python之路 序列化 pickle,json

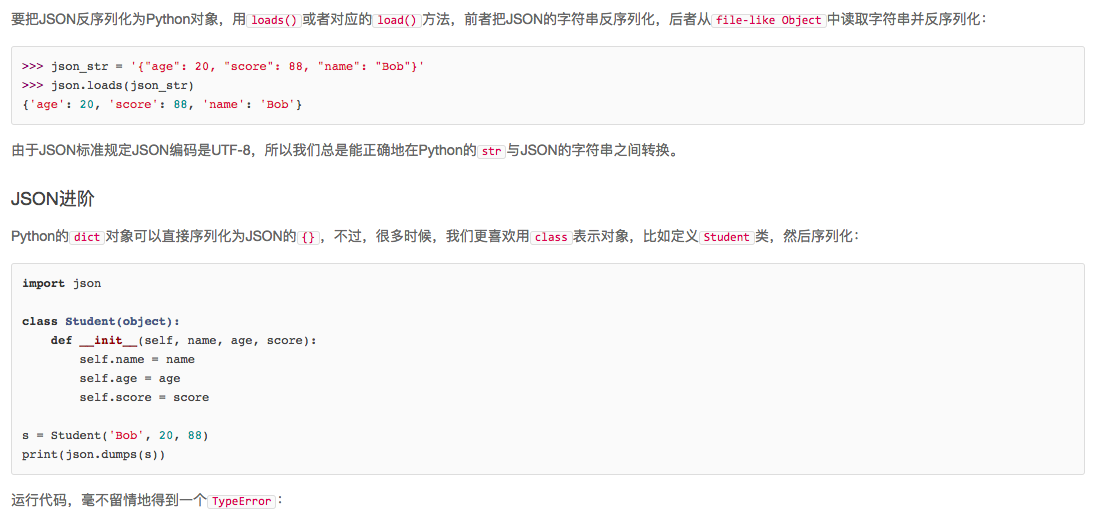
运行代码,毫不留情地得到一个TypeError:
Traceback (most recent call last):
...
TypeError: <__main__.Student object at 0x10603cc50> is not JSON serializable
错误的原因是Student对象不是一个可序列化为JSON的对象。
如果连class的实例对象都无法序列化为JSON,这肯定不合理!
别急,我们仔细看看dumps()方法的参数列表,可以发现,除了第一个必须的obj参数外,dumps()方法还提供了一大堆的可选参数:
https://docs.python.org/3/library/json.html#json.dumps
这些可选参数就是让我们来定制JSON序列化。前面的代码之所以无法把Student类实例序列化为JSON,是因为默认情况下,dumps()方法不知道如何将Student实例变为一个JSON的{}对象。
可选参数default就是把任意一个对象变成一个可序列为JSON的对象,我们只需要为Student专门写一个转换函数,再把函数传进去即可:
def student2dict(std):
return {
'name': std.name,
'age': std.age,
'score': std.score
}
这样,Student实例首先被student2dict()函数转换成dict,然后再被顺利序列化为JSON:
>>> print(json.dumps(s, default=student2dict))
{"age": 20, "name": "Bob", "score": 88}
不过,下次如果遇到一个Teacher类的实例,照样无法序列化为JSON。我们可以偷个懒,把任意class的实例变为dict:
print(json.dumps(s, default=lambda obj: obj.__dict__))
