SparkSQL大数据实战:揭开Join的神秘面纱
本文来自 网易云社区 。
Join操作是数据库和大数据计算中的高级特性,大多数场景都需要进行复杂的Join操作,本文从原理层面介绍了SparkSQL支持的常见Join算法及其适用场景。
Join背景介绍
Join是数据库查询永远绕不开的话题,传统查询SQL技术总体可以分为简单操作(过滤操作-where、排序操作-limit等),聚合操作-groupby以及Join操作等。其中Join操作是最复杂、代价最大的操作类型,也是OLAP场景中使用相对较多的操作。因此很有必要对其进行深入研究。
另外,从业务层面来讲,用户在数仓建设的时候也会涉及Join使用的问题。通常情况下,数据仓库中的表一般会分为“低层次表”和“高层次表”。
所谓“低层次表”,就是数据源导入数仓之后直接生成的表,单表列值较少,一般可以明显归为维度表或事实表,表和表之间大多存在外健依赖,所以查询起来会遇到大量Join运算,查询效率很差。而“高层次表”是在“低层次表”的基础上加工转换而来,通常做法是使用SQL语句将需要Join的表预先进行合并形成“宽表”,在宽表上的查询不需要执行大量Join,效率很高。但宽表缺点是数据会有大量冗余,且相对生成较滞后,查询结果可能并不及时。
为了获得时效性更高的查询结果,大多数场景都需要进行复杂的Join操作。Join操作之所以复杂,主要是通常情况下其时间空间复杂度高,且有很多算法,在不同场景下需要选择特定算法才能获得最好的优化效果。本文将介绍SparkSQL所支持的几种常见的Join算法及其适用场景。
Join常见分类以及基本实现机制
当前SparkSQL支持三种Join算法:shuffle hash join、broadcast hash join以及sort merge join。其中前两者归根到底都属于hash join,只不过在hash join之前需要先shuffle还是先broadcast。其实,hash join算法来自于传统数据库,而shuffle和broadcast是大数据的皮(分布式),两者一结合就成了大数据的算法了。因此可以说,大数据的根就是传统数据库。既然hash join是“内核”,那就刨出来看看,看完把“皮”再分析一下。
hash join
先来看看这样一条SQL语句:select * from order,item where item.id = order.i_id,很简单一个Join节点,参与join的两张表是item和order,join key分别是item.id以及order.i_id。现在假设这个Join采用的是hash join算法,整个过程会经历三步:
- 确定Build Table以及Probe Table:这个概念比较重要,Build Table使用join key构建Hash Table,而Probe Table使用join key进行探测,探测成功就可以join在一起。通常情况下,小表会作为Build Table,大表作为Probe Table。此事例中item为Build Table,order为Probe Table。
- 构建Hash Table:依次读取Build Table(item)的数据,对于每一行数据根据join key(item.id)进行hash,hash到对应的Bucket,生成hash table中的一条记录。数据缓存在内存中,如果内存放不下需要dump到外存。
- 探测:再依次扫描Probe Table(order)的数据,使用相同的hash函数映射Hash Table中的记录,映射成功之后再检查join条件(item.id = order.i_id),如果匹配成功就可以将两者join在一起。

基本流程可以参考上图,这里有两个小问题需要关注:
- hash join性能如何?很显然,hash join基本都只扫描两表一次,可以认为o(a+b),较之最极端的笛卡尔集运算a*b,不知甩了多少条街。
- 为什么Build Table选择小表?道理很简单,因为构建的Hash Table最好能全部加载在内存,效率最高;这也决定了hash join算法只适合至少一个小表的join场景,对于两个大表的join场景并不适用。
上文说过,hash join是传统数据库中的单机join算法,在分布式环境下需要经过一定的分布式改造,就是尽可能利用分布式计算资源进行并行化计算,提高总体效率。hash join分布式改造一般有两种经典方案:
- broadcast hash join:将其中一张小表广播分发到另一张大表所在的分区节点上,分别并发地与其上的分区记录进行hash join。broadcast适用于小表很小,可以直接广播的场景。
