python爬虫xpath
又是一个大晴天,因为马上要召开十九大,北京地铁就额外的拥挤,人贴人到爆炸,还好我常年挤地铁早已练成了轻功水上漂,挤地铁早已经不在话下。
励志成为一名高级测试工程师的我,目前还只是个菜鸟,难得有机会,公司辞职的爬虫大佬教了我下爬虫,故借此机会分享给那些小白,
此篇只是简单爬取了小说的标题,没有涉及到框架,还望各位大佬海涵!!
环境准备:
pycharm(撩妹神器,人手一个) lxml(python的三方库)
如果电脑里没有安装lxml的伙伴,可以安装一下,在控制台输入pip intall https://pypi.douban.com/simple lxml,
利用国外的源下载比较慢,我一般用国内的这个源下载,如果有更好的,欢迎各位留个脚印,么么哒
如果你输入pip show lxml出现像我这样的界面,咦咦咦,厉害了,说明你离走向爬虫大师,差的不是一心半点了

导入文件:
好的,既然这样,说搞就搞,小白们,扑上来吧,要那种纯小白的,哈哈
在pycharm里边新建一个py文件
然后引入requests(请求库),以及lxml里边的etree,如下图

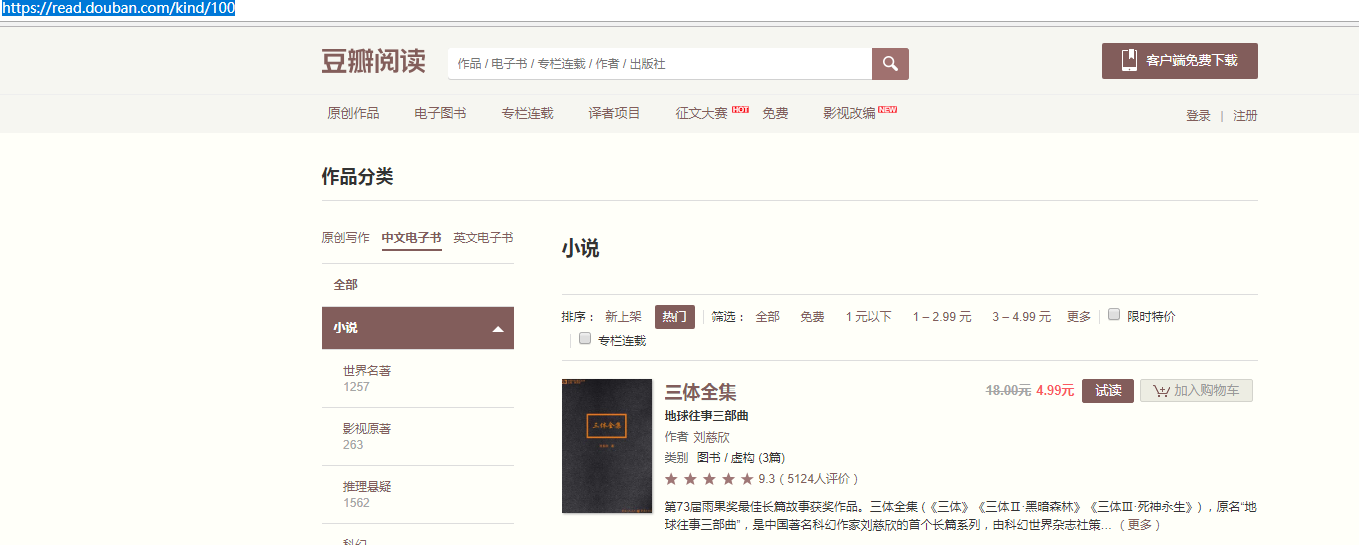
我们先打开豆瓣图书的一个网址,网址是“https://read.douban.com/kind/100”,如下图所示
定位爬取:
现在要做的就是去爬取“三体全集”,“评分”以及“小说简介”这三个内容,可是怎么爬呢,那就要用到了xpath这个定位利器,用过的人都说好,他好我也好! //坏笑,坏笑
1.首先利用request进行get请求:

