Selenium Web 自动化 - 项目实战(二)
Selenium Web 自动化 - 项目实战(二)
2016-08-08
什么是数据驱动?简答的理解就是测试数据决定了测试结果,这就是所谓数据驱动。数据驱动包含了数据,他就是测试数据,在自动化领域里,提倡数据分离,也就是说,测试用例和测试数据是分开(存储)的。
在本框架设计中,采用的是Excel存储测试数据。
1 框架更改总览
在原来的框架下更改,如下图所示

2 框架更改详解
2.1 更改用例类:LoginPage_001_LoginSuccessFunction_Test.java
下面代码中,红色字体显示出更改前后变化。更改后数据不是写在代码中,而是从excel中读取。那么怎么让读取数据,且对应用例呢?
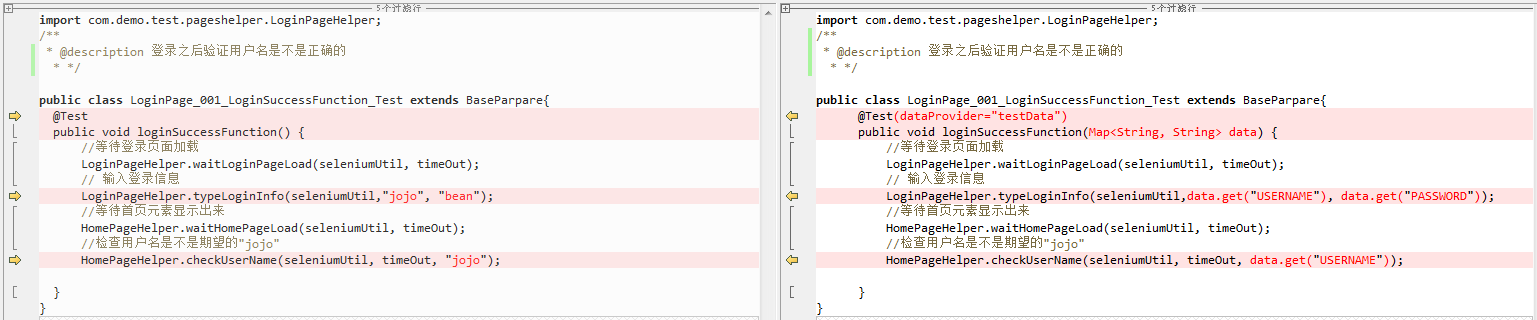
2.2 测试数据如何保存-设计excel
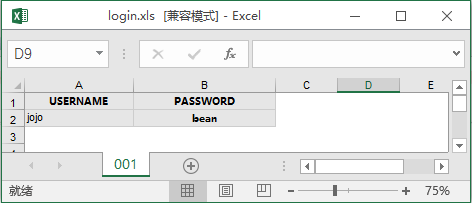
先看看如何设计excel:
excel的表名以模块名命名。excel中,有个sheet,名字为'001',对应用例编号,和设计用例的的类名第二部分是对应的,也就是说一个sheet就是一个测试用例的数据。在执行测试用例的时候,通过模块名字找到对应的excel,然后再根据对应的用例编号找到对应的sheet,最后在读取excel数据。
2.3 通过数据提供者获取测试数据
通过数据提供者(@DataProvider)来传递给测试用例,这里将数据提供者代码放置在BaseParpare.java中,目的是为了每次运行一个用例都会读取对应的测试用例。
/**
* 测试数据提供者 - 方法
* */
@DataProvider(name = "testData")
public Iterator<Object[]> dataFortestMethod() throws IOException {
String moduleName = null; // 模块的名字
String caseNum = null; // 用例编号
String className = this.getClass().getName();
int dotIndexNum = className.indexOf("."); // 取得第一个.的index
int underlineIndexNum = className.indexOf("_"); // 取得第一个_的index if (dotIndexNum > 0) {
moduleName = className.substring(24, className.lastIndexOf(".")); // 取到模块的名称
} if (underlineIndexNum > 0) {
caseNum = className.substring(underlineIndexNum + 1, underlineIndexNum + 4); // 取到用例编号
}
//将模块名称和用例的编号传给 ExcelDataProvider ,然后进行读取excel数据
return new ExcelDataProvider(moduleName, caseNum);
}
2.4读取Excel的方法
ExcelDataProvider.java,代码如下:
package com.demo.test.utils; import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map; import jxl.Cell;
import jxl.Sheet;
import jxl.Workbook; import org.apache.log4j.Logger;
import org.testng.Assert; /**
* @author young
* @description: 读取Excel数据<br>
* 说明:<br>
* Excel放在Data文件夹下<br>
* Excel命名方式:测试类名.xls<br>
* Excel的sheet命名方式:测试方法名<br>
* Excel第一行为Map键值<br>
*/
public class ExcelDataProvider implements Iterator<Object[]> { private Workbook book = null;
private Sheet sheet = null;
private int rowNum = 0;
private int currentRowNo = 0;
private int columnNum = 0;
private String[] columnnName;
private String path = null;
private InputStream inputStream = null;
public static Logger logger = Logger.getLogger(ExcelDataProvider.class.getName()); /*
* @description
* 2个参数:<br>
* moduleName - 模块的名称
* caseNum - 测试用例编号
