MapReduce-实践1
MR进阶实践1: -file 分发多个文件
【-file 适合场景】分发文件在本地,小文件
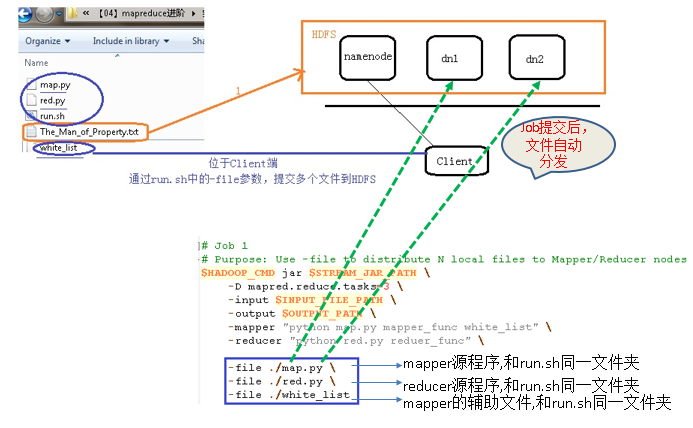
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar"
INPUT_FILE_PATH="/02_filedistribute_input/The_Man_of_Property.txt"
OUTPUT_PATH="/02_filedistribute_output"
$HADOOP_CMD fs -rmr-skipTrash $OUTPUT_PATH
# job1: use -file to distribute local file to cluster
# these files will bestored in the same directory in each datanode
$HADOOP_CMD jar$STREAM_JAR_PATH \
-input $INPUT_FILE_PATH \
-output $OUTPUT_PATH \
-mapper "python map.py mapper_funcwhite_list" \
-reducer "python red.pyreducer_func" \
-file ./map.py \
-file ./red.py \
-file ./white_list
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar"
INPUT_FILE_PATH="/02_filedistribute_input/The_Man_of_Property.txt"
OUTPUT_PATH="/02_filedistribute_output"
$HADOOP_CMD fs -rmr-skipTrash $OUTPUT_PATH
# job1: use -file todistribute files
# these files will be stored in the same directory in each datanode
$HADOOP_CMD jar$STREAM_JAR_PATH \
-input $INPUT_FILE_PATH \
-output $OUTPUT_PATH \
-mapper "python map.py mapper_funcwhite_list" \
-reducer "pythonred.py reducer_func" \
-jobconf “mapred.reduce.tasks=” \ # deprecated option, not suggested
-file ./map.py \
-file ./red.py \
-file ./white_list
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar"
INPUT_FILE_PATH="/02_filedistribute_input/The_Man_of_Property.txt"
OUTPUT_PATH="/02_filedistribute_output"
$HADOOP_CMD fs -rmr-skipTrash $OUTPUT_PATH
# job1: use -file todistribute files
# these files will bestored in the same directory in each datanode
$HADOOP_CMD jar$STREAM_JAR_PATH \
-D mapred.reduce.tasks= \
-input $INPUT_FILE_PATH \
-output $OUTPUT_PATH \
-mapper "python map.py mapper_funcwhite_list" \
-reducer "pythonred.py reducer_func" \
-file ./map.py \
-file ./red.py \
-file ./white_list

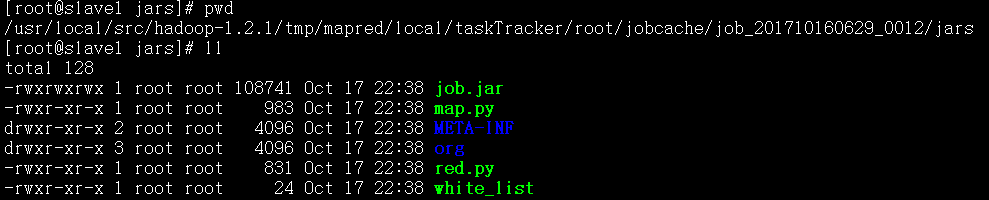