2.然后我们利用请求回来的r.content进行解析

3.下面重点来了,我们解析后的数据进行打印


我们可以知道这个html对象的位置,下面我们就要利用xpath去进行定位
在豆瓣网阅读的网页,我们点击F12,然后点击控制台的箭头,点击一下页面上的三体全集,我们就可以找到该元素的位置了
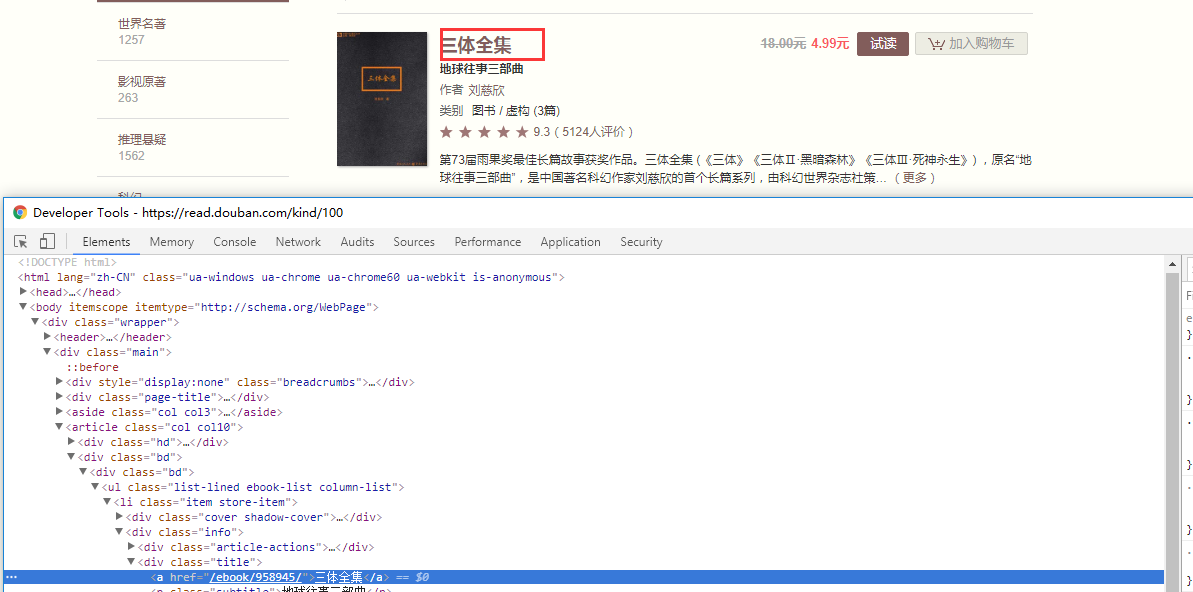
在锁定位置点击右键,找到Copy,点击Copy Xpath,然后在pycharm进行定位打印

其中利用content调用xpath方法,里边写上刚才copy好的位置,后边加一个text(),然后进行取[0],
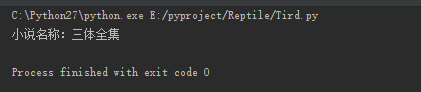
然后运行一下,what fuck,出现了什么,三体全集被打印了,还TM的有这种操作,是在逗我吗!!
评分以及简介同样如此,如果我们想打印多个小说的这些属性,通过定位不难发现,他们是有规律的,我们可以进行循环赋值进行打印,这样就会出现如下所示

