python之路 序列化 pickle,json

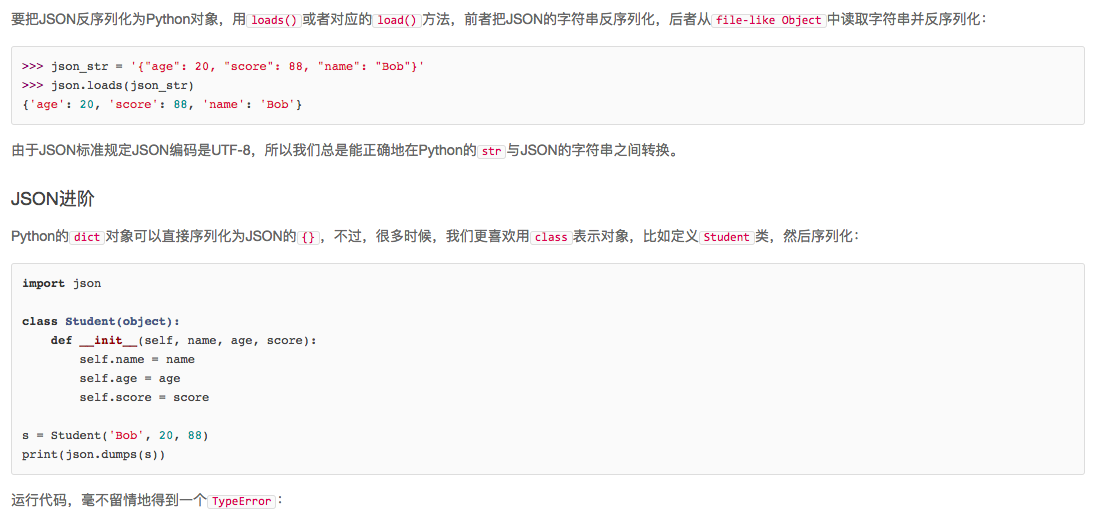
运行代码,毫不留情地得到一个TypeError:
Traceback (most recent call last):
...
TypeError: <__main__.Student object at 0x10603cc50> is not JSON serializable
错误的原因是Student对象不是一个可序列化为JSON的对象。
如果连class的实例对象都无法序列化为JSON,这肯定不合理!
别急,我们仔细看看dumps()方法的参数列表,可以发现,除了第一个必须的obj参数外,dumps()方法还提供了一大堆的可选参数:
https://docs.python.org/3/library/json.html#json.dumps
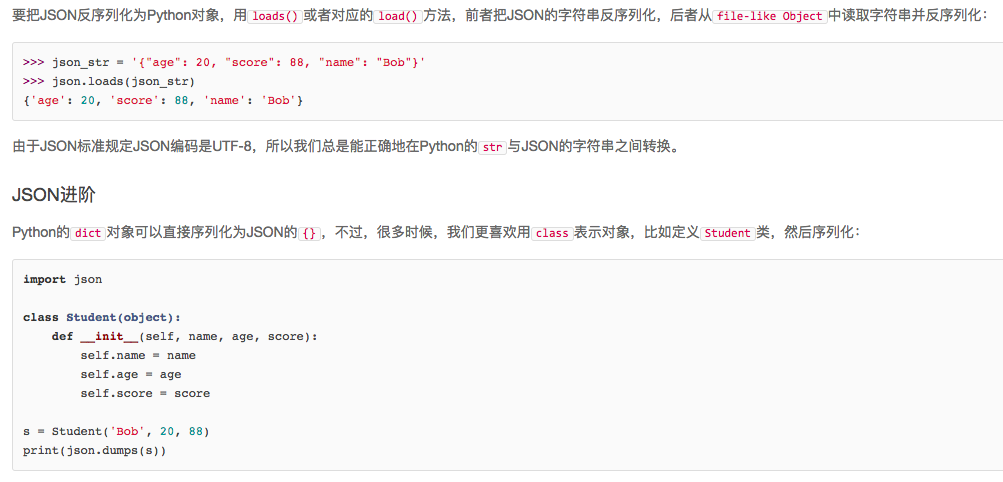
这些可选参数就是让我们来定制JSON序列化。前面的代码之所以无法把Student类实例序列化为JSON,是因为默认情况下,dumps()方法不知道如何将Student实例变为一个JSON的{}对象。
可选参数default就是把任意一个对象变成一个可序列为JSON的对象,我们只需要为Student专门写一个转换函数,再把函数传进去即可:
def student2dict(std):
return {
'name': std.name,
'age': std.age,
'score': std.score
}
这样,Student实例首先被student2dict()函数转换成dict,然后再被顺利序列化为JSON:
>>> print(json.dumps(s, default=student2dict))
{"age": 20, "name": "Bob", "score": 88}
不过,下次如果遇到一个Teacher类的实例,照样无法序列化为JSON。我们可以偷个懒,把任意class的实例变为dict:
print(json.dumps(s, default=lambda obj: obj.__dict__))