- shuffler hash join:一旦小表数据量较大,此时就不再适合进行广播分发。这种情况下,可以根据join key相同必然分区相同的原理,将两张表分别按照join key进行重新组织分区,这样就可以将join分而治之,划分为很多小join,充分利用集群资源并行化。
下面分别进行详细讲解。
broadcast hash join
如下图所示,broadcast hash join可以分为两步:
- broadcast阶段:将小表广播分发到大表所在的所有主机。广播算法可以有很多,最简单的是先发给driver,driver再统一分发给所有executor;要不就是基于BitTorrent的TorrentBroadcast。
- hash join阶段:在每个executor上执行单机版hash join,小表映射,大表试探。
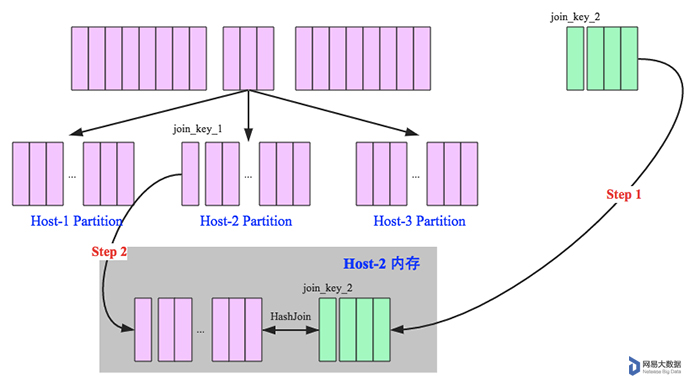
3.SparkSQL规定broadcast hash join执行的基本条件为被广播小表必须小于参数spark.sql.autoBroadcastJoinThreshold,默认为10M。
shuffle hash join
在大数据条件下如果一张表很小,执行join操作最优的选择无疑是broadcast hash join,效率最高。但是一旦小表数据量增大,广播所需内存、带宽等资源必然就会太大,broadcast hash join就不再是最优方案。此时可以按照join key进行分区,根据key相同必然分区相同的原理,就可以将大表join分而治之,划分为很多小表的join,充分利用集群资源并行化。如下图所示,shuffle hash join也可以分为两步:
- shuffle阶段:分别将两个表按照join key进行分区,将相同join key的记录重分布到同一节点,两张表的数据会被重分布到集群中所有节点。这个过程称为shuffle。
- hash join阶段:每个分区节点上的数据单独执行单机hash join算法。
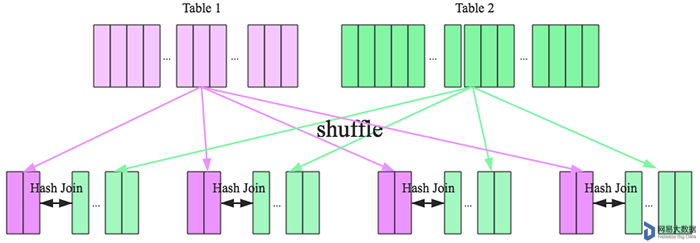
看到这里,可以初步总结出来如果两张小表join可以直接使用单机版hash join;如果一张大表join一张极小表,可以选择broadcast hash join算法;而如果是一张大表join一张小表,则可以选择shuffle hash join算法;那如果是两张大表进行join呢?
sort merge join
SparkSQL对两张大表join采用了全新的算法-sort-merge join,如下图所示,整个过程分为三个步骤:
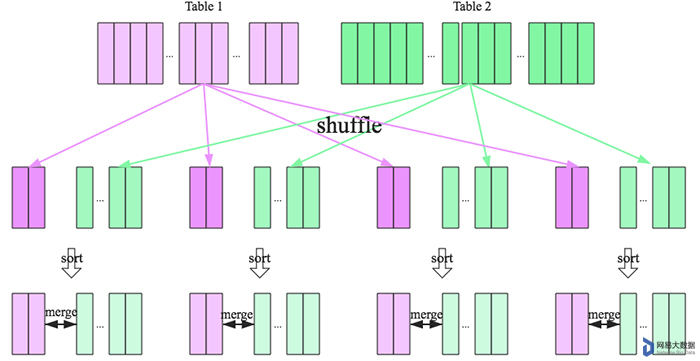
- shuffle阶段:将两张大表根据join key进行重新分区,两张表数据会分布到整个集群,以便分布式并行处理。
- sort阶段:对单个分区节点的两表数据,分别进行排序。
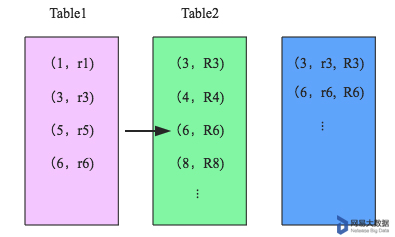
- merge阶段:对排好序的两张分区表数据执行join操作。join操作很简单,分别遍历两个有序序列,碰到相同join key就merge输出,否则取更小一边。如下图所示:
经过上文的分析,很明显可以得出来这几种Join的代价关系:cost(broadcast hash join) < cost(shuffle hash join) < cost(sort merge join),数据仓库设计时最好避免大表与大表的join查询,SparkSQL也可以根据内存资源、带宽资源适量将参数spark.sql.autoBroadcastJoinThreshold调大,让更多join实际执行为broadcast hash join。
总结
Join操作是数据库和大数据计算中的高级特性,因为其独特的复杂性,很少有同学能够讲清楚其中的原理。本文试图带大家真正走进Join的世界,了解常用的几种Join算法以及各自的适用场景。后面两篇文章将会在此基础上不断深入Join内部,一点一点地揭开它的面纱,敬请关注!
本文已由作者范欣欣授权网易云社区发布,原文链接:SparkSQL大数据实战:揭开Join的神秘面纱
SparkSQL大数据实战:揭开Join的神秘面纱的更多相关文章
- 《OD大数据实战》HDFS入门实例
一.环境搭建 1. 下载安装配置 <OD大数据实战>Hadoop伪分布式环境搭建 2. Hadoop配置信息 1)${HADOOP_HOME}/libexec:存储hadoop的默认环境 ...
