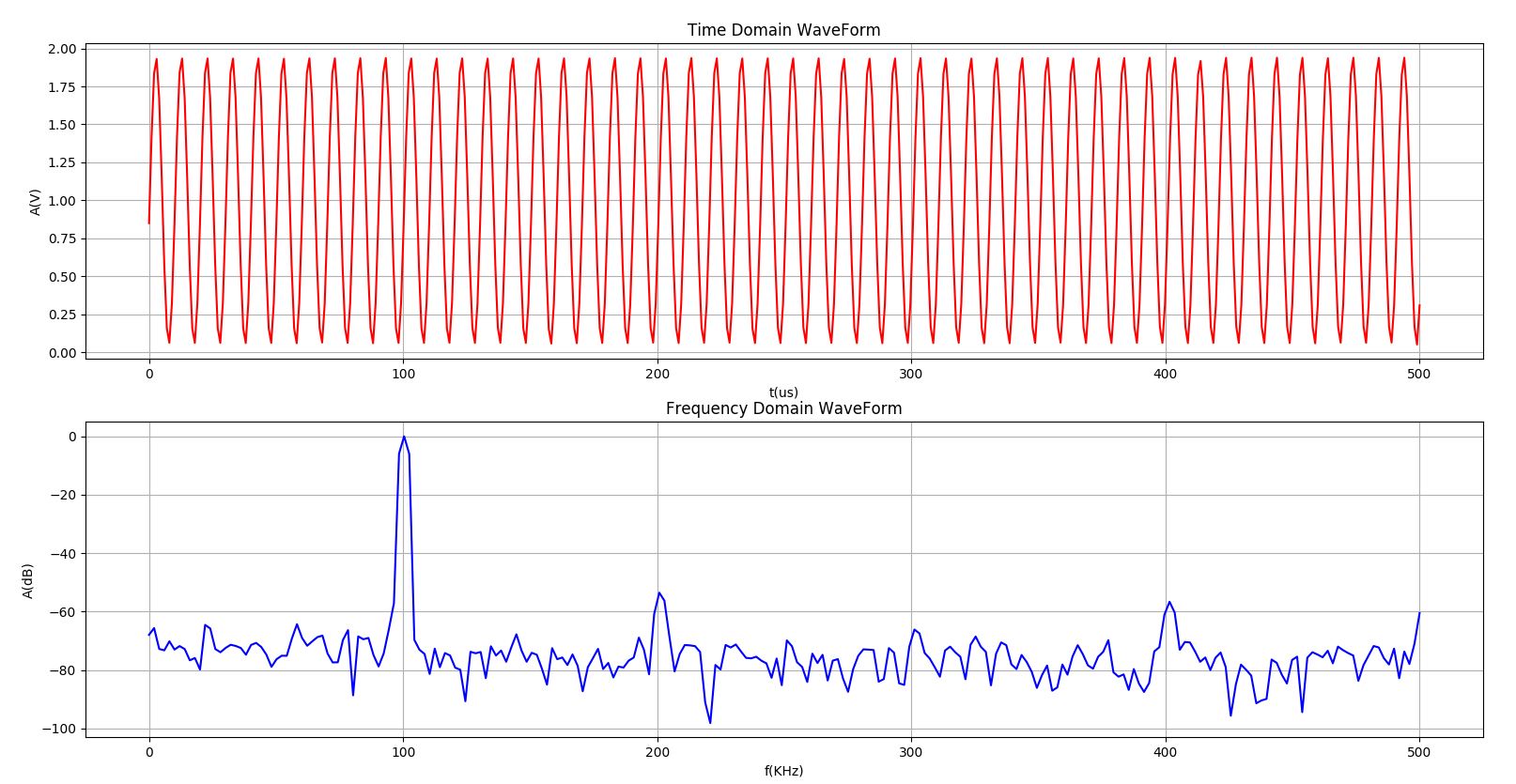
图10 对100KHz正弦信号采样和FFT变换的结果

图11 对200KHz正弦信号采样的结果
对20KHz的三角波进行采样,结果如下图所示。可以明显的看到,作为一种对称的周期函数,三角波的存在能量较大的奇次谐波。
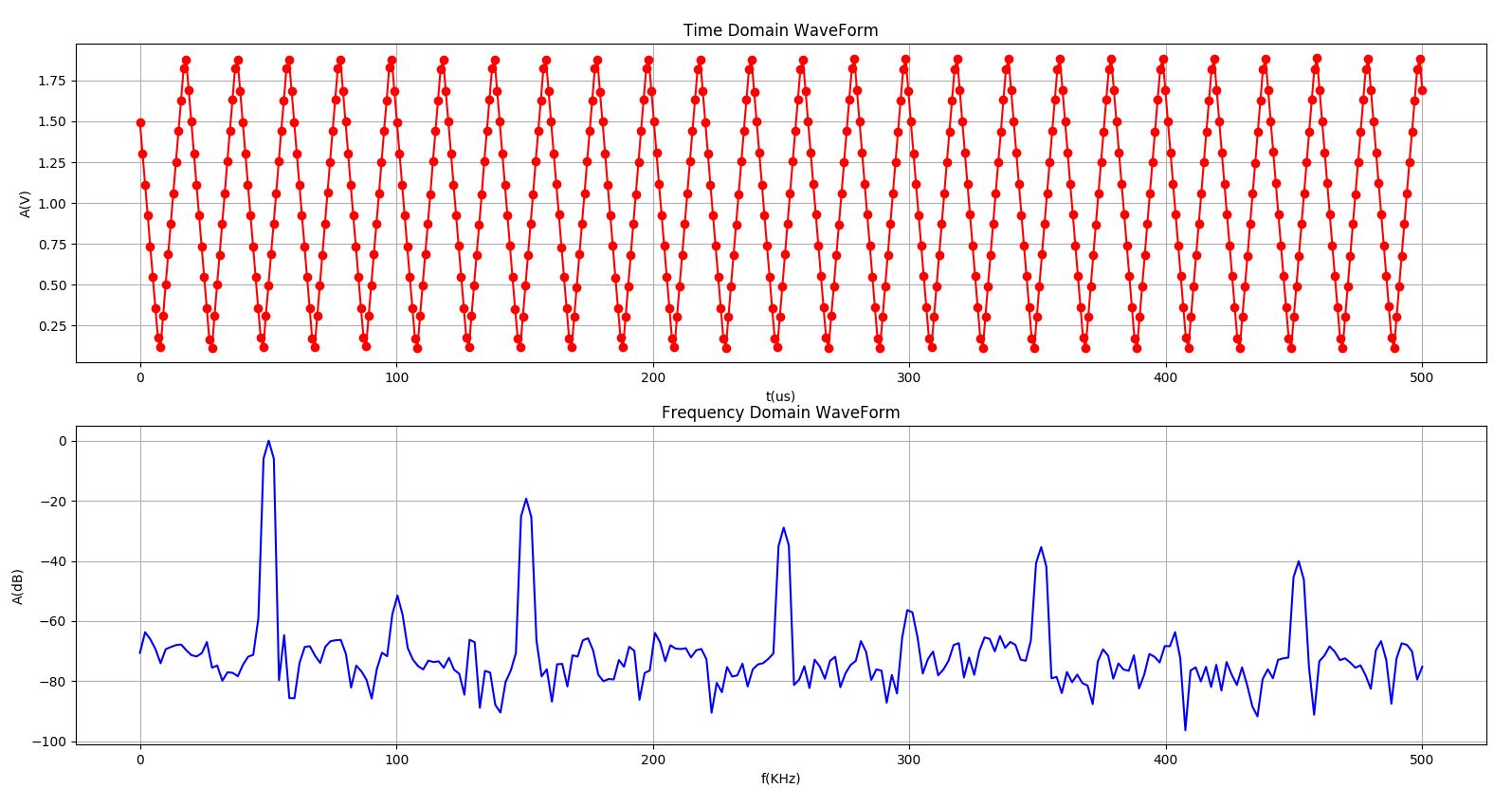
图12 对20KHz三角波信号采样的结果
2、 对A/D转换结果的进一步分析
文献[3]指出,FFT频谱的理论噪底(噪声平面)等于:
QNLdB = -(SNR + 10*log10(M/2)) (2)
其中,SNR为理论信噪比,M是进行FFT的数据点数。理论信噪比SNR的计算公式为[4]:
SNR = 6.02*N+1.76 (3)
N为转换器位数,STM32的A/D转换器为12bits,对于图8-图11所示的500点的FFT,SNR的理论值为74dB,噪声平面为-94dB。显然,图8-图11所示的对正弦信号的测试结果噪声平面有效值在-60dB左右——远高于理论值。
进一步尝试计算信纳比(SINAD),来评估采样结果。信纳比定义为:实际输入信号的均方根值与奈奎斯特频率以下包括谐波但直流除外的所有其它频谱成分的均方根和之比[4]。在树莓派上用Python和NumPy模块实现信纳比的计算,代码如下。
def cal_sinad(sfa,w):#根据FFT的幅值结果,计算信纳比SINAD的函数
#第一个参数是FFT的结果
sfa=sfa**2#将信号折算成能量
s_max = max(sfa)#查找最大值
max_index = list(sfa).index(s_max)
#查找最大值所在的位置,但index()方法只有列表有,所以先将其转回为列表再查找
