图书管理(Loj0034)+浅谈哈希表
图书管理
题目描述
图书管理是一件十分繁杂的工作,在一个图书馆中每天都会有许多新书加入。为了更方便的管理图书(以便于帮助想要借书的客人快速查找他们是否有他们所需要的书),我们需要设计一个图书查找系统。
该系统需要支持 2 种操作:
add(s)表示新加入一本书名为 s 的图书。find(s)表示查询是否存在一本书名为 s 的图书。
输入格式
第一行包括一个正整数 n,表示操作数。 以下 n 行,每行给出 2 种操作中的某一个指令条,指令格式为:
add s
find s在书名 s 与指令(add,find)之间有一个隔开,我们保证所有书名的长度都不超过 200。可以假设读入数据是准确无误的。
输出格式
对于每个 find(s) 指令,我们必须对应的输出一行 yes 或 no,表示当前所查询的书是否存在于图书馆内。
注意:一开始时图书馆内是没有一本图书的。并且,对于相同字母不同大小写的书名,我们认为它们是不同的。
样例
样例输入
4
add Inside C#
find Effective Java
add Effective Java
find Effective Java样例输出
no
yes数据范围与提示
n≤30000
借这个题说几件事情
(1)输入
我们发现书名中间是有空格的,cin和scanf一旦遇到空格就会断开
所以这里要用gets()(详见代码)
(2)双hash
通常来说,hash发生碰撞的概率比较大,所以我们可以分别取两个乘数和模数,只有两个hash值均相等时才说两个数相等。这样可以大大减少碰撞的概率。
(3)哈希表
一种数据结构。查找hash表的时间近似于O(n),十分便捷。
比如我们如果要存一个数组并查找
如果用朴素的A[1……n]来存储
即使用二分查找也要O(logN)
如果用hash的思想,可以将hash值相同的几个数用链表存在一起,每个hash值开一个链表(其实就是邻接表)
这个东西就叫哈希表
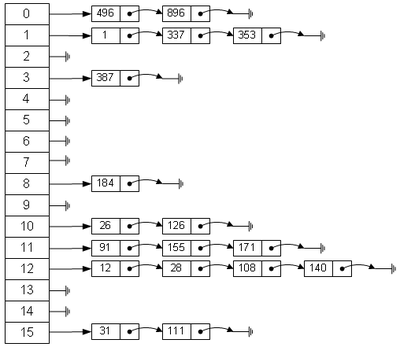
如图,这是一个模数为16的哈希表(实际上将16选为模数并不合适)
储存和查找的期望复杂度为O(1),实际的复杂度取决于链表长度(也就是你选的模数好不好、数据友善不友善),可以看成一个常数
给出代码:
#include<iostream>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<algorithm>
#include<cmath>
#define ULL unsigned long long
#define P 37
#define P2 97
#define MOD 100003
#define MOD2 100009
using namespace std; inline int read()
{
int f=,x=;
char ch=getchar();
while(ch<'' || ch>'') {if(ch=='-') f=-; ch=getchar();}
while(ch>='' && ch<='') {x=x*+ch-''; ch=getchar();}
return x*f;
} int n,cnt;
int v[MOD2+],head[MOD2+],nxt[MOD2+];
char a[],c[];
int i,j; void add(int x1,int x2)//哈希表(怎么看都是邻接表……)
{
v[++cnt]=x2;
nxt[cnt]=head[x1];
head[x1]=cnt;
return ;
} bool check(int x1,int x2)
{
for(int k=head[x1];k!=-;k=nxt[k])
{
if(v[k]==x2) return ;
}
return ;
} int main()
{
memset(head,-,sizeof(head));
n=read();
for(i=;i<=n;i++)
{
scanf("%s",a);
gets(c);
int len=strlen(c);
int sum1=,sum2=;
for(j=;j<len;j++)
{
sum1=(sum1*P+c[j])%MOD;
sum2=(sum2*P2+c[j])%MOD2;//使用双hash值,减少碰撞概率
}
if(a[]=='a') add(sum1,sum2);
else
{
if(check(sum1,sum2))
printf("yes\n");
else
printf("no\n");
} }
return ;
}
哈希表(标准答案)
此外还有其他方法:
#include<iostream>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<algorithm>
#include<cmath>
#define ULL unsigned long long
#define P 1000000007
using namespace std; inline int read()
{
int f=,x=;
char ch=getchar();
while(ch<'' || ch>'') {if(ch=='-') f=-; ch=getchar();}
while(ch>='' && ch<='') {x=x*+ch-''; ch=getchar();}
return x*f;
} int n,cnt;
ULL v[];
char a[],c[];
int i,j; void add(int x)
{
v[++cnt]=x;
} bool check(int x)
{
for(int k=;k<=cnt;k++)
{
if(v[k]==x) return ;
}
return ;
} int main()
{
n=read();
for(i=;i<=n;i++)
{
scanf("%s",a);
gets(c);
int len=strlen(c);
ULL sum=;
for(j=;j<len;j++)
{
sum=sum*P+c[j];
}
if(a[]=='a') add(sum);
else
{
if(check(sum))
printf("yes\n");
else
printf("no\n");
} }
return ;
}
朴素hash(容易被卡+TLE)
石乐志的尝试↓:
#include<iostream>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<algorithm>
#include<cmath>
using namespace std; inline int read()
{
int f=,x=;
char ch=getchar();
while(ch<'' || ch>'') {if(ch=='-') f=-; ch=getchar();}
while(ch>='' && ch<='') {x=x*+ch-''; ch=getchar();}
return x*f;
} int n,tot;
char a[],s[];
int ts[][];
bool book[];
int i,j; void make_trie()
{
int len=strlen(s),u=;
for(int k=;k<len;k++)
{
int c=s[k];
if(!ts[u][c])
ts[u][c]=++tot;
u=ts[u][c];
}
book[u]=;
} bool find_trie()
{
int len=strlen(s),u=;
for(int k=;k<len;k++)
{
int c=s[k];
if(!ts[u][c]) return ;
u=ts[u][c];
}
if(book[u]) return ;
else return ;
} int main()
{
n=read();
for(i=;i<=n;i++)
{
scanf("%s",a);
gets(s);
if(a[]=='a')
{
make_trie();
}
else
{
if(find_trie())
printf("yes\n");
else
printf("no\n");
}
}
return ;
}
Trie(华丽丽的RE&MLE)
本文部分图片来源于网络
部分内容参考《信息学奥赛一本通.提高篇》第二部分第一章 哈希和哈希表
若需转载,请注明https://www.cnblogs.com/llllllpppppp/p/9746749.html
~祝大家编程顺利~
图书管理(Loj0034)+浅谈哈希表的更多相关文章
- 【编程学习】浅谈哈希表及用C语言构建哈希表!
