基础_cifar10_序贯
今天的基础研究主要是在cifar10数据集上解决一下几个问题:
大图:
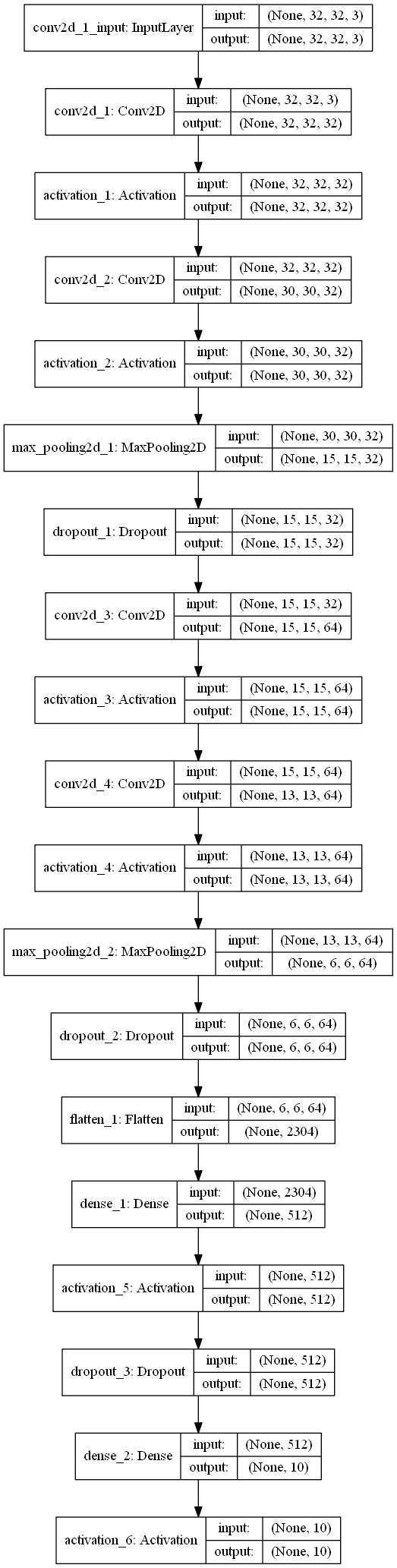
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
model2 = Sequential()
model2.add(Conv2D(32, (3, 3), padding='same',
input_shape=x_train.shape[1:]))
model2.add(Activation('relu'))
model2.add(Conv2D(32, (3, 3)))
model2.add(Activation('relu'))
model2.add(MaxPooling2D(pool_size=(2, 2)))
model2.add(Dropout(0.25))
model2.add(Flatten())
model2.add(Dense(512))
model2.add(Activation('relu'))
model2.add(Dropout(0.5))
model2.add(Dense(num_classes))
model2.add(Activation('softmax'))
到此,我认为《基础_cifar10_序贯》可以结束。
基础_cifar10_序贯的更多相关文章
- R语言︱关联规则+时间因素=序贯关联规则
序贯模型=关联规则+时间因素. 了解这个模型可以参考李明老师的<R语言与网站分析 [李明著][机械工业出版社][2014.04][446页]>,第九章,第二节的"序列模型关联分析 ...
- Keras官方中文文档:序贯模型
快速开始序贯(Sequential)模型 序贯模型是多个网络层的线性堆叠,也就是"一条路走到黑". 可以通过向Sequential模型传递一个layer的list来构造该模型: f ...
- Python机器学习笔记:深入理解Keras中序贯模型和函数模型
先从sklearn说起吧,如果学习了sklearn的话,那么学习Keras相对来说比较容易.为什么这样说呢? 我们首先比较一下sklearn的机器学习大致使用流程和Keras的大致使用流程: skl ...
- Keras之序贯(Sequential)模型
序贯模型(Sequential) 序贯模型是多个网络层的线性堆叠. 可以通过向Sequential模型传递一个layer的list来构造该模型: from Keras.models import Se ...
- web开发基础--字节序
字节是网络传输上的最小单位,是web开发中需要了解的一个知识点. 1.有效位 在谈字节序前需要先了解有效位,有效位分为两种:最低有效位(LSB: Least Significant Bit) 和最高有 ...
- socket编程基础-字节序/IP/PORT转换/域名
socket编程基础 网络IP操作函数 字符串的IP和32位的IP转换 #include <sys/socket.h> #inlcude <netinet/in.h> #inc ...
- linux 基础12-程序与资源管理
1. 基础概念 可执行的二进制文件就是程序 执行程序的时候因触发事件而获取的ID,称为PID 在登入并执行bash时,系统依据登录者的UID/GID给登录者一个PID/GPID/SID等 启动程序时, ...
- 论山寨手机与Android联姻的技术基础 【序】
山寨手机的兴起,离不开 MTK(联发科).MTK为手机制造提供了一揽子解决方案,其中既包括硬件,也包括软件.软件方面最重要的,是操作系统.MTK方案的软件的稳定性非常高,一方面是因为其硬件系统变化不大 ...
- Keras官方中文文档:序贯模型API
Sequential模型接口 如果刚开始学习Sequential模型,请首先移步这里阅读文档,本节内容是Sequential的API和参数介绍. 常用Sequential属性 model.layers ...
随机推荐
- vue父子组件写法,数据传递,顺便封装 element-ui的弹窗组建
父组件如下: <template> <div class="print"> <el-button @click="bbclick" ...
- 第二章:Opencv核心類Mat
Opecv就是做計算機視覺,就是讲图片转换成计算机所能识别的数据 Mat类中由大量的内联函数,主要就是用于提高速度. 一般类型都用rgb,存的时候用CV_8UC3.create函数一般会把原来的空间释 ...
- [IDE] ECLIPSE取消自动更新
eclipse自动更新的取消方法: window --> preferences --> General --> Startup and Shutdown --> 在列表中找到 ...
- oracle 排序 row_number() over(partition by 排序字段)
业务描述:按t.truckId,t.riskCode 分组,每个分组里有分数,取分组中分数最大的那条记录. 如:A1 B1 5 6 A1 B1 5 3 A1 B2 2 5 A1 ...
- DataX介绍
一. DataX3.0概览 DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).HDFS.Hive.ODPS.HBase.FTP等各种异构数据源之间稳定 ...
- python练习:一行搞定-统计一句话中每个单词出现的个数
一行搞定-统计一句话中每个单词出现的个数 >>> s'i am a boy a bood boy a bad boy' 方式一:>>> dict([(i,s.spl ...
- 将jar包制作成docker镜像
将jar包制作成docker镜像1.准备可运行jar包2.建立Dockerfile文件 文件内容: FROM java:8VOLUME /tmpADD xxx-sendemail-0.0.1-SNAP ...
- usb通信小结
2010-07-25 16:52:00 目前了解了usb通信层面的一些基础知识如下.如果有空还要再了解hid报告描述符及协议的数据包波形. 一,USB的一些基本概念 1. 管道(Pipe) 是主机和设 ...
- Navicat连接MySQL8.0亲测有效
今天下了个 MySQL8.0,发现Navicat连接不上,总是报错1251: 原因是MySQL8.0版本的加密方式和MySQL5.0的不一样,连接会报错. 试了很多种方法,终于找到一种可以实现的: 更 ...
- 怎样从外网访问内网Jetty?
本地安装了一个Jetty,只能在局域网内访问,怎样从外网也能访问到本地的Jetty呢?本文将介绍具体的实现步骤. 准备工作 安装并启动Jetty 默认安装的Jetty端口是8080. 实现步骤 下载并 ...