index_low=max_index-w#选取窗口的下限
index_high=max_index+w#选取窗口的上限
signal_pow=sum(sfa[index_low:index_high])#选取窗口内的信号之和
noise_pow=sum(sfa)-signal_pow#计算噪声能量
sinad=10*np.log10(signal_pow/noise_pow)
return sinad
计算SINAD的Python代码
编程的基本思路是找到能量最高的频点,并将其附近的两个w内的能量值都作为信号的能量,用信号能量与其他所有点的噪声能量相除从而得到信纳比。在主程序中的调用方式如下。
SEL_WIDE = 2#选择单频信号的窗口宽度,真实窗口的宽度为SEL_WIDE*2+1
sinad = cal_sinad(sfa_half,SEL_WIDE)#根据FFT的幅值结果,计算信纳比SINAD
print("The SINAD is: %f dB"%sinad) #输出显示采集信号的信纳比
经计算得到图8-图11所示信号的信纳比在44-46dB左右,低于理论值74dB(在理想情况下。理论信纳比SINAD等于理论信噪比SNR)。造成信纳比低于信噪比的原因可能有:
1)从实物图5中可以看到,函数信号发生器和实时性前端的模拟输入采用了鳄鱼夹和单股导线连接,很可能造成了信号的失真。周期性的失真将造成谐波干扰,而这一点可以在图8-图11的频谱图中都可以观测到——信号的二次谐波频率点上都有明显的能量突出。
2)STM32的A/D转换模块本身属于SoC的一部分,由于模数隔离等原因,其模拟性能可能不如单独的ADC芯片,距离SINAD的理论值更是存在一定差距。
3)STM32布线时没有严格区分模拟电源、模拟地和数字电源、数字地,并分别对模拟电源——模拟地,以及数字电源——数字地去耦。