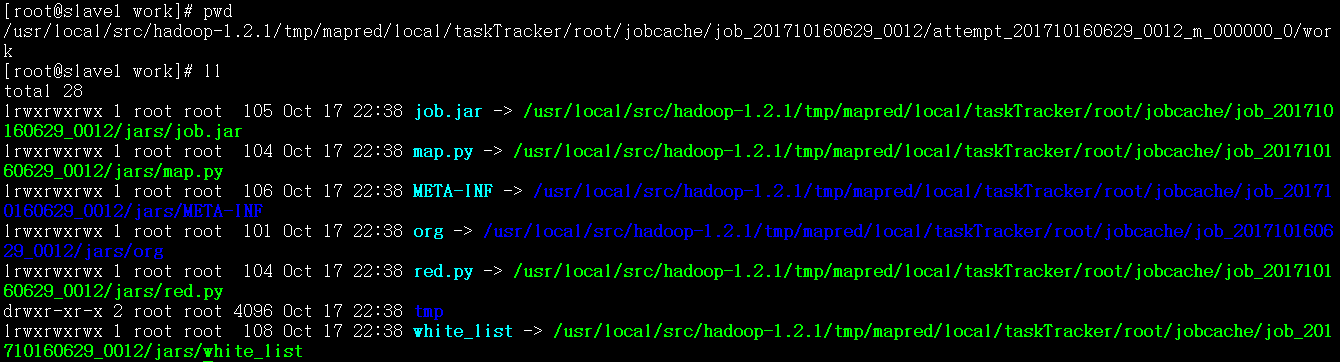
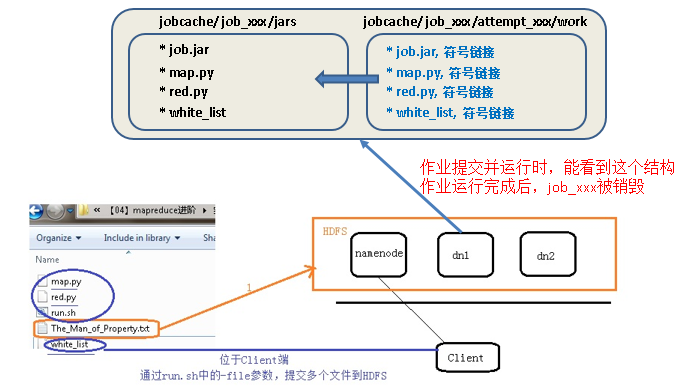
MR进阶实践2: -cacheFile 将放在HFDS上的文件分发给计算节点
# hadoop fs -put ./white_list /
# rm -rf ./white_list
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar"
INPUT_FILE_PATH="/03_cachefiledistribute_input/The_Man_of_Property.txt"
OUTPUT_PATH="/03_cachefiledistribute_output"
$HADOOP_CMD fs -rmr-skipTrash $OUTPUT_PATH
# job2: use -cacheFileto distribute HDFS file to compute node
$HADOOP_CMD jar$STREAM_JAR_PATH \
-input $INPUT_FILE_PATH \
-output $OUTPUT_PATH \
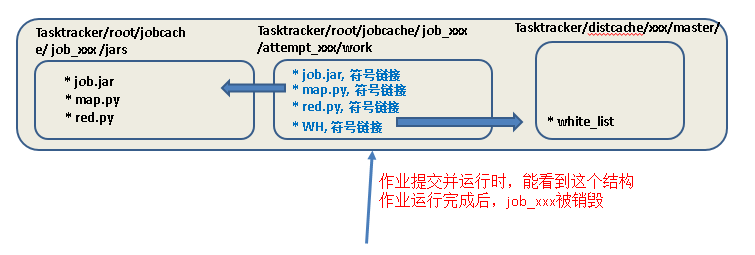
-mapper "python map.py mapper_func WH" \
#这里也一定要用WH符号链接,因为作业开始运行后创建的attemps目录中只能看到WH,和map.py符号链接位于同一目录
-reducer "pythonred.py reducer_func" \
-cacheFile “hdfs://master:9000/white_list#WH”
#WH一定要,每个attemp中要生成该符号链接,指向Tasktracer/distcache中的whitelist
-file ./map.py \
-file ./red.py
MR进阶实践3: -cacheArchive 将位于HFDS上的压缩文件分发给计算节点
# hadoop fs –put ./w.tar.gz / # hadoop fs –ls /
查看是否已经上传成功
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar"
INPUT_FILE_PATH="/03_cachefiledistribute_input/The_Man_of_Property.txt"
OUTPUT_PATH="/03_cachefiledistribute_output"
$HADOOP_CMD fs -rmr-skipTrash $OUTPUT_PATH
# job3: use -cacheArchive to distribute HDFS compressed file to compute node
$HADOOP_CMD jar$STREAM_JAR_PATH \
-input $INPUT_FILE_PATH \
-output $OUTPUT_PATH \
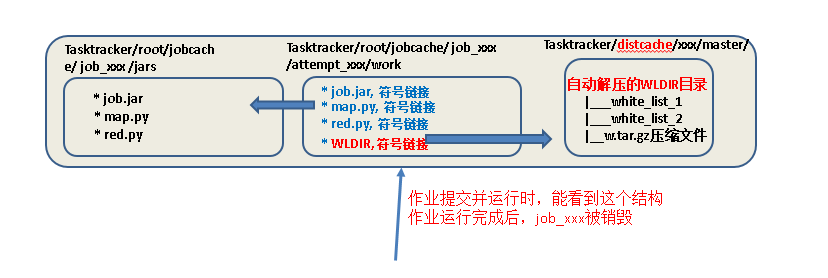
-mapper "python map.py mapper_func WLDIR" \
#这里也一定要用WH.gz符号链接名,因为attemps中只能看到WH.gz
-reducer "pythonred.py reducer_func" \
-cacheArchive “hdfs://master:9000/w.tar.gz#WLDIR”
#WLDIR一定要,每个attemp中要生成该符号链接,指向Tasktracer/distcache中已经自动解压的文件夹,文件夹中有white_list_1,white_list_2
-file ./map.py \
-file ./red.py
MapReduce-实践1的更多相关文章
- 大数据系列之分布式计算批处理引擎MapReduce实践-排序
清明刚过,该来学习点新的知识点了. 上次说到关于MapReduce对于文本中词频的统计使用WordCount.如果还有同学不熟悉的可以参考博文大数据系列之分布式计算批处理引擎MapReduce实践. ...