因为通常class的实例都有一个__dict__属性,它就是一个dict,用来存储实例变量。也有少数例外,比如定义了__slots__的class。
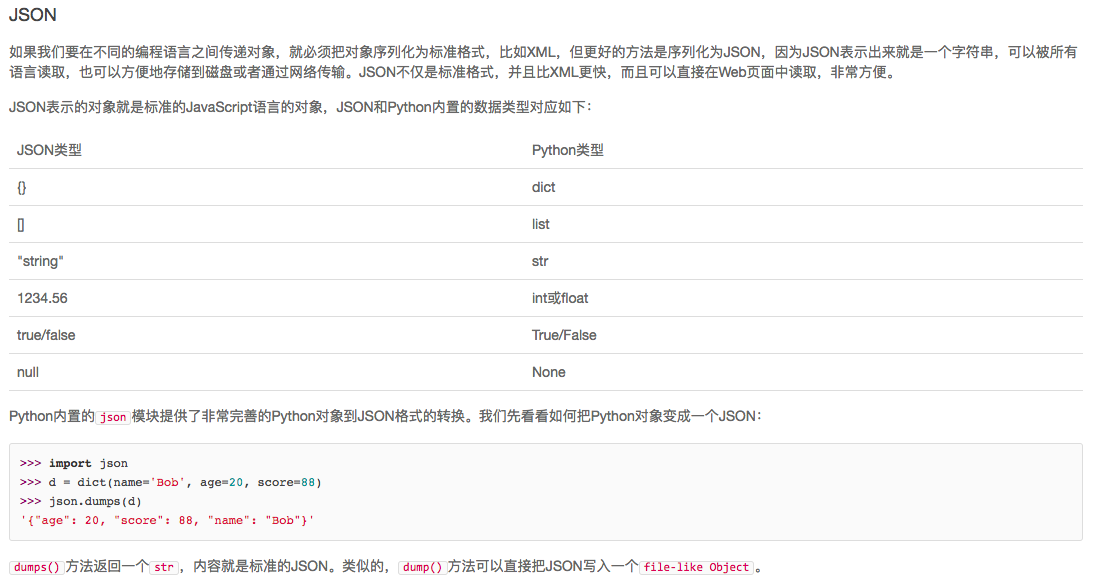
同样的道理,如果我们要把JSON反序列化为一个Student对象实例,loads()方法首先转换出一个dict对象,然后,我们传入的object_hook函数负责把dict转换为Student实例:
def dict2student(d):
return Student(d['name'], d['age'], d['score'])
运行结果如下:
>>> json_str = '{"age": 20, "score": 88, "name": "Bob"}'
>>> print(json.loads(json_str, object_hook=dict2student))
<__main__.Student object at 0x10cd3c190>
打印出的是反序列化的Student实例对象。
python之路 序列化 pickle,json的更多相关文章
- 【转】Python之数据序列化(json、pickle、shelve)
[转]Python之数据序列化(json.pickle.shelve) 本节内容 前言 json模块 pickle模块 shelve模块 总结 一.前言 1. 现实需求 每种编程语言都有各自的数据类型 ...
- Python之数据序列化(json、pickle、shelve)
本节内容 前言 json模块 pickle模块 shelve模块 总结 一.前言 1. 现实需求 每种编程语言都有各自的数据类型,其中面向对象的编程语言还允许开发者自定义数据类型(如:自定义类),Py ...
- Python:序列化 pickle JSON
序列化 在程序运行的过程中,所有的变量都储存在内存中,例如定义一个dict d=dict(name='Bob',age=20,score=88) 可以随时修改变量,比如把name修改为'Bill',但 ...
