zookeeper的安装与配置
单机模式:
1、首先去官网下载zookeeper的包 zookeeper-3.4.10.tar.gz
2、用FTP上传到服务器或者Linux虚拟机的/usr/local目录下
3、解压文件tar -zxvf zookeeper-3.4.10.tar.gz
4、在conf文件夹下新建zoo.cfg文件,或者使用里面自带的zoo_sample.cfg,重新cp zoo_sample.cfg zoo.cfg
zoo.cfg文件内容:
tickTime=2000
dataDir=/Users/zookeeper/data
dataLogDir=/Users/zookeeper/logs
clientPort=4180
至此, zookeeper的单机模式已经配置好了. 启动server只需运行脚本:
5、运行server脚本
./zkServer.sh start
6、Server启动之后, 就可以启动client连接server了, 执行脚本:
./zkCli.sh -server localhost:4180
(本次操作还是在本server上操作,你看localhost了嘛)
伪集群模式:
所谓伪集群, 是指在单台机器中启动多个zookeeper进程, 并组成一个集群. 以启动3个zookeeper进程为例.
1、首先去官网下载zookeeper的包 zookeeper-3.4.10.tar.gz
2、用FTP文上传到/usr/local下
3、解压文件tar -zxvf zookeeper-3.4.10.tar.gz
4、复制3分zookeeper文件
cp -r zookeeper-3.4.10.tar.gz zookeeper0
cp -r zookeeper-3.4.10.tar.gz zookeeper1
cp -r zookeeper-3.4.10.tar.gz zookeeper2
5、在每个zookeeper/conf/新建zoo.cfg文件
① zookeeper0下的zoo.cfg文件
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/Users/zookeeper0/data
dataLogDir=/Users/zookeeper0/logs
clientPort=4180
server.0=127.0.0.1:8880:7770
server.1=127.0.0.1:8881:7771
server.2=127.0.0.1:8882:7772
② zookeeper1下的zoo.cfg文件
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/Users/zookeeper1/data
dataLogDir=/Users/zookeeper1/logs
clientPort=4181
server.0=127.0.0.1:8880:7770
server.1=127.0.0.1:8881:7771
server.2=127.0.0.1:8882:7772
③ zookeeper2下的zoo.cfg文件
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/Users/zookeeper2/data
dataLogDir=/Users/zookeeper2/logs
clientPort=4182
server.0=127.0.0.1:8880:7770
server.1=127.0.0.1:8881:7771
server.2=127.0.0.1:8882:7772
发现只有dataDir和dataLogDir还有clientPort这三个参数不一致,其他参数完全一致。
6、在这三个datadir配置的路径下/Users/zookeeper0、1、2上增加myid文件,里面依次填上0、1、2。
数字0、1、2和每个conf/zoo.cfg中的server.0、server.1、server.2的数字一一对应,让zookeeper知道你是哪个server
7、分别给这3个zookeeper节点开启服务
./zkServer.sh start
开启后,最好每个zookeeper都查看状态看一下服务是否启动:(因为start的启动的信息不准确)
./zkServer.sh status
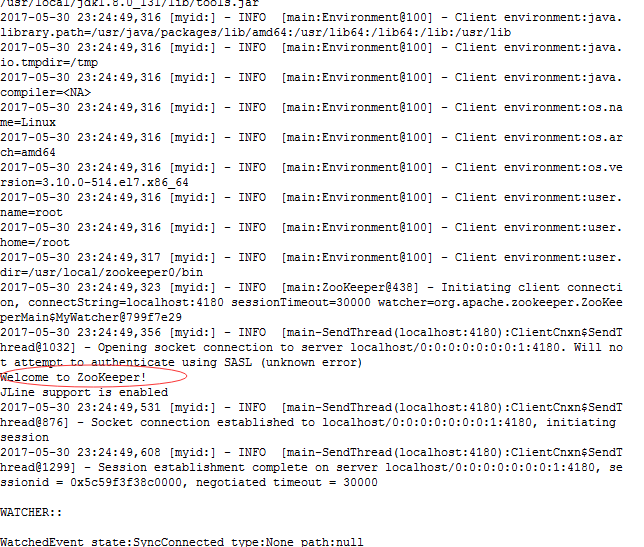
8、用客户端连接:
在任意一台server端,执行:
./zkCli.sh -server localhost:
看到以下信息,就恭喜你成功了。
集群模式:
集群模式, 各server部署在不同的机器上, 因此各server的conf/zoo.cfg文件可以完全一样(是所有都一样)
他们的zookeeper的conf下的zoo.cfg文件为:
tickTime=
initLimit=
syncLimit=
dataDir=/home/zookeeper/data
dataLogDir=/home/zookeeper/logs
clientPort=
server.=10.1.39.43::
server.=10.1.39.44::
server.=10.1.39.45::
部署了3台zookeeper server, 分别部署在10.1.39.43, 10.1.39.44, 10.1.39.45上。
各server的dataDir目录下的myid文件中的数字必须不同。
10.1.39.43 server的myid为1
10.1.39.44 server的myid为2
10.1.39.45 server的myid为3
至此,所有的安装与部署就都搞定了。
------------------------------------------------------------------------------
下面还有一些知识点:
ZooKeeper服务命令:
在准备好相应的配置之后,可以直接通过zkServer.sh 这个脚本进行服务的相关操作
- 1. 启动ZK服务: sh bin/zkServer.sh start
- 2. 查看ZK服务状态: sh bin/zkServer.sh status
- 3. 停止ZK服务: sh bin/zkServer.sh stop
- 4. 重启ZK服务: sh bin/zkServer.sh restart
zoo.cfg配置详解:
tickTime:Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,每个tickTime 时间就会发送一个心跳。
dataDir:Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
clientPort:客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
initLimit:Leader和Follower初始化连接时最长能忍受多少个心跳时间间隔数。总的时间长度就是 5*2000=10 秒。
syncLimit:Leader 与 Follower之间发送消息,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2*2000=4 秒。
server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
myid文件:
除了修改 zoo.cfg 配置文件,集群模式下还要配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面就有一个数据就是 A 的值,Zookeeper 启动时会读取这个文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是哪个server。
server.1=10.1.39.43:2888:3888,很多人不理解为啥后面有两个端口?解释一下:
2888:标识这个服务器与集群中的leader服务器交换信息的端口
3888:leader挂掉时专门用来进行选举leader所用的端口
zookeeper的安装与配置的更多相关文章
- ZooKeeper的安装、配置、启动和使用(一)——单机模式
ZooKeeper的安装.配置.启动和使用(一)——单机模式 ZooKeeper的安装非常简单,它的工作模式分为单机模式.集群模式和伪集群模式,本博客旨在总结ZooKeeper单机模式下如何安装.配置 ...