- 《OD大数据实战》驴妈妈旅游网大型离线数据电商分析平台
一.环境搭建 1. <OD大数据实战>Hadoop伪分布式环境搭建 2. <OD大数据实战>Hive环境搭建 3. <OD大数据实战>Sqoop入门实例 4. &l ...
- 《OD大数据实战》Hive环境搭建
一.搭建hadoop环境 <OD大数据实战>hadoop伪分布式环境搭建 二.Hive环境搭建 1. 准备安装文件 下载地址: http://archive.cloudera.com/cd ...
- 从一个Demo开始,揭开Netty的神秘面纱
本文是Netty系列第5篇 上一篇文章我们对于I/O多路复用.Java NIO包 和 Netty 的关系有了全面的认识. 到目前为止,我们已经从I/O模型出发,逐步接触到了Netty框架.这个过程中, ...
- ASP.NET 运行时详解 揭开请求过程神秘面纱
对于ASP.NET开发,排在前五的话题离不开请求生命周期.像什么Cache.身份认证.Role管理.Routing映射,微软到底在请求过程中干了哪些隐秘的事,现在是时候揭晓了.抛开乌云见晴天,接下来就 ...
- 带你揭开ATM的神秘面纱
相信大家都用过ATM取过money吧,但是有多少人真正是了解ATM的呢?相信除了ATM从业者外了解的人寥寥无几吧,鄙人作为一个从事ATM软件开发的伪专业人士就站在我的角度为大家揭开ATM的神秘面纱吧. ...
- 揭开Future的神秘面纱——任务取消
系列目录: 揭开Future的神秘面纱——任务取消 揭开Future的神秘面纱——任务执行 揭开Future的神秘面纱——结果获取 使用案例 在之前写过的一篇随笔中已经提到了Future的应用场景和特 ...
- 揭开HTTPS的神秘面纱
摘自:https://www.cnblogs.com/hujingnb/p/11789728.html 揭开HTTPS的神秘面纱 在说HTTP前,一定要先介绍一下HTTP,这家伙应该不用过多说明了 ...
- 揭开Future的神秘面纱——结果获取
前言 在前面的两篇博文中,已经介绍利用FutureTask任务的执行流程,以及利用其实现的cancel方法取消任务的情况.本篇就来介绍下,线程任务的结果获取. 系列目录 揭开Future的神秘面纱—— ...
随机推荐
- (2/24) 快速上手一个webpack的demo
写在前面:该部分的安装都是基于windows系统的,且此处的webpack的版本为:3.6.0. 1.安装webpack 1.1 安装方法: 用win+R打开运行对话框,输入cmd进入命令行模式.然后 ...
- 551. Student Attendance Record I + Student Attendance Record II
▶ 一个学生的考勤状况是一个字符串,其中各字符的含义是:A 缺勤,L 迟到,P 正常.如果一个学生考勤状况中 A 不超过一个,且没有连续两个 L(L 可以有多个,但是不能连续),则称该学生达标(原文表 ...
- js解决弹窗问题实现班级跳转DIV示例
js解决弹窗问题实现班级跳转DIV 1.js代码如下: <%--实现班级跳转DIV--%> <div id="displayClassDiv" style=&q ...
- Android 包信息工具类
/** AndroidInfoUtils:安卓游戏包信息工具类**/ 1 public class AndroidInfoUtils { @SuppressWarnings("uncheck ...
- numpy中的ndarray方法和属性
原文地址 NumPy数组的维数称为秩(rank),一维数组的秩为1,二维数组的秩为2,以此类推.在NumPy中,每一个线性的数组称为是一个轴(axes),秩其实是描述轴的数量.比如说,二维数组相当于是 ...
- .net core 一个避免跨站请求的中间件
前提: 前几天看到博客园首页中有这么一篇文章:跨站请求伪造(CSRF),刚好前段时间自己一直也在搞这个东西,后来觉得每次在form表单里添加一个@Html.AntiForgeryToken,在对应的方 ...
- clr相关的一些工具
NGen.exe:将IL代码编译成本地代码. PEVerify.exe:它检查一个集所有方法并报告其中含不 的实用程序. ILDasm.ex:IL反编译 csc.exe:C#编译工具 ilasm.ex ...
- Android中asset文件夹与raw文件夹的区别深入解析(转)
*res/raw和assets的相同点:1.两者目录下的文件在打包后会原封不动的保存在apk包中,不会被编译成二进制.*res/raw和assets的不同点:1.res/raw中的文件会被映射到R.j ...
- Gcc And MakeFile Level1
简单介绍gcc And make 的使用 基本编译 gcc a.c b.c -o exeName 分步编译 gcc -c a.c -o a.o gcc a.o b.c -o main.o 使用Make ...
- spring aop记录用户的操作
1.命名空间 xmlns:aop="http://www.springframework.org/schema/aop" http://www.springframework.or ...