感谢各位的阅读,此篇过于简单,只是自己喜欢写写东西玩,如果能给您带来乐趣,那将是我的荣幸,祝各位前程似锦,工作顺利!!
源码如下:
#coding=utf-8
import requests
from lxml import etree
def ReptileDouBan(url):
r = requests.get(url)
#print r.content
content = etree.HTML(r.content)
print content
for i in range(1,20):
print u"小说名称:" + content.xpath("/html/body/div/div/article/div[2]/div[1]/ul/li[%d]/div[2]/div[2]/a/text()" %i)[0]
#print u"小说备注:" + content.xpath("/html/body/div/div/article/div[2]/div[1]/ul/li[%d]/div[2]/div[2]/p/text()" %i)[0]
print u"评分:" + content.xpath("/html/body/div/div/article/div[2]/div[1]/ul/li[%d]/div[2]/div[3]/span[2]/text()" %i)[0]
print u"介绍:" + content.xpath("/html/body/div/div/article/div[2]/div[1]/ul/li[%d]/div[2]/div[4]/text()" %i)[0]
if __name__ == '__main__':
url = "https://read.douban.com/kind/100"
ReptileDouBan(url)
python爬虫xpath的更多相关文章
- python爬虫xpath的语法
有朋友问我正则,,okey,其实我的正则也不好,但是python下xpath是相对较简单的 简单了解一下xpath: XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XML ...
- Python爬虫 XPath语法和lxml模块
XPath语法和lxml模块 什么是XPath? xpath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历. X ...
- python爬虫----XPath
1.知道本节点元素,如何定位到兄弟元素 详情见博客 XML代码见下 bt1在文档中只出现一次,所以很容易获取到bt1中内容,那怎么根据<td class='bt1'>来获取bt2中的内容 ...
- Python爬虫 | xpath的安装
错误信息:程序包无效.详细信息:“Cannot load extension with file or directory name . Filenames starting with "& ...
- python爬虫前提技术
1.BeautifulSoup 解析html如何使用 转自:http://blog.csdn.net/u013372487/article/details/51734047 #!/usr/bin/py ...
- Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(1)
一.数据类型及解析方式 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为两部分,非结构化的数据 和 结构化的数据. 非结构化数据:先有数据,再有结构, 结构化数 ...
- Python爬虫教程-22-lxml-etree和xpath配合使用
Python爬虫教程-22-lxml-etree和xpath配合使用 lxml:python 的HTML/XML的解析器 官网文档:https://lxml.de/ 使用前,需要安装安 lxml 包 ...
- 小白学 Python 爬虫(19):Xpath 基操
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- 【框架学习与探究之定时器--Quartz.Net 】
声明 本文欢迎转载,原文地址:http://www.cnblogs.com/DjlNet/p/7572174.html 前言 这里相信大部分玩家之前现在都应该有过使用定时器的时候或者需求,例如什么定时 ...
- Codeforce 854 A. Fraction
A. Fraction time limit per test 1 second memory limit per test 512 megabytes input standard input ou ...
- BZOJ1059_矩阵游戏_KEY
1059: [ZJOI2007]矩阵游戏 Time Limit: 10 Sec Memory Limit: 162 MB Description 小Q是一个非常聪明的孩子,除了国际象棋,他还很喜欢玩一 ...
- oracle 常用函数汇总
一.字符函数字符函数是oracle中最常用的函数,我们来看看有哪些字符函数:lower(char):将字符串转化为小写的格式.upper(char):将字符串转化为大写的格式.length(char) ...
- 详解AngularJS中的依赖注入
点击查看AngularJS系列目录 依赖注入 一般来说,一个对象只能通过三种方法来得到它的依赖项目: 我们可以在对象内部创建依赖项目 我们可以将依赖作为一个全局变量来进行查找或引用 我们可以将依赖传递 ...
- JAVA多线程---wait() & join()
题外话: interrupt()方法 并不能中断一个正常运行的线程!!! class myThread extends Thread{ @Override public void run(){ fo ...
- HDFS概述(2)————Block块大小设置
以下内容转自:http://blog.csdn.net/samhacker/article/details/23089157?utm_source=tuicool&utm_medium=ref ...
- ASP.NET没有魔法——ASP.NET与数据库
在之前的文章中介绍了使用ASP.NET MVC来开发一个博客系统,并且已将初具雏形,可以查看文章列表页面,也可以点击文章列表的其中一篇文章查看详情,这已经完成了最开始需求分析的读者的查看列表和查看文章 ...
- vue 实现 换一换 功能
点击按钮列表页随机获取三个商品并渲染 后台返回的数据为 d为一个数组 数组 arr=[0,1,2]初始值 data:{ list:d, arr:[0,1,2] } 生产随机数 replace:func ...
- c# Linq操作XML,查找节点数据
/*查找XML*/ var filePath = Server.MapPath("~/xml/sample.xml"); XDocument doc = XDocument.Loa ...