4)STM32锁相环所产生的系统时钟可能存在较大孔径抖动,从而造成信纳比降低。
3、 D/A输出的结果
在每次数据交互前,需要将D/A输出的数据存入列表tx_data中,可用numpy模块产生一个单频的正弦信号。其中,计算产生的正弦值被增加了211的直流偏置,以将所有数值转换为正数。由于SPI通信的基本单位是1个字节,因此数据最后要分解为高低两个字节。
index = np.arange(D_LEN)
s = 1000*np.sin(2*np.pi*index*k/D_LEN)+2**11#k个周期的正弦波形
s = s.astype(np.uint16)#将numpy对象s强制类型转换为16位无符号整形
tx_data = [] #将数据存放在列表中,且不超过1个字节
for dt in s:
tx_data.append(int(dt%256))
tx_data.append(int(dt/256))
Pyhton产生D/A数据
用spi.xfer()方法启动一次双向通信后,用示波器观察D/A输出的信号如下图所示,其中,考上的绿色部分是D/A输出的时域波形,靠下的红色部分是示波器对时域波形进行FFT得到的频谱图。

图12 示波器观测D/A产生的单频信号
也可以用Python NumPy产生更复杂的波形,如包含三个频率点的信号:
s = 1000*np.sin(2*np.pi*index*2/D_LEN) + 200*np.sin(2*np.pi*index*20/D_LEN) + 40*np.sin(2*np.pi*index*50/D_LEN) +2048
用示波器观察上面代码产生的波形及其频谱如下图所示。
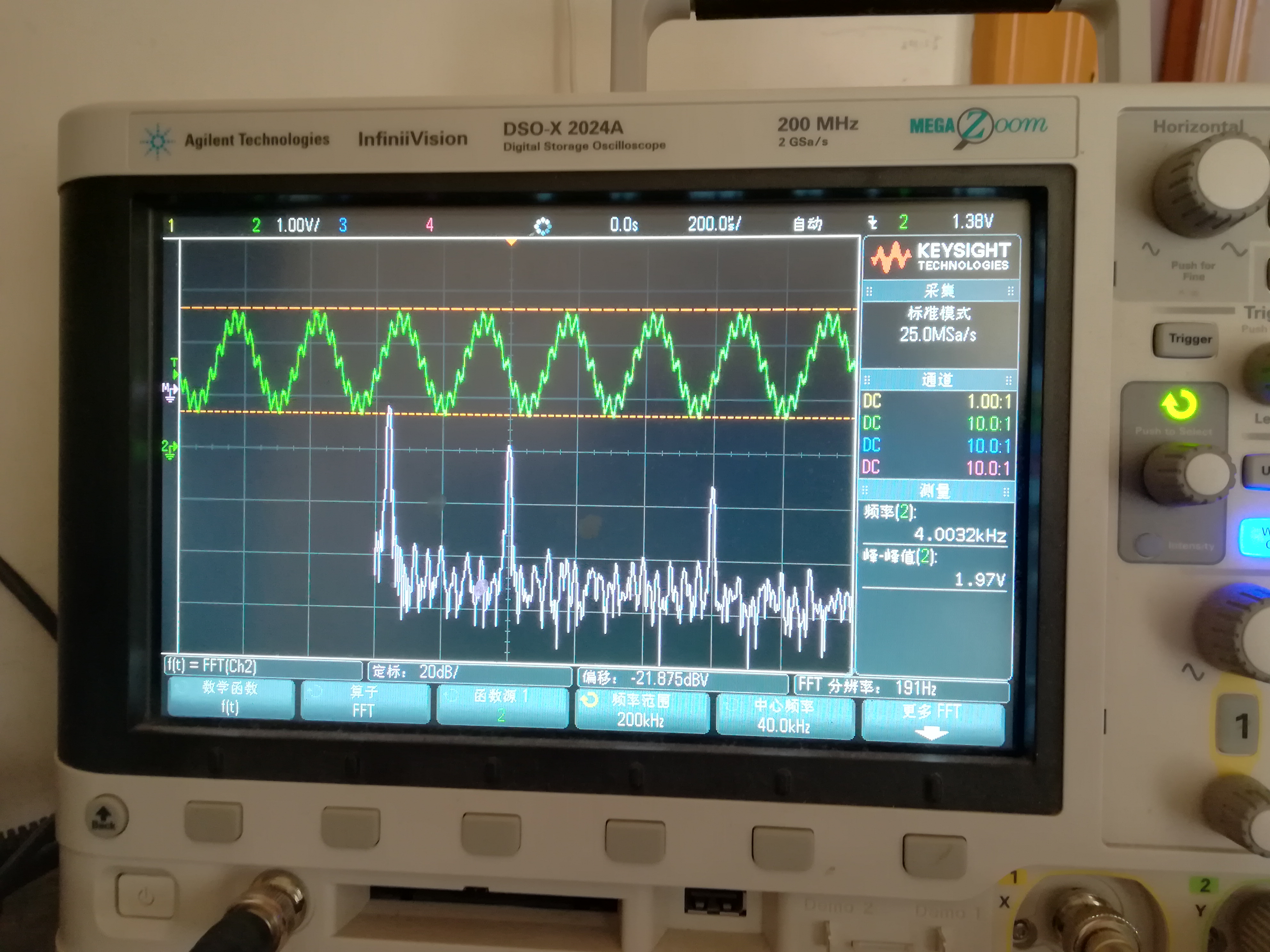
