InnoDB存储引擎介绍-(6) 一. Innodb Antelope 和Barracuda区别
分类
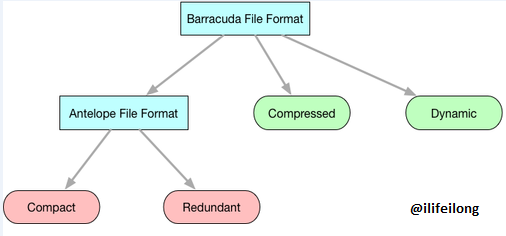
Antelope是innodb-base的文件格式,Barracude是innodb-plugin后引入的文件格式,同时Barracude也支持Antelope文件格式。两者区别在于:
| 文件格式 | 支持行格式 | 特性 |
| Antelope(Innodb-base) | ROW_FORMAT=COMPACT
ROW_FORMAT=REDUNDANT |
Compact和redumdant的区别在就是在于首部的存存内容区别。
compact的存储格式为首部为一个非NULL的变长字段长度列表 redundant的存储格式为首部是一个字段长度偏移列表(每个字段占用的字节长度及其相应的位移)。 在Antelope中对于变长字段,低于768字节的,不会进行overflow page存储,某些情况下会减少结果集IO. |
| Barracuda(innodb-plugin) | ROW_FORMAT=DYNAMIC
ROW_FORMAT=COMPRESSED |
这两者主要是功能上的区别功能上的。 另外在行里的变长字段和Antelope的区别是只存20个字节,其它的overflow page存储。
另外这两都需要开启innodb_file_per_table=1 (这个特性对一些优化还是很有用的) |
备注:
这里有一点需要注意,如果要使用压缩,一定需要先使用innodb_file_format =Barracuda格式,不然没作用。
下面我们看一下区别:
(none)>SHOW VARIABLES LIKE 'innodb_file_format%';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| innodb_file_format | Antelope |
| innodb_file_format_check | ON |
| innodb_file_format_max | Antelope |
+--------------------------+----------+
3 rows in set (0.01 sec) (none)>use wubx;
Database changed
wubx> CREATE TABLE t1
-> (c1 INT PRIMARY KEY)
-> ROW_FORMAT=COMPRESSED
-> KEY_BLOCK_SIZE=8;
Query OK, 0 rows affected, 4 warnings (0.32 sec)
报出来4个warnings查看一下报错:
wubx>show warnings;
+---------+------+-----------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------------------------------------+
| Warning | 1478 | InnoDB: KEY_BLOCK_SIZE requires innodb_file_format > Antelope. |
| Warning | 1478 | InnoDB: ignoring KEY_BLOCK_SIZE=8. |
| Warning | 1478 | InnoDB: ROW_FORMAT=COMPRESSED requires innodb_file_format > Antelope. |
| Warning | 1478 | InnoDB: assuming ROW_FORMAT=COMPACT. |
+---------+------+-----------------------------------------------------------------------+
4 rows in set (0.00 sec)
从以上报错可以看出来不支持压缩。但看一下表结构如下:
wubx>show create table t1;
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`c1` int(11) NOT NULL,
PRIMARY KEY (`c1`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8 |
+-------+-------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec) wubx>show table status like 't1'\G
*************************** 1. row ***************************
Name: t1
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 0
Avg_row_length: 0
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2017-08-19 16:41:17
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options: row_format=COMPRESSED KEY_BLOCK_SIZE=8
Comment:
1 row in set (0.00 sec)
这个是比较坑的地方,所以在使用压缩需要注意。
wubx>create table t2 ( c1 int(11) NOT NULL, primary key(c1));
Query OK, 0 rows affected (0.21 sec) wubx>insert into t2 select * from t1;
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
创建支持压缩的表:
wubx>SET GLOBAL innodb_file_format=Barracuda;
Query OK, 0 rows affected (0.00 sec) wubx>CREATE TABLE t3 (c1 INT PRIMARY KEY) ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
Query OK, 0 rows affected (0.13 sec) wubx>show table status like 't3'\G
*************************** 1. row ***************************
Name: t3
Engine: InnoDB
Version: 10
Row_format: Compressed
Rows: 0
Avg_row_length: 0
Data_length: 8192
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2017-08-19 16:50:09
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options: row_format=COMPRESSED KEY_BLOCK_SIZE=8
Comment:
1 row in set (0.00 sec)
InnoDB存储引擎介绍-(6) 一. Innodb Antelope 和Barracuda区别的更多相关文章
- InnoDB存储引擎介绍-(6) 二. Innodb Antelope文件格式
InnoDB存储引擎和大多数数据库一样(如Oracle和Microsoft SQL Server数据库),记录是以行的形式存储的.这意味着页中保存着表中一行行的数据.到MySQL 5.1时,InnoD ...