**/
public ExcelDataProvider(String moduleName, String caseNum) { try {
//文件路径
path = "data/" + moduleName + ".xls";
inputStream = new FileInputStream(path); book = Workbook.getWorkbook(inputStream);
// sheet = book.getSheet(methodname);
sheet = book.getSheet(caseNum); // 读取第一个sheet
rowNum = sheet.getRows(); // 获得该sheet的 所有行
Cell[] cell = sheet.getRow(0);// 获得第一行的所有单元格
columnNum = cell.length; // 单元格的个数 值 赋给 列数
columnnName = new String[cell.length];// 开辟 列名的大小 for (int i = 0; i < cell.length; i++) {
columnnName[i] = cell[i].getContents().toString(); // 第一行的值
// 被赋予为列名
}
this.currentRowNo++; } catch (FileNotFoundException e) {
logger.error("没有找到指定的文件:" + "[" + path + "]");
Assert.fail("没有找到指定的文件:" + "[" + path + "]");
} catch (Exception e) {
logger.error("不能读取文件: [" + path + "]",e);
Assert.fail("不能读取文件: [" + path + "]");
}
}
/**是否还有下个内容*/ public boolean hasNext() { if (this.rowNum == 0 || this.currentRowNo >= this.rowNum) { try {
inputStream.close();
book.close();
} catch (Exception e) {
e.printStackTrace();
}
return false;
} else {
// sheet下一行内容为空判定结束
if ((sheet.getRow(currentRowNo))[0].getContents().equals(""))
return false;
return true;
}
}
/**返回内容*/
public Object[] next() { Cell[] c = sheet.getRow(this.currentRowNo); Map<String, String> data = new HashMap<String, String>(); for (int i = 0; i < this.columnNum; i++) { String temp = ""; try {
temp = c[i].getContents().toString();
} catch (ArrayIndexOutOfBoundsException ex) {
temp = "";
} data.put(this.columnnName[i], temp);
}
Object object[] = new Object[1];
object[0] = data;
this.currentRowNo++;
return object;
} public void remove() {
throw new UnsupportedOperationException("remove unsupported.");
}
}
Pom.xml添加jar依赖:
<dependency>
<groupId>net.sourceforge.jexcelapi</groupId>
<artifactId>jxl</artifactId>
<version>2.6.12</version>
<scope>provided</scope>
</dependency>
Selenium Web 自动化 - 项目实战(二)的更多相关文章
- Selenium Web 自动化 - 项目实战(三)
Selenium Web 自动化 - 项目实战(三) 2016-08-10 目录 1 关键字驱动概述2 框架更改总览3 框架更改详解 3.1 解析新增页面目录 3.2 解析新增测试用例目录 3. ...
- Selenium Web 自动化 - 项目实战环境准备
Selenium Web 自动化 - 项目实战环境准备 2016-08-29 目录 1 部署TestNG 1.1 安装TestNG 1.2 添加TestNG类库2 部署Maven 2.1 mav ...
- Selenium Web 自动化 - 项目实战(一)
Selenium Web 自动化 - 测试框架(一) 2016-08-05 目录 1 框架结构雏形2 把Java项目转变成Maven项目3 加入TestNG配置文件4 Eclipse编码修改5 编写代 ...