- Python之路--序列化
序列化的目的 1.以某种存储形式使自定义对象持久化 2.将对象从一个地方传递到另一个地方 3.使程序更具有维护性 json json多语言通用 四个功能:dumps.dump.loads.load # ...
- python基础(20):序列化、json模块、pickle模块
1. 序列化 什么叫序列化——将原本的字典.列表等内容转换成一个字符串的过程就叫做序列化. 1.1 为什么要有序列化 为什么要把其他数据类型转换成字符串?因为能够在网络上传输的只能是bytes,而能够 ...
- python基础之 序列 pickle&json
内容梗概: 1. 什么是序列化 2. pickle(重点) 3. shelve 4. json(重点) 5. configparser模块 1. 什么是序列化 在我们存储数据或者网络传输数据的时候. ...
- 第二十二天- 序列化 pickle json shelve
# 序列化:存储或传输数据时,把对象处理成方便存储和传输的数据格式,这个过程即为序列化# Python中序列化的三种方案:# 1.pickle python任意数据——>bytes写入⽂件:写好 ...
- 序列化 pickle & json & shelve
把内存数据转成字符,叫序列化,dump,dumps 把字符转成内存数据类型,叫反序列化load,loads dumps:仅转成字符串 dump不仅能把对象转换成str,还能直接存到文件内 json.d ...
- Python之路-python(装饰器、生成器、迭代器、Json & pickle 数据序列化、软件目录结构规范)
装饰器: 首先来认识一下python函数, 定义:本质是函数(功能是装饰其它函数),为其它函数添加附件功能 原则: 1.不能修改被装饰的函数的源代码. 2.不 ...
随机推荐
- 前端代码组织优化--小demo(进阶你的思路)
事出必有因 最近在看老项目的代码,一个富客户端的js代码,几千行的代码,全是function(){} var...的垂直布局,真的是要感动的哭了. 一开始都是这样,想实现什么功能,不管三七二十一,fu ...
- 通过一个小游戏开始接触Python!
之前就一直嚷嚷着要找视频看学习Python,可是一直拖到今晚才开始....好好加油吧骚年,坚持不一定就能有好的结果,但是不坚持就一定是不好的!! 看着视频学习1: 首先,打开IDLE,在IDLE中新建 ...
- css系列(布局):实现一个元素在浏览器中水平、垂直居中的几个方案
在开发中偶遇需要一个元素垂直居中的需求,之前都是水平居中,垂直居中使用的比较少,经过一通研究,选择了几种相对比较实用的方案分享,抛砖引玉,如有遗漏不足,还望不吝指正. 方案一(IE7下该方案无法实现垂 ...
- CSAcademy Beta Round #4 Swap Pairing
题目链接:https://csacademy.com/contest/arhiva/#task/swap_pairing/ 大意是给2*n个包含n种数字,每种数字出现恰好2次的数列,每一步操作可以交换 ...
- java类集框架(ArrayList,LinkedList,Vector区别)
主要分两个接口:collection和Map 主要分三类:集合(set).列表(List).映射(Map)1.集合:没有重复对象,没有特定排序方式2.列表:对象按索引位置排序,可以有重复对象3.映射: ...
- mysql 优化方法
1.选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快.因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽 ...
- OSI七层模型学习笔记
1.简介 什么是OSI模型呢? OSI模型全名Open System InterConnect 即开放式系统互联,是国际标准化组织(ISO)提出的一个试图使各种计算机在世界范围内互连为网络的标准框架, ...
- hadoop集群间的hdfs文件拷贝
1.背景 部门有个需求,在网络互通的情况下,把现有的hadoop集群(未做Kerberos认证,集群名为:bd-stg-hadoop)的一些hdfs文件拷贝到新的hadoop集群(做了Kerberos ...
- DDD理论学习系列(1)-- 通用语言
1.引言 在开始之前,我想我们有必要先了解以下DDD的主要参与者.因为毕竟语言是人说的吗,就像我们面向对象编程一样,那通用语言面向的是? DDD的主要参与者:领域专家+开发人员 领域专家:精通业务的任 ...
- C++中发声函数Beep详解
By zhcs 以前,我听过一个神犇用C++函数做的音乐,当时的心里就十分激动:哇,好厉害啊,好神啊. 这次,我终于通过自己无助的盲目的摸索.研究,写出了这篇文章(此时我的内心是鸡冻的233) 下面是 ...