因为通常class的实例都有一个__dict__属性,它就是一个dict,用来存储实例变量。也有少数例外,比如定义了__slots__的class。
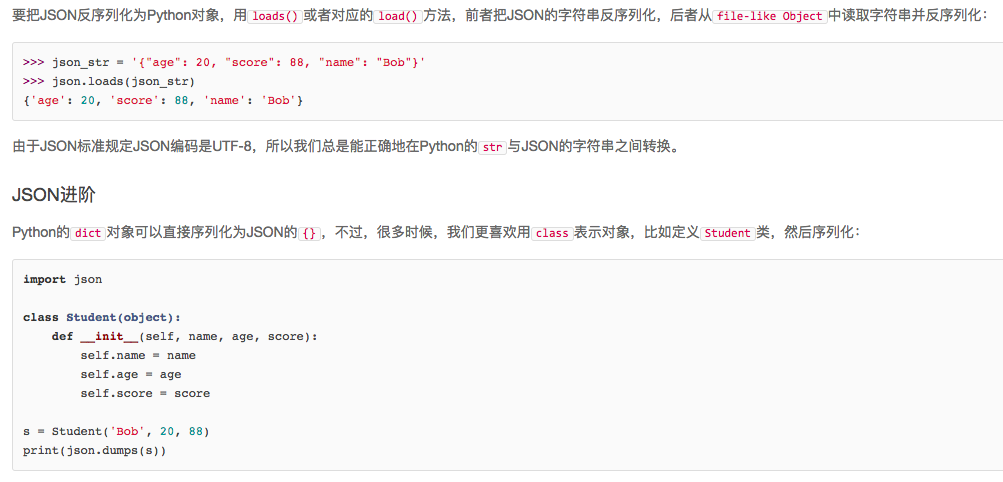
同样的道理,如果我们要把JSON反序列化为一个Student对象实例,loads()方法首先转换出一个dict对象,然后,我们传入的object_hook函数负责把dict转换为Student实例:
def dict2student(d):
return Student(d['name'], d['age'], d['score'])
运行结果如下:
>>> json_str = '{"age": 20, "score": 88, "name": "Bob"}'
>>> print(json.loads(json_str, object_hook=dict2student))
<__main__.Student object at 0x10cd3c190>
打印出的是反序列化的Student实例对象。
python之路 序列化 pickle,json的更多相关文章
- 【转】Python之数据序列化(json、pickle、shelve)
[转]Python之数据序列化(json.pickle.shelve) 本节内容 前言 json模块 pickle模块 shelve模块 总结 一.前言 1. 现实需求 每种编程语言都有各自的数据类型 ...
- Python之数据序列化(json、pickle、shelve)
本节内容 前言 json模块 pickle模块 shelve模块 总结 一.前言 1. 现实需求 每种编程语言都有各自的数据类型,其中面向对象的编程语言还允许开发者自定义数据类型(如:自定义类),Py ...
- Python:序列化 pickle JSON
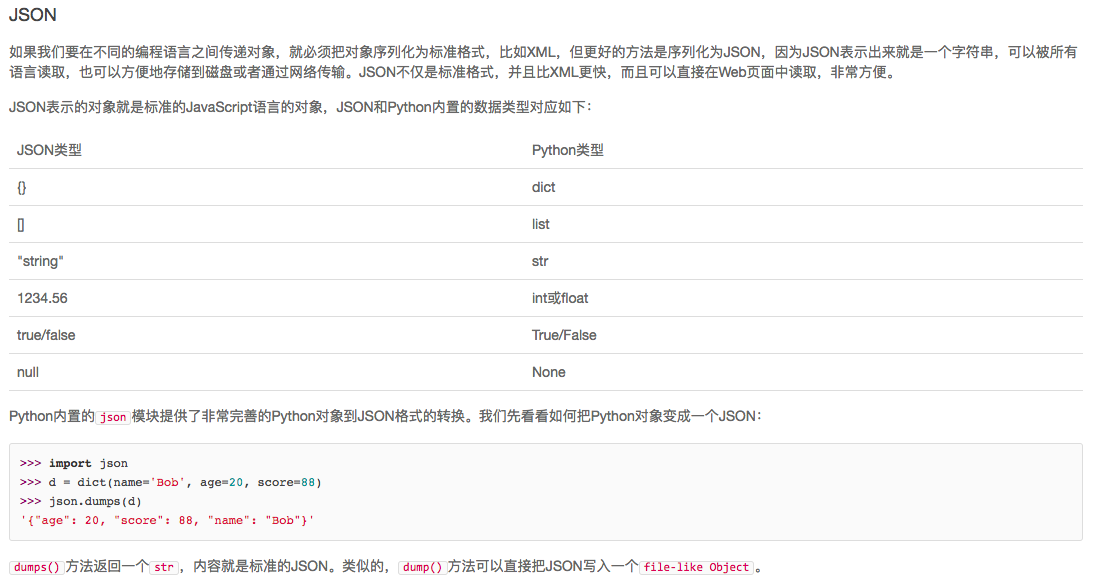
序列化 在程序运行的过程中,所有的变量都储存在内存中,例如定义一个dict d=dict(name='Bob',age=20,score=88) 可以随时修改变量,比如把name修改为'Bill',但 ...