- Selenium Web 自动化 - 项目持续集成(进阶)
Selenium Web 自动化 - 项目持续集成(进阶) 2017-03-09 目录 1 背景及目标2 环境配置 2.1 SVN的安装及使用 2.2 新建Jenkins任务3 过程分析 1 背景 ...
- Selenium Web 自动化 - 项目持续集成
Selenium Web 自动化 - 项目持续集成 2017-02-13 目录 1环境准备 1.1 安装git 1.2 安装jenkins 1.3 安装jenkins插件 1.4 jekins ...
- appium+python自动化项目实战(二):项目工程结构
废话不多说,直接上图: nose.cfg配置文件里,可以指定执行的测试用例.生成测试报告等.以后将详细介绍.
- Selenium Web 自动化
1 Selenium Web 自动化 - Selenium(Java)环境搭建 2 Selenium Web 自动化 - 如何找到元素 3 Selenium Web 自动化 - Selenium常用A ...
- selenium(12)-web UI自动化项目实战(PO模式,代码封装)
web UI自动化项目实战-项目 项目使用禅道,所以你需要搭建1个禅道,搭建禅道的方法和步骤见 https://www.cnblogs.com/xinhua19/p/13151296.html 搭建U ...
- RobotFramework自动化测试框架-Selenium Web自动化(二)关于在RobotFramework中如何使用Selenium很全的总结(上)
好久没有继续分享关于自动化测试相关的东西了,自动化在现今的测试领域已经越来越重要了,大部分公司在测试岗位招聘中都需要会相关的自动化测试知识.而 RobotFramework自动化测试框架 是自动化测试 ...
随机推荐
- 教程:在 Visual Studio 中开始使用 Flask Web 框架
教程:在 Visual Studio 中开始使用 Flask Web 框架 Flask 是一种轻量级 Web 应用程序 Python 框架,为 URL 路由和页面呈现提供基础知识. Flask 被称为 ...
- macos下mongoDB 3.4.5 添加用户、设置权限
macos下mongoDB 3.4.5 添加用户.设置权限 在项目中需要根据项目运行环境访问,以不同的身份访问各自的db,所以研究了一下MongoDB的 需求: 给MongoDB添加两个用户分别用 ...
- springboot项目接入配置中心,实现@ConfigurationProperties的bean属性刷新方案
前言 配置中心,通过key=value的形式存储环境变量.配置中心的属性做了修改,项目中可以通过配置中心的依赖(sdk)立即感知到.需要做的就是如何在属性发生变化时,改变带有@Configuratio ...
- Flag之2019年立
今天是2019年1月12日,这是我第一次在一个公众的平台上立flag. 至于为何想立一个flag,应该是因为自己年龄渐长,从儿时读书时代家人对自己的要求就不高,考试可以及格即可,导致了自己养成了比较安 ...
- iOS 11开发教程(二十一)iOS11应用视图美化按钮之实现按钮的响应(1)
iOS 11开发教程(二十一)iOS11应用视图美化按钮之实现按钮的响应(1) 按钮主要是实现用户交互的,即实现响应.按钮实现响应的方式可以根据添加按钮的不同分为两种:一种是编辑界面添加按钮实现的响应 ...
- JSONObject基本内容(三)
参考资料:http://swiftlet.net/archives/category/json 十分感谢!!!~~ 第三篇的内容,主要讲述的有两点: 1 .如何获取JSONObject中对应ke ...
- 连接池commons-pool2
commons-pool2池技术可以应用在对象上构建对象池,也可以用在http连接或者netty连接 构建连接池,池技术为了节省对象创建销毁或连接资源频繁申请销毁带来的时间消费. 当用于连接池在进行扩 ...
- BZOJ.1497.[NOI2006]最大获利(最小割 最大权闭合子图Dinic)
题目链接 //裸最大权闭合子图... #include<cstdio> #include<cctype> #include<algorithm> #define g ...
- [AGC025B]RGB Coloring
[AGC025B]RGB Coloring 题目大意: 有\(n(n\le3\times10^5)\)个格子,每个格子可以选择涂成红色.蓝色.绿色或不涂色,三种颜色分别产生\(a,b,a+b(a,b\ ...
- Android的onLayout、layout方法讲解
onLayout方法是ViewGroup中子View的布局方法,用于放置子View的位置.放置子View很简单,只需在重写onLayout方法,然后获取子View的实例,调用子View的layout方 ...