哈希表:通过key-value而直接进行访问的数据结构,不用经过关键值间的比较,从而省去了大量处理时间. 哈希函数:选择的最主要考虑因素--尽可能避免冲突的出现 构造哈希函数的原则是: ①函数本身便于 ...
- Sql server 浅谈用户定义表类型
1.1 简介 SQL Server 中,用户定义表类型是指用户所定义的表示表结构定义的类型.您可以使用用户定义表类型为存储过程或函数声明表值参数,或者声明您要在批处理中或在存储过程或函数的主体中使用的 ...
- 浅谈MySQL分表
关于分表:顾名思义就是一张数据量很大的表拆分成几个表分别进行存储. 我们先来大概了解以下一个数据库执行SQL的过程: 接收到SQL --> 放入SQL执行队列 --> 使用分析器分解SQL ...
- 浅谈对ST表的一些理解
今天打了人生第一道ST表题(其实只是ST表跑得最快); ST表是一种用来解决RMQ问题的利器... 大体操作有两步: 第一部分nlogn预处理 第二部分O(1)询问 预处理就是运用倍增+区间动规 ST ...
- 浅谈MySQL多表操作
字段操作 create table tf1( id int primary key auto_increment, x int, y int ); # 修改 alter table tf1 modif ...
- 浅谈 倍增/ST表
命题描述 给定一个长度为 \(n\) 的序列,\(m\) 次询问区间最大值 分析 上面的问题肯定可以暴力对吧. 但暴力肯定不是最优对吧,所以我们直接就不考虑了... 于是引入:倍增 首先,倍增是个什么 ...
- Python 字典和集合基于哈希表实现
哈希表作为基础数据结构我不多说,有兴趣的可以百度,或者等我出一篇博客来细谈哈希表.我这里就简单讲讲:哈希表不过就是一个定长数组,元素找位置,遇到哈希冲突则利用 hash 算法解决找另一个位置,如果数组 ...
- 浅谈MatrixOne如何用Go语言设计与实现高性能哈希表
目录 MatrixOne数据库是什么? 哈希表数据结构基础 哈希表基本设计与对性能的影响 碰撞处理 链地址法 开放寻址法 Max load factor Growth factor 空闲桶探测方法 一 ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
随机推荐
- 关于Unity中NGUI的Checkbox复选框、Slider滑动条和Button的6种触发回调事件的方式
Checkbox复选框 1.创建一个NGUI背景Sprite1节点 2.打开NGUI---->Open---->Prefab Toolbar---->选择一个复选框节点,拖拽到背景节 ...
- Nginx 实现负载均衡
.安装nginx和tomcat 我这里是使用docker安装的.安装流程可参照 dockerfile 这里安装了两个tomcat,端口分别是42000和42001.第二个tomcat的首页随便加了些代 ...
- [GAN] Generative networks
中文版:https://zhuanlan.zhihu.com/p/27440393 原文版:https://www.oreilly.com/learning/generative-adversaria ...
- SpringBoot------个性化启动Banner设置
1.添加Banner.txt文件 . ____ _ __ _ _ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_ | '_| | '_ \/ ...
- Puppet file资源使用
1.文件管理介绍: 可管理的项目: 支持文件和目录 设置文件及目录的所有者及权限 恢复文件(包括文件的内容.权限及所有者) 清理目录以及子目录 2. 可使用参数: ensure :指 ...
- ubuntu-16.04更好软件源
author: headsen chen date:2019-03-06 14:01:07 1,修改软件源文件成如下的清华大学的源(亲测可用) root@ubuntu:/var/lib/apt/li ...
- MassTransit入门
.NET平台ESB框架的中文资料少的可怜,NServiceBus的有几篇,MassTransit的根本找不到,只好硬着头皮看官方的英文文档,顺便翻译出来加深理解. 欢迎拍砖. MassTransit是 ...
- super()方法
super()是一个调用父类的方法. super()用来解决多继承问题,直接用类名调用父类的方法在单继承中是没有问题的,但是如果使用多继承会涉及到查找顺序(MRO).重复调用等种种问题. python ...
- B - Is It A Tree?
来源 hdu 1325 A tree is a well-known data structure that is either empty (null, void, nothing) or is a ...
- 会话管理之AbpSession
一.AbpSession的认识 在ABP中提供了IAbpSession的接口用来获取用户和租户的信息,没有使用Asp.Net中的Session,那么AbpSession到底和Session有没有关系? ...