- Python之路--序列化
序列化的目的 1.以某种存储形式使自定义对象持久化 2.将对象从一个地方传递到另一个地方 3.使程序更具有维护性 json json多语言通用 四个功能:dumps.dump.loads.load # ...
- python基础(20):序列化、json模块、pickle模块
1. 序列化 什么叫序列化——将原本的字典.列表等内容转换成一个字符串的过程就叫做序列化. 1.1 为什么要有序列化 为什么要把其他数据类型转换成字符串?因为能够在网络上传输的只能是bytes,而能够 ...
- python基础之 序列 pickle&json
内容梗概: 1. 什么是序列化 2. pickle(重点) 3. shelve 4. json(重点) 5. configparser模块 1. 什么是序列化 在我们存储数据或者网络传输数据的时候. ...
- 第二十二天- 序列化 pickle json shelve
# 序列化:存储或传输数据时,把对象处理成方便存储和传输的数据格式,这个过程即为序列化# Python中序列化的三种方案:# 1.pickle python任意数据——>bytes写入⽂件:写好 ...
- 序列化 pickle & json & shelve
把内存数据转成字符,叫序列化,dump,dumps 把字符转成内存数据类型,叫反序列化load,loads dumps:仅转成字符串 dump不仅能把对象转换成str,还能直接存到文件内 json.d ...
- Python之路-python(装饰器、生成器、迭代器、Json & pickle 数据序列化、软件目录结构规范)
装饰器: 首先来认识一下python函数, 定义:本质是函数(功能是装饰其它函数),为其它函数添加附件功能 原则: 1.不能修改被装饰的函数的源代码. 2.不 ...
随机推荐
- 【redis专题(8)】命令语法介绍之通用KEY
select num 数据库选择 默认有16[0到15]个数据库,默认自动选择0号数据库 move key num 移动key到num服务器 del key [key ...] 删除给定的一个或多个 ...
- 什么是NoSQL
NoSQL = Not Only SQL 不仅仅是SQL NoSQL,指的是非关系型的数据库(没有声明性查询语言,没有预定义的模式,可以为键 - 值对存储,列存储,文档存储,图形数据库).不同于传统的 ...
- 浅谈 angular新旧版本问题
一直在学习angularJs,之前用的版本比较老,前些天更新了一下angularJs的版本,然后发现了一些问题,希望和大家分享一下. 在老的版本里控制器直接用函数定义就可以 比如: 在angularJ ...
- SQLite数据库_实现简单的增删改查
1.SQLite是一款轻量型的数据库是遵守ACID(原子性.一致性.隔离性.持久性)的关联式数据库管理系统,多用于嵌入式开发中. 2.Android平台中嵌入了一个关系型数据库SQLite,和其他数据 ...
- Linux 系统管理06--磁盘管理
Linux系统管理06——磁盘管理 一.磁盘结构 1.硬盘的物理结构 盘片:硬盘有多个盘片,每个盘片2面 磁头:每面一个磁头 2.硬盘的数据结构 扇区:盘片被分为多个扇形区域,每个扇形区存放512字节 ...
- 保证Android后台不被杀死的几种方法
由于各种原因,在开发Android应用时会提出保证自己有一个后台一直运行的需求,如何保证后台始终运行,不被系统因为内存低杀死,不被任务管理器杀死,不被软件管家等软件杀死等等还是一个比较困难的问题.网上 ...
- [Git]08 如何自动补全命令
[Git]08如何自动补全命令 如果你用的是 Bash shell,可以试试看 Git 提供的自动完成脚本.下载 Git 的源代码,进入 contrib/completion 目录,会看到一个g ...
- 基于jQuery的自定义插件:实现整屏分页转换的功能
动态创建jQuery插件 一.实现功能: 1.基本功能:自适应式整屏分页功能的实现 2.通过鼠标点击标签页转换分页,支持键盘上下左右键的转换分页,同样支持 鼠标滚轮上下滑动转换分页 3.切屏时的动画效 ...
- Gym - 101102C线段树
Judge Bahosain was bored at ACM AmrahCPC 2016 as the winner of the contest had the first rank from t ...
- Haoop基本操作
一.HDFS的常用操作 (一).HDFS文件的权限 与Linux文件权限类似 r: read; w:write; x:execute,权限x对于文件忽略,对于文件夹表示是否允许访问其内容. 如果Lin ...