图13 示波器观测D/A产生的三频信号
参考文献:
[1] Brad Brannon, "Aperture Uncertainty and ADC System Performance" Application Note AN-501, Analog Devices, Inc., January 1998.
[2] Walt Kester, "孔径时间、孔径抖动、孔径延迟时间——正本清源" MT-007 TUTORIAL, Analog Devices, Inc., October 2008.
[3] Walt Kester, "了解SINAD、ENOB、SNR、THD、THD + N、SFDR,不在噪底中迷失" MT-003 TUTORIAL, Analog Devices, Inc., October 2008.
[4] Walt Kester, "Analog-Digital Conversion" Analog Devices, Inc., ISBN 0-916550-27-3, 2004.
为树莓派添加一个强实时性前端[原创cnblogs.com/helesheng]的更多相关文章
- Linux操作系统实时性分析
1. 概述 选择一个合适的嵌入式操作系统,可以考虑以下几个因素: 第一是应用.如果你想开发的嵌入式设备是一个和网络应用密切相关或者就是一个网络设备,那么你应该选择用嵌入式Linux或者uCLinux ...
- Week Plan:强介入性的效率导师[转]
做产品有三重境界,以效率工具这一细分领域为例: 第一重——发现用户需求,如 Fleep,敏锐地发现团队协作中的关键——聊天,围绕这一需求做足文章; 第二重——预见用户需求,如 ProcessOn,在以 ...