- 大数据系列之分布式计算批处理引擎MapReduce实践
关于MR的工作原理不做过多叙述,本文将对MapReduce的实例WordCount(单词计数程序)做实践,从而理解MapReduce的工作机制. WordCount: 1.应用场景,在大量文件中存储了 ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- Hadoop MapReduce开发最佳实践(上篇)
body{ font-family: "Microsoft YaHei UI","Microsoft YaHei",SimSun,"Segoe UI& ...
- 化繁为简(三)—探索Mapreduce简要原理与实践
目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapreduce.演示Mapreduce例子程序 ...
- MapReduce 原理与 Python 实践
MapReduce 原理与 Python 实践 1. MapReduce 原理 以下是个人在MongoDB和Redis实际应用中总结的Map-Reduce的理解 Hadoop 的 MapReduce ...
- 【原创 Hadoop&Spark 动手实践 3】Hadoop2.7.3 MapReduce理论与动手实践
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop化繁为简(三)—探索Mapreduce简要原理与实践
目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapreduce.演示Mapreduce例子程序 ...
- [转] Hadoop MapReduce开发最佳实践(上篇)
前言 本文是Hadoop最佳实践系列第二篇,上一篇为<Hadoop管理员的十个最佳实践>. MapRuduce开发对于大多数程序员都会觉得略显复杂,运行一个WordCount(Hadoop ...
- Mapreduce简要原理与实践
探索Mapreduce简要原理与实践 目录-探索mapreduce 1.Mapreduce的模型简介与特性?Yarn的作用? 2.mapreduce的工作原理是怎样的? 3.配置Yarn与Mapred ...
随机推荐
- Java第十一周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多线程相关内容. 2. 书面作业 本次PTA作业题集多线程 1.互斥访问与同步访问 完成题集4-4(互斥访问)与4-5(同步访问) ...
- java课程设计-猜数游戏(201521123029 郑佳明)
1.团队课程设计博客链接 http://www.cnblogs.com/m1ng123/p/7056740.html 2.个人负责模板或任务说明 猜数运行3个主界面即相关功能 玩家信息存储的play类 ...
- linux crontab详解
服务的启动和停止 cron服务是linux的内置服务,但它不会开机自动启动.可以用以下命令启动和停止服务: /sbin/service crond start /sbin/service crond ...
- Activiti-03-query api
Query API 有两种方式从引擎中查询数据, 查询 API 和本地查询. API方式: List<Task> tasks = taskService.createTaskQuery ...
- mysql数据库-注释相关介绍
mysql执行的sql脚本中注释怎么写? mysql 服务器支持 # 到该行结束.-- 到该行结束 以及 /* 行中间或多个行 */ 的注释方格: mysql; # 这个注释直到该行结束 mysql; ...
- [js高手之路] es6系列教程 - Set详解与抽奖程序应用实战
我们还是从一些现有的需求和问题出发,为什么会有set,他的存在是为了解决什么问题? 我们看一个这样的例子,为一个对象添加键值对 var obj = Object.create( null ); obj ...
- oracle存储过程中is和as区别
在存储过程(PROCEDURE)和函数(FUNCTION)中没有区别:在视图(VIEW)中只能用AS不能用IS:在游标(CURSOR)中只能用IS不能用AS.
- oracle 例外
一.例外分类oracle将例外分为预定义例外.非预定义例外和自定义例外三种.1).预定义例外用于处理常见的oracle错误.2).非预定义例外用于处理预定义例外不能处理的例外.3).自定义例外用于处理 ...
- 详解 HTTPS 移动端对称加密套件优
近几年,Google.Baidu.Facebook 等互联网巨头大力推行 HTTPS,国内外的大型互联网公司很多也都已启用全站 HTTPS. Google 也推出了针对移动端优化的新型加密套件 Cha ...
- 不可不知的socket和TCP连接过程
html { font-family: sans-serif } body { margin: 0 } article,aside,details,figcaption,figure,footer,h ...