- 关于MySql 数据库InnoDB存储引擎介绍
熟悉MySQL的人,都知道InnoDB存储引擎,如大家所知,Redo Log是innodb的核心事务日志之一,innodb写入Redo Log后就会提交事务,而非写入到Datafile.之后innod ...
- mysql innodb存储引擎介绍
innodb存储引擎1.存储:数据目录.有配置参数为“ innodb_data_home_dir ” .“ innodb_data_file_path ” 和 “innodb_log_group_ho ...
- InnoDB存储引擎介绍-(5) Innodb逻辑存储结构
如果创建表时没有显示的定义主键,mysql会按如下方式创建主键: 首先判断表中是否有非空的唯一索引,如果有,则该列为主键. 如果不符合上述条件,存储引擎会自动创建一个6字节大小的指针. 当表中有多个非 ...
- InnoDB存储引擎介绍-(4)Checkpoint机制二
原文链接 http://www.cnblogs.com/chenpingzhao/p/5107480.html 一.简介 思考一下这个场景:如果重做日志可以无限地增大,同时缓冲池也足够大,那么是不需要 ...
- InnoDB存储引擎介绍-(2)redo和undo学习
01 – Undo LogUndo Log 是为了实现事务的原子性,在MySQL数据库InnoDB存储引擎中,还用Undo Log来实现多版本并发控制(简称:MVCC). - 事务的原子性(Atomi ...
- InnoDB存储引擎介绍-(1)InnoDB存储引擎结构
首先以一张图简单展示 InnoDB 的存储引擎的体系架构. 从图中可见, InnoDB 存储引擎有多个内存块,这些内存块组成了一个大的内存池,主要负责如下工作: 维护所有进程/线程需要访问的多个内部数 ...
- mysql之innodb存储引擎介绍
一.Innodb体系架构 1.1.后台线程 后台任务主要负责刷新内存中的数据,保证缓冲池的数据是最近的数据,此外还将修改的数据刷新到文件磁盘,保证在数据库发生异常的情况下Innodb能恢复到正常的运行 ...
- MySQL技术内幕InnoDB存储引擎(二)——InnoDB存储引擎
1.概述 是一个高性能.高可用.高扩展的存储引擎. 2.InnoDB体系架构 InnoDB存储引擎主要由内存池和后台线程构成. 其中,内存池由许多个内存块组成,作用如下: 维护所有进程和线程需要访问的 ...
随机推荐
- 洛谷P2362 围栏木桩----dp思路
在翻dp水题的时候找到的有趣的题0v0 原文>>https://www.luogu.org/problem/show?pid=2362<< 题目描述 某农场有一个由按编号排列的 ...
- Android之使用传感器获取相应数据
Android的大部分手机中都有传感器,传感器类型有方向.加速度(重力).光线.磁场.距离(临近性).温度等. 方向传感器: Sensor.TYPE_ORIENTATION 加速度(重力)传感器: ...
- React Native 组建之IOS和Android通用抽屉
/** * Sample React Native App * https://github.com/facebook/react-native * @flow *npm:https://www.np ...
- 【BZOJ】4542: [Hnoi2016]大数
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=4542 给定一个由数字构成的字符串${S_{1,2,3,...,n}}$,一个正素数$P$, ...
- 学习笔记16—Matlab 基础集
1.常用相关 [r, p] = corr(X,Y), [r, p] = partialcorr(X,Y, Z) , 其中Z是协变量. 2.TD_age = importdata('F:\BrainAg ...
- Python中什么是变量
在Python中,变量的概念基本上和初中代数的方程变量是一致的. 例如,对于方程式 y=x*x ,x就是变量.当x=2时,计算结果是4,当x=5时,计算结果是25. 只是在计算机程序中,变量不仅可以是 ...
- shell和shell脚本基本知识
详情可见: https://www.cnblogs.com/yinheyi/p/6648242.html 这张图,可以帮助我们理解这个词语! 最底下是计算机硬件,然后硬件被系统核心包住,在系统核心外层 ...
- gradle ----> 安装和使用
1.安装gradle 参考官网教程:https://gradle.org/install/ 安装的前提:要求安装jdk1.7或者以上 比较重要的一步:配置环境变量,把gradle的bin目录的全路径配 ...
- python paramiko自动登录网络设备抓取配置信息
ssh = paramiko.SSHClient()ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())ssh.connect(hostn ...
- Nginx安装与使用 及在redhat 中的简单安装方式
首先说下在redhat中的安装方法, 正常安装nginx 需要安装很多的依赖,最后再安装nginx,而且很容易出错. 在nginx官方上有这么一段描述: Pre-Built Packages for ...