- 用Vue开发一个实时性时间转换功能,看这篇文章就够了
前言 最近有一个说法,如果你看见某个网站的某个功能,你就大概能猜出背后的业务逻辑是怎么样的,以及你能动手开发一个一毛一样的功能,那么你的前端技能算是进阶中高级水平了.比如咱们今天要聊的这个话题:如何用 ...
- Puer是一个可以实时编辑刷新的前端服务器
##Puer是一个可以实时编辑刷新的前端服务器 确保你安装了nodejs(现在还有没nodejs环境的前端? 拖出去喂狗吧) 使用npm全局安装puer命令 npm install puer -g 输 ...
- DHTMLX 前端框架 建立你的一个应用程序教程(三)--添加一个菜单
菜单的介绍 这篇我们介绍将菜单组建添加到上节中的布局中: 我们不对菜单做任何处理 只是在这里填充作为界面的一部分. 这里我们介绍的是dhtmlxMenu 组件. 这个组件的数据我们可以从XML或者J ...
- 树莓派Raspiberry 编译Linux实时内核PREEMPT-RT 实战
树莓派4B 实时内核(Preempt_RT)的配置和编译https://blog.csdn.net/zlp_zky/article/details/114994444 基本按照这个blog来操作. 几 ...
- 基于gulp编写的一个简单实用的前端开发环境好了,安装完Gulp后,接下来是你大展身手的时候了,在你自己的电脑上面随便哪个地方建一个目录,打开命令行,然后进入创建好的目录里面,开始撸代码,关于生成的json文件请点击这里https://docs.npmjs.com/files/package.json,打开的速度看你的网速了注意:以下是为了演示 ,我建的一个目录结构,你自己可以根据项目需求自己建目
自从Node.js出现以来,基于其的前端开发的工具框架也越来越多了,从Grunt到Gulp再到现在很火的WebPack,所有的这些新的东西的出现都极大的解放了我们在前端领域的开发,作为一个在前端领域里 ...
- 基于gulp编写的一个简单实用的前端开发环境
自从Node.js出现以来,基于其的前端开发的工具框架也越来越多了,从Grunt到Gulp再到现在很火的WebPack,所有的这些新的东西的出现都极大的解放了我们在前端领域的开发,作为一个在前端领域里 ...
- 【原创】xenomai与VxWorks实时性对比(Jitter对比)
版权声明:本文为本文为博主原创文章,转载请注明出处.如有问题,欢迎指正.博客地址:https://www.cnblogs.com/wsg1100/ (下面数据,仅供个人参考) 可能大部分人一直好奇Vx ...
随机推荐
- Spring boot整合Swagger
本文github位置:https://github.com/WillVi/springboot-swagger2-demo 环境准备 JDK版本:1.8 Spring boot版本:1.5.16 Sw ...
- 在python命令行执行sudo命令
def test(): sudoPassword = 'test' command = '/opt/lampp/lampp stopmysql' str = os.system('echo %s|su ...
- Centos7中yum安装MySQL
安装mysql [root@localhost ~]# yum update [root@localhost ~]# cat /etc/redhat-release CentOS Linux rele ...
- Google的Python代码格式化工具YAPF详解
平时习惯了杂乱无章地编写代码,而最后的代码勘定,却依赖于PyCharm自带的格式化工具,以及其自带的提示功能来规范代码.而pycharm里的格式化工具,不支持对多文件进行代码批量格式化,曾经尝试些解决 ...
- java多态实例
学校有两个打印机,一个彩印,一个黑白印,都打印输出 public class printerDemo { public static void main(String[] args) { colorP ...
- BZOJ3174:[TJOI2013]拯救小矮人(DP)
Description 一群小矮人掉进了一个很深的陷阱里,由于太矮爬不上来,于是他们决定搭一个人梯.即:一个小矮人站在另一小矮人的 肩膀上,知道最顶端的小矮人伸直胳膊可以碰到陷阱口.对于每一个小矮人, ...
- Jquery mobile 自定义 返回按钮 data-rel="back"
data-rel="back" 第一个页面 主页面 studentmaster.html 通过下面js脚本跳转到详情页面 window.location.href="s ...
- Git创建本地分支并关联远程分支
创建本地分支git branch 分支名 例如:git branch dev,这条命令是基于当前分支创建的本地分支,假设当前分支是master(远程分支),则是基于master分支创建的本地分支dev ...
- 通讯协议(一)HTTP协议
协议是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则,超文本传输协议(HTTP)是一种通信协议,它允许将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器.目前我们使 ...
- Oracle数据库常用命令(持续更新)
1. 查询当前用户所有的表 select * from user_tables; 2. 查询当前用户能访问的表 select * from all_tables; 3. 获取表字段 select * ...