- ZooKeeper 的安装和配置---单机和集群
如题本文介绍的是ZooKeeper 的安装和配置过程,此过程非常简单,关键是如何应用(将放在下节及相关节中介绍). 单机安装.配置: 安装非常简单,只要获取到 Zookeeper 的压缩包并解压到某个 ...
- Zookeeper的安装的配置
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt192 安装和配置详解 本文介绍的 Zookeeper 是以 3.2.2 这个 ...
- 初识zookeeper(1)之zookeeper的安装及配置
初识zookeeper(一)之zookeeper的安装及配置 1.简要介绍 zookeeper是一个分布式的应用程序协调服务,是Hadoop和Hbase的重要组件,是一个树型的目录服务,支持变更推送. ...
- 浅谈 zookeeper 原理,安装和配置
当前云计算流行, 单一机器额的处理能力已经不能满足我们的需求,不得不采用大量的服务集群.服务集群对外提供服务的过程中,有很多的配置需要随时更新,服务间需要协调工作,那么这些信息如何推送到各个节点?并且 ...
- Zookeeper的安装与配置、使用
Dubbo的介绍 如果表现层和服务层是不同的工程,然而表现层又要调用服务层的服务,肯定不能像之前那样,表现层和服务层在一个项目时,只需把服务层的Java类注入到表现层所需要的类中即可,但现在,表现层和 ...
- zookeeper之一 安装和配置(单机+集群)
这里我以zookeeper3.4.10.tar.gz来演示安装,安装到/usr/local/soft目录下. 一.单机版配置 1.安装和配置 #.下载 wget http://apache.fayea ...
- 初识zookeeper(一)之zookeeper的安装及配置
1.简要介绍 zookeeper是一个分布式的应用程序协调服务,是Hadoop和Hbase的重要组件,是一个树型的目录服务,支持变更推送.除此还可以用作dubbo服务的注册中心. 2.安装 2.1 下 ...
- Linux系统下zookeeper的安装和配置
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件,提供的功 ...
随机推荐
- USACO Section 1.1-2 Greedy Gift Givers
Greedy Gift Givers 贪婪的送礼者 对于一群(NP个)要互送礼物的朋友,GY要确定每个人送出的钱比收到的多多少. 在这一个问题中,每个人都准备了一些钱来送礼物,而这些钱将会被平均分给那 ...
- Linux 初设root 密码
设置root用户的密码,输入命令:sudo passwd root 然后输入root密码,最后确认,OK,设置完成. 输入:su 提示输入密码,就能够以root身份登录啦.
- T-SQL编程中的异常处理-异常捕获(catch)与抛出异常(throw)
本文出处: http://www.cnblogs.com/wy123/p/6743515.html T-SQL编程与应用程序一样,都有异常处理机制,比如异常的捕获与异常的抛出,本文简单介绍异常捕获与异 ...
- Winform 使用DotNetBar 根据菜单加载TabControl
winform 如何使用TabControl 控件来做winform界面框架? 这样的效果: 首先菜单的窗口展示的承载器为TabControl 控件,这个控件本身包含多页面预览和页面初始化. 如图所示 ...
- 针对Mac的DuckHunter攻击演示
0x00 HID 攻击 HID是Human Interface Device的缩写,也就是人机交互设备,说通俗一点,HID设备一般指的是键盘.鼠标等等这一类用于为计算机提供数据输入的设备. DuckH ...
- CSS3弹性伸缩布局(上)——box布局
布局简介 CSS3提供了一种崭新的布局方式:Flexbox布局,即弹性伸缩布局模型(Flexible Box)用来提供一个更加有效的方式实现响应式布局. 由于这种布局还处于W3C的草案阶段,并且它分为 ...
- 关于vs code的个人配置
vs code官方下载地址 : https://code.visualstudio.com/Download 下载好的vs code相当是一款纯文本编辑器,接下来开始进行对其配置: 页面设 ...
- 纯净CentOS7.2 yum源配置与使用yum 安装系统工具net-tools
本节我们来讲CentOS 的yum 源配置 一.yum 简介 yum,是Yellow dog Updater, Modified 的简称,是杜克大学为了提高RPM 软件包安装性而开发的一种软件包管理器 ...
- 实现sticky footer的五种方法
2017-04-19 16:24:48 什么是sticky footer 如果页面内容不够长的时候,页脚块粘贴在视窗底部:如果内容足够长时,页脚块会被内容向下推送. 用position实现? 如果是用 ...
- logback配置文件详解
一:根节点<configuration>包含的属性: scan: 当此属性设置为true时,配置文件如果发生改变,将会被重新加载,默认值为true. scanPeriod: 设置监测配置文 ...